OctoparseでスクレイピングしたデータをElastic Cloudにインポートしたときの覚書き
自前のWeb検索エンジンを作る練習として、note.comの記事をクローリング&スクレイピングして、Elasticsearchにアップロード&インデックス作成し、検索できるようにしようとしています。Scrapyを使ってMongoDBに保存したり、ダイレクトにElasticsearchに送信&インデックス作成させる方法もあるのですが、諸々とめんどうが多かったので一旦スクレイピングSaaSであるOctoparseを使ってスクレイピングしたデータを、CSVとしてエクスポート。Kibanaを使ってアップロードしインデックスを作成しました。その際のハマりどころなどの覚書きです。
準備段階
1.日付の変換
例えば日付が年月日の場合、Elasticはdate型と認識できないためCSVファイルをExcel(もしくはNumbers)で開いてyyyy-MM-dd HH:mmなどのデータ形式に変換してやる。後述するがこれをデータ整形の後にやってしまうとExcel(Numbers)がダブルクォーテーションを消し去ってしまってエラーになるので、データに改行など不要な文字が入っている最初の段階でやるべし。
2.データの整形
意図せず入ってしまった改行や空白の削除をする必要があります。
Octoparseでやる方法
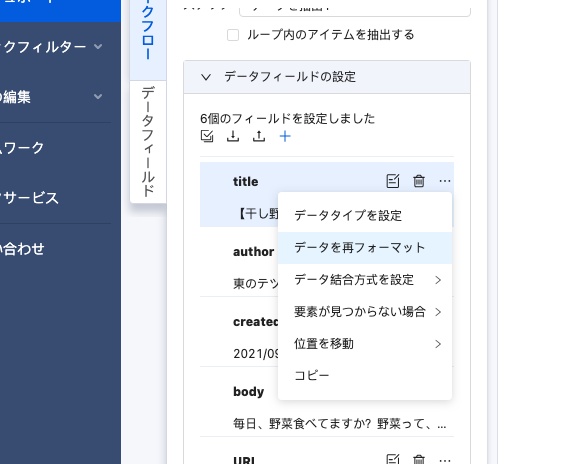
後から気づいてしまったが、Octoparseでのスクレイピング時に「データを抽出」のワークフローの設定項目からデータを再フォーマットできた。ここを使えばデータの整形は必要ない。
手動で置換して整形する方法(現実的でない)
Scrapyなど自前でスクレイピングツールを用意する場合でも、データ整形はクローリング後ではなく、クローリング中に都度改行や空白文字の削除、date型の変換などをやるべきで、後から正規表現でやろうとすると普通に間違ったりハマったり、検索と置換にパソコンが重くなりすぎて非効率過ぎる。が、一応、手動で正規表現を使って置換したのでそのメモとして残しておく。
サンプルデータ
こんな感じでダブルクォーテーションの後に改行や空白文字が入っている。
title,author,created_date,body
"
今日の日記123話
","
田中太郎
",2021年9月16日 19:00,"今日はこんなことがあってあんなことがありました。
そういえばほげほげ
うんたらかんたらです。
"
"
僕のグルメ日記154話
","
山田次郎
",2021年9月14日 00:23,"今日はハンバーグをうんたらかんたら
注意点
なお日付やURLにはダブルクォーテーションはつかないので注意。またメタディスクリプションもダブルクォーテーションはつかないっぽくここが難しい‥。さらに最後の列が空白かつテキスト以外の場合(メタキーワード等)は以下のようにドキュメントの末尾がカンマで終わる。
title,author,created_date,body,url,description,keyword
"今日の日記","田中太郎",2021-09-21 16:33,"今日はいい天気でした。",https://note.com/taro/112,今日はいい天気で,
Regexで置換
## STEP1. データの右端
改行1回以上の後にダブルクォーテーション+カンマ→改行だけ削除
\n+",
→",
空白1回以上の後にダブルクォーテーション+カンマ→空白だけ削除
\s+",
→",
## STEP2. データの左端
ダブルクォーテーションの後に改行1回以上、次の文字がダブルクォーテーション以外(ドキュメントの最後は改行を残したく、ここはカンマがつかず`"→改行→"`と連続するので以下で置換を避けることができる)
"\n+[^"]
→"
空白を削除
"\s+
→"
## STEP3. データ中の改行を削除
直前が(ダブルクォーテーションorカンマ)で始まっていない改行を削除(直前がダブルクォーテーションorカンマだとそれはドキュメントの末尾)
[^,"]\n+
→
役に立ちそうな正規表現
他にCSVデータを置換していくときに役に立ちそうな正規表現をメモがてら貼っておく。
## すべての改行
\n
## すべての空白文字
\s
## 直前がダブルクォーテーションで改行1回以上
"\n+
## 直前がダブルクォーテーション以外で、改行1回以上
[^"]\n+
## 両端ダブルクォーテーション、改行1回以上、(改行orダブルクォーテーション)以外1文字以上
"\n+[^(\\n")]+"
## ダブルクォーテーション以外で終わって改行
[^"]$\n
## 直前が改行orカンマ、両端ダブルクォーテーション、中身はダブルクォーテーション以外の1文字以上
[\n,]"[^"]+"
データの左端を詰める
"(\s*)?\n(\s*)?
右端を詰める
(\s*)?\n(\s*)?"
改行を全削除
(\s*)?\n(\s*)?"
Elastic にインポート
公式ブログ
やり方自体は公式がブログを書いてくれています。
Upload fileでエラー
CSVデータとしてupload時にエラーになったり、import成功してもドキュメントが0件だったりする場合、まず以下をチェックしてみよう。
- 改行や改行文字
\nが入っていないか - 1行1ドキュメントになっているか(最後のpropaertyで改行されているか)
- 日付は
yyyy-MM-dd HH:mmのように対応したフォーマットか(年月日などになってないか) - データの途中にダブルクォーテーション(
")が入っていないか
特にimportをしてもドキュメントが1つもインデックスに登録されない(Documents ingestedが0)場合は、改行が入ってないかよく見て(数時間ハマった)。
Error: File structure cannot be determined
上記のデータ整形を行っても日付がdate型として認識されないとか、「File structure cannot be determined」というエラーがでたりする。もう嫌になりそう。
Override Settingsでtimestampの形式を明示的に指定してもやはりダメ(本来は自動でdate型と認識されるはず)。
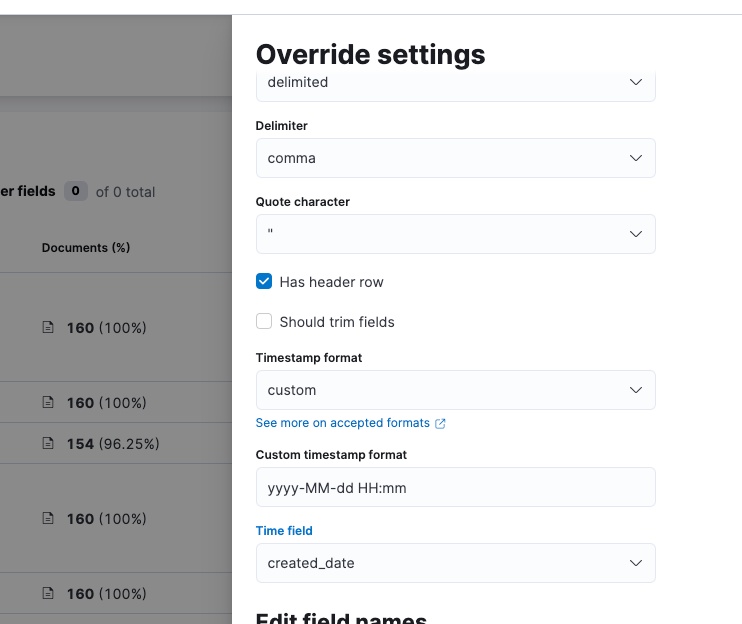
Specified timestamp format [yyyy-MM-dd HH:mm] does not match for record
この原因は日付は年月日→yyyy-MM-dd HH:mmという形式にExcel(Numbers)を使って変換したが、その際にダブルクォーテーションが消し去られてしまったことによる。以下のブログに答えがあった。
フィールド値の中にカンマ「,」が使われていたり、折り返し(改行)を含むテキストデータなど、CSV のデータ区切りを混乱させる文字がある場合を指します。 タイプ2は、このようなフィールド値があったときのみ、データの境界を明確にする目的で、ダブルクォーテーション囲みをします。
https://www.shegolab.jp/entry/windows-csv-quote-all
なので先に改行を消してしまってから日付を変換すると、CSV書き出し時にExcel(Numbers)がダブルクォーテーションを消し去ってしまうのだ。余計なことを!
以下の正規表現による置換でいい感じになった。
(.*?)(,|\n)
→"$1"$2
Create Index Pattern について
公式ブログではチェックを外しているが、Index Patternを作らないとDiscoverでドキュメントを閲覧できない。typeを変更する場合でもCreate Index Patternしてしまっていいかは検証中。
その他
ndjsonでのアップロードを試しましたが、こちらはインデックスは作成できるものの、typeがkeywordになってしまい検索ができなくなります。mappingは後から変更不可なのでndjsonで事前に指定する方法があるはずですが、、わからない。。
まとめ
Elasticsearchは正直すごく複雑だと思います。数日触っても一向に進まないことも多い。ただAlgoliaと比べてKuromojiやMecabなどの日本語形態素解析?に対応できたり、検索精度がプロダクトの肝になる場合はこれが良いようです。Elasticsearchのサポートの人たちも、最初はかなり学習コストが高い(が慣れれば高度なことができる?)と言っていましたので、少しずつ知見をためつつやってくしかなさそうです。またOctoparseも手軽ですがドキュメントがしょっちゅう変わったり動作が不安定だったりするので、早い段階で自前のクローリング&スクレイピングツールに移行するべきと思いました。
Discussion