こんにちは!メドレーで QA エンジニアをしている小島 (@Daishu) です。
AI を活用したテストケース生成について、私が組織で実践しているアプローチを紹介します。

※この記事は「Medley Summer Tech Blog Relay」2 日目の記事です
はじめに
テストケースの自動生成は、もはや珍しい話ではありません。弊社でも全社的に AI 活用を推進しており、個人レベルで AI エディタや CLI を自由に利用できる環境が整っています。
しかし現実には、個人の工夫が個人のローカルで完結してしまうという課題があります。効果的なプロンプトやテスト観点が個人のナレッジに留まり、組織として蓄積されません。結果として、AI に与えるドメイン知識が不足し、メンバーごとに品質にばらつきが生じ、同じ失敗を繰り返すリスクがあります。
開発速度 10 倍化と QA の課題
弊社の AI 推進グループが掲げる「CLINICS 10x」という取り組みが始動しました。AI 活用により、週あたりのアウトプットを 10 倍に引き上げるものです。
実際、生成 AI の活用が急速に広がり、PR の数もコード量も大幅に増加しています。
弊社には「全員が品質に責任を持ち QA を行う」というマインドセットが根付いていますが、CLINICS 10x を実現するには各職種の最適な立ち回りが必要です。医療システムは品質を犠牲にすることはできません。
開発者が AI をフル活用するなら、QA エンジニアも AI をフル活用して対応する必要がある 🔥
組織学習型 QA ツール:qa-knowledge
CLINICS 10x を実現するには、個人のナレッジを組織レベルで集約して AI の精度を高める必要があります。そこで私は、3 つの要素に着目しました:
- プロンプト: AI への指示を標準化できないか?
- ナレッジ: 過去の学びを蓄積できないか?
- 共有と改善: プロンプトとナレッジを Git で管理し、チーム全体で共有・改善できないか?
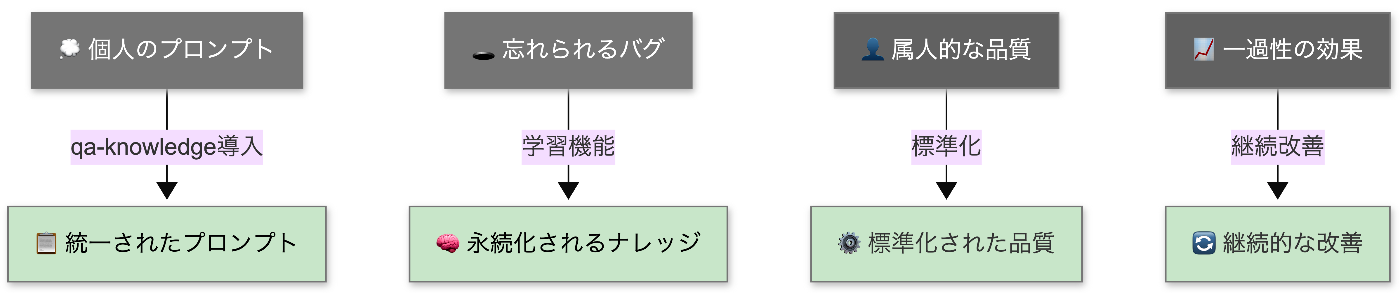
プロンプトとナレッジを Git リポジトリで一元管理することで、個人の AI 活用を組織の資産に変換する仕組みを構築しました。これが組織学習型 QA ツール qa-knowledge です。つまり、チーム全体で AI を成長させる仕組みです。
qa-knowledge の基本コンセプト
「AI が専門知識を補完して、誰でも高品質なテストを設計できることを目指す」
qa-knowledge/
├── prompts/ # AI への指示 (標準化)
├── knowledge/ # テスト観点の蓄積 (資産化)
└── products/ # プロダクト別の学習結果 (進化)
テスト観点の属人性が解消され、個人の経験に埋もれていた観点や過去の不具合パターンが組織の共有資産となります。誰がテスト設計しても一定水準の品質を担保でき、AI が必要な観点を適切に選択・活用します。
システム構成
qa-knowledge はインフラ不要でシンプルな構成です:
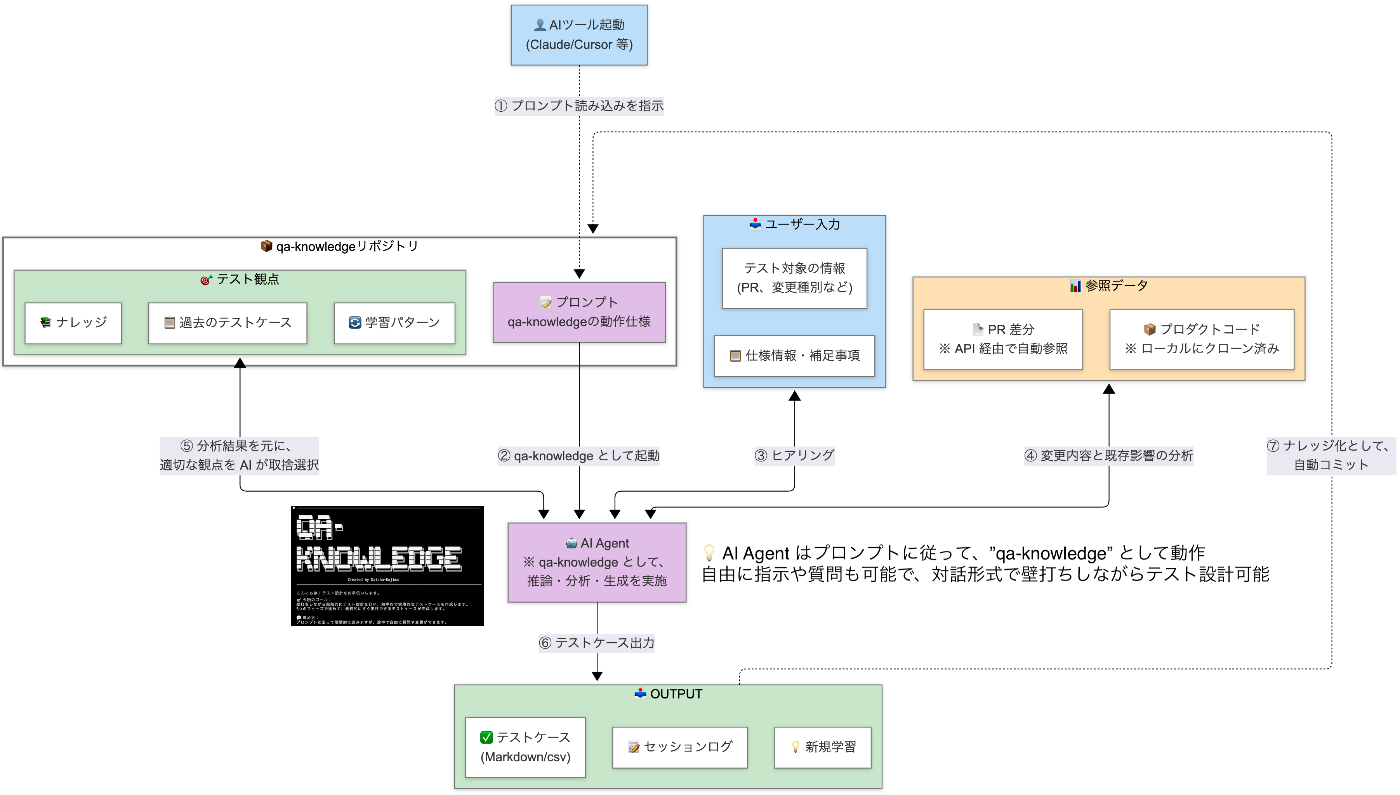
▶︎ 動作の仕組み
4,200 行以上のプロンプトに、qa-knowledge の動作仕様を定義しています(処理フロー、エラーハンドリング、出力形式など)。コードは一切書かず、すべて自然言語の指示のみで動作します。そのため、誰でも理解・修正でき、AI モデルが変わっても同じ qa-knowledge として動作します。
▶︎ 起動方法
AI エディタまたは CLI にて、以下のコマンドを送信するだけです:
「qa-knowledge.mdの内容に従って、テスト設計アシスタントとして動作開始」
▶︎ 主な特徴
シンプルな構成により、どのプロダクトでも導入・運用が可能です。
| 特徴 | 説明 |
|---|---|
| サーバー不要 | Git + AI エディタのみで完結 |
| Token 管理不要 | API キーの中央管理不要 (各自のエディタで完結) |
| メンテナンス容易 | Markdown / YAML 形式で管理 (コードなし) |
| AI モデル非依存 | どの AI モデルでも動作可能 |
テスト設計の仕組み
qa-knowledge の AI が参照する情報について詳しく説明します。
1. 階層型ナレッジ構造
qa-knowledge の中核となる仕組みです。組織全体の知識を体系的に管理しています:
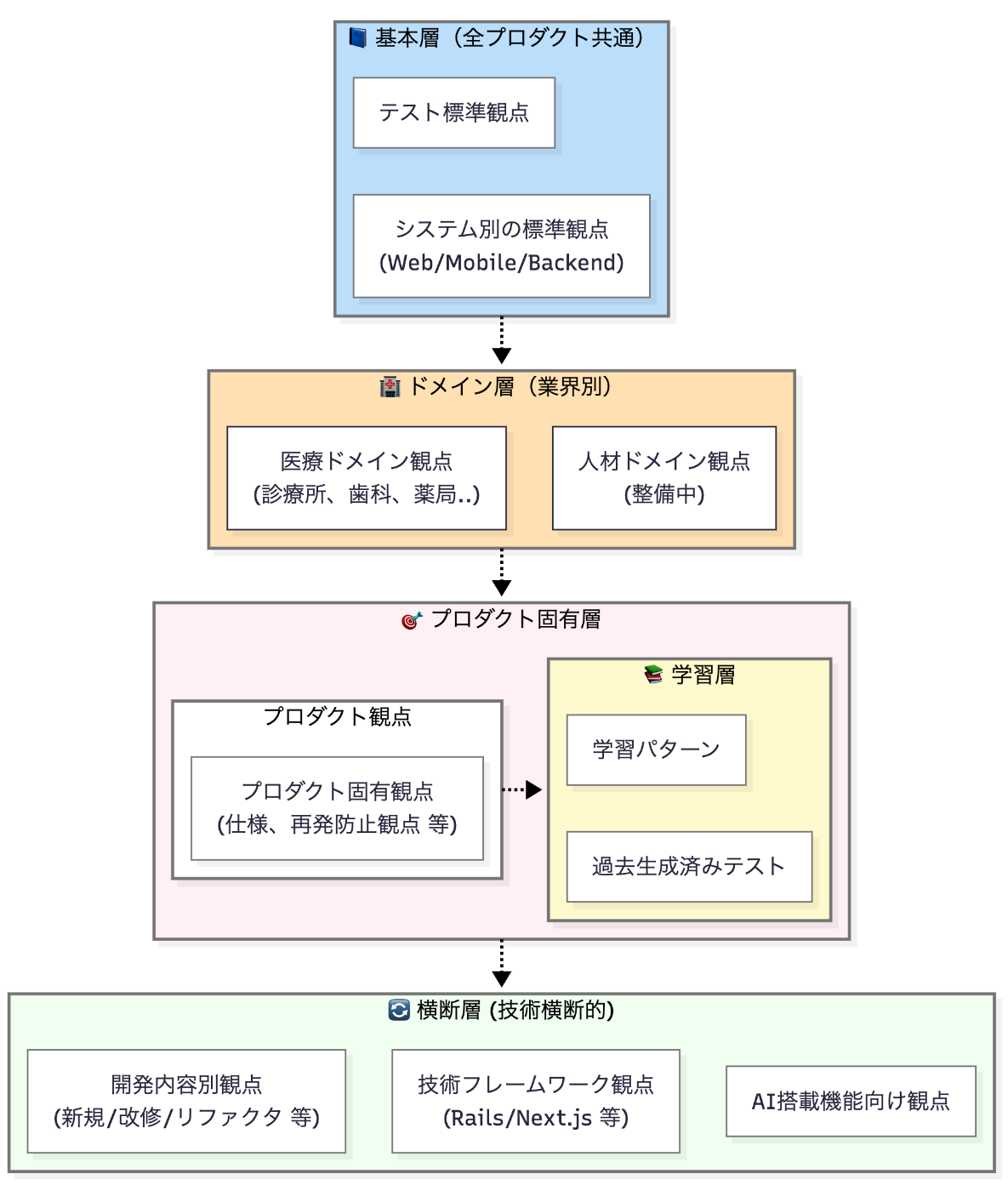
共通知識とプロダクト固有知識の分離
基本的なテスト観点は全プロダクトで共有し、システム固有のテスト観点は各プロダクトで管理します。これにより、組織全体の品質向上と各プロダクトの特性への対応を両立しています。
2. PR とコードベースの包括的分析
PR 情報を多角的に分析
qa-knowledge は、GitHub API を活用して PR (Pull Request) 情報を包括的に取得します:
| 取得情報 | 活用方法 |
|---|---|
| 差分 (diff) | どのファイルが変更されたか、どんな処理が追加・削除されたかを把握 |
| 本文・コメント | 開発者の意図やテスト実施結果を理解 |
| テストコード | 既にカバーされているテスト項目を特定 |
これらの情報から、影響範囲を特定し、重複を避けた効率的なテストケースを洗い出します。
既存コードベースから影響範囲を把握
PR 差分だけでなく、ローカルのコードベース全体を参照することで、見落としがちな影響を検出します。例えば、既存機能への影響や依存関係、要件に対する影響範囲の考慮漏れ、リファクタリング時の実装漏れなど、差分だけでは見えない潜在的な問題を発見できます。
組織全体のコードベースを活用した分析
qa-knowledge の特徴として、単一プロダクトに留まらず、組織配下の全プロダクトのコードベースを参照できます:
medley/ # 組織 root (ここで AI エディタを起動)
├── qa-knowledge/ # テスト設計ナレッジ
├── clinics/ # プロダクト A
├── dentis/ # プロダクト B
└── shared-libs/ # 共通ライブラリ
この構成により、共通ライブラリの変更が複数プロダクトに与える影響を検出したり、プロダクト間の依存関係を考慮したテスト設計が可能になります。
3. 仕様ドキュメントとの整合性確認
任意ですが、仕様を渡すことも可能です。直接テキストで渡しても良いですし、ファイルベースでも問題ありません。MCP[1] 経由で Notion や Confluence などに記載された仕様書を URL ベースで与えることも可能です。
仕様と実装の乖離を自動検出
仕様書と実装の差分を検知する仕組みも実装しています。実装漏れを検知したり、仕様書の最新化が必要なことに気づくことに役立ちます。
テスト観点の絞り込みロジック
qa-knowledge の中核となる、保有するナレッジからテスト観点を段階的に絞り込む流れを説明します。後述する 5 フェーズフローのうち、Phase 3「テスト観点の設計」で実行される処理です:

テスト観点を 4 段階で絞り込むフロー
収集した観点は、変更内容との関連性、実施済みテストの除外、リスク評価、テスト設計技法の適用により、500 - 800 個から最終的に 15 - 20 個まで段階的に絞り込まれます。この過程により、必要最小限かつ網羅的なテスト観点が選択されます。
実際の処理フロー
qa-knowledge は、QA エンジニアの思考プロセスを 5 つのフェーズで再現しています。各フェーズで中間成果物を出力するため、AI の判断過程を把握することができます。
# Phase 1: 要件ヒアリング
- テスト対象の機能と PR 番号を確認
- → 📝 中間成果物:変更概要の理解内容
# Phase 2: 実装分析 & 影響調査
- PR 差分と既存コードベースから影響範囲を特定
- → 📝 中間成果物:変更ファイル一覧と影響範囲レポート
# Phase 3: テスト観点の設計
- 関連する観点を収集・選択
- → 📝 中間成果物:適用する観点リスト、除外した観点とその理由
# Phase 4: テストケース生成
- 優先度付きテストケースを生成
- → 📝 中間成果物:初期テストケース(12-20 個)
# Phase 5: AI セルフレビュー
- 重複削除と不足分追加で最適化
- → 🏁 最終成果物:最適化済みテストケース
これにより、最終成果物までに至る過程がブラックボックスとならず、AI がなぜその観点を選んだのか、どの観点を除外したのかが明確になり、ユーザーは必要に応じて軌道修正が可能です。
📋 実際に生成されたテストケースのキャプチャ(クリックで展開)
MarkDown で生成したテストケースを PR のコメントに貼り付けた例:

組織学習を実現する仕組み
1. セッション終了時の自動ナレッジ化
使用するたびに組織学習が進む仕組みを実装しています:
| 自動保存される内容 | 説明 |
|---|---|
| テストケース | 生成されたテストケースの流用目的で利用 |
| 新規学習 | 今回発見された有効な観点やパターンを蓄積して学習に利用 |
| セッションログ | 対話履歴を記録してプロンプト改善に利用 |
自動化の仕組み:
Phase 5 のプロンプトに Git コマンドを埋め込むことで、セッション終了時に自動的にコミットされます:
git add testcases/ learned-patterns.yml session-logs/
git commit -m "feat(${PRODUCT_NAME}): セッション成果物を保存 (#${PR_NUMBER})"
これにより、「使うだけで組織のナレッジが蓄積される」 という理想を実現しています。次回のセッションから、蓄積された知見が自動的に活用されます。
2. ナレッジの品質管理
セッション中に発見された知見は、ノイズを防ぐため 2 段階で管理されます:

溜まったナレッジは「プロダクト固有か共通か」を判断して適切な場所に配置する運用にしています。この整理・検証作業により、誤った観点の学習を防ぎ、組織全体の知識を洗練します。
| 種別 | 反映タイミング |
|---|---|
| テストケース | 即座に自動保存、次回から参照可能 |
| 新規ナレッジ | 一時保存後、定期レビューで正式化 |
また、定期的にセッションログを分析してプロンプト自体も改善することで、システム全体の精度が継続的に向上していきます。
3. 障害から学ぶ
障害の再発防止策を人の記憶に頼るだけでは、不十分です。qa-knowledge にナレッジとして追加することで、今後のテスト設計時に必ず考慮される恒久的なチェック項目になります。
これまで、各チームで管理していた「再発防止の品質観点リスト」といったドキュメントも、qa-knowledge に一本化できます。これにより、散在していた知見が集約され、全チームが過去の教訓から学べるようになります。

QA 時に見つけた不具合をナレッジに追加した例
定期的に、特定ラベルが付与された不具合修正の PR を収集し、それらの不具合パターンを分析してナレッジ化する運用を進めています。
実績と成果
実運用を通じて継続的に改善している段階ですが、確かな手応えを感じています。
導入効果の比較 (期待値込み)
| 項目 | 従来のテスト設計 | qa-knowledge 導入後のテスト設計 |
|---|---|---|
| テスト観点 | 個人の経験に依存 | 2,000 個以上の組織ナレッジから選択 (共通 600個、ドメイン 600個、プロダクト固有 800個) |
| 設計時間 | 60 分以上 | 約 15 分 (75% 削減) ※ 直近 5 セッションの平均値 |
| Token 使用量 | - | 約 2.3 万 tokens/セッション ($2-3 相当) |
| 品質のばらつき | 担当者のスキルに依存 | AI が標準化された観点を適用 |
| 過去の知見 | 属人化・忘却される | Git 管理で永続化・自動活用 |
| 影響範囲の把握 | 差分のみ確認しがち | PR 差分 + 既存コードベース全体を分析 |
| 学習効果 | 個人に留まる | 使うたびに組織全体が成長 |
※ 2025 年 7 月から運用開始、30 回以上のセッションを実施
※ CLINICS、Dentis など複数プロダクトで展開中
社内からの声
自動生成ツールの説明聞きながら、純粋にすごい良いな!!と感動&ワクワクしました!
誰でも一定水準のテストケースが作れる=全体品質の底上げや一定化に貢献できるのはめちゃくちゃでかいなーと
担当のプロダクトで情報溜めながらガンガン活用していきます!!!!
PMが作成する要件定義での利用も見込めて嬉しいです!(プロダクト全体でもプラスに働く)
要件定義作成もAI活用していきたいと思っているので、フィードバックをPM側で吸収して学習できるとよさそう
単体テストコードの品質向上にも利用できると思う!CI に組み込みたい
その他の成功事例
あるチームを担当していた QA エンジニア が一時的に不在となり、ドメイン知識のない別チームの QA エンジニア がテスト設計を急遽担当することになりました。通常ならキャッチアップに時間を要しますが、qa-knowledge の支援により即座に対応できました。
おわりに
本記事では、組織で AI を育てるテスト設計の仕組みについて紹介しました。qa-knowledge は、10x 時代の QA ボトルネックを解消し、品質と速度を両立させる仕組みです。最大の強みは AI モデル非依存であることです。普遍的な技術のみで構成されています:
- プロンプト: 自然言語で記述
- ナレッジ: Markdown / YAML 形式
- 管理: Git によるバージョン管理
そのため、AI モデルが進化してもナレッジ資産は失われません。むしろ新しいモデルが、既存のナレッジをより賢く活用してくれます。
今後に向けて
今後は、さらに横のプロダクトへの展開、仕様レビューへの活用も検討しています。詳細は「ソフトウェアテスト自動化カンファレンス2025」で発表したいと思っています。
開発が 10 倍速になる世界に向けて、この仕組みの実践と改善を続けていきます!
メドレーで一緒に働きませんか?
メドレーは、開発者、デザイナー、PdM、CS の方々全員が品質に責任を持ってコミットしています。そんな会社だからこそ、組織学習型 QA を実現できる qa-knowledge はフィットすると思い、開発を始めました。「品質と CLINICS 10x を両立」という困難な課題に対して、一緒に挑戦したい方を探しています!
こんな方を探しています:
- 品質と速度の両立に挑戦したい方
- AI を活用した新しい開発/QA に興味がある方
- 医療という社会的意義のある領域で働きたい方
Medley Summer Tech Blog Relay 3 日目は、人材プラットフォーム本部の森川さんの記事です!
メドレーでは生成 AI 利用のガイドラインが社内で展開されており、各部門の業務ではそのガイドラインに沿って利用をしています。
-
Model Context Protocol: AI エディタが外部ツールと連携するための標準プロトコル ↩︎

Discussion