GENIAC 松尾研LLM開発プロジェクトメンバーのNisanです。
本記事では、up cyclingの手法を用いたMoE(Mixture of Experts)モデル:Tanuki-8x8Bの事前学習に関する検討及び学習の結果について記載します。
MoEとは?
Tanuki-8x8BモデルはLlamaに代表されるDense構造ではなく、Mixtralに代表されるMixture of Experts (MoE)構造を採用しました。MoEはDenseモデルのFFN(Feed-Forward Network)層を複数のexpertを持つ層に変更し、どのexpertを採用するかをrouterによって選択する構造です。Tanuki-8x8Bでは8つのexpertを持ち、top2(上位2つ)のexpertを採用する構造を採用しました。

図.1 MoE layer from the Switch Transformers paper
Up cyclingとは?
アップサイクリングとは、既存のモデルや学習済みの重みを再利用して、新しいモデルを効率的に作成する手法です。最近では、既存のモデルの層を増やす手法がElyzaさんやSOLARさんから、学習済みのモデルを複数用意してそれぞれをexpertのように扱う手法等が報告されています。
私たちは今回、学習済みのDenseモデルであるtanuki-8Bをbaseモデルとして、routerを新規に配置し、FFN層をexpertとしてコピーする手法を採用しました。本手法はSkywork-MoEの手法を参考にしたものです。詳細については後述します。
初期のExpertについて
Up cycling手法の適用を検討するにあたり、初期の検討段階では、異なるチェックポイントのtanuki-8Bを用いて、複数のexpertを準備しようかと検討しました。しかし、Skywork-MoEにも記載があるように、異なるチェックポイントのtanukiを用意することは性能の向上にそれほど寄与しないことが想定され、かつ異なるチェックポイントのtanukiを学習するのにも学習資源を要することから、初期のexpertとしては最新のチェックポイントのみを用いました。

図.3 複数のモデルを用いた場合とBaselineのみでのlossの比較(Skywork-MoE)
ただし、モデルの出力が崩壊しないレベルで各expertにそれぞれrandomnessを加えました。この手法はqwenの手法を参考にしており、Skywortk-MoEにて主張されているexpert間の類似度が低いほどMoEとして適切に学習されているとの考えと一致していると判断し、採用しました。
Up cycling後のz-lossについて
MoE化によって、routerが追加されることにより、適切にexpertの出力が選択されるために、z-loss及びload balancing lossの適用について検討しました。
Up cyclingの場合、学習済みのexpertやtransformerとは異なり、routerはrandomで与えられ初期値であるため、z lossが異常に高くなる事象が確認されました。z_lossはlossとして返さなければ、減少が遅く、採用した場合はlossが上手く下がらないという現象が発生しました。

図4. 通常のrouter時のz_lossとlossの関係
これを防ぐため、Skywork-MoEで適用されていたrouter-logitにnormalizeを加える処理を追加しました。ただし、tech report上は平均で引いてから分散で割ると記載がありますが、hugging faceモデル(L832参照)では分散で割るのみだったので、両方を比較し検証し、平均で引かない場合はz lossとgrad normが非常に不安定となったため、平均で引く処理の方を採用しました。
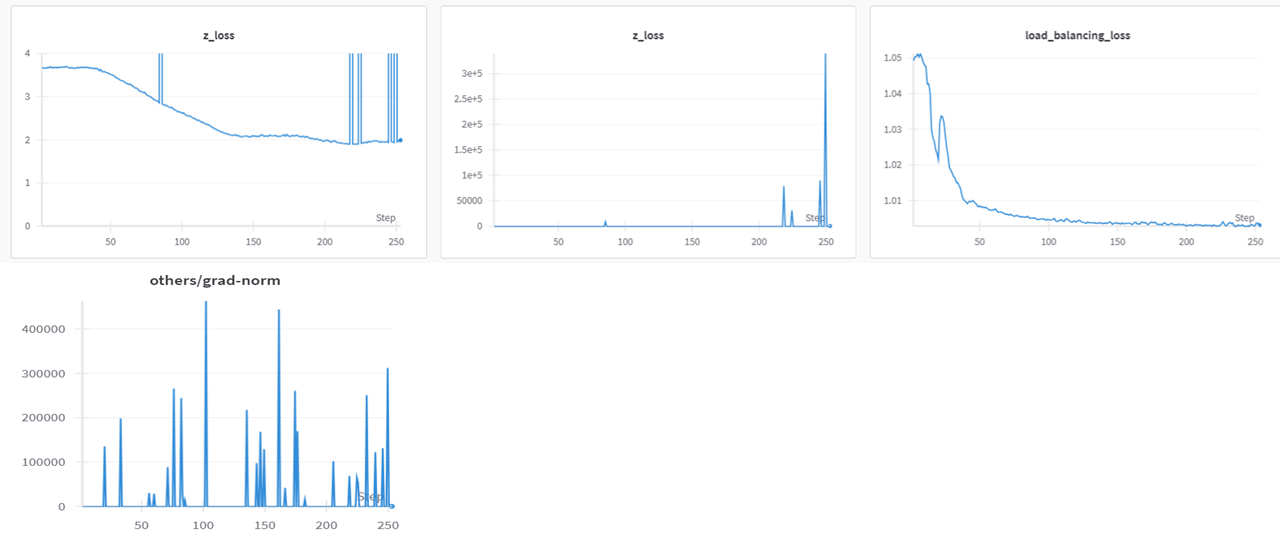
図5 routerにnormalize(averageで引く非適用)の場合のz-loss
事前検討の結果、router logitのnormalized(平均処理付き)を採用したものの、z-lossに関してはモニタリングのみを実施してlossとしては返さないこととしました。理由としては、normalizedの処理によって、z-lossもある程度低くなり、llmのloss及びgrad normの挙動が比較的安定していたからです。
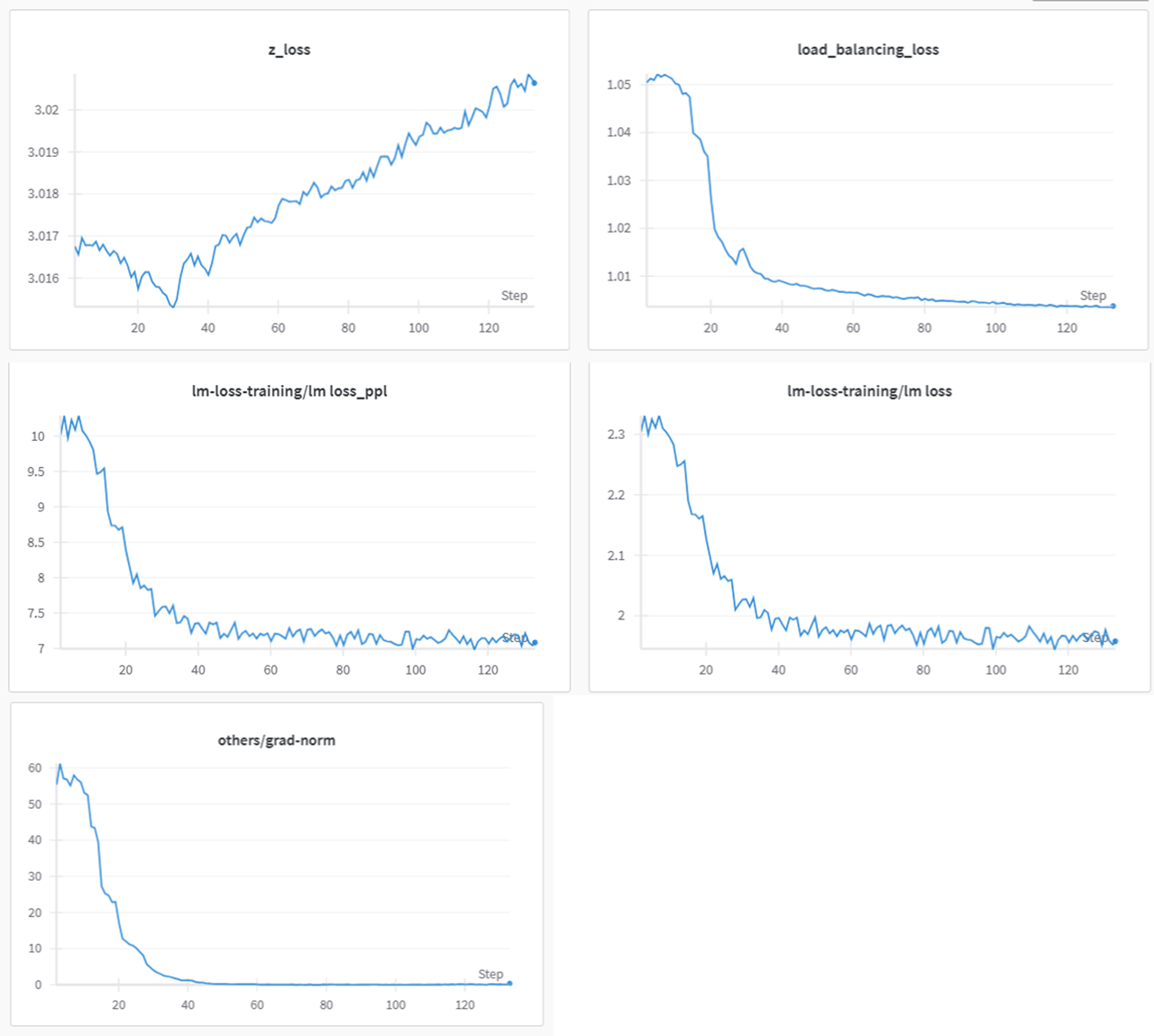
図6 router logit有、z-lossモニタリングのみの検証結果の例
事前学習の本番の際では、z-lossはlossとしたは返さなかったが、学習を全体を通じてnormalize適用後のz-lossは6程度あり、安定していました。
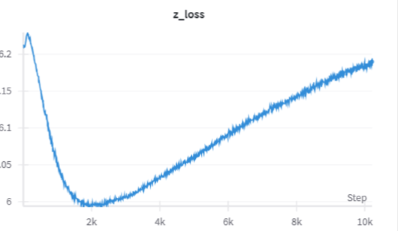
図7 事前学習時のz-lossの一例
各種ハイパーパラメータについて
- Transformer engineは採用したものの、bf16にて学習。
- Grouped-gemについては、変換コードの再現性ができず採用を断念。
- seq_lenは大部分は2048で実施し、終盤に4096に変更。その際にrope thetaも10000→500000に変更。
- バッチサイズは3096で固定。6M Tokens / batch → 12M Tokens /batch
- z lossはモニタリングのみ
- load balancing lossは0.02で一定
- LrについてはSTEPによって臨機応変に変更した。
事前学習結果について
Denseの38Bのモデルで発生したLoss spikeについては発生せず、データの切り替え時によるlossの変化があったものの、同一のデータドメイン内では順調にLossは減少しました。Load balancing lossについては、常に1程度でありました。z-lossとLoad balancing lossともに、一度だけlossが急上昇したが、その後の学習に影響を与えませんでした。
学習データは学習後の出力結果から不足分のデータを加味して、様々なドメインを追加していったため、学習再開時の初期のlossは高く、学習中のlossの値もドメインによって異なりました。ドメインの変更時に初期のlossは高くなることから、Baseモデルの最終的な挙動は最終学習のデータ分布に近いことがわかります。(llama3のテクニカルレポートではデータの分布を厳密に考えているようである。)
また、lossとは別にexpert間の類似度も計測しており、類似度が高いほど学習の余地があり、減少すると学習が進んでいると考え、学習の進行を計測する指標としてモニタリングしました(スクラッチの場合は0に近い値をとります)。学習終盤は学習率が小さいこともあり、類似度の減少も鈍化しましたが、学習が進むに従い、一様に減少していきました。また、図11から見るように、Tannuki-8x8Bのexpert間の類似度はまだ高く、追加の事前学習の余地がまだまだある可能性もあると考えられます。

図8 全学習のtrain lossのlog

図9 全学習のz-lossのlog

図10 全学習のload balancing lossのlog

図11 類似度の測定結果
まとめ
本記事ではTanuki-8x8Bに適用したup cyclingでのMoE化の手法及び学習結果について解説いたしました。本記事が何かのお役に立てれば幸いです。
以上
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion