SAM PT×animatediffで生成した動画から自動でマスク動画を作る
今回の目的
動画でも画像みたく気軽にinpaintとかlama cleanerとか背景透過とか使いたい!
という訳で、今回はanimatediffやGen2などで生成した動画を、画像と同じようにinpaintとか背景透過とかできるようになる事を目指します。(今回の記事ではinpaintや背景透過までは踏み込まず、その前提となるマスク動画の作成までを解説します)
きっかけ
animatediff周りをいろいろ調べていた際に、こちらの記事を見つけました。
この記事では、animatediff×comfyUIでinpaintを行う方法が紹介されています。
たしかに、画像生成ではいまや当たり前のようにinpaintのような生成技術を用いた画像編集手法が使用されていますが、動画ではあまり使用された例を見かけない気がします。
この記事でも紹介されていますが、以下のツイートのようにinpaint等を組み合わせれば、より一貫性が高くかつ柔軟な表現が可能な動画作成にもつながるでしょう。
動画でinpaintや背景透過を行う難しさ
さて、すでにinpaintのやり方が記事として公開されているのであれば、わざわざ同じテーマを取り扱わなくてもよいのでは?となりますが、元記事ではinpaintを物体ではなく、領域に対して行っており、今回はここに焦点をあてて解くべき課題としています。
領域に対してというのは、inpaint(つまり生成しなおす)部分を画面のどの部分か?で指定し、その指定された領域に対して一貫した修正を行います。
一方で、物体に対して行うinpaintとは、例えば髪型を指定して生成しなおすであったり、特定の人物を別の人物に変換する等が考えられます。
さて、この場合難易度は後者の方が高くなります。
当然ですが、今回inpaintしたい対象は動画のため、書き換えたい対象が画面内を移動します。
フレーム単位で一枚ずつ修正していけば、動きがあっても修正可能かと思いますが、animatediffなどで生成される動画は、構成している画像数もかなりの数になるため、いちいち主導でやっていたらかなりのるうかなりの労力になってしまいます。
理想としては、静止画一枚で生成しなおしたい対象を指定したら、動画すべてでその対象となった物体/人物が一括で修正されてほしいですよね
そこで、今回は以下の技術を導入することにしました。
またSegment Anythingだよ
実は生成AIよりもSegment Anythingの方が触っているんじゃないかという疑惑がありますが、使い勝手が良いので仕方ない。
SAM-PT(Segment Anything Meets Point Tracking)は、7月頃に公開されたSegment Anythingの派生技術で、動画をセグメンテーションし、指定したオブジェクトをトラッキングしてくれる技術です。
まさに今回の目的にうってつけですね。
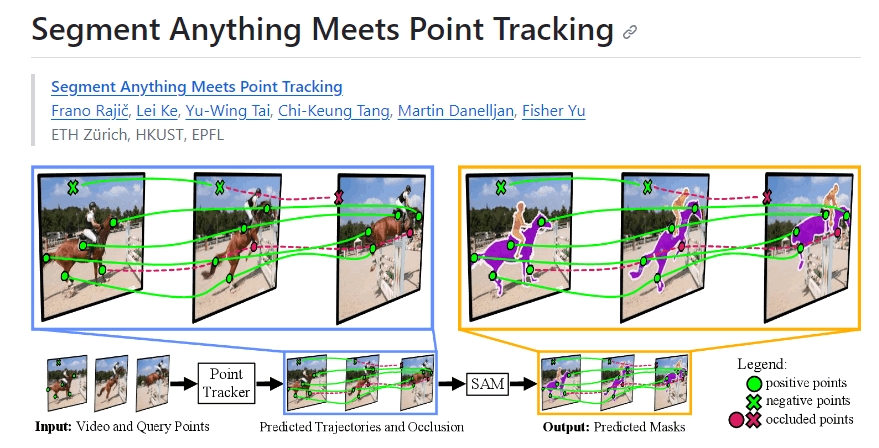
(出展: https://github.com/SysCV/sam-pt)
SAM-PTの導入
では実際にSAM-PTを使ってみましょう。
まずは、今回テストに使う動画をささっとanimatediffで作ります(animatediffでの動画の作り方は割愛)
今回は以下を使います。

では導入していきましょう。
基本的には以下の手順に従って導入していきます。
(今回はdemo部分しか使わないので、01-getting-started.mdだけ実行すればOK)
導入時の注意点
いくつかはまりポイントがあるので、そちらをご紹介
-
はまりポイントその1: Wandbのアカウントが必要
SAM PTは実験管理にWandbを用いているため、プログラムの実行にWandbのアカウントが必要です。
プログラム実行時にアカウントIDとパスワードを聞かれるので、持っていないければ作っておきましょう -
はまりポイントその2: データの持ち方
デモ内では以下のようにデータセットを置いていますが、今回は自前の動画を使うため、ここを置き換える必要があります。
# List the content of the demo_data directory
ls data/demo_data
# bees.mp4 street.mp4 ...
# Convert bees.mp4 to png frames
mkdir data/demo_data/bees
ffmpeg -i data/demo_data/bees.mp4 -vf fps=5 data/demo_data/bees/frame-%05d.png
# Convert street.mp4 to png frames
mkdir data/demo_data/street
ffmpeg -i data/demo_data/street.mp4 -vf fps=10 data/demo_data/street/frame-%05d.png
このフォルダには、動画ではなくフレーム毎に分解した画像を置いているとこが肝です(ffmpeg -i data/demo_data/xxxx.mp4 -vf fps=10 data/demo_data/xxxx/frame-%05d.png 部分で動画を画像に変換している)
そのため、animatediffで生成した動画もフレーム毎の画像にバラし、フォルダ内に格納しましょう。
SAM PTを使ったマスク生成
準備ができたら、プログラムを実行します。
# Run demo on animatdiff movie
python -m demo.demo \
frames_path='${hydra:runtime.cwd}/data/demo_data/{分割した画像を置いたフォルダ名}/' \
query_points_path=null \
longest_side_length=1024 frame_stride=1 max_frames=-1
Wandbのアカウントが聞かれた場合は、IDとパスワードを入力。
すると、「How many positive points? 」と聞かれます。
SAM-PTでは、画像に「マスクしたい部分」と「マスクしたくない部分」をそれぞれ設定できます。
上記の設定は画像をのマスクしたい部分を直接クリックすることで、クリックした部分に「〇」が置かれ、「〇」を含む領域をマスクしてくれるという仕組みになっています。(逆に、マスクしたくない部分については「×」を置く)
「How many positive points? 」は、「〇」を何個画像内に置くか?という設定になります。
今回は10個を指定しましょう。
次に、「How many negative points?」と聞かれるので、「×」を何個置くかを設定します。
こちらも今回は10に設定しましょう。

二つのパラメータを設定すると、以下の画面が出てきます。

こちらに直接、どこをマスクするか?を設定していきます。
今回は人物をマスクしていきます。
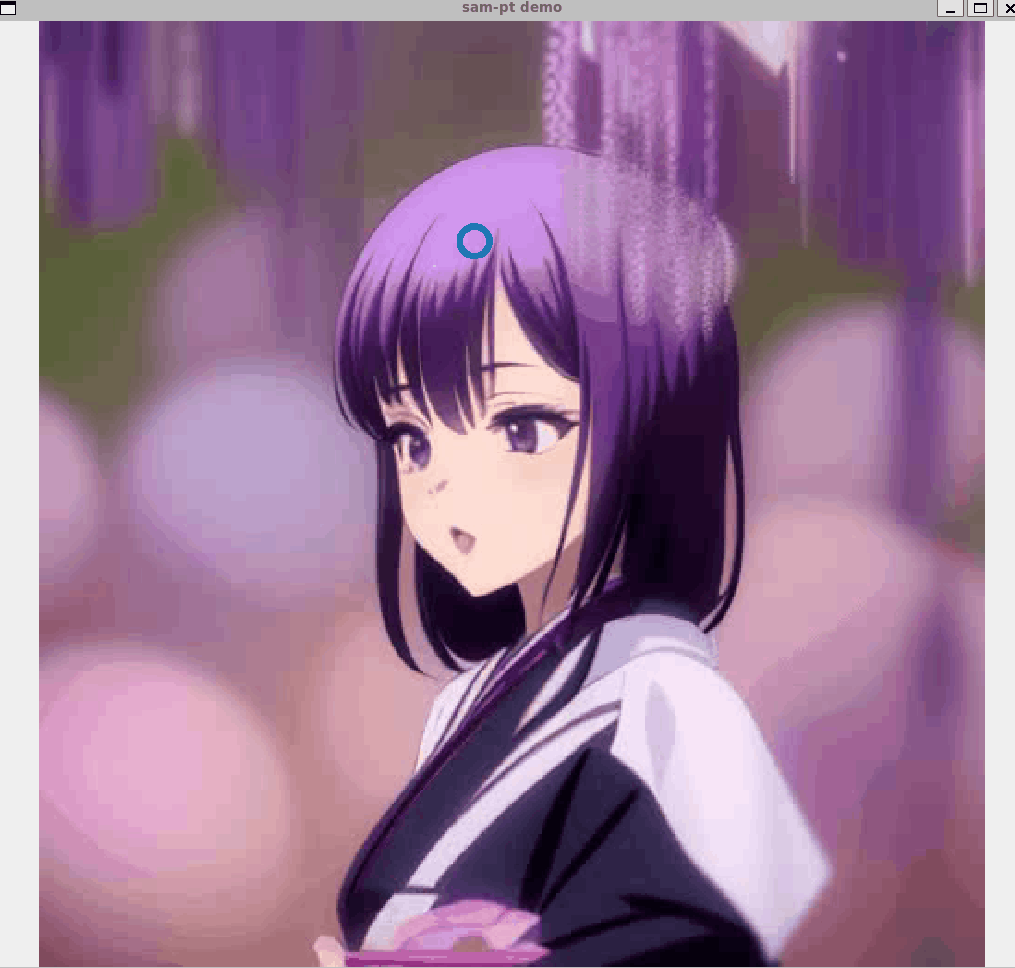
クリックすると、「〇」が追加されます。
ここがマスク対象となる領域を示しています。
このまま、マスクしたい領域を10個所クリックします。

10個所クリックすると続いて「マスクしたくない領域」の設定に入ります。
特に何の表示もなく、11回目のクリックから「マスクしたくない領域」の設定に移りますので、押しすぎないようにしましょう。

このように、11個目からは「×」が置かれるようになります。
そのまま、こちらも10個「×」を置いていきます。
「〇」と「×」の合計が20個になるまで置いたら、「sam-pt demo」の画面がアクティブになった状態で、キーボードの「ESCキー」を押します。

すると、マスクの自動生成が始まるので待機します。
出力結果は、sam-pt/outputs/{実行日}/{実行時間}/wandb/files/media/videos/verbose 配下に格納されています。
出力結果を見てみましょう。
-
ポイントトラッキング

- **自動生成マスク
**

マスク個所を設定したのは1フレーム分だけですが、ちゃんと動画全体を通してマスキングされていることがわかります。
マスク画像の取り出し方
さて、あとはこのマスキング結果を1フレームずつ入手できればいいのですが、僕が見た限りではマスク画像を入手する機能がSAM-PTには無いようです。
このissueを見る限り、logits(座標ごとにそのピクセルがマスク対象となるかのスコア値)は提供しているから、あとは勝手にマスク化しろということらしいです。
というわけで、demo.pyにマスク化する処理を追加していきます。
demo.pyを開き、以下の関数を追加します。
def save_masks(tensor, output_folder):
# バッチサイズを無視して各画像にアクセス
for i in range(tensor.size(1)):
# i番目のマスクを取得し、CPUに移動
mask = tensor[0, i].cpu()
# マスクを0-255の値に変換
mask = mask.to(dtype=torch.uint8) * 255
# PIL Imageに変換
mask_image = Image.fromarray(mask.numpy())
# 画像を保存
mask_image.save(f"{output_folder}/mask_{i}.png")
def visualize_and_save_predictions(rgbs, query_points, target_hw, positive_points_per_mask,
logits, trajectories, visibilities, scores, annot_size, annot_line_width):
sam_masks = logits[:, 1:, :, :].permute(1, 0, 2, 3) > 0
save_masks(sam_masks, "マスク画像を保存するフォルダのPATH")
上記を追記した後に、再度SAM-PTを起動しマスキング作業を行います。
すると、指定したマスク画像保存フォルダに、マスク画像が保存されます。

全てのマスク画像を繋げて動画化してみたものがこちら

元動画と合成してみるとこのようになります。

終わりに
今回は生成した動画から、SAM-PTを用いて自動でマスクを生成する手法を紹介しました。
次回は、実際にこの生成したマスク画像を使ってinpaintや背景透過を行う方法を紹介します!
Discussion