画像生成AI:StableDiffusionの仕組み
SD(Stable Diffusion)は、画像生成AIのデファクトスタンダードです。
前回SDXLの解説を書いたのですが、そもそもその大前提であるSDが難しいということで、今回の記事を用意しました。相補的に使っていただければと思います。
ちょっと今回は技術オタク寄りの内容かもしれません。(書いてたら説明したくなってしまったため)
対象
今回は、元論文
を参考にしています。Submitted on 2021/12とあり、2024/9現在、3年近くも経過してしまったのでもう古い話題かもしれないのですが、SD2, SD3, SDXLなどを理解する上でも重要です。
次元の確認
「このモデルはプロンプトからH×Wの解像度の、RGBフルカラー画像を生成するものだ」というのを常に念頭においておきましょう。
混乱を避けるために時々次元を確認するのが便利です。
今回は単純なモデルなので項目は少なめです。
| 変数名 | 種類 | 次元 |
|---|---|---|
| x | 画像 | H×W×3 |
| z = E(x) | latent | h×w×c |
| f | downsample factor | scalar(f = H/h = W/w) |
| m = log 2 f | log f | scalar(0, 1, 2, 3, 4, 5) |
| x~ = D(E(x)) | 画像 | H×W×3 |
推論の仕組み
SDの推論はy(プロンプト) → x~(画像)という処理で、大まかに以下の7stepで行われています。

①画像xのencodeを行う

②noisingを行う

これは下のような正規分布ノイズを加えるという意味
αtx0(潜在空間のベクトル長さを調整したもの)を中心に、等方向的なノイズを加えます。
α・σはSignal Noise Ratioを決めるパラメーター
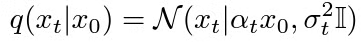
③ϕi(zt)とτθ(y)を次のようにconcatする

④ただし、Q, K, Vは学習可能射影Wを使って次のように作る
ϕi(zt) → Q
y → τ(y) → K, V

Q, K, Vはcross-attentionなので、denoising前と後との一貫性を保持する
⑤denoisingを行う

ただしεはconditional denoising autoencoderと呼ばれる、オートエンコーダーxθのリパラメトリゼーションで、noisingのパラメーターを含む。

⑥denoisingをあとT-1回行う

⑦画像x~へのdecodeを行う。

こうして欲しかった推論結果y(プロンプト) → x~(画像)が得られるわけです。
trainの仕組み
loss

ただし
である。
学習可能なパラメーターはθであるから、θでこれをSDGすれば、εθとτθはjointly optimized
正則化
KL-reg, VQ-regという、以前発明された方法を使います。
実装の確認
predictはタスクごとに行う仕様で、以下のような実行可能pyファイルがたくさんあります。
いずれにせよforwardはmodels以下のddpm(後述)でハンドリングされています。
trainはモデルごとに行う仕様で、以下の2種類があります。
# AutoEncoder, E
CUDA_VISIBLE_DEVICES=<GPU_ID> python main.py --base configs/autoencoder/<config_spec>.yaml -t --gpus 0,
# Latent Diffusion Model, tau_theta, epsilon_theta
CUDA_VISIBLE_DEVICES=<GPU_ID> python main.py --base configs/latent-diffusion/<config_spec>.yaml -t --gpus 0,
そのため、ステップごとに対応したクラスがあるはずです。
Class解説
LightningDataModule
train/validation/test splitやデータ準備、変換が標準化されモデル間で一貫します。
ImageNetを例にとると、具体的なデータは以下のように呼んでいます。
①AutoEncoder
first_stage_modelというのが入り口で、この最初のステップに対応します。
pythonではなくyamlが貼られていてギョッとすると思いますが、diffuserフレームワークは設定ファイルをインスタンス化するのです。(慣れると読みやすいかも)
これはAutoencoderKLクラスを参照しています。
このconfigから、
このAutoencoderKLクラスをinstantiateする仕組みです。以下を読むと、__init__でinit_from_ckptされていることがわかります。
②noising
以下のように正規分布からサンプルしているだけです。
posterior = DiagonalGaussianDistribution(moments)
z = posterior.sample()
実装はtorch.randnです。
③concat・⑤denoising
このステップではx = ϕi(zt)とc = τθ(y)をconcatしますが、それを実行しているのはこの行です。
def forward(self, x, c, *args, **kwargs):
t = torch.randint(0, self.num_timesteps, (x.shape[0],), device=self.device).long()
if self.model.conditioning_key is not None:
assert c is not None
if self.cond_stage_trainable:
c = self.get_learned_conditioning(c)
if self.shorten_cond_schedule: # TODO: drop this option
tc = self.cond_ids[t].to(self.device)
c = self.q_sample(x_start=c, t=tc, noise=torch.randn_like(c.float()))
return self.p_losses(x, c, t, *args, **kwargs)
それに渡すc = τθ(y)を得ているのはこの行です
c = self.cond_stage_model.encode(c)
このクラスはddpm(Denoising Diffusion PyTorch Model)であり、U-Netのckptをロードしています。
④projection
学習可能な射影はConv2Dで実装されています。LinearAttentionクラスですね。
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)', heads = self.heads, qkv=3)
k = k.softmax(dim=-1)
context = torch.einsum('bhdn,bhen->bhde', k, v)
out = torch.einsum('bhde,bhdn->bhen', context, q)
SpatialSelfAttention・CrossAttentionもあります。
⑦decoding
encodingの時に使ったのと同じモデルのdecodeを呼んでいます。
output_list = [self.first_stage_model.decode(z[:, :, :, :, i],
force_not_quantize=predict_cids or force_not_quantize)
for i in range(z.shape[-1])]
おわりに
いかがでしたでしょうか?
本記事では「SDとは何か」の解説をしました。
この記事ではpredict/trainの原理、公式にどう実装されているかを解説しました。
この記事が、SD2, SD3, SDXLなどを理解するのに役立てば幸いです。
Discussion