はじめに
チームリーダーの畠山です。開発が終盤に差し掛かってきたので、備忘録として開発の振り返りメモを書いていきます。
前回の記事では、限られたリソースで高性能なモデルを作るために、3つの点に注目しました。
- モデルアーキテクチャの最適化
- 事前学習用データセットの準備
- ファインチューニング用データセットの準備
今回は、それぞれのアプローチを試した結果について説明します。タイトルにもあるように、Scaling lawの壁は高く、簡単にはうまくいきませんでした。むしろ、うまくいかない条件がわかったという知見が多く得られました[1]。
モデルアーキテクチャの工夫: Branch-Train-Merge (BTM)もどきを試す
BRTもどき戦略はうまくいったのか?
チームでは、事前学習の際にランダムにシャッフルしたデータを使う代わりに、以下のようなカリキュラムを設定しました。
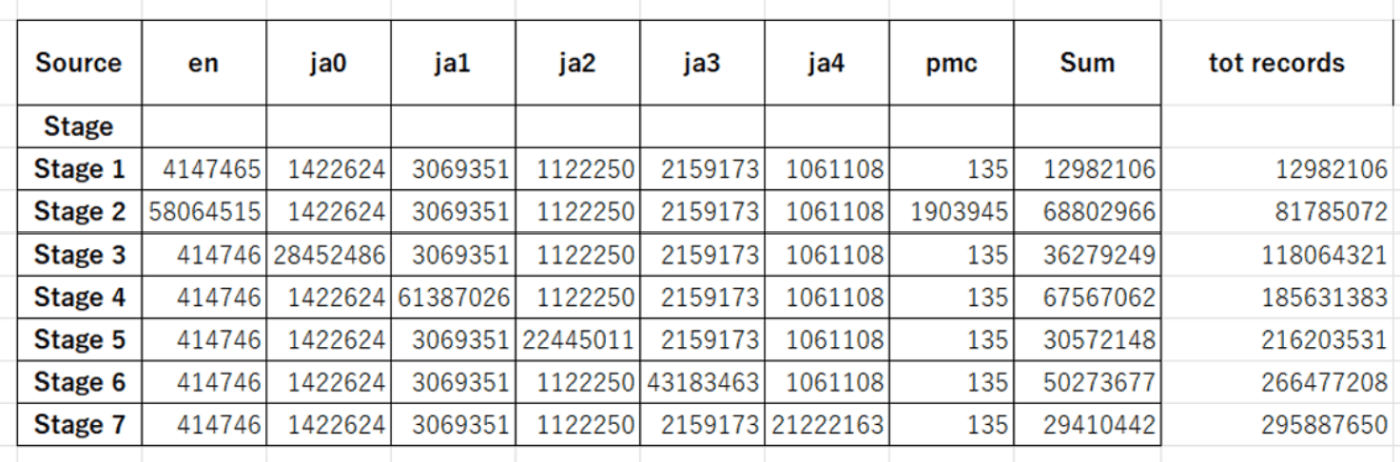
各ステージの内容:
Stage 1: 全データをランダムにシャッフル。モデルを様々なトークンに慣らすことが目的。
Stage 2: 英語とコードのデータ。Wiki、英語論文、コード、数学系のデータを使用。
Stage 3~7: 日本語の各ドメイン(A~E)のデータ。
LLaMAベースの8Bサイズのモデルを用意し、上記のデータセット(約200Bトークン)で学習させました。8Bは必ずしも大きなモデルサイズではないため、各ドメインに特化した学習を繰り返し、スナップショットを保存するという戦略を立てました。全ての学習が終了後、各ステージのモデルを統合することで、各ドメインのエキスパートから構成される高性能なモデルが得られると期待しました。このような試みは、大規模言語モデルの研究でもまだあまり行われていない(少なくとも公開されていない)ようです[2]。そのため、試してみる価値のあるアプローチだと考えました。
結果は...?
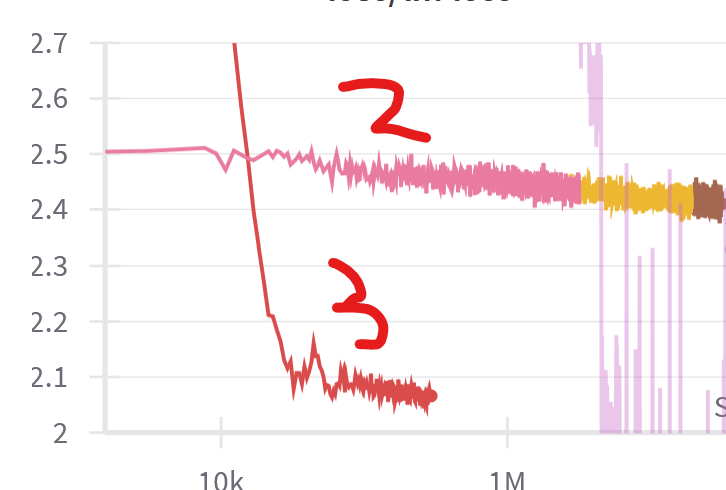
学習時のtrain lossは以下のようになりました。ドメインの切り替わりのタイミングは、赤い矢印で示されています。
英語 to 日本語ドメイン
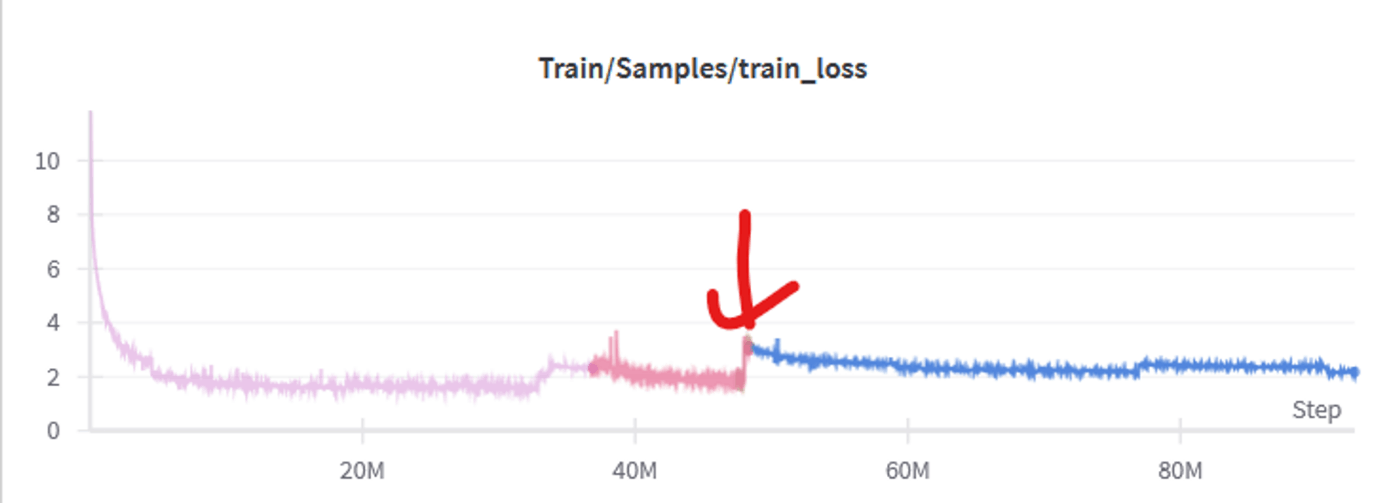
日本語ドメインx5
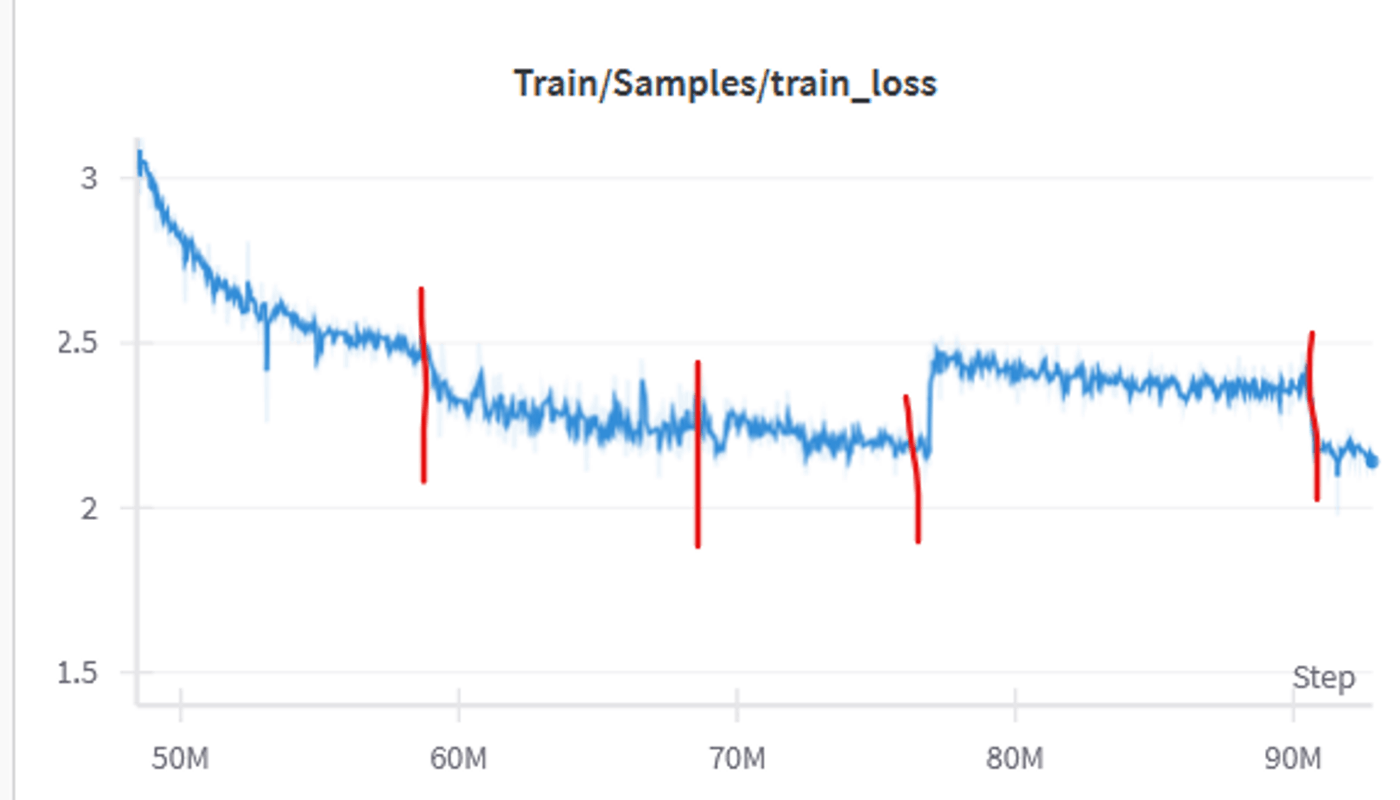
loss curveに関する観察記録と考察
ドメインが切り替わるたびにlossが一時的に上昇するのは、新しい専門分野を学習するために予測が難しくなるためであり、想定内の挙動です。また、ドメインによってモデルの予測難易度が変化し、lossが大きく上下することも予想されていましたが、その変化の大きさには驚きがありました。
英語+codeドメインではlossが2を大きく下回る一方、日本語ドメインではlossが2-2.5付近で停滞しています。llamaの7bモデル(loss curve)でもlossが2を切っていたため、この停滞には焦りを感じましたが、モデルにとっての予測難易度がドメインによって異なるのは当然であり、他のモデルのlossを必ずしも参考にする必要はないと考えるに至りました。
英語+code系のデータは法則性の高い文字列が多いため、モデルにとって予測がし易いはずです。対照的に、雑多な日本語のwebテキストは扱うジャンルも広いため、学習に時間がかかると考えられます。
ドメインによるlossの変化は、モデルの学習過程において自然な現象であり、各ドメインの特性を反映していると言えます。モデルの性能評価には、単一の基準だけでなく、ドメインごとの特徴を考慮することが重要だと思われます。
ドメイン特化したモデル群は作れたのか?
結論から言うと、期待した専門家モデル群は作れなかったような気がします。
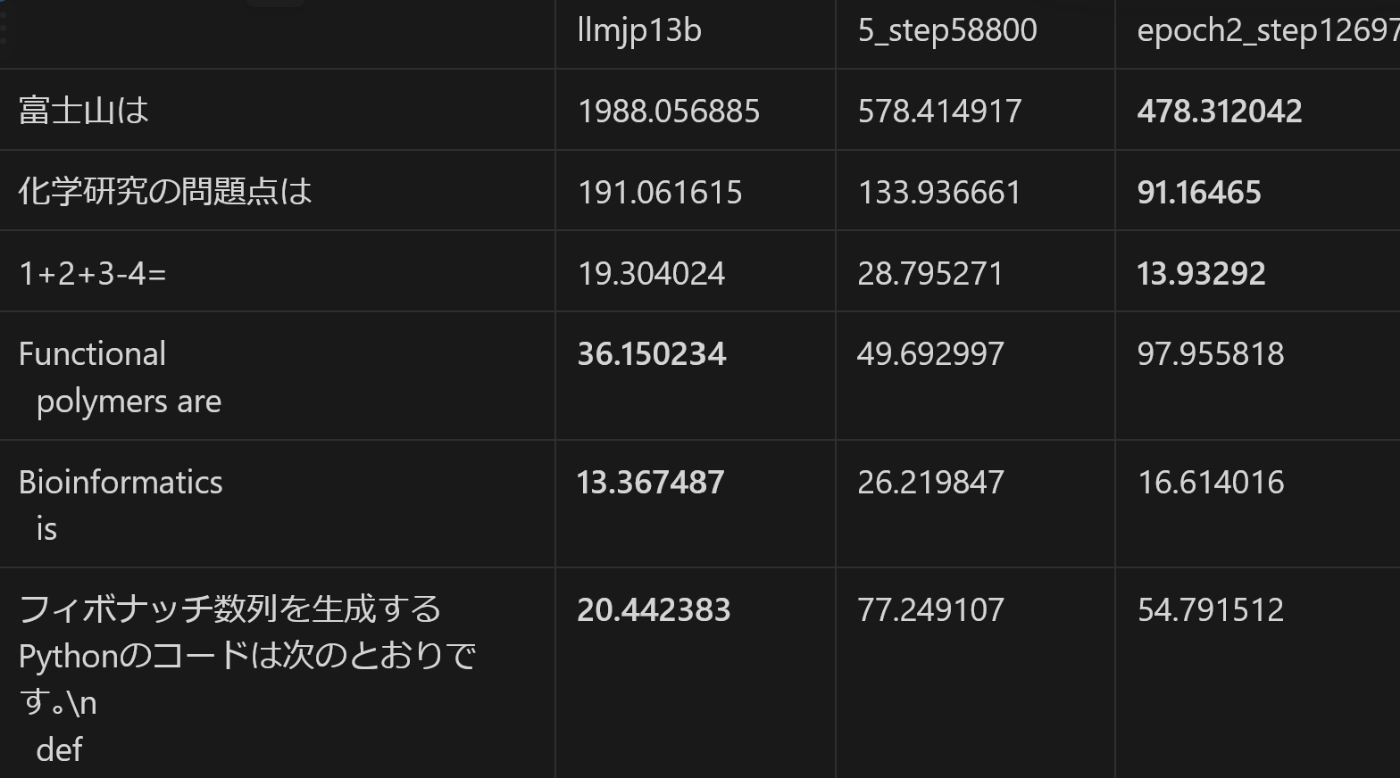
以下は、種々の入力文に対するperplexity[3]を、各モデルに対して計算した結果です。
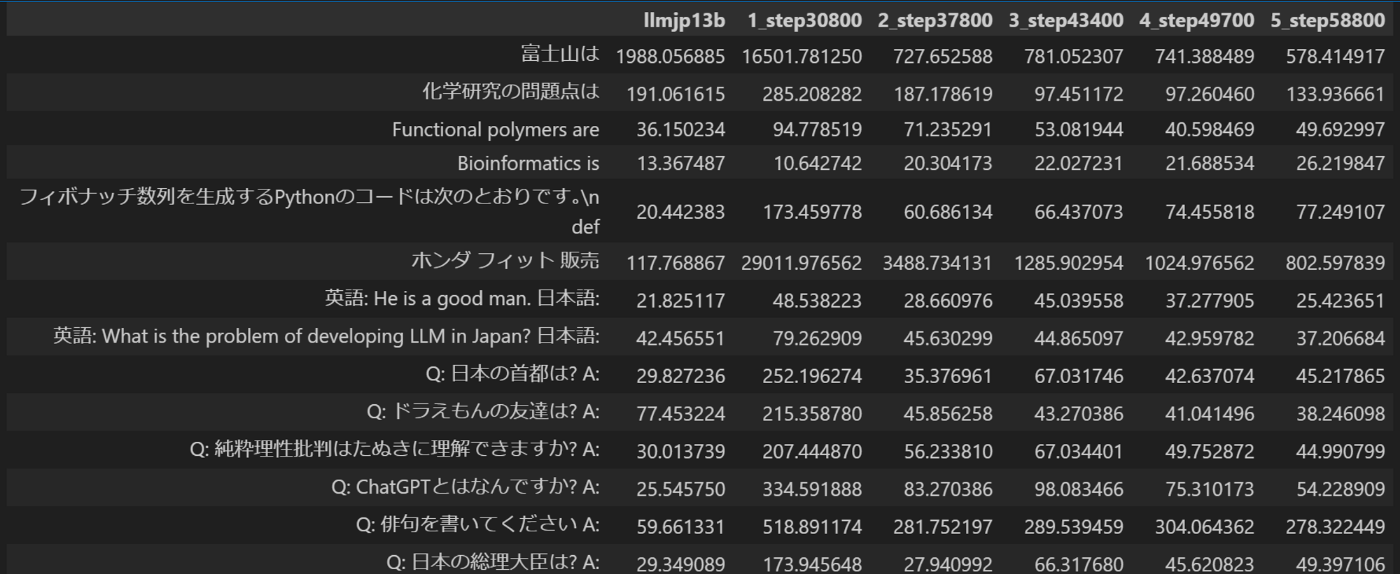
- ベースライン: llmjp-13b v1.0
- step1-5: 英語, 日本語A, ..., 日本語Dに対応します
- 5つ目の日本語ドメインの学習が終わる前のデータのため、日本語Eはありません。
若干の変動はあるものの、文章の種類によらず、学習stepが増えるにつれてperplexityが下がるという傾向が得られました。
すなわち、モデルの性能は、「英語ドメインを学習完了<日本語Aドメインを学習完了<...<日本語Dを学習完了」という順番だったわけです。この結果の意味するところは、わざわざ各ドメインでのsnapshotをとって最後にモデルをマージする必要はなく、一番最後のモデルを普通に使えば良いということです[4][5]。
対応策は?
今回のモデルにおいて、データセットのドメイン分割によるカリキュラム学習は、必ずしも効果的ではないことがわかりました。
そこで本チームでは、2 epoch目[6]からは素直にデータセットをシャッフルしてモデルを学習させることにしました。
- 2 epoch(?)目[7]: 日本語だけのデータをシャッフルして学習(数十b token)
- 学習完了
- 3 epoch(?)目[7:1]: データセット全体をshuffleし、token長を2048から8192に増やして学習(数十b token)
- 執筆時点、まだ学習中です。
- 執筆時点、まだ学習中です。
以下は、2 epoch目を終えた後のモデルのperplexityと出力例です。追加学習により、性能が上がっている印象です。

一連の経緯をまとめると、モデルアーキテクチャの試行錯誤をまとめると、ドメイン別のカリキュラム学習やBTMは、今回はあまりうまく行かなかったので、普通のアプローチに途中で軌道修正した、ということになります。
事前学習データセットの準備時の試行錯誤
時系列がモデル学習と前後しますが、事前学習データの準備も、かなり大変でした。
データ収集・解析を通じて大変だった点は、以下のとおりです。
(このセクションは、あまりScaling lawとは関係のない話が中心です)
オープン開発の難しさ
オープン開発では、質の高いデータを集めるのが難しいという問題がありました。日本の著作権法では、AIがデータを学習することは合法だと一般的に解釈されています[8]。しかし、クローズドな開発では、一般に公開されていない書籍や論文なども学習に使うことが理論上可能です[9]。
今回のプロジェクトでは、開発の透明性を重視していたため、誰でもアクセスできるデータだけを使うことにしていました。このオープンなデータは主にインターネット上のウェブサイトを指します。しかし、ウェブサイトの文章は必ずしも質が高いとは限りません。
本当に優れたAIモデルを作るためには、OpenAIなどがやっていると噂されているように、一般に公開されていないデータも使って学習を進める必要があるのかもしれません。
学術データの商用利用の壁
本プロジェクトでは、誰でも自由に商用利用できるAIモデルの開発を目標としていますが、学術系データを集める過程で予想外の障害にぶつかりました。「自由な商用利用が可能」という言葉は一見良さそうに聞こえますが、いくつかの大学や公的機関、学会などにデータ提供を打診したところ、「商用利用は難しい」という反応が返ってきました。
これらの機関、特に公益社団法人は、法律により特定の団体への利益提供が制限されているため、「商用利用」という言葉に強く抵抗を感じていることがわかりました。その結果、データを活用することはできませんでした。
今後、公的機関や公益法人にデータ提供を依頼する際は、「商用利用」という言葉を避け、代わりに「Creative Commonsのような寛容なライセンスでモデルを公開したい」と伝えることで、交渉をスムーズに進められると考えています。このように表現することで、相手の懸念を和らげ、データ提供に前向きな反応を引き出せるかもしれません。
プロジェクトの目的を達成するには、相手の立場や考えを理解し、適切な言葉選びと戦略的なアプローチが欠かせません。今回の経験を生かし、よりスムーズなデータ収集を目指していきたいと思います[10]。
学習に必要なデータ量の膨大さ(収集編)
大規模言語モデルを開発するには、大量の学習データが必要です。有名なChinchilla論文によると、学習させるトークン数は、モデルサイズの約20倍が目安だそうです[11]。今回のプロジェクトでは、約10Bのモデルを作ることを目指しているので、必要なトークン数は約200Bになります。
では、200Bトークンはどのくらいのファイルサイズに相当するのでしょうか。経験的に、1Bトークンあたり約5GBのファイルサイズになることがわかっています[12]。つまり、200B × 5 = 1000GB、すなわち約1TBのテキストデータが必要ということになります。
1000GBというテキスト量は膨大です。日本語のWikipediaには約140万件の記事があり、テキストサイズは10GB程度です。つまり、必要なテキスト量はWikipediaの約100倍にもなります。これだけの量のテキストを集めるのも、データ処理をするのも、非常に大変な作業でした。
データ収集については、主にCommon Crawlを解析することにしました。ただし、Common Crawlの1スナップショットあたりのデータサイズは約100TBもあり、そこから日本語の文章を抽出する必要がありました。通常の環境では、データのダウンロードすら不可能です。幸いなことに、GCPやAWSを得意とするメンバーがいたので、いくつかのスナップショットのデータを収集・解析することができました。
これらの技術的な詳細や苦労話については、担当メンバーが別途執筆してくれる予定(?)です。
学習に必要なデータ量の膨大さ(解析編)
テキストデータの解析は、大規模言語モデルを開発する上で重要な課題の一つです。Common Crawlなどから収集したテキストには、ノイズや重複表現が多く含まれているため、それらを丁寧に取り除く必要があります。最終的に1000GBのクリーンなテキストを得るためには、中間データも含めると、少なくとも10TB程度のストレージ容量が必要だということがわかりました。
また、処理速度も大きな問題となりました。テキストの清掃にはGPT-4のような大規模言語モデルを使うのが最適ですが、現実には限られた計算リソースと時間内で処理を完了させなければなりません[13]。そこで、本プロジェクトではFastTextやK-Meansのような「枯れた手法」を採用しました。これらの手法は最先端のアルゴリズムではありませんが、速度と精度のバランスに優れています。
大規模言語モデルの開発では、GPT-4のような最高性能のモデルだけでなく、様々なレベルのモデルを揃えておくことが重要だと実感しました。目的や状況に応じて適切な手法を選択し、効率的にデータ処理を進めることが求められます。
ルールベース、機械学習、確率的なフィルタリングを組み合わせることで、個人的には、それなりに満足のいく品質のデータセットが得られました。一方、クリーニング後のデータサイズは約500GB(約100Bトークン相当)となりました。今回の開発では、英語とコードで約100Bのデータを使用し、合計で約200Bトークンを達成することができました。しかし、それ以上のサイズのモデルを開発するには、データが不足している可能性があります。今後は、さらなるデータ収集や、クリーニング条件の最適化が必要かもしれません[14]。
これらの技術的な詳細や苦労話についても、担当メンバーが別途執筆してくれる(?)予定です。
ファインチューニングデータを集めるのが大変だった
日本語のファインチューニングデータが足りない
大規模言語モデルの開発では、事前学習の計算コスト(つまり、Scaling law)が最大の障壁となっていますが、最終的な性能を決めるのは事後学習(ファインチューニング)の質だと言われています。
現在公開されているオープンモデルの多くは、似たようなモデルアーキテクチャ(Transformer)を採用しており、学習データもCommon Crawlなどの公開テキストがベースになっています。このように、モデルの基本的な構成が似通っている状況では、最終的な出力の違いを生み出すのは、事前学習の計算量とファインチューニングの質だと考えられます。
実際に、高品質な指示データで学習したモデルの多くは、ベンチマークテストで高いスコアを記録しています[15]。つまり、うまくファインチューニングを行うことができれば、Scaling lawから予測される平均的な性能を上回る優れた応答を生成できる可能性があるのです[16]。
ファインチューニングが重要だという共通認識がある一方で、日本語ドメインにおけるオープンな指示データは、十分に整備されていないのが現状です。
プロジェクト開始時点で利用可能だったデータセットは、言語モデルの発展初期段階ということもあり、dollyやoasstなど、英語で作成された指示データセットを自動翻訳したものがほとんどでした[17]。
このような状況では、日本語の言語的な特性や文化的な背景を十分に反映したファインチューニングを行うことが難しくなります。高品質な日本語指示データの不足は、日本語の大規模言語モデルの開発における大きな課題の一つと言えます。
ファインチューニングデータを自作する(手作業)
日本語のファインチューニング用データが不足していることが明らかになったため、チームでは完全にオープンな指示データセットを自作することにしました。このデータセットは、CC0ライセンスの下で公開され、誰でも自由に利用できるようにしています。
その成果物の一つが、「minnade chat」です[18]。このデータセットは、日本語の自然な会話や指示を収録しており、日本語の大規模言語モデルのファインチューニングに適しています。
このサイトでは、参加者が自由に質問や回答を投稿することができます。
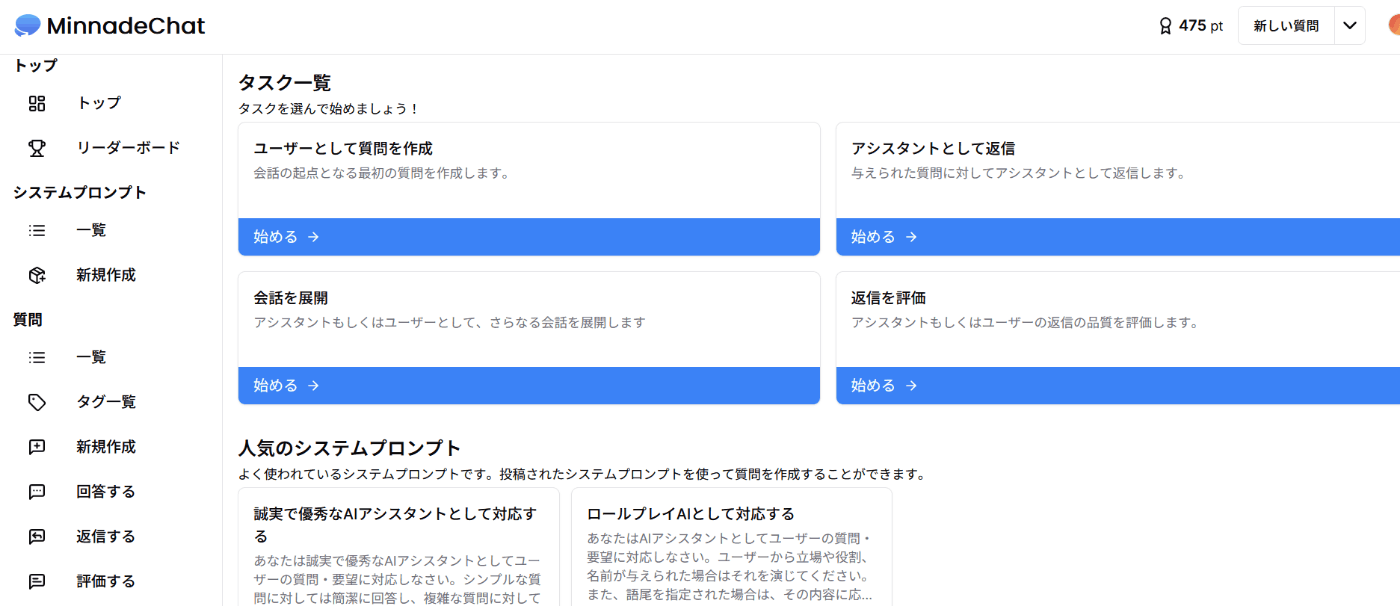
投稿されたデータは定期的にHugging Faceのレポジトリにアップロードされる仕組みになっています。
質問や回答、されにはそれらに対する評価を投稿するとポイントが加算され、ランキングに反映されるギミックもあります。このような報酬システムにより、参加者のやる気を促す仕組みです。
期待を遥かに上回るシステムを作ってくれたメンバー[18:1]に、大変感謝です。
このシステムの活用により、5/22時点で、数百件程度のオリジナルなデータを収集することができました。
指示データづくりは結構辛い
指示データを投稿するすばらしいシステムが完成したので、あとは放っておけば皆が次々とQ&Aを投稿してくれると期待していました。しかし、そう簡単にデータが集まるわけではないことがわかりました。実際に投稿してみるとわかりますが、指示データの作成は精神的に疲れるものです。質問文はある程度いい加減でも大丈夫[19]ですが、回答文にミスがあってはいけません。
データは自動生成した方が良いかもしれない
Metaが1000万件もの指示データを作成したことに疑問を感じるのは当然のことですが、筆者はそうではないと考えています。Llama3の紹介サイトには、指示データセットについて以下のような記述がありました。
Llama 3 Instruct has been optimized for dialogue applications and was trained on over 10 Million human-annotated data samples
(日訳)Llama 3 Instructは対話アプリケーション向けに最適化されており、1,000万以上の人間による注釈付きデータサンプルでトレーニングされています。
一般的に、"annotate"の訳語である「アノテーション」は、「機械学習やデータ分析の分野で、データに対してラベル付けやタグ付けを行うこと」(by GPT-4)を意味します。つまり、データセットはhuman-generated(人間によって作成された)のではなく、あくまでもhuman-annotated(人間によってチェックされた)に過ぎないのです。
英語でさえ、1000万件もの大規模な指示データセットは存在しないと考えられることから、Llama3の指示データの一定数は、AIによって自動生成されたものだと推測しています。
実際、今回の取り組みを通して、多くの質問に対しては、人間がゼロから回答文を作成するよりも、GPT-4に自動生成させた方が全体的にクオリティが高いことがわかってきました。
最終的には、自動生成された指示データをもとに、人間が手を加える(フィードバックする)というアプローチが、質と量の両方を担保する上で最善の方法ではないかと考えるに至りました。つまり、人間がAIの「赤ペン先生」になるというわけです。
救世主?としてのMixtral 8x22b
AIのトップ企業は、おそらくかなり前から自動データ生成のアプローチを活用してきたと推察されますが、この取り組みにはGPT-4のような高性能AIが必須である上、一般ユーザーには商用モデルの出力を学習に使用することを禁じる利用規約が課せられていました。そのため、自動生成のアプローチは一部のトップ企業以外では(少なくとも公には)活用できないというジレンマがありました。
この閉塞感を打ち破ったのが、2024年4月に公開されたMixtral 8x22bです。このモデルは寛容なapache2.0ライセンスで公開されており、出力を自由に利用できます。また、GPT-4には劣るものの、それなりに良質な出力(体感ではGPT-3.5レベル)を生成できるようになりました([こちらのサイト](https://labs.perplexity.ai/)から試せます)。
そこで、本チームではMixtral 8x22bを使った指示データの自動生成にも踏み込むことにしました。ユーザーが質問を投稿すると自動で回答してくれるスプレッドシートも準備し、より気軽にQ&Aを生成できる仕組みを整えました。

このシステムを通して、数百件以上の質問データを収集できたと思います。
GPUをフル活用した指示データの自動・大量生成
Mixtral 8x22bによって生成される回答は、個人的には60-70点くらいのクオリティだと感じています。日本に関連するドメインでは明らかなハルシネーションが多々含まれますが、論理的な思考力や国際的に通用する知識については、指示データとしても及第点の回答を出力します。
うまくクリーニングをすれば、十分に実用的なデータが得られそうだという手応えが得られたので、次はMixtralを用いて指示データセットを自動で大量生成することにしました。
質問データの生成アルゴリズムはいくつか試しましたが、代表的な手法は以下の3つです。
- 既存の質問に対する類題の生成
- 与えられた記事を元にQ&Aを生成
- ランダムなキーワードや数値を元にQ&Aを生成
特に最良の方法というわけではありませんが、ハルシネーションを多く含むQ&Aがあったり、期待通りの質問が生成できなかったりと、試行錯誤の連続でした。このあたりについては、今後さまざまな人が試すことでノウハウが蓄積されていくのではないかと思います。
大量の指示データを学習させる意図
筆者の目標は、Q&Aの自動生成を駆使して、「人類と行われるであろう質疑応答」を想定問答の形式で可能な限り網羅することでした。GPT-4を含む現在の大規模言語モデルは、本質的な意味での知能や推論能力を持っているとは考えていません。しかし、AIは並外れた量の努力をすることができます。そのため、この先人類と行われるであろう質疑を可能な限り多く指示データセットに含めておくことで、実用水準を満たす出力が得られるかもしれないと考えています。そのためには、とにかく多くのオリジナルな質問と自動生成されたQ&Aが必要でした。前者については、チームでの取り組みなどを通してある程度確保できたと言えます。
計算リソースの問題
ここでの解決策は、本プロジェクト(GENIAC)とは「別枠で推進していた研究成果を利用する」というものでした。筆者は大学の研究者で、研究テーマの一つに大規模言語モデルの学習・活用が含まれています。特に、Mixtralを使って人工データを大量生成するというタスク(やそのためのノウハウの集積)は、研究を進める上での重要課題でした[20]。
たまたま、筆者が本業で行っている研究で得られる成果物をGENIACにも転用できることがわかったので、一連の成果物は一般公開した上で、本プロジェクトでのファインチューニングにも活用しています。計算には、大量のH100 GPUが搭載されたTSUBAME 4.0も活用しました。
計算で得られたデータセットは以下の通りです。全部で100万件以上あります。
(※ハルシネーションを含む回答が多々あるので、人手によるフィルタリングが必要です)
最後に
本記事では、モデルアーキテクチャ、事前学習のデータセット準備、ファインチューニングのデータセット準備にポイントを絞り、どのような困難や紆余曲折があったかについて記しました。
肝心のScaling lawの壁を超えることができたと言えるのか?という疑問については、5/22時点では明確な回答ができません。まだモデルは事前学習中で、最終的な成果物が得られていないからです(今週末に学習が完了する予定です)。ただし、一連の試行錯誤を通して、少しずつではありますが、効率的にモデルを作るための知見やノウハウは詰めてきたのではないかと自分に言い聞かせている次第です。
(以上)
この成果は、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業「ポスト5G情報通信システム基盤強化研究開発事業」(JPNP20017)の結果得られたものです。
-
とにかく試行錯誤を重ねて、うまくいく条件、行かない条件を洗い出すことが重要だと考えています。 ↩︎
-
すみません、先行研究はきちんと調べてません。 ↩︎
-
lossの一種です。 ↩︎
-
期待通りにうまく行かなかった要因は、いくつかあります。最大の要因は、8bモデルの記憶容量は意外と大きかったということです。そのため今回のトークン数(200b)では、8bモデルに対して、必ずしもドメイン分割をする必要はないということがわかりました。例えば1000 bトークン程度のデータセットであれば、ドメイン分割して学習させる意義はあったかもしれません。 ↩︎
-
一応、Mergekitを用いて、各snapshotのモデルを軽くMoEマージしてみたりもしましたが、検討した範囲では、性能向上の兆しは見つけられませんでした(うまくマージすれば、良いモデルを作れる可能性はあるとは思います)。 ↩︎
-
最近の大規模言語モデルの学習は、過学習を避けるために1 epochで終えることが多いです。しかし、データ数に制約がある場合は、復数回のepochを回しても問題ないという報告があります。例えばこちらの記事が参考になります。 ↩︎
-
ただし、著作物を学習したモデルの頒布などについては、まだ細かなガイドラインが整備されておらず、難しい議論が続いています(2024/5/22現在)。 ↩︎
-
ただし上述の通り、モデル配布については、様々な議論や考え方があります。 ↩︎
-
これらの機関は、「商用利用」というキーワードに極度のアレルギーは持ちつつも、一方でCreative CommonsのCC-BY 4.0(商用や改変可)といったライセンスで、オープンアクセス論文を公開していることがよくあります。 ↩︎
-
最近、もっと多い方が良いというのがトレンドです(Llamaモデルなど)。Scaling law的には、学習効率がどんどん下がっていくのが課題です。 ↩︎
-
この値はトークナイザーの種類に応じて変化します。 ↩︎
-
処理速度という面では、Pythonは最適解ではないかもしれません。実際、類似文章の削除タスクなどでは、C言語でコンパイルされたスクリプトを利用しました。 ↩︎
-
クリーニングのしすぎで、データが減ってしまった可能性があります。加えて、実は日本語のWebテキストデータは、すでに枯渇気味なことが、今回の取り組みを通して分かってきました。 ↩︎
-
たとえばMTBench。GPT-3.5/4の出力は高品質なので、それを真似すれば、高性能なモデルを簡単に作ることができます。ただし、これらの商用モデルの出力をAI開発に使うことは、利用規約によって禁止されているので、学術用途以外での活用が、難しい状況です。 ↩︎
-
ファインチューニングを極めるという作業は、「人間との対話」にドメインを絞るというタスクとみなせるかもしれません。 ↩︎
-
このような問題意識の下、理研を中心に、高品質なデータセットichikaraが構築・公開されています。専門家がコストをかけて真面目に構築したデータセットということもあり、非常に高品質との評判です。ただし、商用利用にあたっては、契約が必要なライセンスになっています。 ↩︎
-
実際の運用時には、ユーザーは最小限の入力しかしたがらないため、ChatBotに対する指示が非常に簡潔で雑になる傾向があります(ご自身のChatGPTとのやり取りを見ると理解できるかもしれません)。このような雑な質問に対して、ユーザーの意図を正確に汲み取り、丁寧な回答をするシステムが理想的なChatBotと言えます。
つまり、指示データを作成するのは想像以上に大変だということがよくわかったのです。実際、AI企業は協力者に高い報酬を支払って(時給5000円のケースもあります)、指示データを作成しているようです。
今回のプロジェクトには意欲的な方々が多く集まっていますが、それでもMetaのように1000万件もの指示データを作成するのは、さすがにきついということがわかってきました。 ↩︎ -
専門・日本語ドメインのように学習可能なデータが少ない領域において、どうやって情報を水増し(オーグメンテーション)して言語モデルに学習させるかという課題に悩み続けていました。例えば、こちらのpreprintを書きました。 ↩︎
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion