はじめに
こんにちは。松尾研 GENIAC LLM開発プロジェクト、Team JINIAC の佐野敏幸です。Team JINIACでは、日本語LLMの構築でヒンディー語のデータを学習させることにも取り組みました。その取り組みについて報告します。
そもそもの動機:日本語データ不足の補強
LLM学習に用いる日本語データが英語データに比べて少ないことが、日本語のLLMを構築する際の障害になっています。日本語データの大きさは、英語データの10分の1以下ほどです。LLM構築には大規模なデータが必要ですが、そのための日本語データが不足しており、日本語LLM構築のネックとなっています。
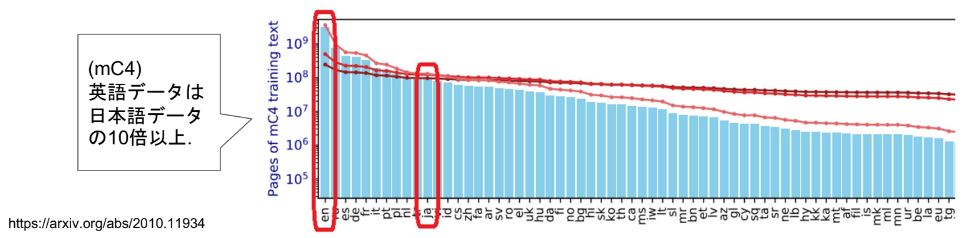
https://arxiv.org/pdf/2010.11934 より
そこで目を向けたのが、日本語と類似した言語です。私が知っている中では、ヒンディー語が日本語と近い文法を持っています。基本的な文法は、日本語と同じ
「S(主語)+O(目的語)+V(述語)」
の順番です。ほかにも、後置詞を用いる点、日本語の「様」「さん」にあたる言葉(जी)を使う点など、日本語と類似した点がヒンディー語には比較的多いのです。もちろん、ヒンディー語の専門家に話を聞くと、「いや、似てる点もあるけど、違う点も多い」と言われますが、英語と比べればヒンディー語の方がかなり日本語に近いので、一旦細かいことには目を瞑ることにしました。
ちなみに、インドの人口は10億人超で、そのうち4億人程度がヒンディー語を母語としています。ヒンディー語は世界で中国語、英語に次いで3番目に多く話されている言語です。話者数が多いことから、ヒンディー語のデータは大量にあるのかもしれない、という期待もありました。
ここまで、ヒンディー語について簡単にまとめると、
- ヒンディー語は日本語と類似した文法構造を持つ。
- ヒンディー語は話者数が世界で3番目に多い言語である。
ということです。
そこで、日本語データの不足をヒンディー語データで補えないか?と考えたことが、Team JINIACでヒンディー語を学習するそもそもの動機となっています。
もう1つの動機:知識転移
2023年に松尾研究室で構築されたLLMのWeblab-10Bでは、日本語と英語のマルチ言語混合データセットで大規模言語モデルの学習を行うことにより、日本語の性能を高められるかどうか実験を行っています。その際に、言語間の知識転移を確認できたとしています。
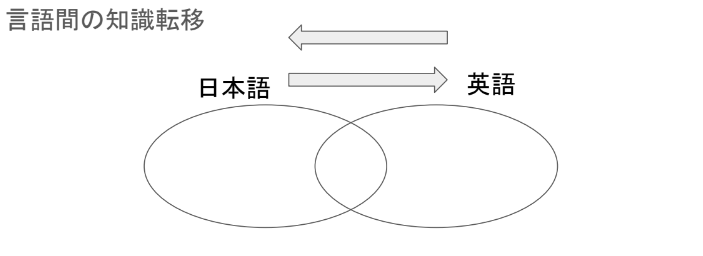
図:LLM勉強会2023-09-04「 日英2ヶ国語対応の大規模言語モデル “Weblab-10B” の構築(小島)」より
知識転移とはどういうことかというと、学習に用いた英語データセットの中にしかない知識を、日本語で引き出すことができるものです(逆も然り)。
知識転移が起こる理由について、私なりに仮説を考えています。それは、データセットの中に各言語をつなぐ単語が混ざっていて、それら単語が各言語世界の橋渡しをしているのではないかということです。
例えば、英語のデータセットの中に日本語の単語が混ざっているようなケースがあります。またその逆もあります。これらのコンタミ的な単語がいわば「結節点」となって、各言語の世界をつないでいるのではないか、ということです。
実際に、日本語データセットの中で英単語を検索して見つけることができます。
青空文庫( 著作権の消滅した文芸作品を中心に収集したデータセット。多少表現が古いものも含まれる。 https://huggingface.co/datasets/globis-university/aozorabunko-clean )で ”cat”、"fish”、”electricity” を検索すると以下のようなデータがあることがわかります。
“cat”を含むデータの例
…保吉は教室へ出る前に、必ず教科書の下調べをした。それは月給を貰っているから、出たらめなことは出来ないと云う義務心によったばかりではない。教科書には学校の性質上海上用語が沢山出て来る。それをちゃんと検べて置かないと、とんでもない誤訳をやりかねない。たとえば Cat's paw と云うから、猫の足かと思っていれば、そよ風だったりするたぐいである。…
”fish”を含むデータの例
…四つか五つの漢字が、如何に多くを伝えるかは、驚くばかりである。一例として、ここに Facing water shame swimming fish なる五つの漢字を並べたものがあるが、これを我々の言葉で完全に述べると、「魚が平穏と安易とを以て泳いでいる水のことを考えると、我々がこのように忙しい人間であることを恥しく思う」ということになる。これがどこ迄正しいか私は知らぬ。…
”electricity”を含むデータの例
レーリーの最初の講義は「物理器械使用法」で、次は「湿電気(galvanic electricity)と電磁気」であった。当時まだ galvanic electricity などという語が行われていたのである。聴講者はただの十六人であった。この数は彼の在職中あまり変化はなかった。当時の思い出を書いたシジウィック夫人(レーリー卿夫人の姉エリーノア)の記事に拠ると「彼が人々の研究を鼓舞し、また自分の仕事の援助者を得るに成効した所以は、主に彼の温雅な人柄と、人の仕事に対する同情ある興味とであった」。彼はこの教授としての仕事を充分享楽しているよに見えた。「彼の特徴として、物を観るのに広い見地から全体を概観した。樹を見て森を見遁すような心配は決してなかった。」「いつでも大きな方のはしっこ(big end)をつかまえてかかった。」「手製の粗末な器械を愛したのも畢竟同じ行き方であった。無用のものは出来るだけなくして骨まで裸にすることを好んだ。」
仮に英単語を知らない人がこれらの文章の中での英単語の使われ方からその意味を推測するとしたら、cat=猫、fish=魚、electricity=電気、big end=大きな方のはしっこ、と推測する確率は比較的高いと思われます。大規模言語モデルは、すごく大雑把にいえば単語の関連・並び順を確率的に学習したものであって、上記のようなデータを学習した場合には、例えば”cat”が「猫」についての知識とつながっていくことは想像に難くないです。他の英単語でも同様です。
英語、日本語、ヒンディー語のデータセットの関係
ちゃんとデータを調べたわけではないのですが、各言語データの中の他国語は、直感的にはおそらく次の表のようになっていると推測します。(「日本語の文章の中でヒンディー語の単語を今までに見たことがほとんどない」「日本語の文章の中で英単語を見たことがちょくちょくある」といった経験から推測しました)
各言語のデータセット中の他言語単語数の推測
| 日本語単語数 | 英語単語数 | ヒンディー語単語数 | |
|---|---|---|---|
| 日本語データセット | ◎ | 〇 | △~× |
| 英語データセット | 〇 | ◎ | 〇 |
| ヒンディー語データセット | △~× | 〇 | ◎ |
◎:多量にある、〇:そこそこある、△:かなり少ない、×:全くない
ここまでに述べた知識転移に関する「結節点」や、各言語データ中の他言語の単語数が正しいとすれば、2つの言語で学習したLLMでの知識転移の起こりやすさは、次のようになると考えられます。
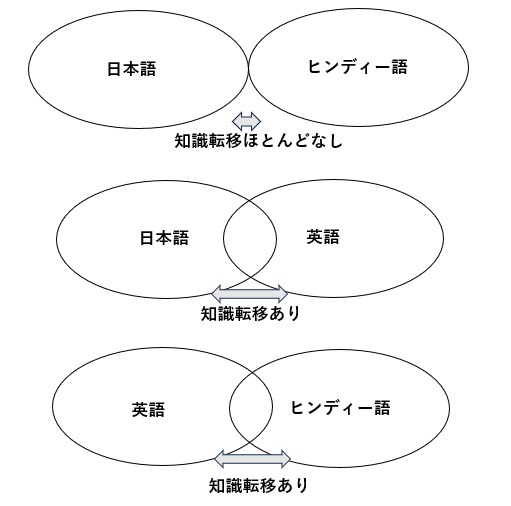
各言語間での知識転移の予想
日本語とヒンディー語の2言語でLLMを学習した場合、結節点の少なさから知識転移はほとんどないと推測します。しかし、日本語・英語・ヒンディー語の3言語でLLMを学習した場合には、次の図のようになる可能性があると考えます。
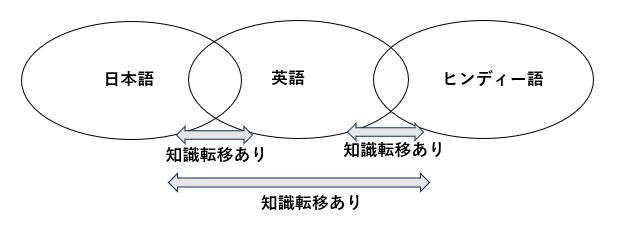
日本語・英語・ヒンディー語の3言語を学習した場合の知識転移の予想
つまり、英語を仲介して日本語とヒンディー語の間での知識転移が起こるのではないか、ということです。そんなことを確認してみたい…というのも Team JINIAC のモデルにヒンディー語を学習させてみる動機となっています。
ヒンディー語のデータを収集する。
Common Crawl
まずは Common Crawl からヒンディー語のデータの収集を行いました。データ収集ではGoogle Colaboratory を用いてスクレイピングをまわしました*。
このスクレイピングの処理が非常に重く、時間がかかります。大規模言語モデル構築のためのデータ収集の大変さを思い知ることになりました。どのくらい重いかというと、Google Colaboratory を丸一日まわして数百キロバイトのデータにしかならないほどの重さです。私はGoogle Colaboratory でスクレイピングを3週間ほどまわし、チーム内のメンバーの皆さんもスクレイピングに尽力してくださいましたが、最終的に集まったのは43.5MBのみでした。大規模言語モデル用の学習データとしては不足しています。
ヒンディー語圏にあったデータセットBPCC
そんな中、Team JINIAC の元谷崇さんが、ヒンディー語のデータセットを見つけてきてくれました。
Bharat Parallel Corpus Collection (BPCC) https://ai4bharat.iitm.ac.in/bpcc/
ファイルサイズがzipで13.8GB、展開するとおよそ50GBほどのデータです。
ただし、このデータセットはインド国内で使用されている言語のうち22言語のデータが入っています。ヒンディー語のデータのみを取り出すと、およそ6GBでした。さらに重複削除等のフィルター処理をすると半減し、およそ3GBとなりました。
ヒンディー語のデータセットの質については、私単独では評価が困難であることから、ヒンディー語に詳しい外部専門家*の協力を賜りつつ、簡易の評価を行いました。
最終的に、LLMの学習に使用したヒンディー語データは2GBほどとなりました。
2GBではLLM学習には少ないのですが、現状用意できたこのデータを用いて学習することにしました。
学習に使用したヒンディー語データ: JINIAC/Hindi_samanantar_v2
このデータセットの中には27.2M件の文章データが入っています。
ヒンディー語データにありそうな知識のキーワードとして、「ナレンドラ・モディ」「マザー・テレサ」「マハトマ・ガンディー」を選び、データセット中でのキーワードが出現回数を調査しました。
キーワード出現回数
| キーワード(日本語) | データセット中での出現回数 |
|---|---|
| नरेन्द्र मोदी(ナレンドラ・モディ) | 393,400 件 |
| मदर टेरेसा(マザー・テレサ) | 86,444件 |
| महात्मा गांधी(マハトマ・ガンディー) | 168,429件 |
それぞれのキーワードについて、8万~39万件のデータがあることから、各人物についてそこそこの知識はデータセット中にあることが推測されます。
学習
Team JINIAC で構築を進めているLLMの事前学習に投入をしました。
学習の順序は、事前学習として 「英語 ⇒ 日本語 ⇒ ヒンディー語」 の順番で行いました。(その後、さらに事後学習として日本語によるSFTを行いましたが、事後学習については別記事で書きます。)
学習したモデルのアーキテクチャは MoE(Mixture of Experts)で、ゲーティング機構により64個のエキスパートを切り替える形式のものです。
モデルの挙動
事前学習をしたモデル
事前学習で「英語 ⇒ 日本語 ⇒ ヒンディー語」の順にデータを投入した学習をしたモデルについて挙動を確認しました。
ヒンディー語でシンプルに質問
”महात्मा गांधी किस प्रकार के व्यक्ति हैं?”(Google翻訳で作成:「マハトマ・ガンディーってどんな人ですか?」の意)という質問を複数回行ってみました。次のような結果となりました。ヒンディー語の回答にはGoogle翻訳をつけてあります。
और आप जानते है यह क्या था।
Google翻訳: そして、それが何であったかはご存知でしょう。
-
वे भी एक-दूसरे का सम्मान करते।
Google翻訳: 彼らはまた、お互いを尊敬し合っていました。
-
यह देश बदलती रहती है।
Google翻訳: この国は変わり続けています。
-
यह बात मैंने अपने देश में कही।
Google翻訳: 私の国でもそう言いました。
-
ये सब सच हुआ।
Google翻訳: これらすべてが実現しました。
-
यह भी एक ऐसा ही मामला है।
Google翻訳: これも同様のケースです。
-
यहं बात उन्होंने मीडिया की।
Google翻訳: ここで彼はメディアに語った。
-
यह जानकर सा कि वह अतिशय प्रसन्न हुआ।
Google翻訳: これを知って彼はとても幸せになりました。
-
とりあえず、ヒンディー語の質問に対してヒンディー語で答えてくれてはいますが、マハトマ・ガンディーがどんな人であったかを答えてくれてはいないようです。
同様に100回ほど出力させてみましたが、どれも似たような回答でした。
「ナレンドラ・モディ」「マザー・テレサ」について質問しても同様でした。
one-shot学習でヒンディー語で質問
ヒンディー語でシンプルに質問をしても知識を答えてくれなかったので、one-shot学習を試みました。
one-shot学習とは、プロンプトで質問をする際に、質問と回答の例を1つ提示してから質問することで、LLMの回答を改善する手法です。
「マハトマ・ガンディーはどのような人物ですか?」という意味のヒンディー語 ”महात्मा गांधी किस प्रकार के व्यक्ति हैं?” を用いた質問を行います。以下のようなプロンプトを用いました。
Q:坂本竜馬はどんな人ですか?
A:坂本竜馬(さかもと りょうま、1836年1月3日 - 1867年12月10日)は、日本の幕末期の政治家、志士、実業家です。
Q: महात्मा गांधी किस प्रकार के व्यक्ति हैं?
A:
このプロンプトを用いて、10回質問を行ったところ、次のような結果となりました。
हम अपने आपसे कभी भी भलीभांति नहीं बोलना चाहते.
Google翻訳: 私たちは決して自分自身に良いことを話したくないのです。
-
हमारे देश में, मैं भी बहुत कुछ बोलता हूं।
Google翻訳: 私たちの国でも、私はよく話します
-
मैंने हमेशा कहा;
Google翻訳: 私はいつもこう言いました。
-
हम सभी को इसे करने का अधिकार है।
Google翻訳: 私たちは皆、そうする権利を持っています。
-
आप अकेले नहीं रहूंगा।
Google翻訳: あなたは一人ではありません。
-
मुझे इसको लेकर कोई जानकारी नहीं।
Google翻訳: これについては知識がありません
-
वह कहते हैं कि भारत में क्या हुआ.
Google翻訳: 彼はインドで何が起こったのかを語った。
-
मैं भी अपने आपमें, एक ही नही होती।
Google翻訳: 私も一人ではありません。
-
हम सभी, अत्यंत दुखी होकर ।
Google翻訳: 私たち全員、非常に悲しんでいます。
-
एक बड़े कवि ने कहा, ‘‘मुझे बहुत मज़ा आया।
Google翻訳: 偉大な詩人はこう言いました。
one-shot学習を用いても、アサッテな回答ばかりでした。10回のいずれの回答も、「マハトマ・ガンディーはどのような人物ですか?」に対する意味のある回答とはなっていないようです。
日本語で質問
そもそも日本語で日本の知識を聞いた場合にどうなるのかを確認しました。「日本で一番高い山は?」という質問を10回行った結果は次のようになりました。
日本で一番高い山は?
CSK vs SCRAM
-
क्या आपको लगता है कि आप किसी भी जगह पर अपना नंबर उपलब्ध करा सकते हैं?
Google翻訳: 自分の番号をどこでも利用できるようにできると思いますか?
-
- यह हमलोग नहीं
Google翻訳: これは私たちではありません
-
यह बहुत ही सराहनीय है।
Google翻訳: 大変感謝しております。
-
ये सभी चीजें एक दूसरे के साथ अच्छी तरह से चर्चा में हैं।
Google翻訳: これらすべてのことは互いによく議論されています。
-
भारत.
Google翻訳: インド。
-
- दिल्ली : समिट में, पीएम मोदी ने कहा, ‘भारत-नेपाल सीमा पर शांति बनाए रखने, अल्पसंख्यकों को उनके हितों का समर्थन करने और सभी के लिए दृढ़ता से प्रतिबद्धता प्रकट की।
Google翻訳: デリー:サミットでモディ首相は、「インド・ネパール国境の平和を維持し、少数派の利益やあらゆる面で支援するという強い決意」を表明した。
-
ये एक बड़ी समस्या है।
Google翻訳: これは大きな問題です。
回答の言語に着目すると、日本語で質問したにも関わらずほとんどがヒンディー語による回答で、一部が英語(というよりアルファベット)の回答となっています。
内容に着目すると、「日本で一番高い山は?」に対する適切な回答は1つも得られず、むしろ質問とは全く無関係な内容ばかりの出力となりました。
ヒンディー語のデータセットの中の知識を引き出せるほどには今回は学習できていないようです。今回、ヒンディー語の学習に用いたデータは2GBであり、そこから知識を獲得まではできなかったということと思われます。
事前学習では、英語データと日本語データを数百GB学習した後で、ヒンディー語データを学習したものです。ヒンディー語データはたった2GBであったにも関わらず、学習後のモデルの出力はヒンディー語ばかりとなってしまいました。このことから、最後に学習するデータが出力に与える影響が大きいということが示唆されます。
まとめ
Team JINIAC では、
①文法が似ている点に着目し日本語データの不足を補強する、
②英語を仲介役とした日本語とヒンディー語の知識転移が起きるか確認したい、
という2つの動機から、日本語LLMの構築で事前学習にヒンディー語データを学習させてみました。
今回の結果では、そもそも知識を十分に引き出すことができませんでした。学習に用意できたヒンディー語の学習データが2GBであり、学習データとして不十分なボリュームであったためと考えられます。
十分な量の学習データを用意して学習した場合に、どのような結果になるのかは未知数であり、機会があれば検証をしてみたいです。
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion