MLflowの使い方 〜高レベルAPIでの簡単入門と低レベルAPIでの簡単入門〜
修士の研究でMLflowを使っている.これは機械学習のライフサイクルの管理を楽にしてくれるオープンソースのソフトウェアだ.まだ解説記事がたくさんあるわけではないので,公式ドキュメントを読んだ方が良い.(本来はまず何よりも先に公式ドキュメントを読むべきであるだろうが).ただ,以下の記事も素晴らしいのでさっさと始めたいという人や英語が嫌いな人は参照してみると良い.
ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう-
https://ymym3412.hatenablog.com/entry/2020/02/09/034644
公式ドキュメント冒頭にあるように.MLflowは以下の4機能を我々に提供してくれる.この記事では,1つ目のMLflow Trackingについて書いているので,その他の機能を求めている方は参考リンクを辿ると良い.
- MLflow Tracking(実験管理が楽にできる,研究やkaggleなどにおすすめ)
- MLflow Projects(実行環境等の整理を楽にしてくれる,多分 参考)
- MLflow Models(モデルを様々な形式・場面で利用可能とする,多分 参考)
- MLflow Model Registry(モデルのバージョン管理とかができる,多分 参考)
以下.MLflow TrackingをMLflowと記す.
MLflowを使うにはまずはpip等でローカルに取り込もう
pip install mlflow
それで, MLflowを超簡単に始めるには以下を実行するだけで良い.以下のmain.pyを作成して,ターミナルでpython3 main.pyと打ってみよう.
import mlflow
with mlflow.start_run():
for epoch in range(0, 3):
mlflow.log_metric(key="train acc", value=2*epoch, step=epoch)
実行すると, mlruns/ ディレクトリが作成されているだろう.続けて以下をターミナルで実行してみてほしい.
mlflow ui
すると,以下のような出力が出ると思う. http://127.0.0.1:5000 でListening atしているとのことなので,ブラウザでアクセスしてみよう.

アクセスすると以下のような画面が出てくると思う.ここから色々実験結果が確認できるわけだ(lossとかパラメータの変化とか).ここからの使い方は,いろんなとこを押してみたりすることで習得できると思うので,これ以上の解説はしない.色々押してみよう.先ほど実行したmain.pyでの mlflow.log_metric(key="train acc", value=2*epoch, step=epoch)によって,エポックごとのtrain accが保存されているはずだ.
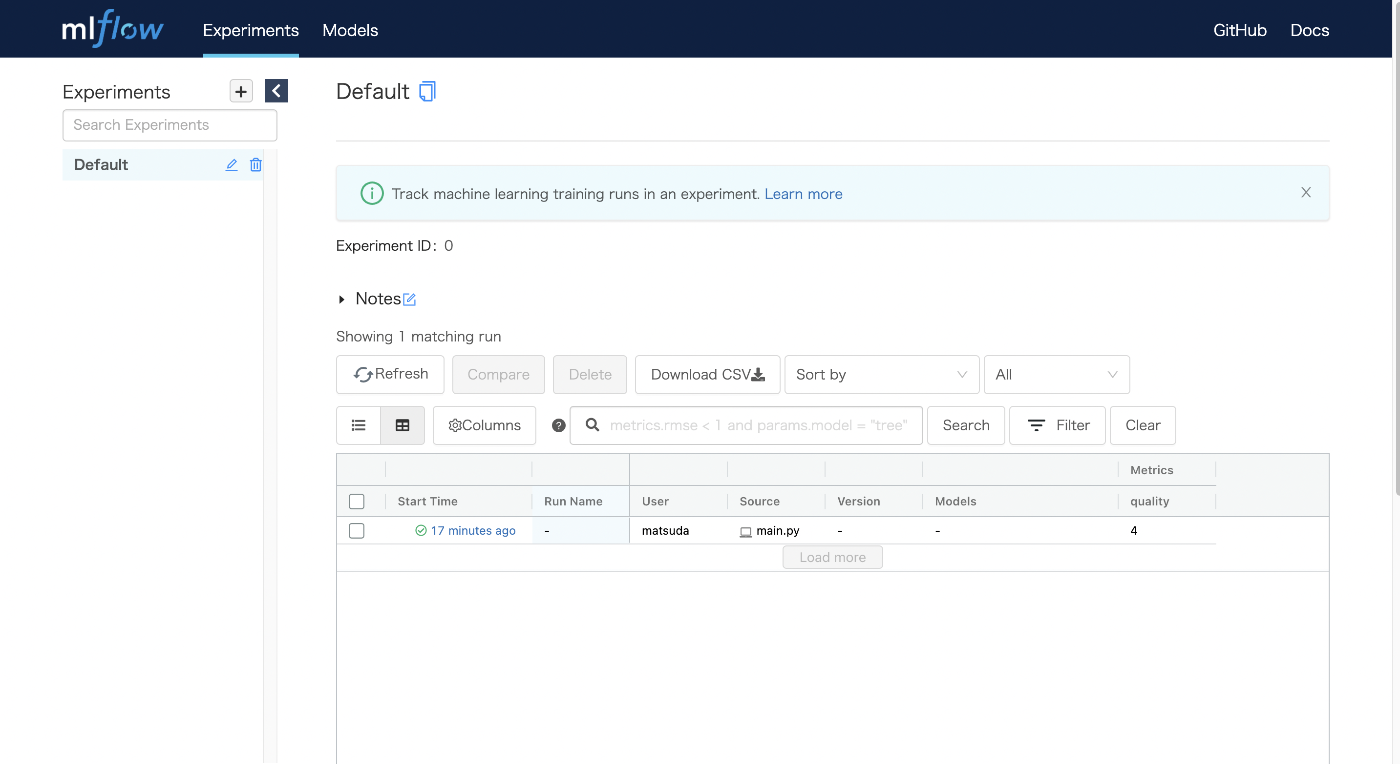
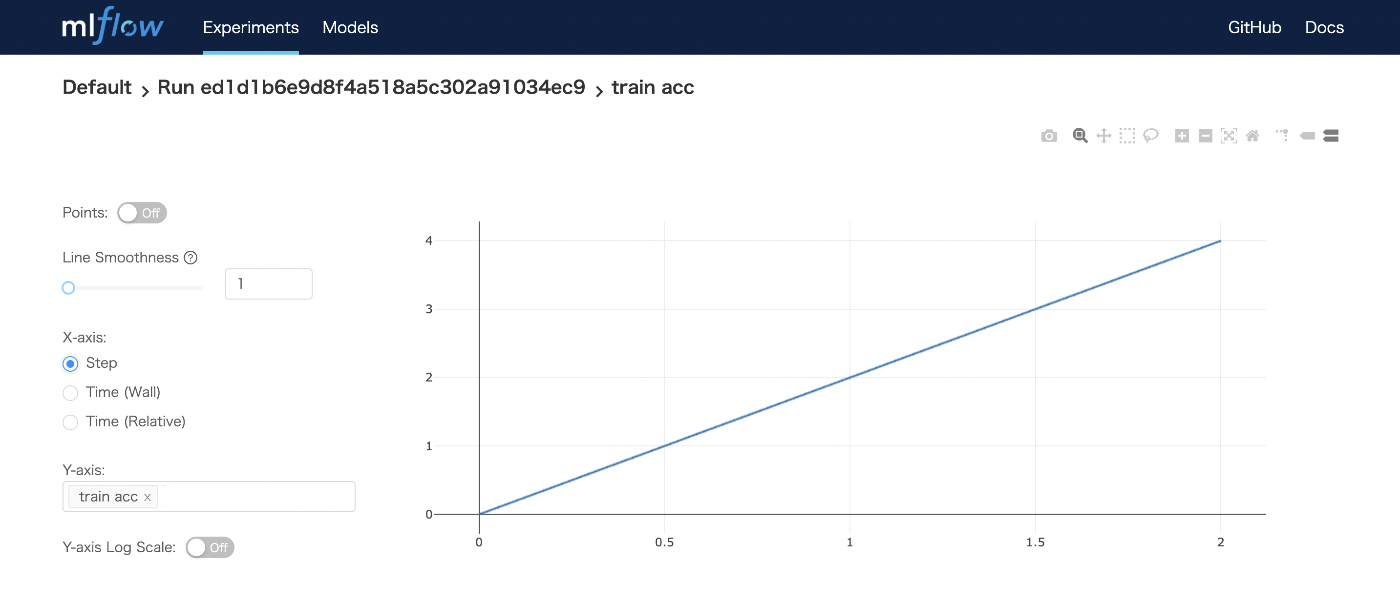
というわけで,ものすごく簡単にMLflowを使ってみた.これで十分な人は良いが,もう少しMLflowについて理解するために用語を整理しようと思う.また,より低レベルなAPIの使い方について触れていく.
MLflowには, experimentとrunがある.公式ドキュメントやAPIにたくさんexperimentとrunという単語が出てくるので覚えよう.experimentは1つの実験で,runは1つの実験内の1試行だと思えば良い.1つの実験内にたくさんのrunが存在するイメージだ. 例えば,画像認識モデルを学習する1実験がexperimentで,その実験内で5-foldで交差検証を行なっているなら5つのrunがあるというイメージだ.イメージ図が欲しければ以下のリンクをみてみてほしい.
それで,先程行った簡単な始め方において,mlflow.start_run()でrunを作成していたわけだ(ドキュメントを読まなくてもメソッド名が意味を教えてくれている).このやり方でも良いのだが,より細かなことをやりたい場合は低レベルAPIを利用した方が良い.MLflowは,先ほどのような高レベルAPIに加え,低レベルAPIを提供している.それがMlflowClientだ.これを利用してどのようにMLflowを利用するかを述べていく.まずはコードを動かしてしまおう.以下のクラスをmain.pyファイルにでもコピペしよう.__init__()内にself.client = MlflowClient()とあるように,MlflowClientをラップして使うためのクラスMlflowWriterがある.元の参考は以下の記事で,自分の研究にとって使いやすいように変更を幾らか加えている.
ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう-
https://ymym3412.hatenablog.com/entry/2020/02/09/034644
import numpy as np
import matplotlib.pyplot as plt
import mlflow
from mlflow.tracking import MlflowClient
from mlflow.utils.mlflow_tags import MLFLOW_RUN_NAME,MLFLOW_USER,MLFLOW_SOURCE_NAME
from omegaconf import DictConfig, ListConfig
class MlflowWriter():
def __init__(self, experiment_name):
self.client = MlflowClient()
try:
self.experiment_id = self.client.create_experiment(experiment_name)
except Exception as e:
print(e)
self.experiment_id = self.client.get_experiment_by_name(experiment_name).experiment_id
self.experiment = self.client.get_experiment(self.experiment_id)
print("New experiment started")
print(f"Name: {self.experiment.name}")
print(f"Experiment_id: {self.experiment.experiment_id}")
print(f"Artifact Location: {self.experiment.artifact_location}")
def log_params_from_omegaconf_dict(self, params):
for param_name, element in params.items():
self._explore_recursive(param_name, element)
def _explore_recursive(self, parent_name, element):
if isinstance(element, DictConfig):
for k, v in element.items():
if isinstance(v, DictConfig) or isinstance(v, ListConfig):
self._explore_recursive(f'{parent_name}.{k}', v)
else:
self.client.log_param(self.run_id, f'{parent_name}.{k}', v)
elif isinstance(element, ListConfig):
for i, v in enumerate(element):
self.client.log_param(self.run_id, f'{parent_name}.{i}', v)
else:
self.client.log_param(self.run_id, f'{parent_name}', element)
def log_param(self, key, value):
self.client.log_param(self.run_id, key, value)
def log_metric(self, key, value):
self.client.log_metric(self.run_id, key, value)
def log_metric_step(self, key, value, step):
self.client.log_metric(self.run_id, key, value, step=step)
def log_artifact(self, local_path):
self.client.log_artifact(self.run_id, local_path)
def log_dict(self, dictionary, file):
self.client.log_dict(self.run_id, dictionary, file)
def log_figure(self, figure, file):
self.client.log_figure(self.run_id, figure, file)
def set_terminated(self):
self.client.set_terminated(self.run_id)
def create_new_run(self, tags=None):
self.run = self.client.create_run(self.experiment_id, tags=tags)
self.run_id = self.run.info.run_id
print(f"New run started: {tags['mlflow.runName']}")
#mlflow.set_tracking_uri("file://" + cwd + "/mlruns") #/mlrunsディレクトリの場所変えたかったらこれでできるよ
EXPERIMENT_NAME = "hogeeeeeehogeeeee"
writer = MlflowWriter(EXPERIMENT_NAME)
for seed in [46,47,2021,0,1]: #朧げながら浮かんできたよ
#タグにrunの情報等を入れられるよ
#System tagsについて : https://mlflow.org/docs/latest/tracking.html#id19
tags = {'trial':seed,
MLFLOW_RUN_NAME:"runの名前を決められるよ",
MLFLOW_USER:"ユーザーも決められるよ",
MLFLOW_SOURCE_NAME:"ソースも決められるよ",
}
writer.create_new_run(tags) #新しいrunを作るよ
# 〜〜〜〜 学習とかテストとかのコードは省略 ~~~~~~~~
writer.log_param("learning_rate", 0.01) #args => key and value
writer.log_metric("test accuracy", 88) #args => key and value
writer.log_metric_step("train loss", 10, step=1) #args => key and value and step
writer.log_metric_step("train loss", 5, step=2) #args => key and value and step
writer.log_metric_step("train loss", 2, step=3) #args => key and value and step
text = "Hi, I am Matsutakk"
with open("text.txt", 'w') as f:
f.write(text)
writer.log_artifact("text.txt") # 他にもpickleファイルの保存とかもできるよ
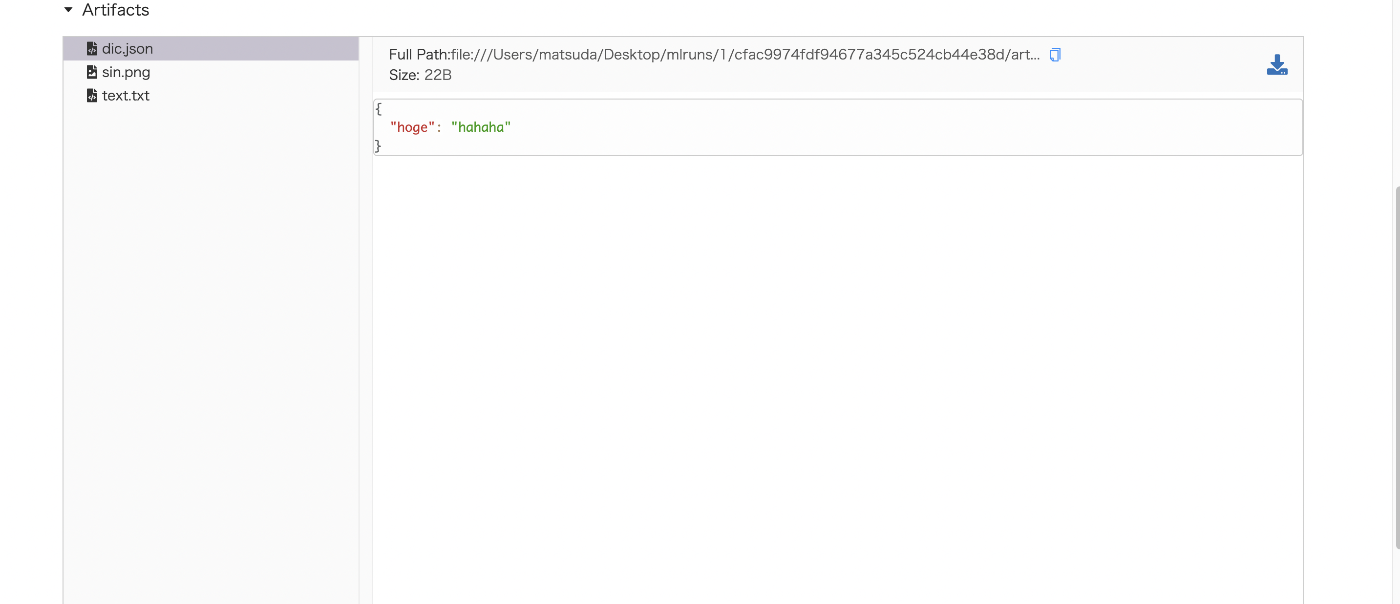
dic = {'hoge':"hahaha"}
writer.log_dict(dic, 'dic.json') # jsonとかyamlにもできるよ
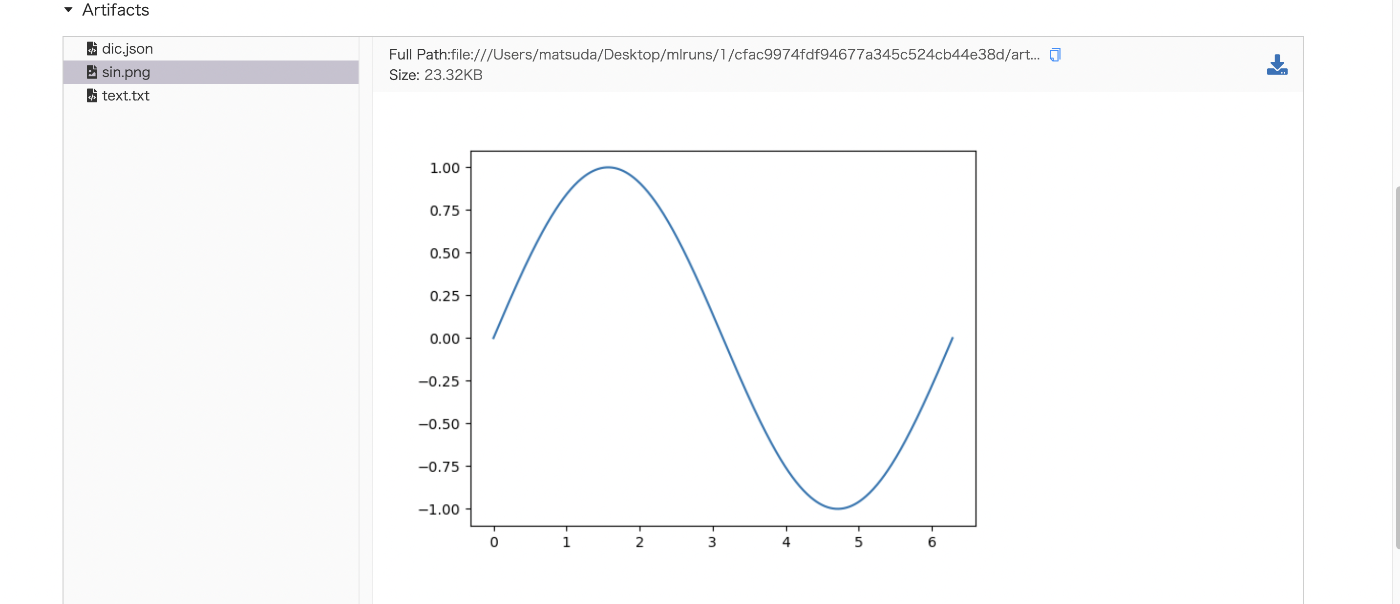
fig = plt.figure()
x = np.linspace(0, 2*np.pi, 500)
plt.plot(x,np.sin(x))
writer.log_figure(fig, 'sin.png') # 図の保存用メソッド,
plt.close(fig)
writer.set_terminated() #必ず呼ぶこと! ファイルのクローズみたいなもんだよ,きっと
# その他メソッドを知りたい・追加したいなら以下を参考に
# https://mlflow.org/docs/latest/python_api/mlflow.tracking.html
先ほど同様に, python3 main.py と実行しよう. numpyとmatplotlibも使うので,ない場合は
pip install numpy matplotlib
とでも打っておこう.
python3 main.pyと実行したあと,先ほど同様に以下のコマンドを打ち,http://127.0.0.1:5000 にアクセスしよう.
mlflow ui
先ほどとは違い,5つ分の表示が出てくるはずだ(5つのrunをコード内で作ったため).
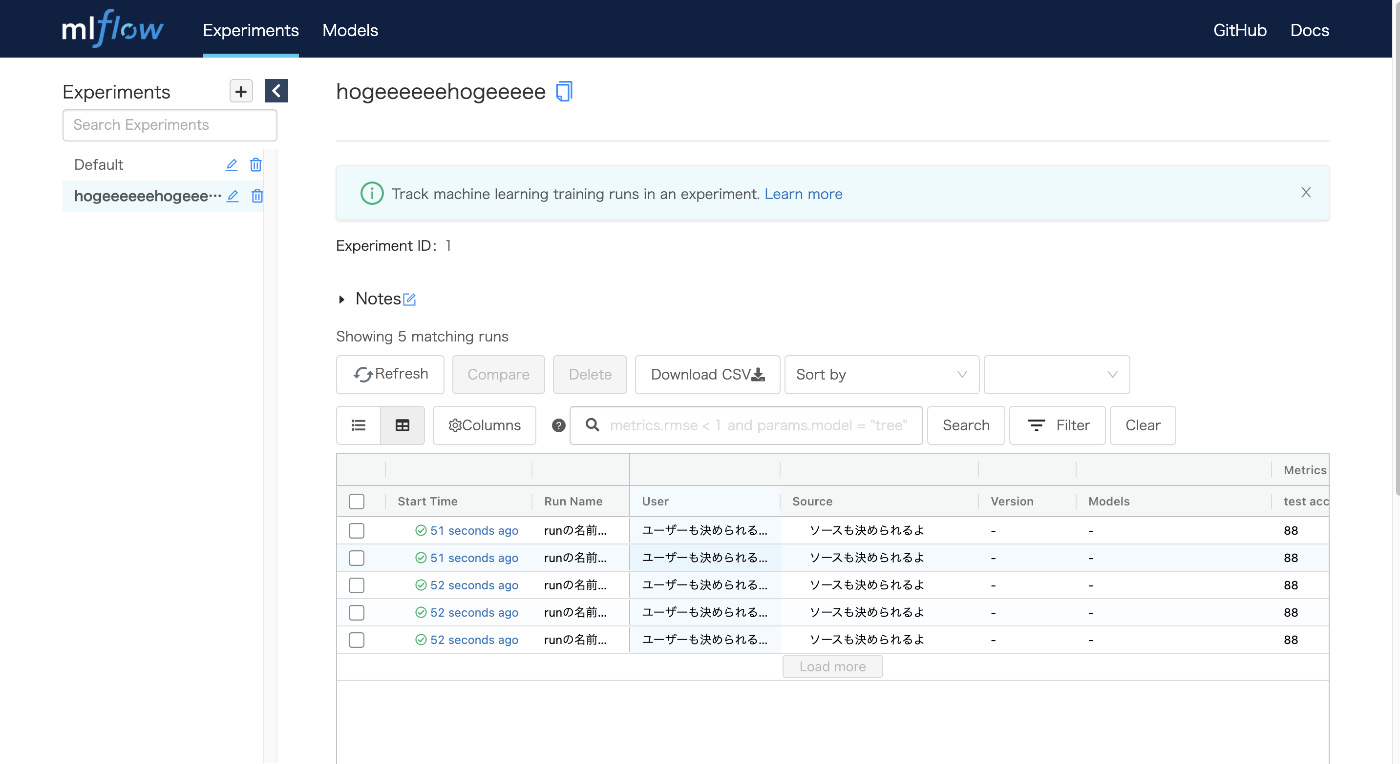
中身についてはコード内のコメントを参照してほしい(クソ投げやり).コード内で保存した画像やjsonが保存されているのがわかる.
HEROの再放送の時間が近づいて来たので今回はここらへんで.
MLflowを使うことで簡単に機械学習の学習中のlogや結果を簡単に保存でき,GUIで確認できるようになる.これできっと研究も捗るはずだ.マスカレードナイト見にいこう.
Discussion