Magic animate論文解説
世の中の進みが早すぎてついていけません
はじめに
Animate Anyoneが出てきて数日、まだコードもモデルも公開されていないうちに新しい高精度動画生成手法が発表されました。
名前はMagic animate、TickTok運営元が研究開発した生成モデルとのこと。
しかも今回はモデルもコードも公開されており、すでに誰でも触れる状況にあります。
僕も早速弄り倒そうかと思ったのですが、モデルインプレは別に僕がやらなくても誰かが書くだろうと思い直したので、とりあえず論文から読もうかなと思います。
という訳で今回も速報論文解説をやっていきます(論文紹介の味を占めただけ)
元論文はこちら(https://arxiv.org/pdf/2311.16498.pdf)
論文解説
概要
この研究は、ある特定の動作シーケンス(デモ動画見る限りはセグメント情報を主に使っていそう。ただ機構的にいろいろな動作シーケンスへ応用が可能っぽい)に従い、かつ参照画像の特徴に忠実なビデオ生成が目的。
既存手法は時間的モデリングの欠如と参照画像の保存が不十分なため、アニメーション全体を通して時間的一貫性を維持出来ていないという課題に直面している。
上記の課題に対応するため、時間的一貫性を高めることを目的とした拡散ベースのフレームワークであるMagicAnimateを開発した。
研究の肝は以下2点
①参照画像に忠実なアニメーション生成を行うために、時間情報を符号化するビデオを拡散モデルを開発
③フレーム間の一貫性を維持するために、新しいappearance encoderを導入
ちらつき対策
既存の拡散モデルベースの手法だと、フレーム単位で独立に処理する(各フレームをi2iで処理するイメージ?)ため、いわゆる「ちらつき」が発生します。
この提案手法では、「ちらつき」対策として動画拡散モデル(Temporal Consistency Model)を新しく構築しています。
参照画像に忠実な動画生成
おそらくこちらがこの論文のメイン。
既存手法では、参照画像をCLIPに通してエンコードするが、これは意味レベルの情報圧縮になるため、複雑な情報を捉えるには不足しているとのこと。これはAnimate Anyoneでも同じことが主張されてましたね。
Animate Anyoneでは、この対策としてReference Netを導入したのに対し、Magi animateではappearance encoderを導入しています。
仕組みの解説
それでは、論文を構成する主要な二つの機構について説明していきます。
全体的な構成図はこちら。

[出展:MagicAnimate: Temporally Consistent Human Image
Animation using Diffusion Model
(https://arxiv.org/pdf/2311.16498.pdf)]
temporal consistency modeling
この部分の肝はtemporal attention layersを導入することで、既存の拡散学習モデルが取り扱っている2DUNetから3DUNetへ拡張しています。
基本的な考え方はAnimateDiffやAnimate Anyoneと同じみたいですね。(Anymate Anyoneの方が、Animatediffと同じ仕組みを採用していて、学習も転移学習で済ませていたためそちらの方が筋が良い気もする)
ただし、Magic animateは他二つと比較して大きく違う部分が一点あります。
それがDensePoseシーケンスも一緒にtemporal attention layerで学習している部分。
他の二手法は、動作の一貫性を司る部分と、表現する動作を支持する部分が完全に切り離された構成だったのに対し、Magic animateはTemporal Layerで両方学習しています。
そのため、Magic animateはContorolNetのようにシーケンスの互換性がなく、DensePose以外のシーケンスを入力する場合は一から学習しないとうまく動きません。
(実際にopenposeで試した方のツイートがこちら)
appearance encode
ControlNetやReferenece Onlyのような参照画像の条件付けを行う機構。
具体的な手法としては、まずベースとなるUNet(普通のDenoising UNet相当)を作成し、ノイズ除去ステップごとに参照画像の特徴を抽出する。
このとき、抽出する特徴は中間ブロックとupsamplingブロックの正規化されたattention hidden statesが取り出され、抽出した特徴はspatial self-attention layersに渡されるとのこと。
はい、何言ってるのかわかりませんね。
細かく見ていきましょう、まずSDのDenoising UNetの構成を振り返ります。
SDのUNetはざっくりこんな感じの構成をしています。

この中間層とupsampling層から特徴を取り出すわけですね。
この時、中間層やupsampling層から取り出されるものがattention hidden states(隠れ状態)と呼ばれるものになります(多分)。
隠れ状態は層を通った後の中間出力だと解釈してもらえれば大体あっている気がします。
この中間出力をspatial self-attention layersに通し、その結果を元のDenoising UNetの隠れ状態に接続する、といった流れになっているようです。
spatial self-attention layersはAnimate AnyoneでいうSpacial Attention層に相当するもののようです。こちらもAnimate Anyoneの構造とよく似ています。
spatial self-attention layersの細かい説明は別記事を書こうかなと思っているのでここでは詳しい説明は省きます。
気になる人は以下のリンクにspatial self-attention layerの実装がのっているので、そちらを確認してもらえると良いかなと思います!
パイプライン
さて、上記で解説したtemporal attention layersとappearance encodeを組み合わせて学習を行います。
パイプラインはMotion transfer, Denoising process, Long video animationの3つに分かれているため、それぞれ分けて説明します。
Motion transfer
動作のガイドとなるシーケンス画像を反映する部分に該当します。
このあたりの部分ですね。

