こんにちは、エンジニアの morux2 です。株式会社メディキューでは、GitHub Actions を用いた CI/CD の実装を担当しています。
今回は、dbt モデルの更新によって生まれるデータの差分を検知する「table diff」の実装をご紹介します。table diff は 本番環境 (main ブランチ) と PR 環境のデータの差分を計算し、結果を PR にコメントします。

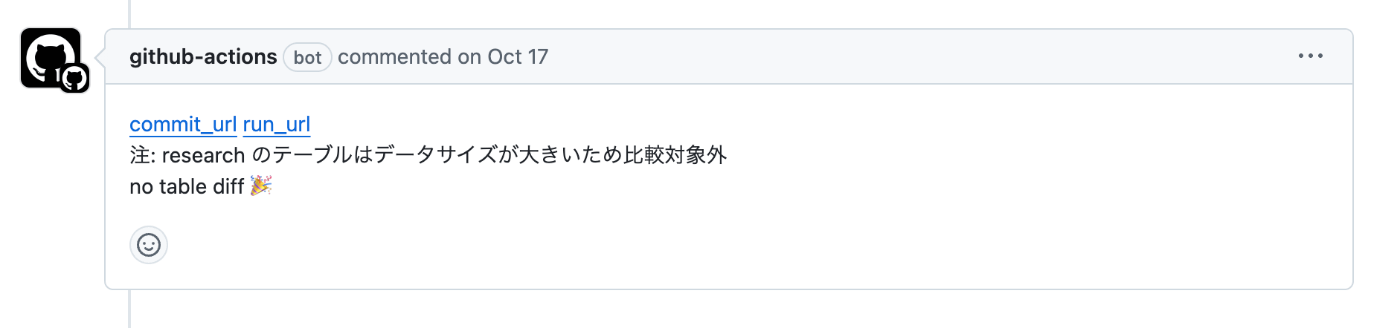
table diff で差分を検知する
前提
弊社では、BigQuery にそれぞれの PR 専用の環境を立ち上げています。この仕組みを 「dbt fork」と呼んでいます。(dbt fork の実装詳細は本記事では省略します。)

dbt fork によって PR 専用の環境が立ち上がる
dbt fork を用いて、PR で変更が入ったデータセットのみを BigQuery の sandbox プロジェクトに作成し、作成したデータセットに対してテストを実行しています。
完成品
PR にラベルを付与すると、dbt fork が実行された後に table diff が実行されます。table diff は、本番環境と PR 環境のデータの差分を計算し diff の個数をカウントします。

table diff の用途
table diff 実装のモチベーションは以下の2点です。
-
dbt モデルの変更によって、意図した差分が加わることを確認したい
特にテーブルやビューの依存関係がある場合に、PR の影響範囲を確認したいケースが多いでしょう。テーブル A に依存している B にも変更が加わるかどうかや、認知していない依存関係によって、思わぬテーブルに変更が入ってしまわないかを確認できます。 -
dbt モデルのリファクタリングによって、差分が生まれないことを確認したい
差分が0件であることを確認できれば、自信を持って PR をマージすることができるでしょう。
table diff の実装
それではここから、具体的な実装をご紹介していきます。table diff の処理の流れは次の通りです。
- dbt fork を用いて、変更が入ったデータセットを PR 専用の環境に作成する
- PR 環境のデータセットの情報を取得する
- PR 環境のデータセットに対応する、本番環境のデータセットの情報を取得する
- データの差分を計算するクエリを組み立てる
- BigQuery のクライアントから API を叩き、組み立てたクエリを実行する
- クエリの実行結果を整形して PR にコメントする
0. dbt fork を用いて、データセットを PR 専用の環境に作成する
dbt fork では、profiles.yml を上書きして BigQuery の sandbox プロジェクトに接続するようにします。dbt fork の後、dbt build コマンドを叩くことで、fork した環境でデータセットを作成したり、モデルやテストを実行します。なお、sandbox で利用するデータは、 dbt の selector で PR で変更が入ったものに絞られており、データ量は 1/64 にサンプリングされています。
上書きされる profiles.yml は次のようなイメージです。
medicu:
outputs:
dbt-fork-sampling64:
dataset: pr_number_merge
job_execution_timeout_seconds: 300
job_retries: 1
location: asia-northeast1
method: oauth
priority: interactive
project: medicu-sandbox
threads: 50
type: bigquery
target: dbt-fork-sampling64
詳細は割愛しますが、マクロの書き換え を行うことで pr_number_merge_dataset_name の形で作成されるように設定しています。
実行するコマンドは次のようなイメージです。
scripts/fork.sh run --target sampling64
dbt build --full-refresh --selector modified
dbt build コマンドを実行すると、 run_results.json (実行結果) と manifest.json (プロジェクト全体の情報) が出力されます。table diff ではこれらのファイルの読み取り、diff を計算するためのクエリを組み立てていきます。
1. PR 環境のデータセットの情報を取得する
PR 環境のデータセットの情報の取得には run_results.json を用います。run_results.json には、モデルとテストの実行結果が格納されています。
run_results.json の中身は次のようなイメージです。(一部抜粋)
{
"results": [
{
"status": "success",
"message": "CREATE TABLE (622.0 rows, 432.1 KiB processed)",
"failures": null,
"unique_id": "model.medicu.model_name",
"relation_name": "`medicu-sandbox`.`pr_number_merge_xxx`.`yyy`"
},
{
"status": "pass",
"message": null,
"failures": 0,
"unique_id": "test.medicu.test_name",
"relation_name": null
}
]
}
このように、モデルの実行結果から relation_name を抽出することで PR で変更のあったデータセットの情報を取得できることがわかります。run_results.json には、テストの実行結果も含まれるので、モデルの実行結果のみを抽出対象にします。
これらを踏まえて、run_results.json を次のようにモデリングしています。
class Run:
def __init__(self, doc):
self.doc = doc
@property
def unique_id(self):
return self.doc.get("unique_id")
@property
def relation_name(self):
relation_name = self.doc.get("relation_name")
return relation_name.replace("`", "") if relation_name else None
@property
def is_table_creation(self):
return self.resource_type == "model" and self.relation_name is not None
@property
def resource_type(self):
return self.unique_id.split(".")[0]
@property
def status(self):
return self.doc.get("status")
2. 対応する本番環境のデータセットの情報を取得する
main ブランチでは、dbt のモデルに変更が加わるたびに dbt build を実行して、本番環境のデータを更新しています。main ブランチで dbt build を実行した結果の run_results.json と manifest.json を GitHub Actions の Artifacts としてアップロードしておきます。そして、table diff を計算する際には、main ブランチの最新の Artifacts を gh コマンドを用いてダウンロードします。
対応する本番環境のデータセットがどれなのかは manifest.json で確認することができます。manifest.json の中身は次のようなイメージです。(一部抜粋)
{
"nodes": {
"model.medicu.model_name": {
"unique_id": "model.medicu.model_name",
"columns": {
"column1": {
"name": "column1",
"type": "INTEGER"
},
"column2": {
"name": "column2",
"type": "STRING"
},
"column3": {
"name": "column3",
"type": "FLOAT64"
},
"column4": {
"name": "column4",
"type": "RECORD"
}
"column4.field1": {
"name": "column4.field1",
"type": "RECORD"
}
"column4.field2": {
"name": "column4.field2",
"type": "RECORD"
}
},
"relation_name": "`medicu-sampling64`.`xxx`.`yyy`",
},
"test.medicu.test_name": {
"unique_id": "test.medicu.test_name",
"columns": {},
"relation_name": null,
}
}
}
}
このように、manifest.json の key と run_results.json の unique_id が対応していることがわかります。そして、データセットの情報は先ほど同様に relation_name から取得できます。
これらを踏まえて、manifest.json を次のようにモデリングしています。
class Node:
def __init__(self, doc):
self.doc = doc
@property
def relation_name(self):
relation_name = self.doc.get("relation_name")
return relation_name.replace("`", "") if relation_name else None
@property
def columns(self):
return self.doc.get("columns")
@property
def unique_id(self):
return self.doc.get("unique_id")
3. データの差分を計算するクエリを組み立てる
ここまでで、PR 環境のデータセットとそれに対応する本番環境のデータセットの情報が取得できました。ここからは、データの差分を計算するクエリを組み立てていきます。
ベースとなるクエリは以下の通りです。PR 環境のみ存在するレコードと、本番環境のみ存在するレコードをそれぞれ取得し、両テーブル間の全ての差分をカウントしています。
with
pr_table as (select * from `pr_table`),
main_table as (select * from `main_table`),
diff as (
select * from (
select * from (
select * from pr_table
except distinct
select * from main_table
)
union all
select * from (
select * from main_table
except distinct
select * from pr_table
)
)
)
select count(*) from diff;
基本的には、このクエリのテーブル名に今までのステップで取得した情報を渡すことで、diff をカウントすることができます。
しかし、このクエリを叩いた際に以下の2点の問題が発生しました。
- Float の丸め誤差によって、誤って diff があると判定されてしまう
- RECORD 型には、EXCEPT DISTINCT との互換性がない ので、RECORD 型 を含むテーブルに対してクエリを実行するとエラーになる
そこで、SELECT 文を加工することにしました。それぞれ以下のように対処しています。
- Float 型を 指数表記の文字列 に変換する
- RECORD 型 は diff の計算対象にしない
カラムの情報は manifest.json から取得できるので、この情報から SELECT 文を組み立てます。実際のコードは次の通りです。
class Node:
# 省略
@property
def select_list(self):
if self.columns is None:
return None
select_list = []
for column_name, column_info in self.columns.items():
column_type = column_info.get("type", None)
column_name = column_info.get("name", None)
if column_type == "RECORD" or "." in column_name:
# RECORD 型 は diff の計算対象にしない
continue
elif column_type in ("FLOAT64", "FLOAT"):
# Float 型を指数表記の文字列に変換する
select_list.append(f"format('%e', cast({column_name} as float64))")
else:
select_list.append(column_name)
return ", ".join(select_list)
最終的には次のようなクエリが組み立てられます。
with
pr_table as (select column1, column2, format('%e', cast(column3 as float64))
from `pr_table`),
main_table as (select column1, column2, format('%e', cast(column3 as float64))
from `main_table`),
diff as (
select * from (
select * from (
select * from pr_table
except distinct
select * from main_table
)
union all
select * from (
select * from main_table
except distinct
select * from pr_table
)
)
)
select count(*) from diff;
4. BigQuery の API を叩き、組み立てたクエリを実行する
クエリの組み立てが完了したら、あとは公式ドキュメントに沿ってクエリを叩くだけです。クエリの叩き方は 公式ドキュメント を参考にしてください。
QueryJob の total_bytes_billed の値を参照することで、table diff の計算にいくらかかったか計算することも可能です。料金は こちらのページ を参考にしました。
5. クエリの実行結果を整形して PR にコメントする
table diff の実行結果は gh コマンドを用いて PR にコメントします。差分のカウントだけでなく、比較したテーブルの情報や実行したクエリを添付しておくことで、手動でのデバッグができるようにしています。
まとめ
今回は、dbt モデルの更新によって生まれるデータの差分を検知する「table diff」の実装をご紹介しました。dbt build 実行時に出力される json ファイルを用いて、PR 環境と本番環境のデータセットを取得し、差分を計算するクエリを組み立てています。table diff によって、dbt のモデルをより安全に更新することができます。ぜひ、皆さまも実装を検討してみてください!

Discussion