Diffusersを用いたControlNetの学習方法解説
はじめに
自作ControlNetの学習に挑戦してうまくいったので、改めてやりかたを整理します。
作ったControlNetはこちら
この記事で話す内容
- 学習環境の構築
- Diffusersで利用可能なDatasetフォーマットの作り方
- Diffusersを用いたControlNetの学習手順
この記事で話さない内容
- ControlNetとは何か
- Diffusersとは何か
- 学習データの作り方
学習手順
基本的には、DiffusersのControlNetの学習例に沿って進めていきます。
環境構築
今回はDiffusersのexampleに格納されているControlNetの学習コードをそのまま使うため、まずはDiffusersをGithubリポジトリからCloneしてきます。
git clone https://github.com/huggingface/diffusers.git
また、Diffusersをライブラリとしてインストールしていない場合は、ここでインストールを行います。
pip install git+https://github.com/huggingface/diffusers.git transformers accelerate xformers==0.0.16 wandb
huggingface-cli login
wandb login
学習結果をwandbで確認したい場合はwandbのインストールをし、ログインを行っています。
学習に必須ではないので、スキップしてしまっても大丈夫です(僕は今回スキップしました)
また、huggingface-cliへのログインも行っていますが、こちらは学習したモデルを自分のHFリポジトリに自動で上げる場合に必要になります。
ここについても、モデルをアップロードするつもりがなければ必要ありませんので、スキップしてしまっても大丈夫です。(後から学習したモデルを手動でアップロードすることも可能です)
続いて、ControlNetの学習に必要なライブラリをインストールします。
Diffusers -> examples -> controlnetに移動し、
pip install -r requirements.txt
コマンドを打つと、必要なライブラリがインストールされます。
Datasetフォーマットの作成
続いて、Diffusersで学習できるようにデータフォーマットを整備していきます。
ControlNetの学習には以下の3つのデータが必要となります
| # | データ種類 | データフォーマット | 学習データの例 |
|---|---|---|---|
| 1 | 正解となる画像データ | 画像 |  |
| 2 | 生成時のヒント画像 | 画像 | 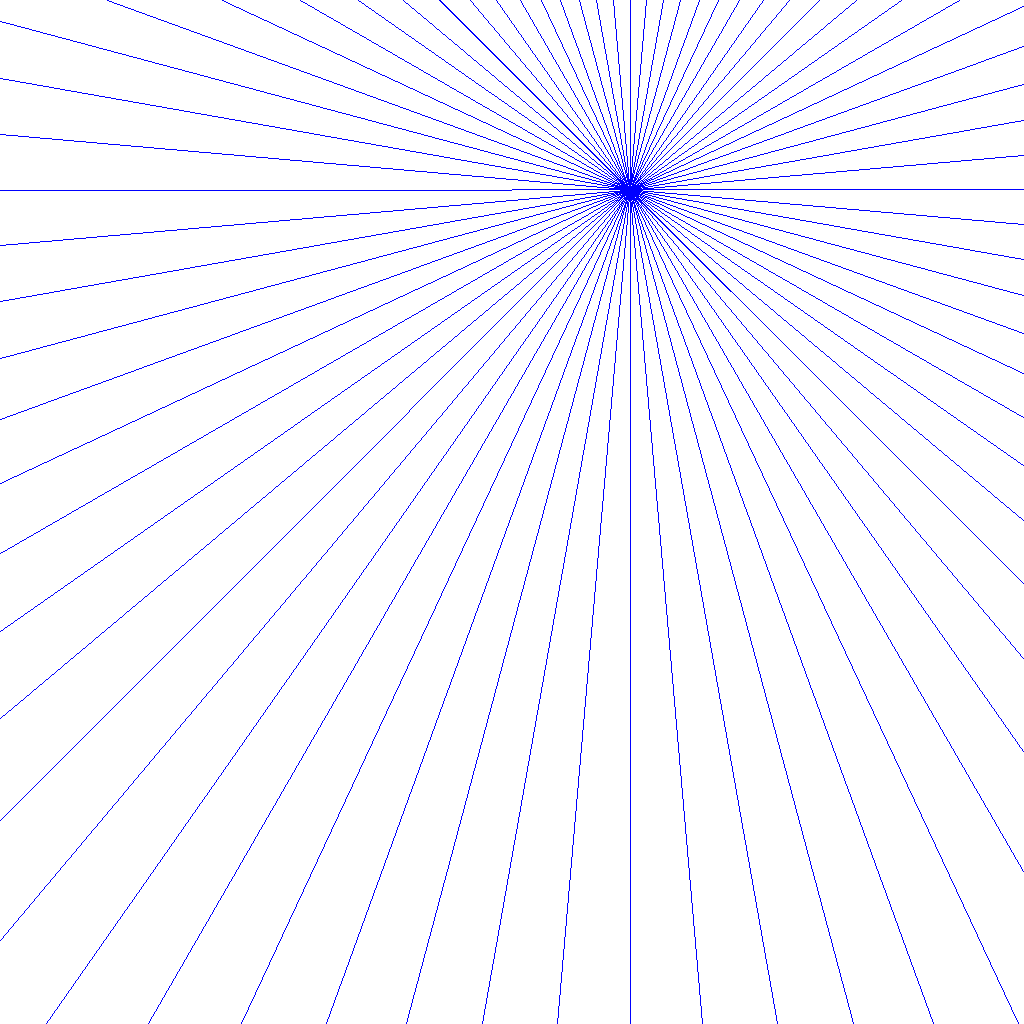 |
| 3 | 正解となる画像データのキャプション | テキスト | simple, single point perspective, one point perspective, anime, |
データセットを用意したら、以下のようにデータを配置します。
データセット格納フォルダ
├── image
│ └──xxxxx1.png
│ └──xxxxx2.png
│ └──xxxxx3.png
│
└── conditioning
└──yyyyy1.png
└──yyyyy2.png
└──yyyyy3.png
(※今回、僕はキャプションにすべて同じテキストを使ったので、キャプションはプログラム上で直接描きこんでいます)
ここまで準備ができたら、Datasetのフォーマットを作っていきます。
基本的には以下のページを参考にDatasetを作成します。
Datasetの作成には、Datasetsライブラリを用いるため、
pip install datasets
で必要なライブラリをインストールします。
また、DatasetをHFにアップロードする際にHuggingFaceにログインをしておく必要があるため、
huggingface-cli login
コマンドでログインを済ませておきます。
ログイン時にアクセスTokenを聞かれるので、
にアクセスし、ログイントークンを発行しておきましょう。
DatasetはHFにアップロードしなくても使えるようですが、ローカルでデータを読み込もうとするとうまくいかない場合が多いため、HFにアップロードして利用する事を強く推奨します。
(今回の記事でも、DatasetはHFにアップロードされている前提で進めていきます)
続いて、要したデータセットを読み込んでフォーマットを整えていきます。
フォーマットを整えてHFにアップロードするスクリプトがこちら
from datasets import Dataset, load_dataset
from huggingface_hub import HfApi, HfFolder
import os
from PIL import Image
def create_dataset_from_images(path):
"""
画像フォルダから画像のパスを読み込んでDatasetを作成する
"""
image_folder = os.path.join(path, "image")
conditioning_folder = os.path.join(path, "conditioning")
image = [Image.open(os.path.join(image_folder, f)) for f in os.listdir(image_folder) if os.path.isfile(os.path.join(image_folder, f))]
conditioning = [Image.open(os.path.join(conditioning_folder, f)) for f in os.listdir(conditioning_folder) if os.path.isfile(os.path.join(conditioning_folder, f))]
caption = ["simple, single point perspective, one point perspective, anime,"]*len(conditioning_paths)
dataset = Dataset.from_dict({'image': image, 'conditioning': conditioning, 'caption': caption})
return dataset
def upload_dataset_to_hub(dataset, dataset_name, organization=None):
"""
DatasetをHugging Face Hubにアップロードする
"""
# Hugging Faceの認証トークンを取得
api = HfApi()
token = HfFolder.get_token()
if token is None:
raise ValueError("Hugging Faceの認証トークンが見つかりません。huggingface-cliでログインしてください。")
# データセットをアップロード
if organization:
repo_id = f"{organization}/{dataset_name}"
else:
repo_id = dataset_name
dataset.push_to_hub(repo_id, token=token)
# 画像が格納されているローカルフォルダのパス
image_folder = 'input/your/path'
# Datasetオブジェクトを作成
image_dataset = create_dataset_from_images(image_folder)
# DatasetをHugging Face Hubにアップロード
upload_dataset_to_hub(image_dataset, 'データセット名', 'ユーザー名')
再度の注意となりますが、今回キャプションは全て同一のものを使っているため、コード内で簡易的に登録しています。
画像毎に異なるキャプションを設定する際は、適宜変更していただければと思います。
上手くいくと、このようにHuggingFaceの自分のアカウント内に新しいリポジトリができ、学習データがParquet形式でアップロードされます。
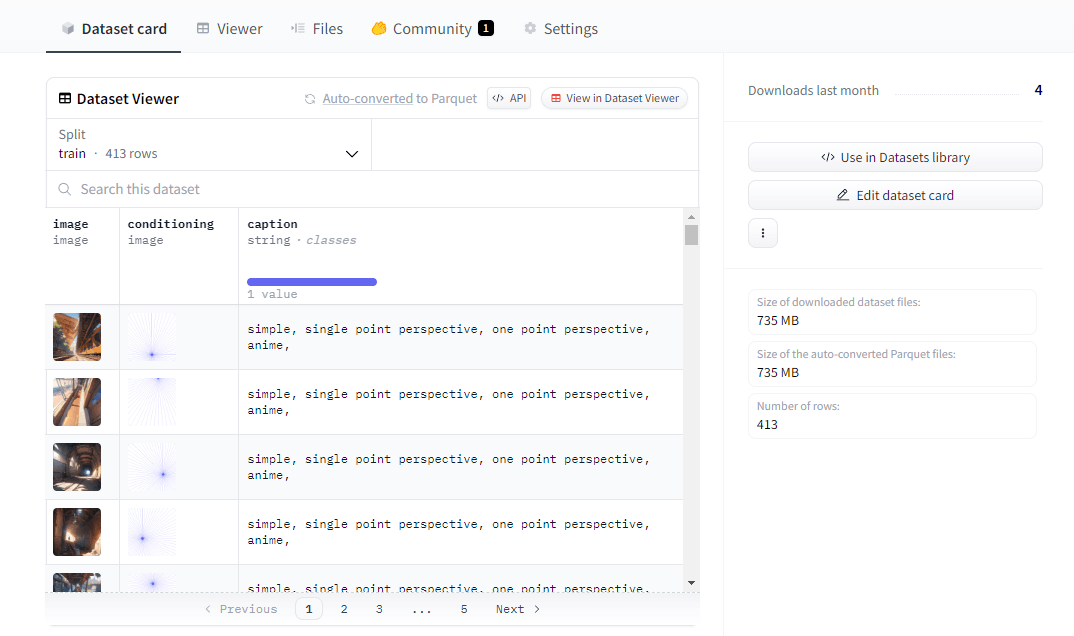
ControlNetの学習
ここまで準備ができたら、あとは訓練コードを動かすだけとなります。
再び、Diffusers -> examples -> controlnet 配下に移動します。
このディレクトリにある、train_controlnet.pyを叩くことで学習が始まります。
叩き方は以下
!accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="username/repositoryname" \
--output_dir="model_out" \
--dataset_name=username/repositoryname \
--conditioning_image_column=conditioning \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./test1.jpeg" "./test2.jpeg" "./test3.jpeg" \
--validation_prompt "prompt1," "prompt2," "prompt3," \
--train_batch_size=4 \
--num_train_epochs=10000 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000 \
学習結果をWandbで見る場合は --report_to wandb を
学習したモデルをHFに上げる場合は --push_to_hub を更にオプションに付け加えます。
追記(ローカルデータセットで学習を行う方法)
基本的には引き続きHF上にデータセットをアップロードする方法を推奨しますが、社内データなど公開が難しいデータを取り扱う場合もあると思われるため、ローカルデータセットを使って学習する方法も記載します。
まず、HFにデータをアップロードした手順と同様に、以下のスクリプトを実行します。
このスクリプトでは、作成したデータセットをHFではなく、ローカルに保存するように変更しています。
データセットを保存したPATHは次のステップで使いますので控えておきましょう。
from datasets import Dataset, load_from_disk
from huggingface_hub import HfApi, HfFolder
import os
from PIL import Image
def create_dataset_from_images(path):
"""
画像フォルダから画像のパスを読み込んでDatasetを作成する
"""
image_folder = os.path.join(path, "image")
conditioning_folder = os.path.join(path, "conditioning")
image = [Image.open(os.path.join(image_folder, f)) for f in os.listdir(image_folder) if os.path.isfile(os.path.join(image_folder, f))]
conditioning = [Image.open(os.path.join(conditioning_folder, f)) for f in os.listdir(conditioning_folder) if os.path.isfile(os.path.join(conditioning_folder, f))]
caption = ["simple, single point perspective, one point perspective, anime,"]*len(conditioning)
dataset = Dataset.from_dict({'image': image, 'conditioning': conditioning, 'caption': caption})
return dataset
def save_dataset_locally(dataset, save_path):
"""
Datasetをローカルに保存する
"""
dataset.save_to_disk(save_path)
print(f"Dataset saved to {save_path}")
def load_dataset_locally(save_path):
"""
ローカルからDatasetを読み込む
"""
dataset = load_from_disk(save_path)
print(f"Dataset loaded from {save_path}")
return dataset
if __name__ == "__main__":
# 画像パスからデータセットを作成
dataset = create_dataset_from_images("/path/to/your/images")
# ローカルに保存
save_path = "/path/to/save/dataset"
save_dataset_locally(dataset, save_path)
続いて、控えておいたローカルデータセットのPATHをフルPATHでdataset_nameの部分に記載します。
それ以外はHF上のデータセットを使う場合と変わりませんので、そのまま実行をします。
!accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir="model_out" \
--dataset_name= "your/localdataset/path" \
--conditioning_image_column=conditioning \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./test1.jpeg" "./test2.jpeg" "./test3.jpeg" \
--validation_prompt "prompt1," "prompt2," "prompt3," \
--train_batch_size=4 \
--num_train_epochs=10000 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000 \
パラメータ解説
- pretrained_model_name_or_path: ControlNetのベースとなるモデルを選択します(CNは変則的な追加学習のためベースが必要)入力形式はHFの「username/repositoryname」表記になります
- output_dir: 学習したモデルや、学習ログを出力するディレクトリの指定
- dataset_name: 学習に使うデータセットを指定します。ここに、先ほど作った学習データをHFの「username/repositoryname」表記で指定しましょう。
- conditioning_image_column: データセットの中で、ヒント画像を表すカラム(列名)を指定します
- image_column: データセットの中で、正解となる画像を表すカラム(列名)を指定します
- caption_column: データセットの中で、正解となる画像のキャプションを表すカラム(列名)を指定します
- resolution: 学習する画像の解像度を指定します
- learning_rate: 学習率を指定します(とりあえずデフォルトで良いと思います)
- validation_image: 学習モデルを途中評価する際に、入力となるヒント画像を指定します。
- train_batch_size: 一度に学習する画像の枚数(バッチ)を指定します(とりあえずデフォルトで良いと思います)
- num_train_epochs: 訓練回数を指定します。(学習にかなり時間がかかるので5万回くらいを推奨)
- tracker_project_name: モデル出力時に使用します(とりあえずデフォルトで良いと思います)
- enable_xformers_memory_efficient_attention: メモリ最適化の有効化
- checkpointing_steps: 学習中のモデルを途中で保存するタイミングの指定
- validation_steps: 学習中のモデルを途中で評価するタイミングの指定
評価
学習が進むと、model_outに指定したディレクトリにcheckpoint-xxxxxというフォルダができます。
この中に、tracker_project_nameで指定した名前のフォルダが入っています。
これが、学習結果が格納されたフォルダとなります。
実際に訓練したモデルを使用してみましょう。
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.utils import load_image
import torch
controlnet = ControlNetModel.from_pretrained("./model_out/checkpoint-xxxxx/controlnet", torch_dtype=torch.float16)
pipeline = StableDiffusionControlNetPipeline.from_pretrained(
"username/repositoryname", controlnet=controlnet, torch_dtype=torch.float16
).to("cuda")
control_image = load_image("./conditioning.png")
prompt = "positive prompt,"
generator = torch.manual_seed(0)
image = pipeline(prompt, controlnet_conditioning_scale = 1.0, controlnet_conditioning_scalenum_inference_steps=20, generator=generator, image=control_image).images[0]
image.save("./output.png")
無事、ヒント画像に沿った画像が生成されたら、訓練成功です。
おわりに
今回はDiffusersを用いたControlNetの学習方法について解説していきました。
意外とControlNetの学習をしている人が少なく、やり方を調べるのに手間がかかったので、ControlNetの学習に挑戦する際に参考にしていただければと思います!
Discussion