typo ckeck しようぜ
はじめに
興味深かったので深追いしてみた。問題点をまとめると
- check と ckeck は見間違えやすい
-
RubyHCL はコンパイルしない言語 - 文字列内(string interpolation)なので linter が通らない
こうなると typo を検知できる linter を使うしかない。しかし healthckeck の様に1ワードになっていると、それがどんな単語から構成されているか分からない。
- he alt h ckeck なのか
- health ckeck なのか
- heal th ck eck なのか
これをチェックできるコマンドを作った。
辞書が足らない、遅い、など問題点はあるけど、ひとまず動きそうなところまで作ったので、自分の整理の為に文章を残しておく。
healthckeck をエラーにするには
healthckeck をエラーにするにはまずこの単語を health と ckeck に分けなければならない。
単語リストを用意し、長さが長い順にソート、順にマッチした候補を前方一致で試し、全て何れかの単語で埋める事ができれば正常とする。
もちろんこの方法は、最悪のケースを考えると healthckeck という単語が全て単語リストに無い場合 単語リストの数 x 文字列長 の検索になってしまうので、かなり計算効率が悪い。しかし一般的に、プログラミング言語で使われる3文字程度の文字列は、変数名など省略された名前が多い。
func isSomeWords(s string) bool {
for _, w := range words {
if s == w {
return true
}
if len(w) < len(s) && strings.HasPrefix(s, w) {
if isSomeWords(s[len(w):]) {
return true
}
}
}
return false
}
文字列をトークナイズする
ソースコードの文字列の中やコメント文字列には何が書かれているか分からないので、トークナイズには2種類の分解を使った。
この unicodeclass はユニコードの文字クラスで分解するパッケージ。これと、空白や記号で分解する以下の関数を使った。
func tokenize(s string) []string {
ts := []string{}
prev := 0
rs := []rune(s)
for i := 1; i < len(rs); i++ {
if unicode.IsSpace(rs[prev]) != unicode.IsSpace(rs[i]) || unicode.IsSymbol(rs[prev]) != unicode.IsSymbol(rs[i]) {
ts = append(ts, string(rs[prev:i]))
prev = i
}
}
ts = append(ts, string(rs[prev:]))
return ts
}
辞書が知らないから typo なのか
辞書に無い単語だから一概に typo として扱うと、プログラミング言語のソースコードはほぼほぼエラーになってしまう。そこでレーベンシュタイン文字列距離を使い、以下の判定を行った。
- 既知の単語との距離が一定以上であればそれは無視する
- 既知の単語との距離が一定未満であればそれは typo と判断する
閾値は文字列長に依存するので、閾値として扱える様に。
func maybeTypo(s string) float64 {
s = strings.ToLower(s)
l := float64(len([]rune(s)))
m := l
for _, w := range words {
mm := float64(lsd.StringDistance(w, s))
if mm < m {
m = mm
}
}
return m / l
}
それでも知らない単語は
これだけやっても知らない単語は多い。例えば Go 言語であれば float64 という型があるが、もちろん単語リストには無い。そこで追加の単語リストを指定できる様にした。
$ ckeck -d /path/to/wordlist.txt main.go
実行結果
ここまでやると、healthckeck をエラーとして認識できる様になる。
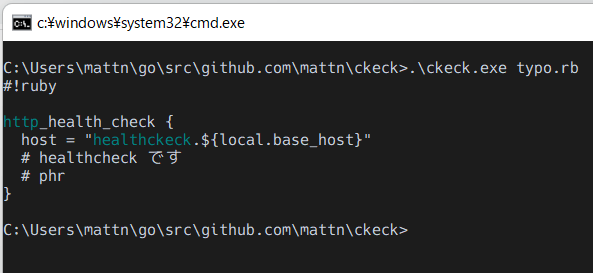
http がエラーなのは辞書に無いから。-u を指定すると grep 等と同じ UNIX コマンド形式の出力になる。
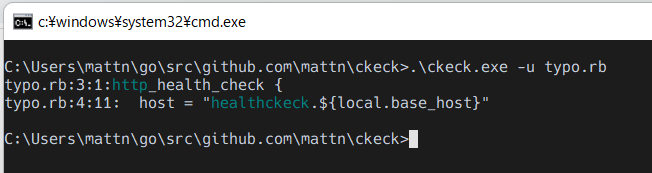
こんな風に Vim から使える。
おわりに
自分の納得の為に healthckeck を検出できる typo チェッカーを作りました。実用性などは全く考えていないので、自己責任で遊んで下さい。
Discussion
文字列の類似度の測定部分で一点気になったので質問です。
省略形を多く含むことが推定される文字列と省略前の単語候補を比較するのであれば、レーベンシュタイン距離を使用するよりも 省略形に対してスコア変動が少なく出やすいJaro距離の方が向いている印象を受けます。
手ごろなライブラリがなかった等の理由で却下した、
あるいは色々試してレーベンシュタイン距離が一番ということに落ち着いたということなのかが気になったので
よろしければお聞かせいただけると嬉しいです。
ありがとうございます。
省略形の考慮が入ってなかった為です。時間が取れたら検討してみたいと思います。ありがとうございます。
とりあえずの仮実装をしました。あとで検証したいと思います。