はじめに
この記事では松尾研 GENIAC LLM開発プロジェクトにおける、Team 天元突破モデルチームの活動報告を行いたいと思います。
この記事の作成にあたり、モデルチームの皆さまに深い感謝の意を表します。特に、チームを牽引してくださったSさんには、感謝を申し上げます。Sさんのアドバイスにより、この記事が作成されましたことをここに明記いたします。
モデルチームの役割
Team 天元突破ではこのようなチーム分けを行った上で大規模言語モデルの開発を行っていました。その中でもモデルチームでは、事前学習をどのように行うのかなどの調査や実際の実装を担当していました。

Team 天元突破では最終的にLlamaアーキテクチャを採用したのですが、その決定に至るまでに試したことや困難だったことを紹介できたらと思います。
モデルチームの活動内容
Phase0(事前準備期間)
今回のGeniacプロジェクトではコンペ本番のPhase1の前に準備期間としてPhase0が用意されていました。Phase0の期間で、小規模な実験を行うことでどのモデルを採用するのかを調査を行いました。
アーキテクチャの選定
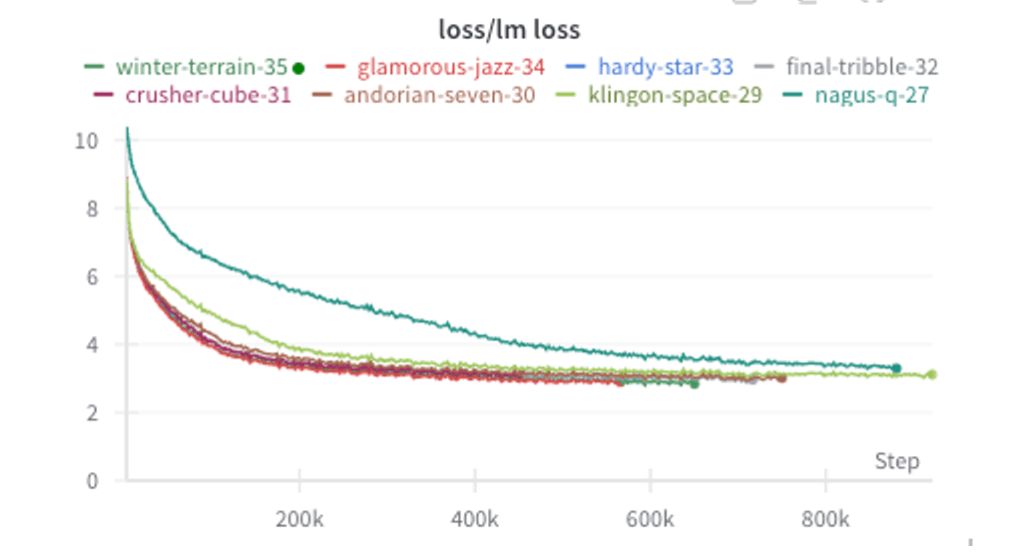
このPhase0の間にモデルチームでは標準コードベースのモデルに対してLlamaで良いとされていた手法を小規模に試したところ(モデルサイズ:125M)、Lossが改善されることが確認できました。(濃い緑の27が標準コードで、改善手法を取り入れていったのが他の曲線になります)
MoE
この他にも、Megatron-DeepspeedによるMoE実装の方にも取り組んでいました。
Megatron-Deepspeedではexampleコードが提供されていたのですが、実行してみたところそのまま動かすことはできませんでした。Phase1開始ギリギリまで検討していましたが、本番で使用できる状態にまでいかなかったので今回は採用を見送りました。
これらの過程を経て最終的にTeam 天元突破ではMegatron-Deepspeedを用いた標準コードをベースにLlama2をモデルアーキテクチャとして採用しました。
学習手法の選定
Team 天元突破ではカリキュラム学習的に学習させるデータに順番を与えることで性能向上に挑戦してみました。
カリキュラム学習とは
カリキュラム学習とは、学習を行う際にランダムにデータを学習するのではなく、何らかの順番に基づいてデータを学習させるテクニックのことを指します。LLMにおいて、この何らかの順番としてポピュラーなものとして、「簡単なタスクから徐々に難易度を上げていく」があります。
この簡単なタスクをどのように定義するかですが、Sequence Length Warmupという方法があります。初めは短いテキストから学習を始め、徐々に長いテキストへと学習を進める方法です。
Megatron-Deepspeedには文章の長さに基づいたカリキュラム学習が実装されています。しかし、実験不足と後述する天元突破チームで取り組んだ内容とを組み合わせるのが難しいかったのでテキストの長さに基づいたカリキュラム学習は見送りました。
Team 天元突破でのアプローチ
Team 天元突破ではテキストの長さではなく、データの種類に基づいた順序で設計する方法を検討しました。データの種類としては言語(日本語/英語/コード/数学)、質の良さをもとに設計を行いました。
データの種類に基づく設計の効果というのは未知数ではあり実験的な試みでもありましがTeam 天元突破では以下の方針をとることにしました。
・モデルの大まかななパラメータが決まる初期段階に日本語を多く学習させる。
・一番記憶が保たれる終盤に、質の高いデータを学習させる
・数学/コードのような高度な処理が要求されるものは、ある程度学習が進んだ中盤以降に学習を行う。
ここで言う質の高いデータとはキュレーションチームによってデータ処理が行われたデータのことを指します。
一方でこのアプローチを取ることで以下の懸念点もありました。
異なるドメイン(今回の場合は英語と日本語など)に切り替わる際にlossが急上昇するのはないか。この懸念はSequence Length Warmupなどのように徐々に難しいタスクに進むのではなく、突然知らないドメインに切り替わることで発散して学習が失敗してしまうのではないかという内容でした。また、特定のドメインをしばらく学習していないと過去に学習したドメインの内容を忘れてしまうのではという懸念もありました。
この懸念の対策として、 英語/日本語で完全な切り分けは行わずどの段階でも少しは学習されるような配分で行いました。このようにすることで、lossの発散と特定のドメインの忘却を防げないかを期待しました。
以上の話し合いのもとで最終的にこのようなデータ配分となりました。
Stage1:雑多な日本語データをメインとしつつ英語データも入れる
Stage2:同程度の日本語と英語データ+数学データ
Stage3:綺麗な日本語データ+英語、数学、コードデータ
Stage4:さらに綺麗な日本語データ+英語、数学、コードデータ

これらのモデルアーキテクチャの選定と学習手法の検討を行いPhase0は終了し、学習本番期間であるPhase1へと進む運びとなりました。(細かなところではモデルの保存や学習の再開などの方法の動作確認なども行っていました)
Phase1(学習本番期間)
トークナイザーの作成
標準コードのSentencePieceTokenizerで言語別にトークナイザーを作成しました。
事前学習データから一定量サンプリングを行って、全体で4GB程度を抽出してトークナイザーの学習に使用しました。
言語別にトークナイザーを作成した後にトークナイザーをマージを行い最終的なトークナイザーとして利用しました。
いくつかのパターンを比較して、length_per_token(トークンあたりの文字数)を参考にトークナイザーの決定を行いました。*lengh_per_tokenはテキストをどの程度圧縮できているかを表し、トークナイザーの性能目安となります。
語彙数を増やすと効率は上がるが、汎化しにくくなることと、あるところから圧縮率の増加により語彙数増加によるパラメータ増の計算コストが上回るので語彙数はある程度の数で打ち切る必要がありました。そのラインとなるのが50kくらいと言う見積もりであったので、語彙数と圧縮率の兼ね合いから作成したパターンのうち②の構成を採用しました。(③まで増やしてもあんまり圧縮率が変わらなかった)

参考:
Elyzaは45k, swallowは48k, llm-jpは50k程度
ハイパラメータの調整
ハイパラメータは論文やライブラリに使われている設定を踏襲する方針で設定しましたが、学習率とバッチサイズのみ調整を行いました。
学習率
Llamaの論文では3.0e-4が採用されていましたが、参考にしたライブラリでは1.0e-4が採用されていました。
学習率が小さすぎると、lossの減少が遅くて性能が上がらない可能性がある一方で、上げすぎると発散してしまうリスクがありました。今回は発散して学習がやり直しになる方がリスクが高いと言う判断で1.0e-4を採用しました。
学習率を下げる代わりにバッチサイズを下げることで更新回数を増やして、学習率が低いことによるリスクの低減を狙いました。
バッチサイズ
上述の通りに学習率を下げたことで性能に影響が出る恐れがあったため、バッチサイズを下げることにしました。オリジナルのLlamaの論文や、参考にしたライブラリも2048が採用されていましたが、Team 天元突破では1022を採用しました。
学習中のエラー
マシントラブル以外の要因で3度ほど意図しない形で学習コードが停止しました。
最初はモデルを保存する容量が足りないため停止、2度目はiterationの設定ミスで、予定していたトークン数を学習するより前に学習が停止してしまいました。
学習結果
当初懸念していた、Stageごとのドメイン切り替え時による学習の発散でしたが、ドメイン切り替え時に確かにlossが急増しましたが、すぐに想定される水準に戻り大きな問題にはなっていないようでした。また、最初に学習した内容を忘れてしまうのではないかと言う懸念点も細かくcheckpointで確認したところ、最初に学習させた日本語を途中で忘れてしまうようなことは発生しませんでした。
データの設計上のどのStageにも日本語をある程度入れていたので、知識の忘却はともかく、日本語を生成する能力の喪失は発生しなかったと考えられます。
一方で想定していた問題以外の問題も発生していました。それはlossが思ったより下がらないと言う内容でした。Stage1(日本語メイン)のデータを学習させてから2日程度たった段階でlossの減少ペースが緩やかであることに気づきました。llm-jp-eval v2.0では10~20B程度学習した段階でlossが2.0付近にありましたが、Stage1の終了時には2.4~5程度になる見通しとなっていました。
最終的に振り返ると、この原因1つは日本語のlossが英語より大きいからと言う結論となりました。他のチームの学習曲線などをみると日本語の方がlossが高く(2.0~2.5程度)、英語やコード、数学では低い(1.5~1.8程度)傾向にあったようです。実際にllm-jpでは英日半々のデータで学習が行われていましたが、Team 天元突破ではStage1では日本語が8~9割を占めていたため想定しよりlossが減少しなかったと考えています(これは結果からの振り返りであり、当時この原因を知る由もなかったのでモデルチームリーダーのSさんが他にも色々検証を行っていただきました)。
紆余曲折はありながらも、Stage4までに23日間かけて180Bトークンを消化し、lossは2.0付近で終了しました。

終わりに
モデルチームの活動内容について報告させていただきました。
今後のLLM開発の参考になればと思います。
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion