はじめに
こんにちは!メドレーで QA エンジニアをしている@Daishu です。
Dify といえば「ノーコード AI 開発プラットフォーム」ですが、シンプルに LLM のラッパーとして使ってみたら便利だったので、その方法を紹介します。
背景: API キー管理とモデル切り替えの悩み
E2E テストの失敗を分析する Slack bot「MagicPod Assistant」を実装する中で、いくつかの課題に気づきました。
課題感
- 個別に払い出した Claude API キーの管理責任
- 新しい LLM を試すたびに API キーの発行手続きが必要
- Token 使用量のモニタリングを実装・管理する必要
プロンプトのチューニングにも一手間かかる:
コード修正 → PR 作成 → レビュー → デプロイ → 数十分後に反映
💀 Dify でイチから作り直すか?
この課題に気づいたのは、実装終盤です。弊社は、全社的に Dify での業務効率化も推奨しており、積極利用できる環境があります。Dify でも Slack bot を作成できるので、Dify でゼロから作り直すという選択も検討していました..😭
解決策: Dify を「ただのラッパー」として使う
Dify は API で呼び出せるので、ただの LLM ラッパーとして使うことで解決しました。既存の Slack bot の実装はそのままで、LLM API の呼び出し部分だけ Dify 経由にしました:
Before:直接 Claude API を呼び出し

After: Dify 経由で LLM API を呼び出す

Dify 経由で呼び出すことで各課題を解決することができました:
| 項目 | Before (直接API呼び出し) | After (Dify経由の呼び出し) |
|---|---|---|
| プロンプト変更 | コード修正 → PR → デプロイ必要 | Dify の UI で即座に反映 |
| APIキー管理 | 個別に払い出し・管理が必要 | Dify が一元管理 |
| モデル切り替え | 新規キー申請・実装が必要 | Dify 上でプルダウン選択のみ |
| Token使用量 | 自前で実装・モニタリング | Dify のダッシュボードで自動可視化 |
既存コードの変更を最小限にしながら、Dify のメリットを活用することができました。
実装例
エラーメッセージを LLM で分析するアプリケーションを例にして説明します。
1. 既存アプリケーション側の実装
// difyを呼び出す関数
async function callDify(workflowId: string, inputs: any) {
const response = await fetch(`${process.env.DIFY_API_URL}/workflows/${workflowId}/run`, {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.DIFY_API_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
inputs,
response_mode: 'blocking',
user: 'app'
})
});
return response.json();
}
既存コードの変更は、LLM API の呼び出し箇所とプロンプト管理部分です:
-const prompt = `以下のエラーを分析してください:
- エラー: ${errorMessage}
- コンテキスト: ${context}`;
-
-const response = await anthropic.messages.create({
- model: "claude-3-5-sonnet-20241022",
- messages: [{ role: "user", content: prompt }],
- max_tokens: 1024
-});
+const response = await callDify('your-workflow-id', {
+ error_message: errorMessage,
+ context: context
+});
2. Dify 側のワークフロー設定
RAG[1] やエージェントは使わず、LLM ノードを配置するだけのシンプルな Dify ワークフローです。

シンプルな3ノード構成(Start → LLM → End)
具体的な設定手順:
-
入力変数の設定 (Startノード)
-
error_message: エラー内容を受け取る -
context: 実行コンテキストを受け取る
-
-
LLM ノードの設定
- モデル: 任意の LLM
- プロンプト: 変数を
{{error_message}}のように埋め込み
-
API キーの発行
- Publish 後、「API Access」からキーを取得
- このキーを環境変数
DIFY_API_KEYとして使用
導入メリット
1. API キー管理から解放
個別に払い出してもらった Claude の API キーを破棄し、Dify の API キー 1 つで運用可能に。モデル変更に必要な社内手続きも不要になりました。
2. プロンプト変更が簡単に
デプロイ不要でプロンプトの調整が可能です。LLM が切り離されて独立しているので、ツール動作中でも即時反映できます:
- 想定していた運用:コード修正 → PR → レビュー → デプロイ (数十分)
- 実際の運用 :Dify のUI → テキスト編集 → 保存で即時反映 (10秒)
3. Token使用量の可視化
Dify のダッシュボードで自動的にモニタリング。実装不要で使用量を追跡できます。
4. LLMの付け替え、使い分けが簡単
分析タスクごとに最適な LLM を簡単に使い分けできる点もメリットです。

LLM を タスクごとに使い分ける例
このように LLM で処理を行うタスクごとに最適なモデルを選択できます。また、切り替えは Dify の UI でプルダウンで選択するのみです。実装側への影響を気にせず、いつでも変更できます。気軽に新しい LLM を試したり、戻したりできます。
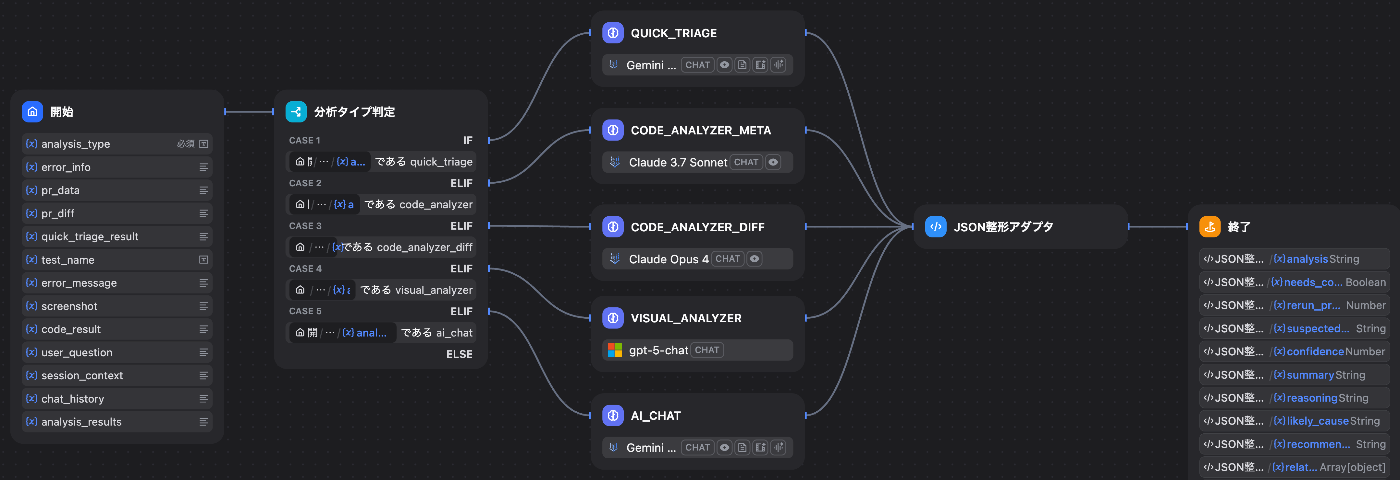
実際のMagicPod Assistantワークフロー(Pythonアダプタ付き)
5. その他のメリット
下記のようなメリットもありました。
| メリット | 詳細 |
|---|---|
| 実行履歴の可視化 | 誰が実行したか、入出力の内容、エラー詳細が全て記録される |
| A/Bテストが簡単 | ワークフロー複製して異なるプロンプトを並行運用 |
| コストの一元管理 | 複数LLMの利用料金をDifyのダッシュボードで統一管理 |
注意点
社内ツールには適していますが、本番プロダクトでの運用は難しいと思われます。
技術的な制約:
- レスポンス速度:プロキシ経由で遅延が発生 (体感で数百 ms ほど)
- 初期設定:複雑な JSON を扱う場合、Python アダプタでの整形などの工夫が必要
- デバッグ:確認箇所は増えてハマりやすい。プロンプトの変更履歴が追えない
向いている用途:
- 社内向けのツール・システム
- 実験的なプロトタイプ
- プロンプトを頻繁に調整したいプロジェクト
向いていない用途:
- ユーザー向けの本番プロダクト
- レスポンス速度がクリティカルなサービス
- 変更履歴の厳密な管理が必要なシステム
まとめ
API キー管理、社内手続き、Token 使用量のモニタリングといった課題が、Dify をラッパーとして使うことで全て解決しました。また、プロンプト変更は 10 秒で完了、モデル切り替えも容易です。
同じような課題を抱えている方の参考になれば幸いです。既存コードはそのままで、LLM 呼び出し部分だけ Dify 経由にすれば、最小限の変更で済むはずです。
メドレーでは生成 AI 利用のガイドラインが社内で展開されており、各部門の業務ではそのガイドラインに沿って利用をしています。
-
Retrieval-Augmented Generation (検索拡張生成) 。事前に登録したドキュメントから関連情報を検索し、その情報を基に LLM が回答を生成する仕組み ↩︎

Discussion