図にある通り、入力されたポーズ画像をControlNetのコンディショニング(条件付け)に変換し、中間層とアップサンプリング層に残差接続しています。
この処理はフレーム一つ一つに対し個別で行われるため、ビデオの長さ(フレーム数)分処理を行う必要があります。
ちなみにこの論文では入力されるポーズ画像に、良く使われるopenposeではなくDensePoseが用いられています。
論文著者もopenposeが良く使われていることは承知の上で、openposeは動作制御をするには情報が少なく、回転のような動き(体をひねるとか?)に対してロバストではないという報告がされています。
そのためDensePoseを採用したとのこと。
ただ、有志の方がデモ版を利用した結果をみる限りでは、生成される動画がDensePoseに引っ張られ過ぎており動画が破綻している物も多いため、今後この条件画像に何を用いるのがベストか?は深堀の余地がありそうです。
Denoising process
これはいつものdenoiseプロセスですね。
denoiseは、appearance encoderから得られるとappearance conditioningと、motion transferの項で触れたmotion conditioningによって制御されます。
Long Video Animation
temporal consistency modelingとappearance encoderを使うことで、
参照画像な任意の時間的一貫性のあるアニメーションを作ることは可能になりましたが、課題としてフレーム間の不自然な遷移や、一貫性が乏しいディティールの書き込みが発生するという課題が依然残っています。
そこで、ここでもMagic Animateは一工夫をしています。
この課題が発生する要因として、temporal attention blockが異なるセグメントの時間的特徴を認識する事ができないためと述べられています(ここで述べられているセグメントが何を指すのかが正直ちょっと不明。恐らく、一回の生成で一貫性を保って出力できるフレーム数に(animatediffの24フレーム制限のような)限界があり、長時間動画を生成する時は複数個の生成物を繋ぎ合わせる必要があり、その一つ一つをセグメントと読んでいるのではないかと思われる)
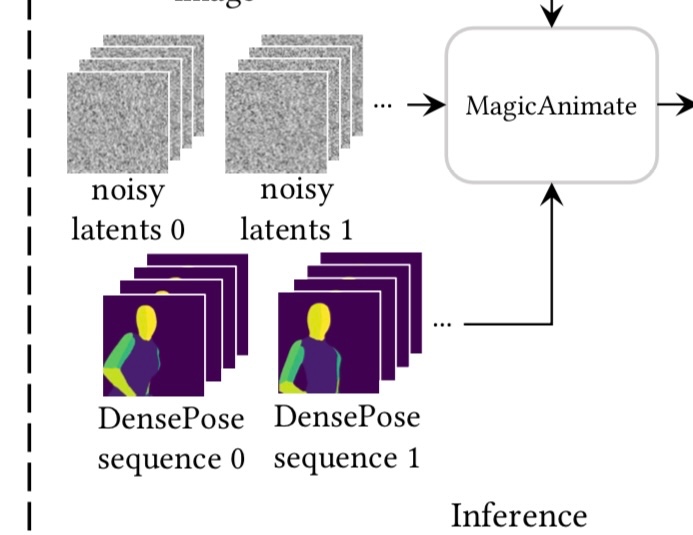
この課題に対処するために、sliding window method というものが導入されています。
sliding window method はまず、モーションシーケンス動画を複数のセグメントに分割し、各セグメントにオーバーラップ(フレームの重なり)が生まれるように結合し、重なっている部分は平均をとります。(平均を取る対象はデノイズのタイミングで予測された取り除くべきノイズ)
また、各セグメントは初期ノイズを全て同一にする事で、より一貫性を保った動画が生成できるとのこと。
こうする事で任意の長さの動画を生成できるようにしているみたいです。
訓練
Magic Animateでは多段階の訓練を行なっています。
ここの多段階訓もAnimate Anyoneと似ていて、第一段階ではTemporal attentionを飛ばして学習します。
ここでの学習ターゲットはappearance encoderとポーズcontrolnetで、同時に学習を行います。
第二段階では、こちらもAnimate Anyone 同様、temporal attentionのみを学習します。
おわりに
今回も簡単な論文解説を記事にしてみました!
こちらの論文はAnimate Anyoneと比べても結構複雑なことを行なっており、説明不足や説明が足りない部分、私の理解が間違っている部分も多いかなと思います。
今後もこの記事はアップデートしていこうと思いますので、まずは論文理解の最初の踏み台として使っていただければと思います!
今年の終わりまで残り1か月、どれだけ技術が進化するか楽しみですね!
Discussion