【AI動画生成】Animate Anyone 論文解説
はじめに
11月も終わり、今年も残るところあと一か月となりました。
今年ももう終わるから今年中に成果を上げとけ!と言わんばかりに最近は新技術の登場が多いです。
今回取り上げるのも11月最後の大砲として出てきた新技術、その名もAnimate Anyone
Animate Anyoneとはなんぞや
文字で説明するより見たほうが早い
凄くざっくり説明すると、一枚の絵と動きをボーン動画として入力すると、入力した絵がボーン動画と同じ動きをしてくれるよ!というもの。
似たようなものは今までもReferenceOnly × openpose × animatediffとかで出来ましたが、特筆すべきはその精度。
動画生成の大敵であるちらつきは一切なく、入力画像にかなり忠実な動画を生成しています。
さてこの技術、動画生成にずっと注目している自分としてはいますぐにでも弄り倒したいのですが、残念ながらコードとモデルがまだ公開されていません。
論文は公開されているので、コードとモデルが公開されるまでの前準備として、今日は発表された論文の解説をしていきたいと思います。
論文解説
元論文はこちら(https://arxiv.org/pdf/2311.17117.pdf)
概要
Animate Anyoneは、キャラクタ画像を、所望のポーズシーケンスによって制御された動画に変換する手法。
事前学習された重みとしてStableDiffusionの重みを継承しており、Denoising Unetをマルチフレーム入力に対応するように改造している。
また、参照画像の詳細な空間的特徴(多分各要素の位置情報?)を補足する(StableDiffusionのDenoising UNetと同じ構造をした)UNet構造として、新しく設計したReferenceNetを導入。
UNetブロックの対応する各層で、Spacial Attention層を用いてReferenceNetが入力された画像から抽出した特徴をDenoising Unetに結合している。
これにより、モデルは参照画像との関係を包括的に学習することができ、外観の詳細保存の改善に大きく寄与するとのこと。
他にも、ポーズ画像での動画生成の制御性を確保するために、ポーズ制御信号をノイズ除去プロセスに効率的に統合するPose Guiderを提案している。
とまあいろいろ書いたんですが、ざっくり説明すると以下の3つが提案手法の肝です。
- ReferenceNet: 入力した参照画像からかなり詳細な特徴を抽出してノイズ除去UNetに渡してくれるUNet。ReferenceOnlyみたいなもん。
- Pose Guider: ポーズ動画から特徴を抽出して、画像生成時にポーズに沿うように制御してくれるやつ。ControlNetみたいなもん。
- TemporalLayer(名前は後で出てくる): マルチフレームの入力を可能にして、フレーム間の動きを自然に補完してくれる機構。animatediffみたいなもん。
モデル構造
ここから本題。上で紹介した3つの機構について詳しく見ていきましょう。
モデル全体
全体のモデル構造はこちら
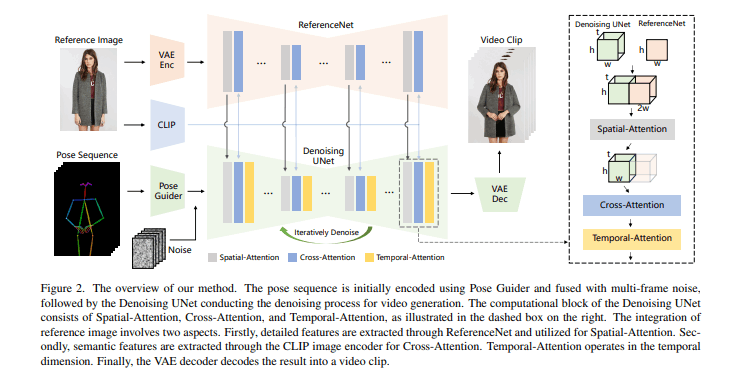
[出展: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for
Character Animation(https://arxiv.org/pdf/2311.17117.pdf) P3]
全体の構造として触れておくべきことは、このモデルがStableDiffusionに準拠している事(おそらく論文で紹介されていたUNetの構造的に1.x系のモデル構造を想定している)
そのため、既存のLoRA、基盤モデルがそのまま使える可能性がある(一方で使えない可能性もあり、その理由は後述)
改造方法も比較的簡単なため、おそらくモデルが公開されたら翌日くらいにはWebUIの拡張機能が作られていそうなほどシンプルな構造をしている。
それではモデルを構成している各要素について詳細を見ていきます。
ReferenceNet
入力画像の特徴を保持するうえで重要な働きをする部分。
いままでの画像→動画変換技術は、CLIPエンコーダをテキストエンコーダの代わりとして採用している。(テキストプロンプトの代わりに、画像をCLIPでエンコードしたものを使ってるよね、という意味だと思われる)
ただし、この方法だと画像の詳細な特徴がほとんど失われてしまうという事が指摘されている。
理由は二つあり、
一つはCLIPに入力される段階で、画像が224×224の低解像度に変換されてしまい細かい特徴が落ちる事。
もう一つは、CLIPがテキストの意味的特徴にマッチするように訓練されているため、エンコーディング内の詳細な特徴が欠落してしまう点。
上記の問題を解決するため、Animate AnyoneではCLIPエンコーダの代わりに新しく設計したReferenceNetを使っている。
ReferenceNetは、Denoising UNet(ここでいうDenoising UNetはStableDiffusionのものではなくAnimat Anyoneのものっぽい)とほぼ同じ構造をしている。唯一違う点として、TemporalLayerという時間特徴を保持する層をReferenceNet側は持っていない。
ReferenceNetは学習時、初期の重みとしてStableDiffusionの重みをそのまま使っており、重みの更新はそれぞれ独立して行っている(ここがちょっと懸念点。ここでSD側の重みも更新している場合は既存のモデルと組み合わせられない可能性がある。単純にSD側の重みを凍結してReferenceNetだけ学習すればいいんじゃ?という気もするがそれだとうまく学習が進まないのだろうか)
続いて、学習したReferenceNetとDenoising UNetはどうやって接続するの?というお話。
元のSDではSelf Attention層を使っている部分をSpacial Attention層に置き換えているらしい。(画像のtはおそらくフレーム数。ここでReferenceNetが抽出した特徴を全フレームの生成に使いまわしているので、ReferenceNetの処理は一回で済み、ControlNetのようにフレーム毎に特徴を抽出しなくてよいっぽい)
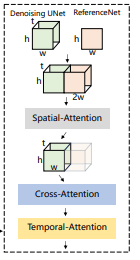
また、CLIPの画像エンコーダを用いたCross Attention層を採用することで、位置情報だけではなく参照画像の意味的な特徴も利用できるとのこと。
Pose Guider
ControlNetの代替。
ControlNetはテキスト以外にも条件生成能力を示す(OpenposeとかCannyとかの画像入力を受け付けられる)が(Animate Anyoneの)Denoising UNetをFineTuningして同じことをしようとすると膨大な計算力が必要になるため、今回は採用を見送ったとのこと。
代わりに採用されたのがこのPose Guiderで、4つの畳み込み層(4×4 kernels, 2×2 strides, using 16,32,64,128 channels)で作られている。
これはほぼControlNetのcondition encoderとおなじらしい。
(多分ここのことを言っている)
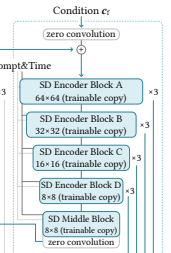
[出展: Adding Conditional Control to Text-to-Image Diffusion Models(https://arxiv.org/pdf/2302.05543.pdf) P3]
Pose Guiderを通ったポーズ画像は、Denoising UNetを通る前にnoise latent(いつもの初期ノイズ)に追加される。
Temporal Layer
時間特徴を拾うやつ。
ビデオフレーム間の時間依存性を捉えている層。
Temporal LayerはAnimateDiffを参考に作られている。
この辺の細かい説明は割愛。
Temporal Layerから抽出された特徴は、残差接続によって元の特徴(ReferenceNetとSDの特徴を合成した後の特徴?)に組み込まれる。
Temporal LayerはDenoising UNetのRes-Transブロックにのみ適用している。
面白い点として、ReferenceNetは時間的な特徴に一切関与しておらず、動画としての滑らかさはこのTemporal Layerが全て担っているとのこと。
訓練
訓練は二段階に分けて実施。
一段階目は、Temporal Layerを取り除いて、学習データも複数フレームではなく、一枚の画像のみで学習。
学習の対象はReferenceNetとPose Guiderで、VAEのエンコーダとデコーダ、およびCLIP画像エンコーダの重みはすべて固定された状態で学習を行う。(SDの既存の重みは多分更新される)
一段階目の学習の目的は、与えられた参照画像とポーズ画像から、高品質のアニメ画像をモデルが生成できるようにすること。
第2段階では、Temporal Layerを導入して学習を実施。
モデルの入力は、24フレームのビデオクリップで構成れていて、Temporal Layer以外の全ての重みを固定し、Temporal Layerだけを学習している。(この学習方法により、時間特徴量の残差接続が効いてくるらしい)
弱点
大きな弱点は3つ
- 画像生成モデル全般に言えることだけど、手の動きの再現は苦手。
- 参照画像が一つの視点からしか提供されない(一枚しか入力しない)ので、参照画像に映ってない部分の動きは不安定になる
- DDPMベースのアーキテクチャなので、非拡散モデルベース(GANとか?)と比較して演算効率が悪い。
終わりに
以上、たぶん日本一(?)早いAnimate Anyoneの解説記事でした!
モデルとコードが展開されるのが楽しみですね!
Discussion
こんにちは、初めまして(?)
この論文さっき読んだばかりなんですが、
Temporal Layer と Temporal Attention (黄色い四角)は同義としてとらえていいのか気になったんですが、どうなんでしょう?
多分同じものとしてみて良いと思います!(正確には包括している?)
AnimateDiffを参考にして作った~の部分で
"""
Specifically, for a feature map x∈R
b×t×h×w×c
, we first reshape it
to x∈R
(b×h×w)×t×c
, and then perform temporal attention,
which refers to self-attention along the dimension t.
"""
と書かれてるので、この一連の処理をTemporal Layerといっているのかなと!
ありがとうございます。どうやら、Temporal Layer は Attention + フィードフォーワード (≈ TransformerのEncoder のような構造) と解釈していいのかなと、調べたりいろんな方の意見を聞いて判断しました。どっちにしろコードが Comming Soon なので、いずれ出てきた時に判明するでしょうと思いました