はじめに
こんにちは、チーム「たぬき」です。
この記事では、大規模言語モデル(large language model; LLM)の性能を向上させるために不可欠な指示データセットの作成プロセスについて解説します。前回の記事(チーム「たぬき」ゴールデンウィークの現況)で触れたように、私たちは高品質な日本語データベースの構築と活用を重視しており、その核心にあるのが指示データセットです。これらのデータセットは、LLMが多種多様な指示に対応し、より自然で人間らしい応答をするために不可欠です。
指示データセット作成に重要なこと
指示データセット作成にあたって重要なことが、量と品質です[1]。大規模言語モデルの文脈では、既存のLLMを用いて指示データセットを自動で作成する試みがあります。この方法を採用すれば量は確保できますが、品質については疑問が残ります。また、最近では日本語のLLM開発の注目が高まっていることもあり、オープンに使用可能なデータが増えてきました。しかし、それでも十分にデータが存在するとは言えません。そこでチーム「たぬき」では、問題、回答、それらの評価を行うフレームワークであるMinnadeChatを作成して運用しています!!
MinnadeChat
MinnadeChatは、ichikara-instruction[2]やOpen Assistant[3]を参考に作成された、指示データセット収集システムです。
ユーザは、
(1) 質問の作成
(2) 質問への回答の作成
(3) 質問・回答の評価
ができます。
各項目を簡単に説明しましょう。
(1) 質問の作成
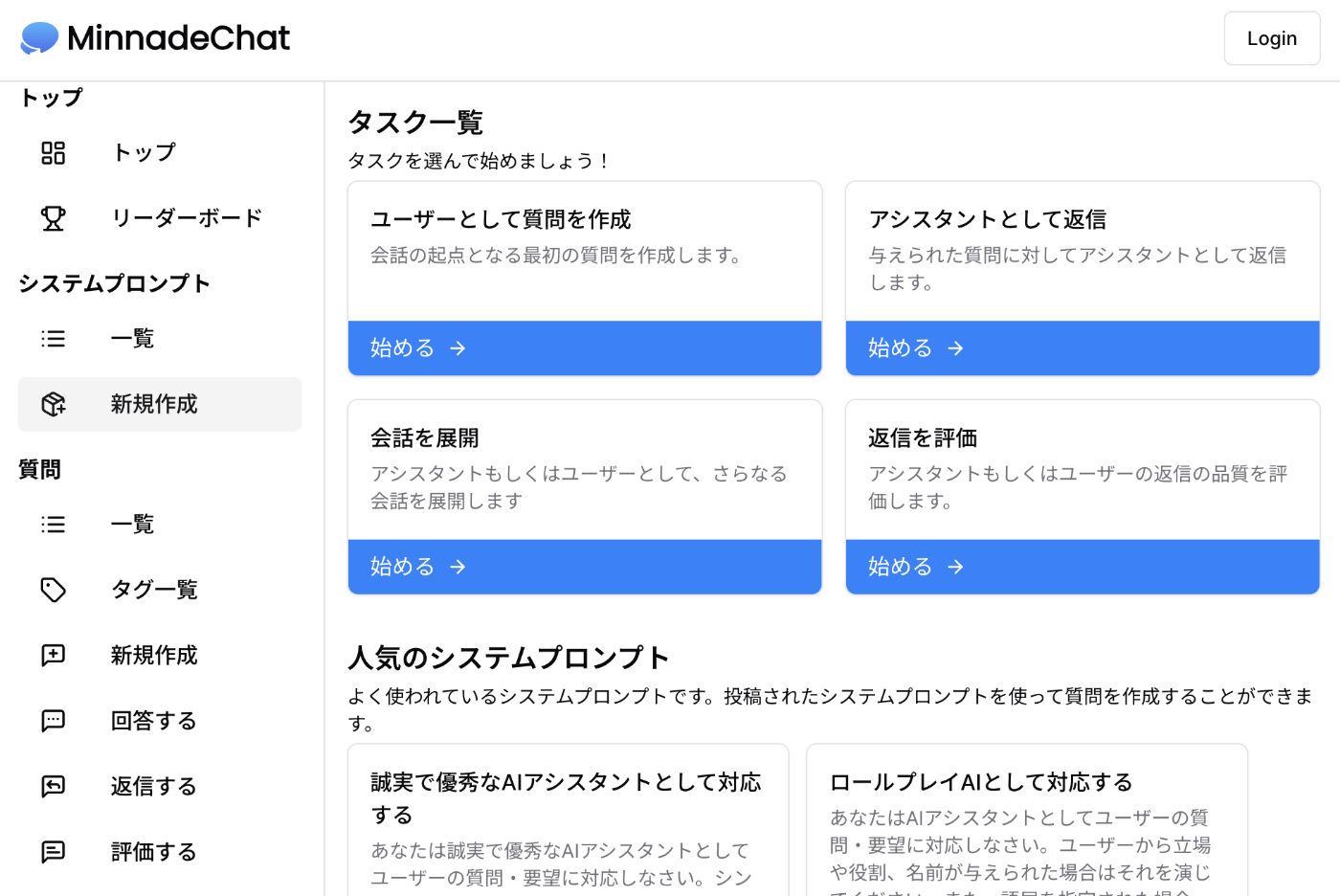
トップページにおいて、「新規作成」を選択すると、下の画像のような画面が表示されます。

質問作成画面
「質問の作成」では、タイトル、本文、カテゴリーなどの情報を入力します。
- 質問タイトル:質問を表す題名(例:円周率が3より大きいことを証明したい)
- 質問本文:LLMに入力する質問(例:円周率が3より大きいことを証明するにはどうすればいいですか?)
- カテゴリー:質問を表すカテゴリー(例:数学・計算問題)
ここで作成した質問が、次の回答の生成に登場します。
(2) 回答の作成
トップページにおいて、「回答する」を選択すると、回答の生成ができます。以下が作業画面です。

回答生成画面
ChatGPTのような対話型生成AIを利用したことがある方には馴染みのあるデザインではないでしょうか。ここでは、LLMになったつもりで、ユーザーの回答をします。
質問に答えられない場合にはスキップをするか、画面左側に表示されている別の質問を選択します。
ユーザは自身の得意分野において回答をすればOK。
より多様な指示データセットを作成するために、様々なバックグラウンドを持った方が参加しています。
(3) 質問と回答の評価
高品質なデータを作成するために、質問と回答の評価をしています。評価画面では、複数の観点から、質問と回答の品質をチェックします。
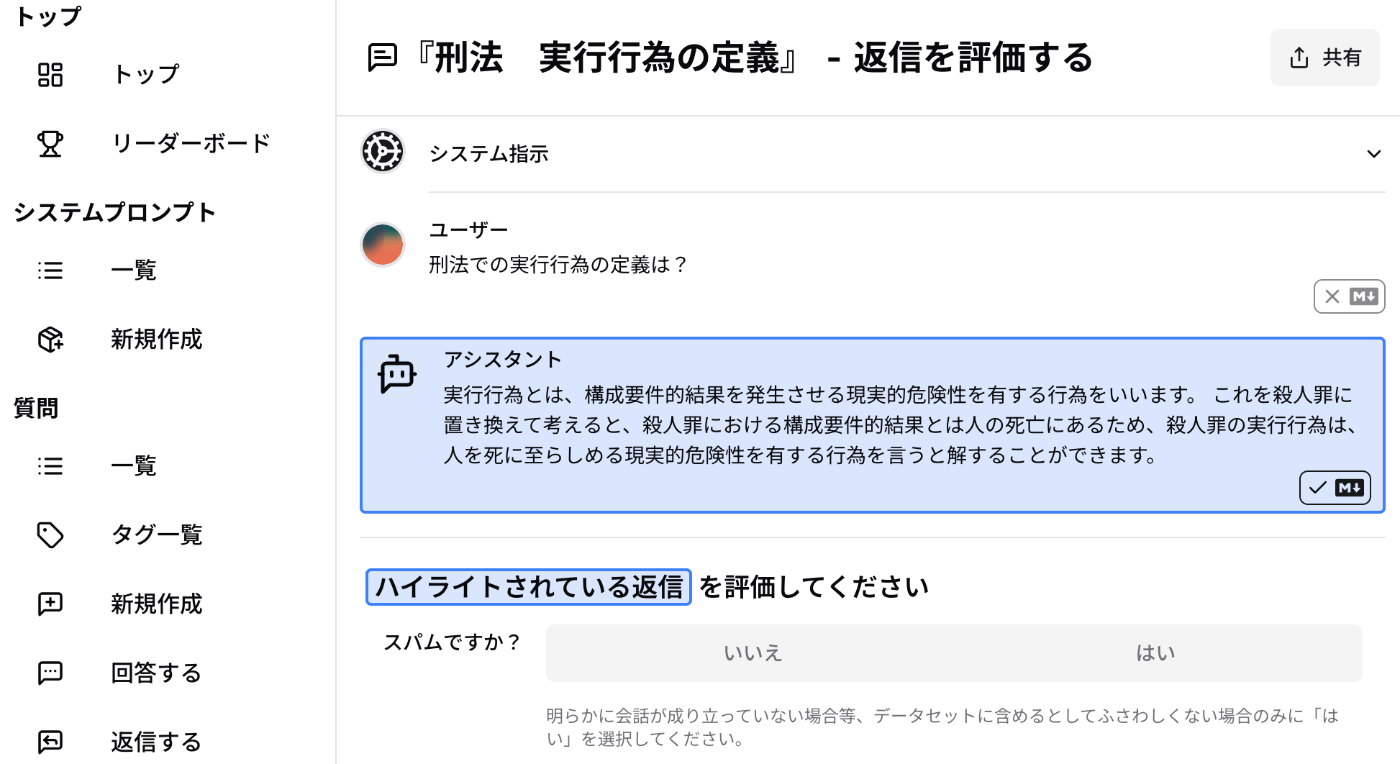
質問回答評価画面
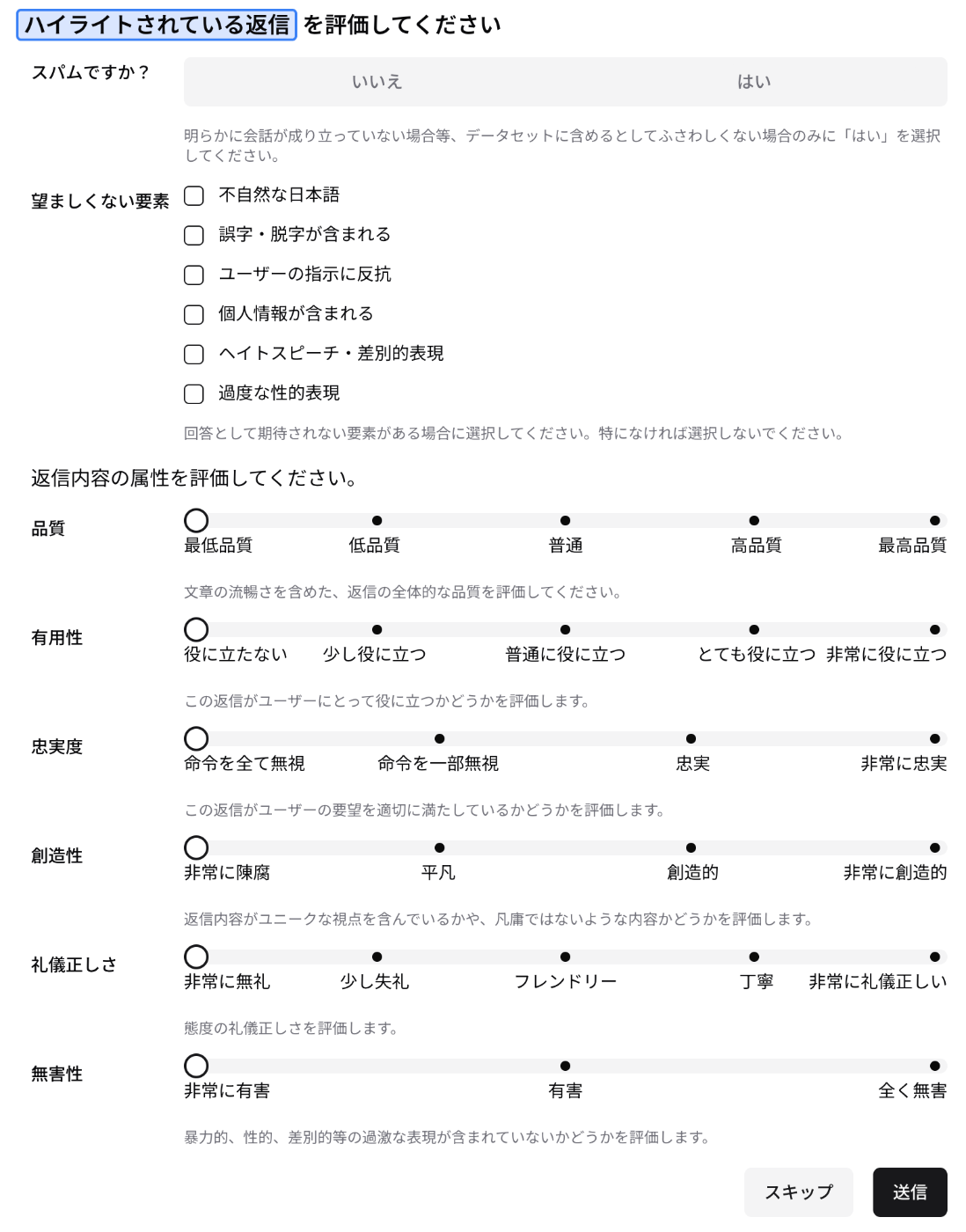
評価項目
以上の項目で得たデータを加工して、LLMのファインチューニングに使用します。
作成したデータ
MinnadeChatで作成されたデータは、以下のページに定期的にアップロードされるようになっています。どのような質問・回答があるのかはここから確認できます。
その他
MinnadeChatには、リーダーボードがあります。データを作成するとポイントがGetでき、自分の順位を確認することができます。この記事の執筆時、1位の方は5,000ptも獲得していました!これを読んだ方も、MinnadeChatに参加して、リーダーボードでの上位を目指してみてはいかがでしょうか?
ちなみに、MinnadeChatの開発はp1atdevさんが担当されています。システムに使用されている技術については、p1atdevさんの記事を参照ください。
さいごに
チーム「たぬき」では引き続きオープンにLLM構築およびデータセット構築に取り組んでいきます。プロジェクトやチーム外からの参加協力も大いに歓迎しております。興味のある方はお声がけください。
この成果は、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業「ポスト5G情報通信システム基盤強化研究開発事業」(JPNP20017)の結果得られたものです。
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion