実行計画とは何なのか、インデックスがどのように検索を効率化しているのか理解できていなかったのでSQL初心者の方の勉強にとっかかりになれば幸いです!
RDBMSの仕組み
まずはじめに、実行計画とはなにかを理解するために、RDBMSがどのようにクエリの処理をおこなっているのか解説します。
RDBMSは以下のサブモジュールで構成されています。
- パーサ
- オプティマイザ
- カタログマネージャ
- プラン評価
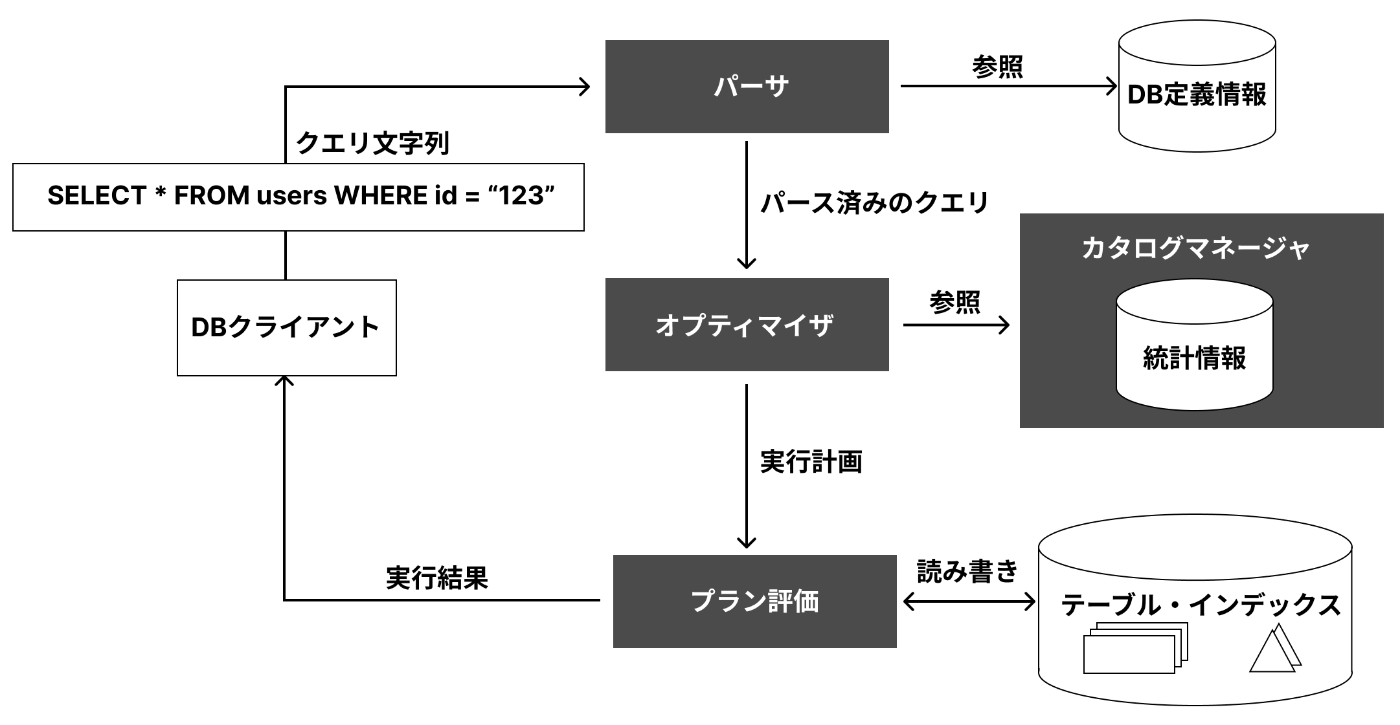
パーサ
コンパイラのようなものです。
受け取ったクエリ文字列を構文解析し、SQL文として正しい構文になっているかどうかの判定に加え、FROM句に存在しないテーブルを指定していないかチェックしたりSQLのVIEWをSELECT文に書き換えたりなど、DBの定義情報を含めた解析もおこなうモジュールです。
オプティマイザ
最適なデータへのアクセス方法(実行計画)を決定するモジュールです。
カタログマネージャから受け取った統計情報(データの分散や偏り度合いなど)を考慮して複数の実行計画を作成し、その中から最もコストの低い実行計画を選定してくれます。
※実行計画の例↓(詳細は後述します)
Index Scan using "IDX_2dd975e8a6f46ea1fa0c19ec9e" on users (cost=0.15..8.17 rows=1 width=261)
Index Cond: ((kana)::text = 'きたのたけし'::text)
カタログマネージャ
オプティマイザが実行計画をたてる際に必要な統計情報を提供するモジュールです。
統計情報は以下のような情報です。
- 各テーブルのレコード数
- 各テーブルの列数と列のサイズ
- カラム値のカーディナリティ
- カラム値のヒストグラム
- インデックス情報
統計情報は SELECT * FROM pg_stats; で閲覧できるので興味のある方はぜひ試してみてください!
プラン評価
オプティマイザからうけとった実行計画を手続き型のコードに変換してデータへのアクセスをおこないます。
インデックスってなに?
次に、カラム値による検索のパフォーマンスを改善する一手となるインデックスについて解説します。
インデックスの役割
インデックス(ファイル)とは、SQL実行におけるデータアクセスを効率化するために文字通り索引として利用されているDBMS内部のファイルです。
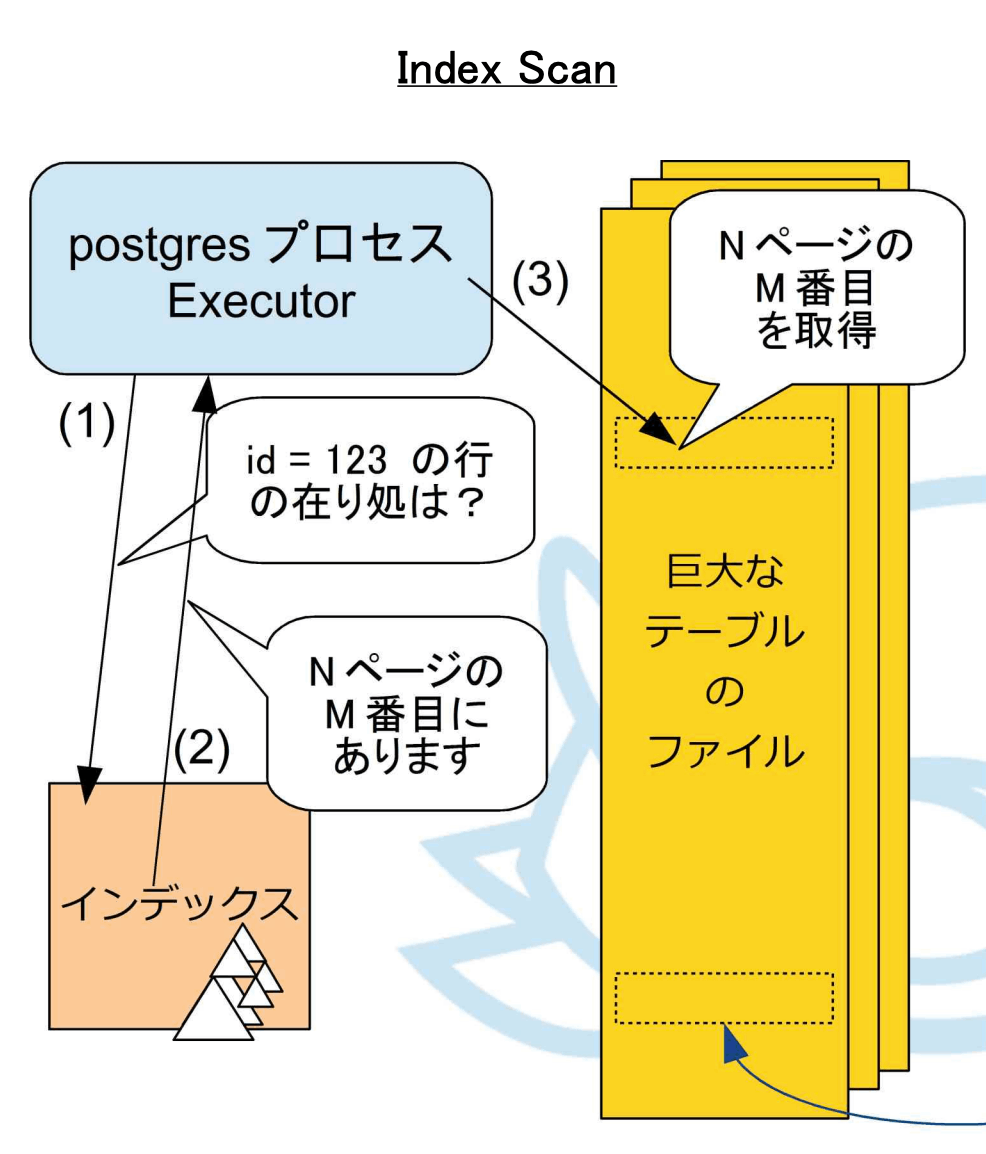
画像:「PostgreSQL SQLチューニングの基礎」より
CREATE INDEX "XXXX" ON "table_name" ("column_name"); のようなSQL文によってインデックスが貼られたカラムでデータ検索をおこなう際に利用されるもので、postgresプロセスがインデックスファイルにキー値を問い合わせると、そのキー値を持った実データのテーブルファイルにおける座標(ポインタ)を返します。
インデックスから実データの座標を得たpostgresは、晴れて一発でテーブルファイルの目標のレコードにアクセスすることができるようになります。
インデックスの仕組み(例:B-treeインデックス)
インデックスにはいくつか種類がありますが、その中で最も頻繁に利用される[1]ものが「B-treeインデックス」ですので、インデックスの代表としてB-treeインデックスの仕組みを解説します。(typeORMでは多分B-treeインデックスしか使えない?)
B-treeインデックスでは、以下のようなソート済みのツリー構造のデータがインデックスファイルに格納されており、ここから二分探索の要領でキー値から実データのポインタを検索します。
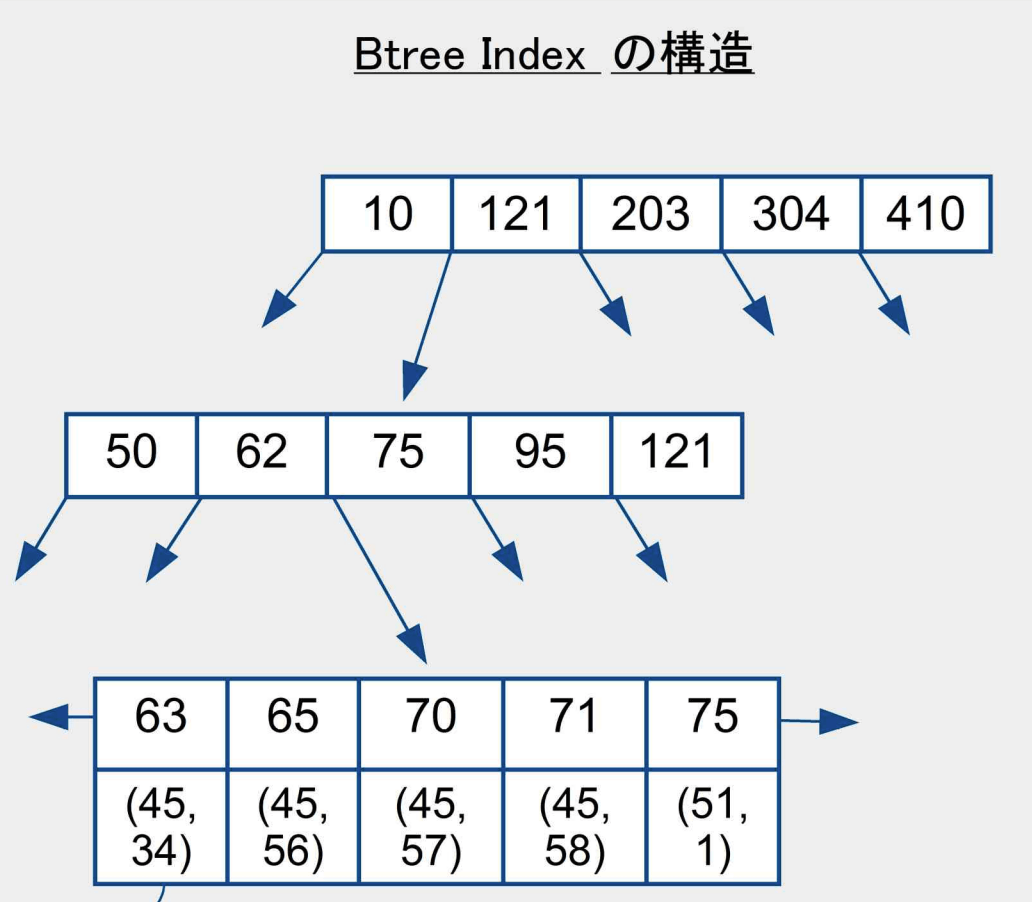
画像:「PostgreSQL SQLチューニングの基礎」より
例えば、carsというテーブルがあり、その中でprice=70なレコードを探す場合に上記のような探索ルートになります。なお、10,121,203,...といったツリーを構成する値はすべて、carsテーブルに実際に存在するレコードがpriceカラムに持つ値の集合です。
計算量は二分探索と同様に O(log(n)) となります。(nはテーブルに含まれるレコード数)
インデックスを利用した場合のパフォーマンスへの影響
レコード数が増えるほど線形探索(シーケンシャルスキャン)よりも計算量が優位になる
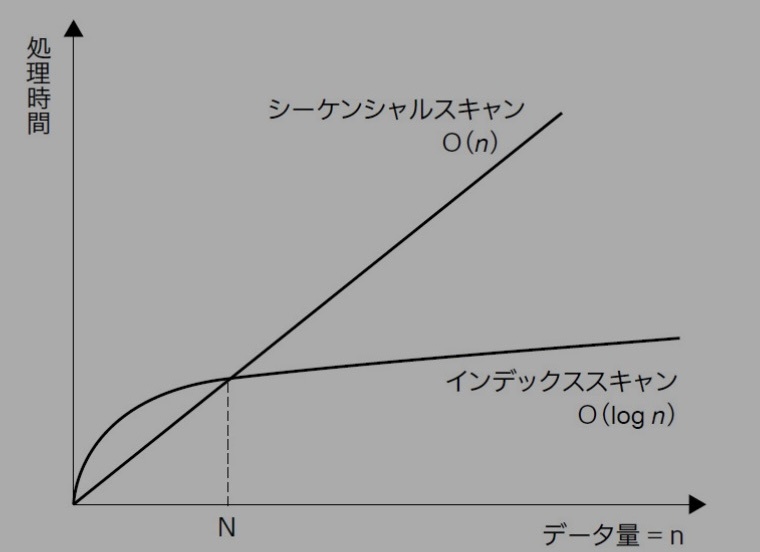
画像:SQL実践入門 ──高速でわかりやすいクエリの書き方 WEB+DB PRESS plusより
前述したようにB-treeインデックスを利用した場合の計算量はO(log(n))に抑えられる一方、シーケンシャルスキャンはO(n)のため、レコード数が増えてもインデックススキャンは性能劣化が非常に緩やかになるという特長があります。
インデックスは更新性能を劣化させる
インデックスをはることはメリットばかりではありません。
基本的にインデックスはテーブルとは独立したオブジェクトとしてDBMS内部に保持されています。そのため、インデックスが作成されているカラムの値を更新する際、テーブルファイルだけでなくインデックスファイルに保持している値も変更する必要があります。
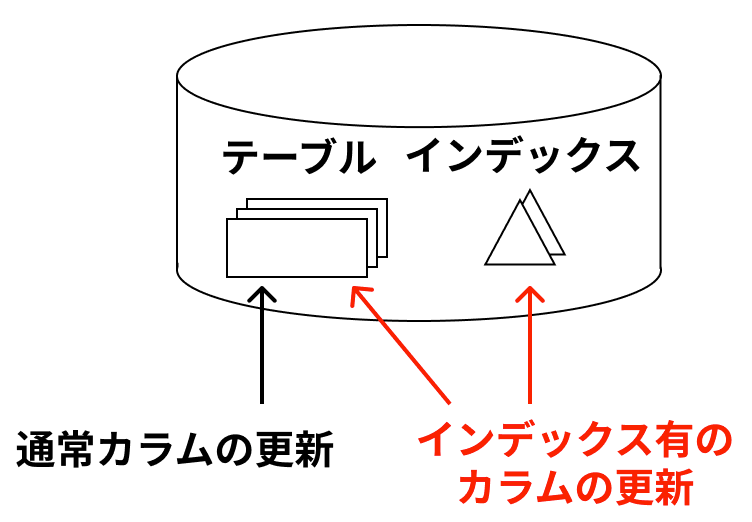
更新先のデータが増えることで単純に処理にかかる時間が伸びるため、無駄なインデックスは作成しないように注意しなければなりません。
どのようなカラムにインデックスをはるべきか?
ではどのようなカラムにインデックスを作成するべきなのでしょうか?
それは、一般的に以下の3つを満たすカラムだとされています。
- レコード数の多いテーブル
- カーディナリティの高いカラム
- SQL文でWHERE句の選択条件or結合条件に使用されているカラム
実際に実行計画を見てみよう
実行計画とインデックスとはなにかを理解したところで、ここからは実際に実行計画を見ていこうと思います。
実行計画1: インデックスを使わない検索
EXPLAIN SELECT * FROM users WHERE gender = 'MALE';
上記のようにクエリ文頭にEXPLAIN句をつけると実行計画を表示することができ、出力はこんな感じになります。[2]
Seq Scan on users (cost=0.00..10.81 rows=7 width=261)
Filter: ((gender)::text = 'MALE'::text)
各要素を説明すると、
-
Seq Scan on users: usersテーブルに対してシーケンシャルスキャンを行っていることを表します。この処理の最小単位を「計画ノード」と呼びます。 -
cost=0.00..10.81: クエリのコストを表します。はじめの0.00が1行目を返すまでのコストで、10.81が全行を返すまでのコストです。(単位はなし) -
rows=7: クエリが処理する行数です。 -
width=261: 結果の各行が占めるバイト数を表します。今回は261バイトです -
Filter: ((gender)::text = 'MALE'::text): 行の選択条件を表します。今回はWHERE句と同一のフィルタ条件になってます。
ここで、postgreSQLで出現する主要な計画ノードを紹介します。
| 計画ノード名 | 動作 |
|---|---|
| Seq Scan | テーブルの全件読み取り |
| Index Scan | インデックスを利用した読み取り |
| Nested Loop | 二重ループによるテーブル結合 |
| Hash Join | ハッシュによるテーブル結合 |
| Merge Join | ソート済みデータのテーブル結合 |
| Sort | 並べ替え(ORDER BY句) |
| Hash Aggregate | ハッシュを使用した集約(GROUP BY句) |
実行計画2: インデックスを使う検索
実行計画1の場合と同じようにusersテーブルにて検索を行いますが、今回はインデックスを作成済みのカラムkanaを条件に指定してみます。
EXPLAIN SELECT * FROM users WHERE kana = 'きたのたけし';
↓@Indexのデコレータがついてます
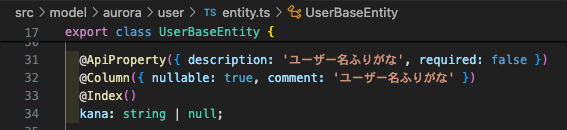
この場合、実行計画は以下のようになります。
Index Scan using "IDX_2dd975e8a6f46ea1fa0c19ec9e" on users (cost=0.15..8.17 rows=1 width=261)
Index Cond: ((kana)::text = 'きたのたけし'::text)
インデックスを使用して検索がおこなわれていることがわかります。
実行計画3: インデックスを使った結合
最後に、結合を含むクエリの少し複雑な実行計画を見てみましょう。
例えば、2つのテーブルarticles usersを結合する場合、
EXPLAIN SELECT * FROM articles INNER JOIN users ON (articles.user_id = users.id);
上記のようにクエリ文頭にEXPLAIN句をつけると実行計画を表示することができ、こんな感じになります。
Merge Join (cost=166.65..769.23 rows=19723 width=1158)
Merge Cond: ((articles.user_id)::text = (users.id)::text)
-> Index Scan using "IDX_8956d969e13ae50074afaf9030" on articles (cost=0.29..3430.97 rows=19723 width=487)
-> Sort (cost=166.36..170.37 rows=1603 width=671)
Sort Key: users.id
-> Seq Scan on users (cost=0.00..81.03 rows=1603 width=671)
なお、articlesテーブルのuser_idにはインデックスが作成されています。
結合処理になると、ネストがはいってきて分かりにくくなりますね。
この実行計画は計画ノードだけに注目するとこのような構造になっています。
Merge Join
↳ Index Scan
↳ Sort
↳ Seq Scan on users
Merge Join はソート済みのテーブル同士を上から順に比較して結合していく方式です。
実行順序としては上から順にネストの深い計画ノードから処理されるので、
Index Scan → Seq Scan on users → Sort → Merge Join というフローです。
なお本来の処理としては、
- articlesテーブルをソート
- usersテーブルをソート
- ソート済みのarticlesテーブルにusersテーブルの要素を結合していく
というステップが必要ですが、インデックスはそもそもソート済みなのでその工程がスキップされてインデックススキャンだけで済んでいます。
終わりに
以上の実行計画・インデックスのイメージが湧いていると、どういう場合にインデックスを使えばよいのか丸覚えではなく状況に合わせて判断したり応用が効くのではないかと期待して記事を書いてみました。
また、本記事はパフォーマンスチューニングの基礎となる知識だと思いますので、今後はDBMSが効率的でない実行計画を提示してきていないか、という視点で改善の糸口を探せるようになりたいと思います。
参考資料
SQL実践入門 ──高速でわかりやすいクエリの書き方 WEB+DB PRESS plus
達人に学ぶDB設計 徹底指南書
SQL チューニングの基礎(YouTube動画です)
-
他のインデックスの種類としてはBitmap, Hash, GINなどがあります。 ↩︎
-
もちろん
EXPLAIN (FORMAT JSON)...で出力し、https://explain.dalibo.com/ などで可視化するのも良いですが、個人的には生の実行計画を見るほうが手軽だと思うのでこの方法を紹介しています! ↩︎

Discussion