はじめに
こんにちは、松尾研GENIACプロジェクト、チームビジネスの前河利治です。
東京大学松尾研究室にて、経済産業省によるGENIACの国産大規模言語モデル(Large Language Model: LLM)開発に参加しています。
私たちの開発チームは、ビジネスに有用なLLMの開発を目指し、ビジネスの現場で活躍するメンバーが数多く集まっています。
本稿ではビジネスに有用なLLMの開発に向けて私たちのチームがとったアプローチについて、主にGPU最適化についての側面から解説します。
採用したモデル構造
精度の高さで定評のあるLLaMAモデルを採用した。
パラメータサイズは、LLaMA2のものを参考にした。
また、計算効率を挙げるため、LLaMA3で使われているGQAを採用した。
・LLaMA2で使われているパラメータサイズ
Our Model 12.3B
{
"hidden_act": "silu",
"hidden_size": 5120,
"intermediate_size": 13824, ⇒ LLaMA2の値を参考
"num_attention_heads": 40, ⇒ LLaMA2の値を参考
"num_hidden_layers": 40,
"num_key_value_heads": 8, ⇒ LLaMA2の値を参考
"torch_dtype": "bfloat16",
"vocab_size": 100096
}
GQAについて
LLaMA3で使用されているGQA(Grouped Query Attention)は、Transformerモデルの効率を改善するためのメカニズムです。
GQAは、クエリ(Query)をグループ化して処理することで、計算量を削減し、メモリ使用量を最適化します。これにより、より大規模なモデルでも効率的な学習と推論が可能になる。
GQAの特徴と利点
- 効率的な計算:従来のアテンションメカニズムでは、全てのクエリが個別に処理されますが、GQAではクエリをグループ化することで、計算量が大幅に削減される。
- メモリ使用の最適化:クエリをグループ化することで、メモリ使用量が抑えられ、大規模モデルの学習が現実的になる。
- スケーラビリティ:効率化により、より多くのパラメータを持つモデルでも実用的に運用可能となり、高性能な結果を得られる。
GQAは、特に大規模な言語モデルの学習において、計算リソースを最適化し、性能向上に寄与する重要な技術です。LLaMA 3のような先進的なモデルでの実装により、高度な自然言語処理タスクでの応用が期待される。
計算環境
計算環境は、Megatron-DeepSpeedを採用した。
Megatron-DeepSpeedについて
近年、大規模言語モデル(LLM)は、自然言語処理分野において目覚ましい進歩を遂げ、様々なタスクで人間を超える性能を示している。
しかし、LLMの学習には、膨大な計算資源と時間が必要となる。例えば、GPT-3のような巨大なモデルを学習するには、数百台のマシンを数週間稼働させる必要がある。
この課題を克服するため、NVIDIAとMicrosoftはそれぞれ、大規模言語モデルの学習を効率化する技術を開発した。
それが、NVIDIAのMegatronとMicrosoftのDeepSpeedです。Megatron-DeepSpeedは、これらの技術を組み合わせることで、大規模言語モデルの学習を飛躍的に加速する強力なツールとして注目されている。
-
Megatron:
Megatronは、NVIDIAが開発した、大規模言語モデルを効率的に学習するための分散並列学習です。
Megatronは、巨大なLLM(大規模言語モデル)を複数のGPUに分割して学習する手法です。
特にTransformerのAttentionとFFN(Feed-Forward Network)を分割することに特化しています。
Attentionの分割では、Multi-Head Attentionの各ヘッドを異なるGPUで計算し、結果を共有します。
FFNの分割も同様に、重みを分割して各GPUで計算し、結果を統合します。これにより、巨大なモデルを効率的に学習が可能です。 -
DeepSpeed
DeepSpeedは、Microsoftが開発した深層学習の最適化ライブラリで、大規模なモデルの訓練と推論を効率的に行うための多くの機能を提供しています。
以下は主な機能の概要です:2-1. ZeRO (Zero Redundancy Optimizer):
- メモリ効率化: 大規模モデルの訓練時にメモリ使用量を削減し、GPUメモリに収まりきらないモデルでも効率的に学習可能にします。
- ZeRO-Offload: 学習パラメータをGPUメモリからCPUメモリにオフロードすることで、さらに大規模なモデルの学習を可能にします。
- ZeRO-Infinity: NVMeストレージにもオフロードすることで、極めて大きなモデルの学習をサポートします。
2-2. DeepSpeed Inference:
- 高速推論: テキスト生成などの推論を高速化し、スケーラブルな推論を実現します。
2-3. DeepSpeed-Chat:
- 大規模チャットモデルの訓練: ChatGPTのような大規模チャットモデルを簡単かつ高速に訓練するためのフレームワークです。
2-4. MoE (Mixture of Experts):
- 計算効率化: 入力データに応じてモデルの一部のみを計算することで、計算量や時間、コストを削減します。
2-5. Universal Checkpoint:
- 柔軟な学習再開: 学習途中で実行環境や設定を変更する場合に、保存したモデルやOptimizerの状態を異なる並列設定で読み込み、学習を再開できます。
モデル構造決定まで経緯
Tflopsを上げるため、Sequence Lengthを小さくし、
Activation CheckpointをFalseにした。
以下に、効果について説明する。
Sequence Lengthを小さくする。
Sequence Lengthを小さくすることで、モデルが処理するデータの量が減る。
これにより、各学習ステップや推論ステップで必要な計算量が減少し、結果として計算速度が上がる。
Activation CheckpointをFalseにする。
通常、ディープラーニングの学習中に、順伝播(フォワードパス)で計算されたアクティベーション(中間層の出力)は、逆伝播(バックプロパゲーション)で勾配を計算するために必要。これらのアクティベーションはメモリに保持されるため、大規模なモデルではメモリ使用量が非常に高くなる。
Activation Checkpointingは、このメモリ使用量を削減するために、特定のアクティベーションだけをメモリに保持し、必要に応じて他のアクティベーションを再計算する技術です。
モデルパラメータを最適に分割できるようにMP、PPを以下のように調整した。
MP=1,PP=6
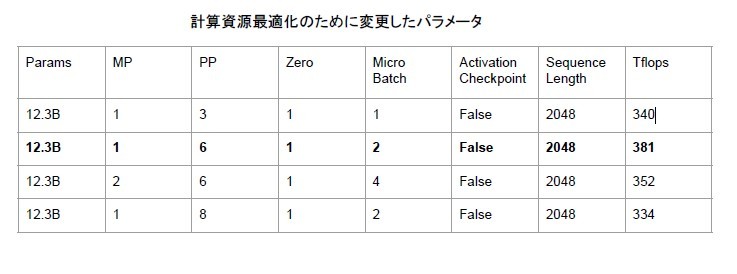
モデル分割でバランスが良い、12B_Layer40 FFN 13824を採用した。
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion