はじめに
こんにちは,松尾研 GENIAC LLM開発プロジェクト Team天元突破(Team尾崎)の板井孝樹です.
本記事ではTeam天元突破のキュレーションチームの取り組みについて報告します.
概要
Team天元突破では開発方針として 「LLMのハルシネーション逓減」 を掲げ,LLMの学習データ(事前学習データ・事後学習データ)の高品質化の取り組みに注力しました.Team天元突破の開発体制は以下の通りです.
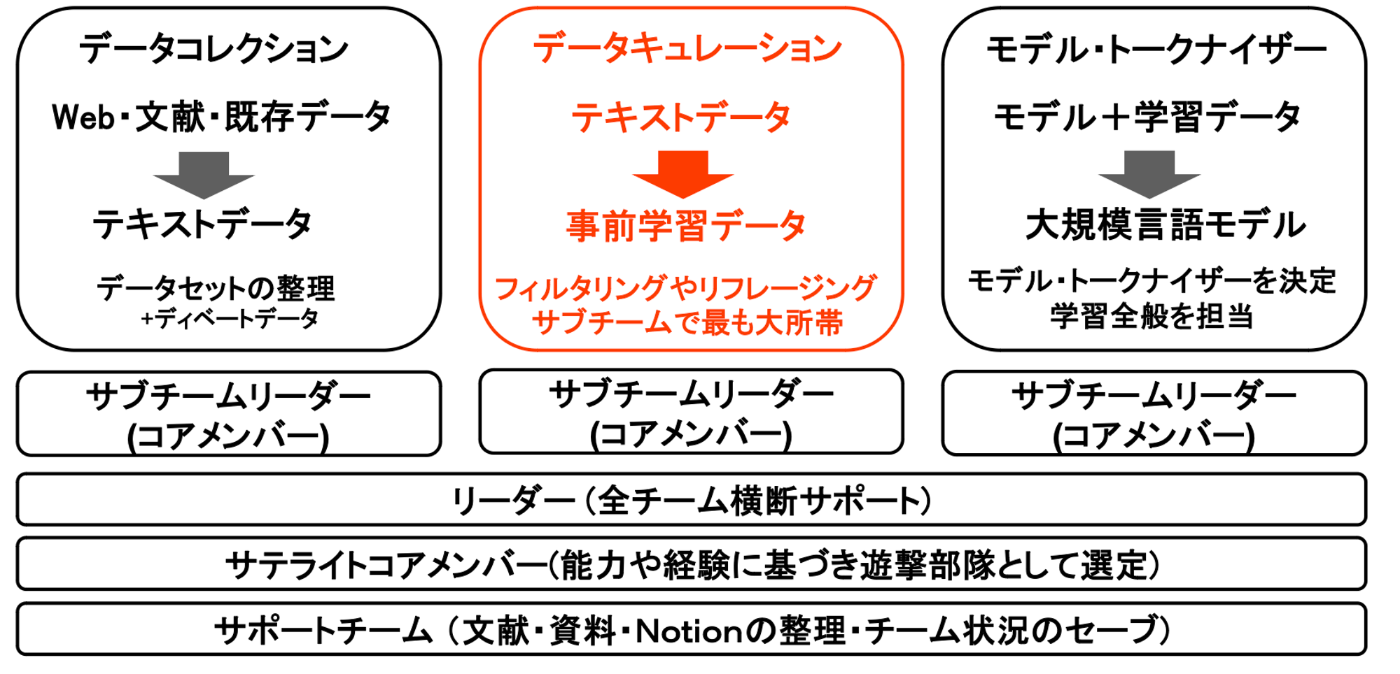
以下は,A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questionsから抜粋したハルシネーションの原因分類です. Data, Training, Inferenceの中でも我々はDataに着目し,ハルシネーションの逓減を目指しました.
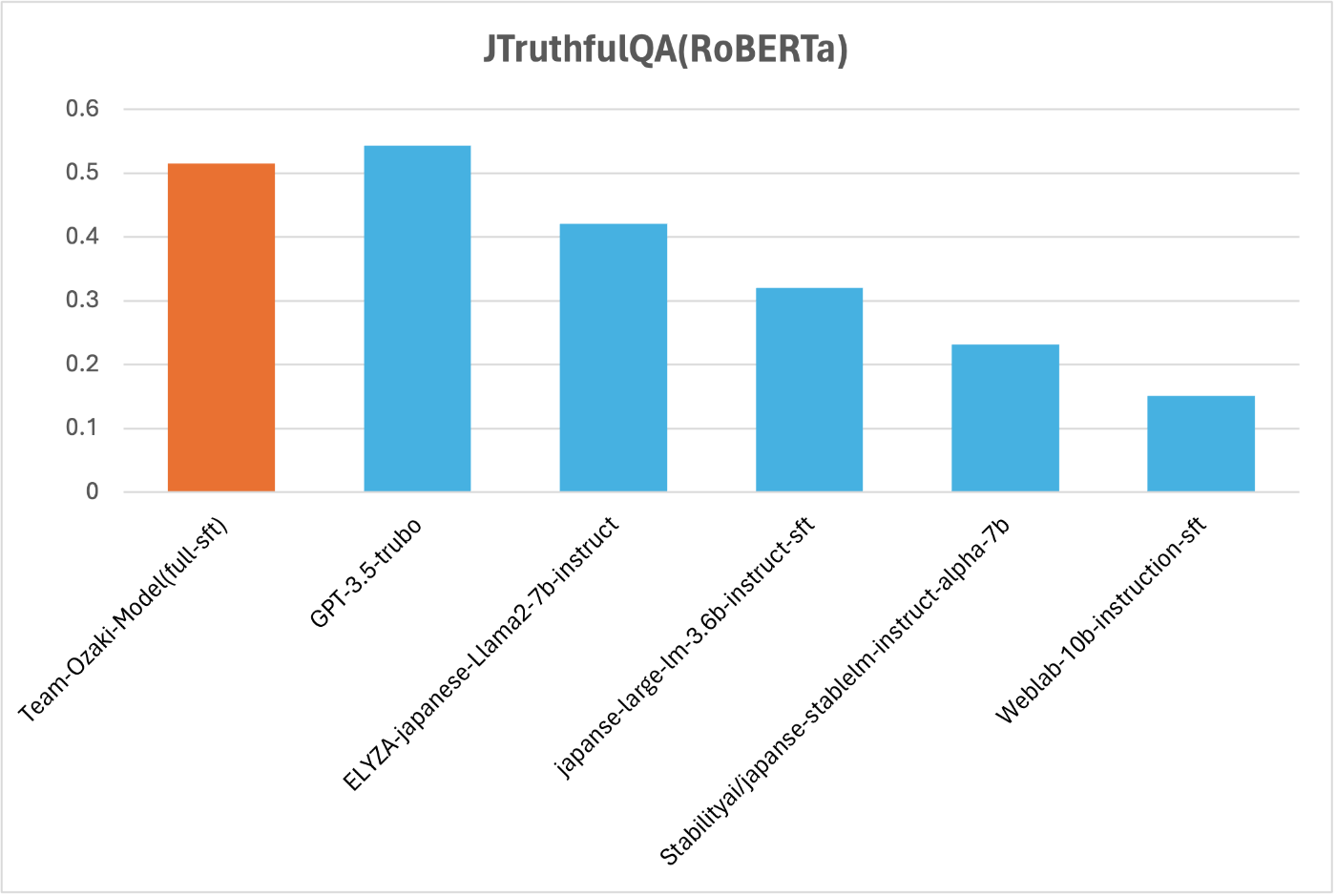
最終的に構築したモデルのJTruthfulQAのRoBERTaにより自動評価の結果は下図の通りです.JTruthfulQAはLLMの真実性(信頼性・安全性)を測るベンチマークであり,我々のモデルは真実性の観点において,GPT-3.5-turboに匹敵する優れた性能のモデルを構築することができました.
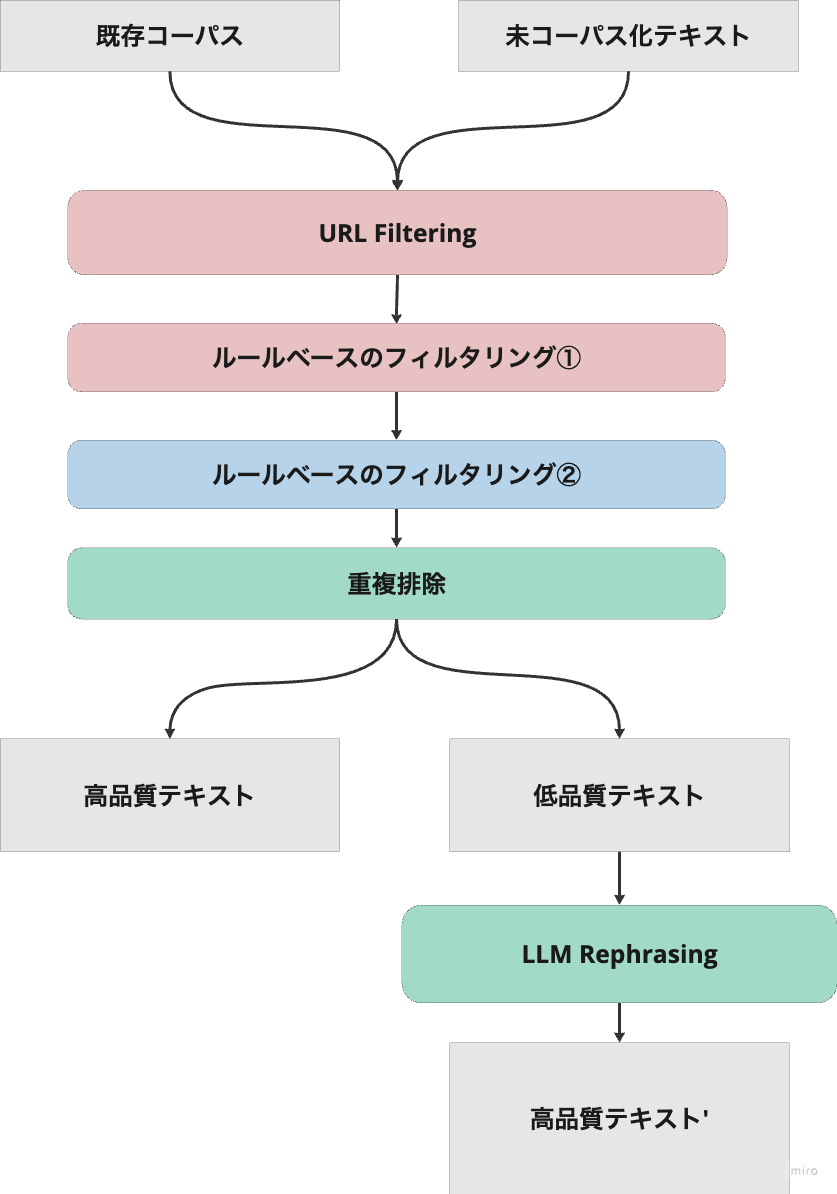
データキュレーションチームでは主に以下の取り組みを行いました.
- LLM-jpやRefinedWeb,Swallowコーパスで実施された日本語向けフィルタリング処理を実装
- 英語やその他コーパスは既に高品質なものを使用
- 一部LLM Rrephrasingを実施し,低品質なテキストを高品質化
Team天元突破におけるキュレーションの流れは下図の通りです.
キュレーションチームの開発方針
日本語コーパスの現状
Scaling則[Kaplan 20, Wei 22]によると,10Bモデルの学習には200B近くのトークン数のデータセットが必要であると考えられます.開発当時の国内の代表的なLLMの取り組みとして,Weblab-10Bでは314Bトークン,llm-jp-13b-v1.0では138Bトークンによる日本語の学習が行われていました.代表的な日本語コーパスとして以下が挙げられますが,いずれも低品質なデータが多量に含まれていることを確認し,ハルシネーションの逓減を目的とした質の高い学習のためには低品質なデータの扱いが重要であると考えられました.
一般的に議論されている高品質コーパスの基準としては以下のようなものが挙げられます.
- Wikipediaや書籍の文章のように,長文かつ一貫性のある文章
- 重複データが含まれていない(過学習を助長するため)
- データの多様性が確保されている
※ 合成データ(LLMで生成した文章)を高品質なデータとして扱うべきかという議論については賛否が分かれている.
また低品質なテキストとしては以下のようなものが挙げられます.
- クローリングデータに特徴される単語の羅列
- URL・ID等が混在した文章

高品質テキスト(左)と低品質テキスト(右)の例
最終的に得たいLLMの生成は,上図の左側のような自然な日本語文章です.LLMの学習データの質は生成の結果と直結すると考えられるため,高品質なテキストをどれだけ収集することができるか,低品質なテキストをいかに排除・高品質化するかが,高い性能のLLMにおいて重要であると言えます.
キュレーションの方向性議論
開発当初キュレーションの方向性について,大きくFiltering・Generating・Rephrasingの3つが挙げられ,以下の表のような議論が行われました.本チームではハルシネーションの増大を懸念して,Generatingは採用せず,FilteringとRephrasingにより,既存データセットの低品質データ排除・高品質化に取り組みました.
| Filtering | Generating | Rephrasing | |
|---|---|---|---|
| 概要 | 低品質なデータを取り除く(ルールベース or MLベース) | LLMを使用して新しく学習用のテキストを生成する | 既存のデータセットをLLMで言い換えて綺麗な文章にする |
| メリット | 高品質なデータを抽出できる・手法によっては比較的高速 | 日本語の学習トークン数を増やすことができる・ジャンルやトピックを自由自在に生成できる | データ量・知識を失わずに高品質なテキストに変換できる |
| デメリット | データサイズが減ってしまう→知識が減少する懸念 | データの多様性が失われる可能性→ハルシネーションが増大する? | 生成に時間がかかる,使用するLLMの性能に依存する |
| 代表例 | RefinedWeb | Textbooks are All You Need | Rephrasing the Web |
事前学習データセットのキュレーション
最終的にTeam天元突破で用いた事前学習データは下の表の通りです.日本語,英語,数学,コードを含めた約176BTのデータセットを構築しました.
| データセット | サイズ | 概要 |
|---|---|---|
| (日) Web-ja | 111BT | CulturaX(70BT),japanese2010(40BT),CommonCrawl(1BT)から成る大規模なWeb日本語コーパス |
| (日) Wiki-ja | 1.5BT | wikipediaをLLM-jp Corpusのスクリプトでフィルタリングした高品質日本語コーパス |
| (日) Scraping-ja | 0.2BT | Wikitionaryなどスクレイピングして得たコーパス |
| (英) Web-en | 20BT | SlimPajama |
| (英) Paper-en | 14.5BT | SlimPajamaの論文由来コーパス |
| (英) Wiki-en | 7.7BT | SlimPajamaのwiki由来の高品質コーパス |
| (数) Math | 15BT | 英語の数学ドメインコーパス:Open-web-math |
| (コ) Code | 6BT | Python(+α)のコードコーパス:algebraic-stack |
| (+α日) news-ja/wikinews-jadocci-ja jetcopper-ja/J-ResearchCorpus | - | 終盤に追加した高品質日本語コーパス |
調査・検証
CommonCrawlデータの問題点の調査
事前に,実際にデータセットの文章を目視で確認して,フィルタリングで取り除くべきと考えられる文章や表現の洗い出しを行いました.挙げられた問題点は以下の通りです.
- 単語の列挙
- クローリングデータに特徴される単語の羅列
- パンクズリスト
Disney Parks.info > トピックス > 6月11日
- 個人情報の混在(マスキングが必要)
名前,電話番号,メールアドレス,住所など - 広告データ
製品の広告や販売情報(例: 製品価格,販売情報)が含まれている場合,これらは一般的な言語使用を反映していない可能性があり,言語モデルのトレーニングには適していない場合がある. - コピーライト
Copyright,©︎,(C)など - 意味のない文字列や,無関係な情報
nپ@“ٹچeژزپF‚ئ‚µ‚«پ—ڈh’ - ヘッダーやフッターのタグの残存
- 3点リーダ(...)
- 文章中のURL
- 重複文
ヒッグス粒子を探せ\n〜質量の起源にせまる〜\nヒッグス粒子を探せ\n〜質量の起源にせまる〜
既存フィルタリングルール・プロジェクトの調査
詳細は割愛しますが,以下の通りです.
- The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher (Rae et al,. 2022)
- HojiChar: テキスト処理パイプライン
- 日本語 LLM 構築におけるコーパスクリーニングの網羅的評価
- Swallow コーパス: 日本語大規模ウェブコーパス
- llm-jp/llm-jp-corpus
- lighttransport/japanese-llama-experiment
実装
ルールベースフィルタリング
ルールベースフィルタリングでは,既存のSwallowコーパス,RefinedWeb,MassiveWebをベースに実装しました.実装はTeam天元突破のGithub(oss-llm-japanese/src/preprocessing/filtering)から確認できます.
これらのフィルタリング処理により,既存の日本語コーパスにおける,全体の40%に及ぶ低品質なデータを削除しました.

Swallowコーパスにおけるフィルタリングの流れ(第6回 Data-Centric AI勉強会,東工大Swallowプロジェクトにおける大規模日本語Webコーパスの構築より引用)
実装の分類として以下のように切り分けを行いました.
- 前処理:文章を編集するが,フィルタリングはしない(URLの除去など).
- フィルタリング①:アダルト系などの有害コンテンツや情報量が少なすぎる文章(削除するもの)
- フィルタリング②:キーワードの羅列などで内容は有益だが形式が悪い文章(Rephrasingに回すため,削除せずに別で保存する)
前処理
-
個人情報のマスキングフィルタリング
電話番号,メールアドレスをマスキングするHojicharののMaskPersonalInformationを実装 -
コピーライトの削除
「Copyright", "©", "(C)", "COPYRIGHT", "copyright」を検出して削除するフィルタリングを実装 -
URL・謎文字の削除
- URL:http:などのurlを削除する機能を実装.(ftp: や日本語を含む場合も対応)
- 謎文字:「nپ@“ٹچeژزپF‚ئ‚µ‚«پ—ڈh’」のような謎文字の除去
変換前:
"text": "新町(しんまち)は、千葉県(https://life-style.chiba.jp/)佐倉市の町丁。郵便番号285-0023。\n地理.\n北は鏑木町・nپ@“ٹچeژزپF‚ئ‚µ‚«پ—ڈh’・並木町・中尾余町・最上町、東は弥勒町、南は野狐台町・裏新町・鏑木町、西は鏑木町と宮小路町に隣接している。変換後:
"text":"新町(しんまち)は、千葉県()佐倉市の町丁。郵便番号285-0023。地理.北は鏑木町・n@“eF‚‚‚«—h’・並木町・中尾余町・最上町、東は弥勒町、南は野狐台町・裏新町・鏑木町、西は鏑木町と宮小路町に隣接している。一部謎文字は残ってしまう現象が確認されましたが,これらは後述するLLM Rephrasingにより,排除が可能であることが確認できました.
-
連続する記号の削除
—や++,**など記号が2連続しているものの除去
フィルタリング①
-
繰り返しの多いWebページ
Swallowコーパスを参考に,以下を実装しました.これらはMassiveWebのルールがそのまま採用されています.- 他の行と重複する行数 / 全行数 (0.30)
- 他の段落と重複する段落数 / 全段落数 (0.30)
- 他の行と重複する行に含まれる文字数 / 全文字数 (0.20)
- 他の段落と重複する段落に含まれる文字数 / 全文字数 (0.20)
- 最頻出の2-gramの出現回数 / 全2-gramの出現回数 (0.20)
- 最頻出の3-gramの出現回数 / 全3-gramの出現回数 (0.18)
- 最頻出の4-gramの出現回数 / 全4-gramの出現回数 (0.16)
- 2回以上出現する5-gramの総出現回数 / 全5-gramの総出現回数 (0.15)
- 2回以上出現する6-gramの総出現回数 / 全6-gramの総出現回数 (0.14)
- 2回以上出現する7-gramの総出現回数 / 全7-gramの総出現回数 (0.13)
- 2回以上出現する8-gramの総出現回数 / 全8-gramの総出現回数 (0.12)
- 2回以上出現する9-gramの総出現回数 / 全9-gramの総出現回数 (0.11)
- 2回以上出現する10-gramの総出現回数 / 全10-gramの総出現回数 (0.10)
-
最小文字数のフィルタリング
文字数が400文字未満の文章を除去.HojicharのDocumentLengthFilterを実装. -
ひらがなの文字の割合
文中のひらがなの割合が0.2未満の文書を除去 -
カタカナの文字の割合
文中のひらがなの割合が0.5以上の文書を除去 -
日本語の文字(平仮名,カタカナ,漢字,句読点)の割合によるフィルタリング
文中の平仮名,カタカナ,漢字,句読点の割合が0.5未満の文書を除去 -
有害な表現を含む文章のフィルタリング
llm-jp-corpusのis_not_adult_content,is_not_discrimination_content,is_not_violence_contentをベースとして,有害な単語辞書をからのキーワードが3つ以上含まれる場合に除去
フィルタリング②
-
文章中の文の文字数の平均によるフィルタリング
- 文章中の文の文字数が最小閾値以上最大閾値未満の文章を除去するフィルタリング
- llm-jpの
has_good_average_sentence_lengthと, HojicharのDiscardRareKutenを改造して作成
-
最も長い文の文字数 によるフィルタリング
- 最も長い文の文字数が200文字以上の場合は除去
-
広告文章のフィルタリング
- llm-jpの
is_not_ad_contentをベースに実装
- llm-jpの
URLフィルタリング
URLフィルタリングでは,既知の有害なデータソースからのページを排除することを目的としています[Nguyen et al., LREC-COLING 2024]. CulturaXではUT1 blocklistにより,pornography(ポルノ), grumbling(不平不満),hacking(ハッキング)等の関連サイトが含まれています.このリストは人間や機械により,週に2~3回更新されており,370万ものレコードが含まれています[Abadji et al., 2022].
SwallowコーパスやRefinedWebでの同様の取り組みがされており,ブロック対象はそれぞれ以下の通りです.
-
Swallowコーパス:
1. UT1 blocklist10に収録されている 2. 出会い系サイトのサービス名を一度でも含むページの割合が 0.001 を超える場合 3. NG 表現を含む割合が0.005を超える場合 4. *wikipedia.org 5. *.5ch.net -
RefinedWeb:
1. UT1 blocklist10に収録されている 2. スコアリングで点数が閾値を超えたもの soft,hard,strictの3つのスコアリング - strict:サブ文字列内に禁止された単語と一致するURLを禁止 - hard:リスト内の単語と完全に一致するURLを禁止 - soft:最低2つの一致が必要
Team天元突破では上記の内容を加味して以下の方針で実装を行いました.
| 対象 | 条件 | 備考 | 結果 |
|---|---|---|---|
| トップレベルドメイン | 一致すればOK | llm-jp-corpusからja_valid_domains.txt を取得 | 2.0%削除(CC(lang=ja判定済み)の9099 URLで検証) |
| ブロックリスト | マッチしたらNG | UT1 blocklistを使用.件数は多い(450万)が,日本語サイトは少ないため, ja_valid_domains.txt で絞り込んで(80万)使用 |
0.5%削除(CC(lang=ja判定済み)の9099 URLで検証) |
| ブロックリスト(追加) | マッチしたらNG | Swallowコーパスに習って「wikipedia.org,5ch.net」を追加.独自で「-av , porn , -sex , xvideos」を追加 | 0.0%削除(CC(lang=ja判定済み)の9099 URLで検証) |
重複排除
技術選定
SimHash,MinHash,RETSimの3手法が議論に上がりました.最終的には処理速度と実装(導入)の容易さからtext-dedup(MinHash+LSH)に決定しました.
日本語Webコーパス2010(japanese2010)のdedupを例にとると,dedup前は3,656,120件であったのに対して,text-dedupの適用後,削除されたデータは162,533件であり,4.45%重複したデータであることがわかりました.
技術選定において参考にした文献は以下の通りです.
- In Defense of MinHash Over SimHash
- MinHash — How To Deal With Finding Similarity At Scale With Python Code To Get Started
LLM Rephrasing
上述した通り,LLM Rephrasingは,LLMを用いて既存のデータセットを高品質なテキストに書き換える手法です[Maini et.al, 2024]. 合成データにより,データセットの多様性を確保した上で回答の品質を高めることができることが可能であると考えられます.
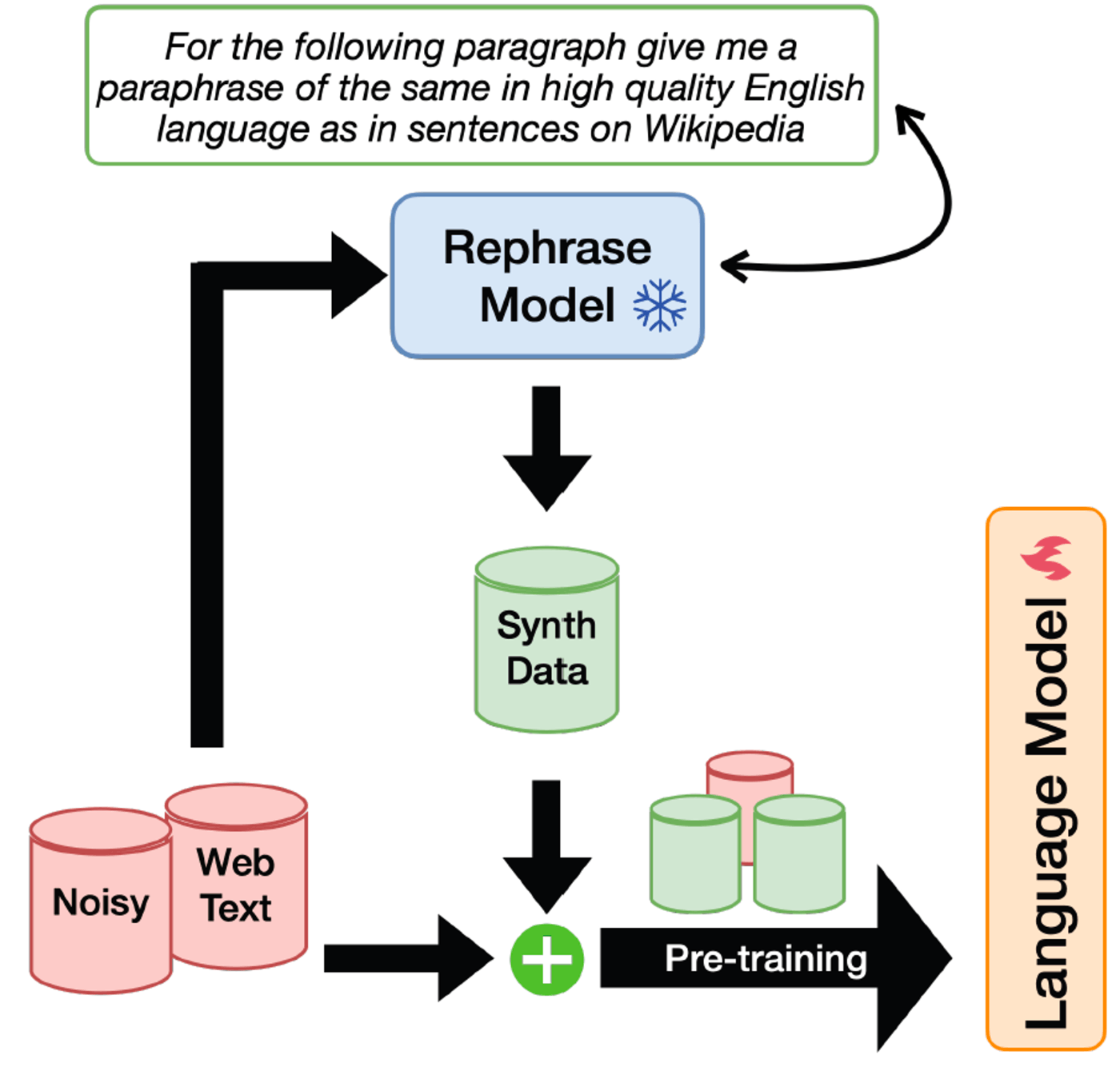
LLM Rephrasingの概要図(Rephrasing the Webより引用)
Rephrasing the Webでは,以下の4種類の書き換えスタイルが設計されています.今回はMediumおよびQAによるRephrasingを行いました.
- Easy:幼児が理解できるような非常に少ない語彙と極めて簡単な文章を使って書き換え
- Medium:ウィキペディアの文章と同じように,質の高い日本語で多様な書き換え
- Hard:博学な学者だけが理解できるような,非常に簡潔で難解な言葉を使った書き換え
- QA:"Question: "の後に "Answer: "が続く複数のタグを使った会話形式に書き換え
商用利用が可能な以下のモデルを用いて,事前に検証を行いました.
- lightblue/karasu-7B-chat
- tokyotech-llm/Swallow-MS-7b-v0.1
- Rakuten/RakutenAI-7B-chat
- HachiML/Swallow-MS-7b-v0.1-ChatSkill
最終的に,生成結果が良好であったlightblue/karasu-7B-chat,Rakuten/RakutenAI-7B-chatの2つのモデルを切り替えながらRephraseするように実装しました.
if task_id % 2 != 0:
# task_id が奇数の場合 karasu
model_name = "lightblue/karasu-7B-chat"
else:
# task_id が偶数の場合 rakuten
model_name = "Rakuten/RakutenAI-7B-chat"
LLMのPromptは以下のように設計しました.
- Medium:
次の入力について、ウィキペディアの文章のように、質の高い日本語で多様な言い換えをしてください。 - QA:
次の段落を、「質問」の後に「回答」が続く複数のタグを持つ会話形式に変換してください。
またPromptについては,few-shotによる実装を行いました.まず,CulturaX等の実データに対してMedium・QAをそれぞれ10件ずつ人手でRephrasingした合計20件のExampleデータを構築しました.実際に各データセットに対してRephrasingを適用する際は,これらのExampleからランダムに2件をPromptに加える実装を行いました.
Filtering処理では,謎文字の除去の過程で,一部謎文字が残存する現象が見られましたが,LLM Rephrasingにより,以下のように修正が可能であることを確認しました.
Rephrasing適用前:
"text":"新町(しんまち)は、千葉県()佐倉市の町丁。郵便番号285-0023。地理.北は鏑木町・n@“eF‚‚‚«—h’・並木町・中尾余町・最上町、東は弥勒町、南は野狐台町・裏新町・鏑木町、西は鏑木町と宮小路町に隣接している。
Rephrasing適用後(karasu-7B-chat):
この地域は、千葉県佐倉市に位置しており、郵便番号は285-0023です。この地域の特徴として、北は鏑木町や弥勒町、並木町、最上町などがあり、東は弥勒町、南は野狐台町や裏新町、鏑木町、西は鏑木町や宮小路町が隣接しているという点が挙げられます。また、地理的な特徴としては、鏑木町と宮小路町に隣接しているという点が特徴的です。
事後学習データセットのキュレーション
最終的にTeam天元突破で用いた事後学習データは下の表の通りです.日本語,数学,コード,LLMによる合成データを含めた合計121,414サンプルのデータセットを構築しました.
| データセット | サンプル数 | 概要 |
|---|---|---|
| chatbot-arena-ja-karakuri-lm-8x7b-chat-v0.1-awq | 12474 | chatbot-arena-jaの不要なQAをフィルタリング+回答をkarakuri(8x7b)で生成 |
| WikiHowNFQA-ja_cleaned_newans | 6545 | 「~する方法」に関するQA |
| Hachi-Alpaca_newans | 27805 | Alpacaデータ回答をkarakuri(8x7b)で生成 |
| oasst1-oasst2-ja_single_deduped | 13223 | OASST1,2の1ターン面の会話を抽出 |
| AnswerCarefully | 945 | 有害・不適切な回答を控えるQA |
| databricks-dolly-15k-ja-newans | 14681 | dolly-jaの回答をkarakuri(8x7b)で生成 |
| llm-ja-train | 1191 | llm-jp-evalの練習問題(自作) |
| JaGovFaqs-22k | 22794 | 官公庁サイトの「よくある質問」 |
| debate_argument_instruction_dataset_ja | 304 | ディベートの動画やPDFから作成 |
| Evol-hh-rlhf-gen3-1k_cleaned | 507 | Evol-Instruction、質問が複雑 |
| OpenMathInstruct-1-1.8m-ja_10k | 9985 | 算数・数学のQA(python回答+計算) |
| alpaca_jp_python | 10960 | pythonコードの生成・説明・修正 |
日本語の事後学習データセットに関する調査
既存の日本語のInstructionデータセットは,英語からDeepL等を用いて自動翻訳されたものが多く,意味や文法の誤り,日本文化的でないテキストなどが多く含まれることを確認しました.また応答が単語のみや短文の回答も目立ち,これらは学習において悪影響を及ぼすと考えられました.
LIMA: Less Is More for Alignmentで主張されているように,Instruction Tuningにおいては,少量で高品質なデータセットにより性能が向上することが知られています.下図に示す通り,LIMAでは7B程度の小規模なモデルでは最低2,000件のデータが必要であり,4000件以上に増やしても性能差は見られなかったとの報告がされています.
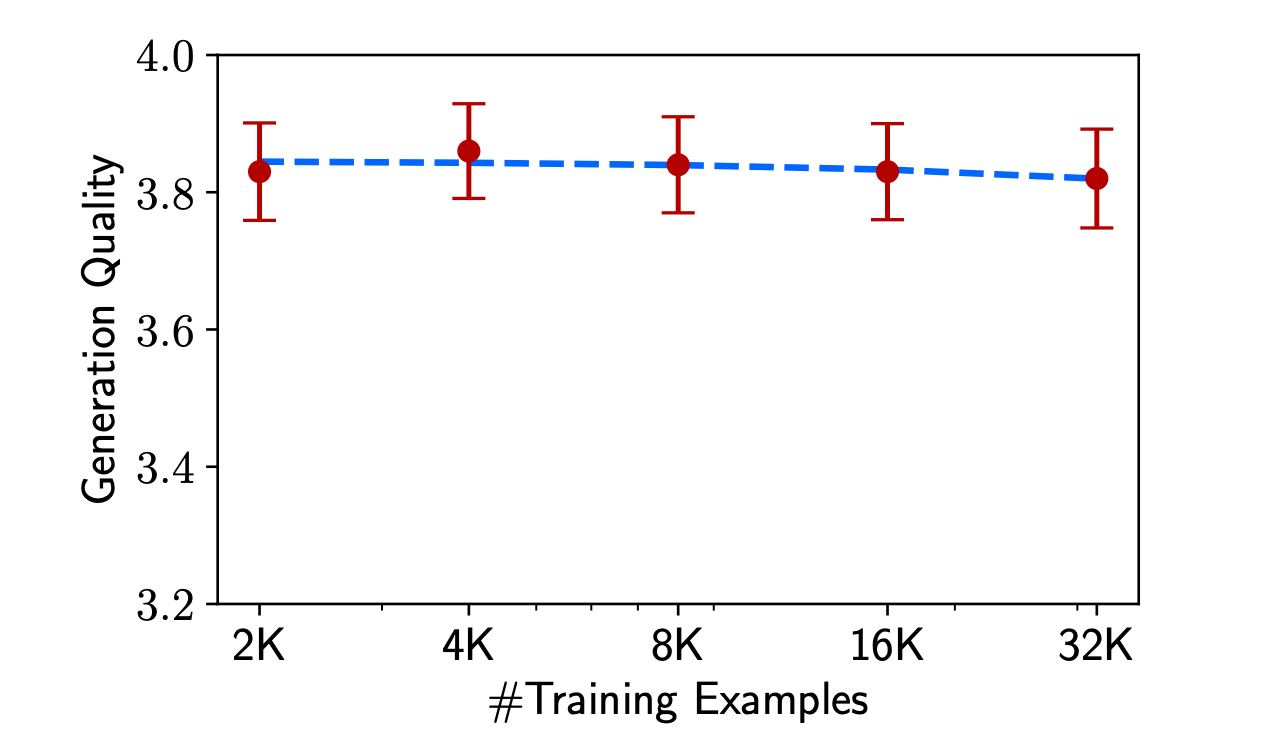
学習データ数と生成の品質の関係.データ量が最大16倍に増加しても,ChatGPTにより計測されたパフォーマンスは頭打ちとなる.(LIMAより引用)
可能であれば全てのデータを人手で確認し,校正することを行いたかったのですが,コンペにおける時間と人的リソースに制約がある中で,一から人手で高品質なInstructionデータを作るのは現実的ではないと考え,本チームでは既存データセットの高品質化による性能向上を狙いました.取り組みの方針は以下の通りです.
- 人手でデータをアノテーションし,「意味不明なQA」や「日本文化にそぐわないQA」削除
- 既存のQAのAnswerを高性能な日本語LLMで生成して回答の質を向上
最終的に上述の12万件程度のInstructionデータを構築し,単一モデルで当コンペにおける上位チームに迫るスコアを達成することができました.事後学習データの高品質化の取り組みにより,適切にモデルの性能向上を行うことができたと考えています.
実装
人手アノテーション
CyeberAgentのchatbot-arena-ja-calm2-7b-chat-experimentalに対して人手でアノテーションを行いました.このデータセットはChatbot Arenaを通して人間が作成した指示文であり,LLMのユースケースに近いと考えられますが,一部意味不明な質問が含まれていました.この約3万件のデータセットにおける質問文に対して,「使用可能」または「削除すべき」かを,人手でアノテーションを行いました.アノテーションの基準は以下の通りです.
-
使用可能
- 日本語が正しく内容も有益
ニューラルネットワークを並列化するには? - LLMへの入力としてあり得そうな文章
- 今日はいつですか? - 私の頭の中にある単語を当ててみてください
- 日本語が正しく内容も有益
-
削除すべき
- 意味不明な内容
- 「共有」の絵文字。リスト10 - 遠い昔、はるか彼方の銀河系で - 日本に馴染みのない内容
エデリックという名前と相性の良い50の姓のリストを教えてください。 - マイナーなプログラミング言語の問題
- 10B程度のモデルに解かせるには難しすぎる内容
- 意味不明な内容
LLMによる回答生成
Prefereceデータにおけるchosenにあたる高品質な回答データを作成するために,高性能な日本語LLMにQAタスクを遂行させる取り組みを行いました.当コンペ中にリリースされた高性能な日本語LLMとして,karakuri社のkarakuri-lm-8x7b-instruct-v0.1が挙げられ,こちらを採用することにしました.
以下のデータセットに対して回答生成を行いました.
- 人手でアノテーションを施したcyberagent/chatbot-arena-ja-calm2-7b-chat-experimental
- Lurunchik/WikiHowNFQA (日本語に翻訳した質問文に対して回答生成)
- kunishou/databricks-dolly-15k-ja
- HachiML/Hachi-Alpaca
まとめ
ここまでご覧いただきありがとうございました.
本記事では松尾研 GENIAC LLM開発プロジェクト,Team天元突破(Team尾崎)におけるデータキュレーションの取り組みについてまとめました.
日本は英語圏と比較すると学習データの質,量ともに劣っている状況です.私見にはなりますが,今後高性能な日本語LLMを構築する上で,データの高品質化,LLMによるLLM学習のための合成データ生成等の取り組みは重要度が高まるのではないかと考えています.本チームでの取り組みが今後の日本語LLM開発者にとって有益な知見となることを願います.
謝辞
この成果は,NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業「ポスト5G情報通信システム基盤強化研究開発事業」(JPNP20017)の結果得られたものです.
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion