SQLは書けるけどBigQueryは初見の人に贈るざっくりBigQuery
去年使い始めたBigQueryについて、BigQueryを使う前の私に教えてあげたいことをまとめてみました。
BigQueryとは
Google Cloudで提供されている、データ管理と分析のためのデータウェアハウス(めっちゃデータが入ってる総合的な倉庫と思ってもらえれば)サービスです。
フルマネージドなので、インフラ管理も楽なままSQLクエリだけで大規模なデータ分析基盤を構築できます。
気軽に試すには、Sandbox環境がおすすめです。
DDL(CREATE TABLEとか)は発行できませんが、パブリックデータセットなども存在しているので、基本的な操作は試すことができます。
特徴
BigQueryは早いということがよく特徴として上がりますが、それを実現する二つの大きな要素があります
列指向データベースであること
データウェアハウスでは列指向データベースが多いですが、BigQueryも例に漏れずです。
データ列の高速な取得向けに最適化されるので、列指向の方がデータ分析に向いていると言えます。
例えば、身体測定の結果のテーブルがあったとして、全員の身長の平均を出したい!としたときに、行指向だと身長以外のカラムも取り出す必要がありますが、列指向では身長のカラムだけ取り出せばいいので効率的です。
一方、1行単位での更新やSELECT * FROM tablenameとかは行指向より苦手です。
インディックスもないので、テーブルの設計が割とキモです。
分散型コンピューティングであること
データを保存するストレージとクエリを実行するエンジンが分かれており、クエリ実行エンジンが処理を複数のワーカーに並行して分散するため高速なフルスキャンが可能となっているそうです。
ストレージとコンピューティングが分離されているため、スケールもしやすいです。
そして使う側は最初はそこまで意識しなくていいんですけどね。ありがたいね。
料金
おもに以下のように分類されます。(投稿時の情報なのでご容赦ください)
分析料金
クエリの処理にかかる費用でさらに以下に分類されます。
-
オンデマンド料金
クエリで処理されたバイト数に基づいて課金されます。(毎月 1TBまで無料)
1TBあたりの料金はリージョンによりますが、$5~$6あたり、ちなみに東京は$6.00 per TBです。 -
定額料金
仮想CPUであるスロットを購入することで、専用のクエリ処理容量を使えます。
100スロット単位で購入でき、スロットの料金もリージョンによりますが、$1,700〜$3,000で100スロットくらいです。東京は$2,400で100スロットです。
ストレージ料金
読み込むデータを保存する費用で、アクティブなストレージと長期保存されるデータに対して発生します。
なお、毎月10GBまで無料です。
-
アクティブストレージ
過去90日間で変更されたテーブルまたはテーブルパーティション
東京はGBあたり$0.023です。 -
長期保存
90日間連続して変更されていないテーブルまたはテーブルパーティション
アクティブストレージとの違いは、約半額の割引がされます!東京はGBあたり$0.016です。
基本的な用語
初見で使ってみて「なんだろうこれ?」と思ったのもをいくつか挙げておきます。
| 用語 | 説明 |
|---|---|
| project id | BigQueryのユニークになるプロジェクトID |
| dataset | データベースでいうスキーマにあたります |
| table | これはそのまんまテーブル |
| Job | データの読み込み、エクスポート、クエリ、コピーなど、BigQueryがユーザーに変わって実行するアクション |
| レガシーSQL | BigQuery には、標準SQL(SQL:2011サポート)とレガシーSQLという2つのSQLが使えます。レガシーを利用する理由はもはや特にないですが、度々ドキュメントで用語が出てくる |
| Googleデータポータル | BIツールです。BigQueryのデータをグラフや表を使って視覚化できる |
| マテリアライズドビュー | パフォーマンスと効率を向上のために結果を定期的にキャッシュへ保存するビューのこと。事前に計算されているので素早くアクセスできる |
| セッション | 一般的なセッションではなく、BigQueryセッションというものがあるようです。セッションスコープ内で変数や一時テーブルを維持したり、SQLアクティビティの履歴が見れるなど |
| ネイティブデータ | データソースの文脈で、BigQueryストレージに保存されているデータを指す |
| 外部データソース | データソースの文脈で、BigQueryのストレージ外で直接操作できるデータソースを指す。使えるものは、Bigtable、Cloud Spanner、Cloud SQL、Cloud Storage、Google ドライブ |
データの取り込みに使えるもの
大きく分けて、バッチとストリーミングの二つの方式があります。
それぞれ以下のようなものがデータの取り込みに利用できます。
バッチ
読み込みジョブ
Cloud Storageまたはローカルから以下のファイル形式のデータの読み込みができます
なお、ネスト構造などはCSVでは表現できないので他の形式を使う必要があります。
- CSVファイル
- Avro
- JSON(改行区切り)
- ORC
- parquet
他サービスのデータから読み込み
Cloud Storageに保存されている以下のサービスのデータから読み込みができます
- Hive パーティショニング
- Datastore のエクスポート
- Firestore のエクスポート
Data Transfer Serviceで読み込み
BigQuery Data Transfer Serviceは、設定されたスケジュールに基づいてBigQueryへのデータの移動を自動化するマネージドサービスです。
いろんなサービスが対応してます(今後も増えそう)
- キャンペーン マネージャー
- Cloud Storage
- Google アド マネージャー
- Google 広告
- Google Merchant Center(ベータ版)
- Google Play
- 検索広告 360 (ベータ版)
- YouTube - チャンネル レポート
- YouTube - コンテンツ所有者レポート
- Amazon S3
- Teradata
- Amazon Redshift
などなど
Storage Write APIで読み込み
高スループットでデータをBigQueryに取り込むための gRPCベースのストリーミング取り込みとバッチ読み込みを組み合わせたAPIです。
バッチに関しては読み込みジョブと守備範囲が被りますが、プロトコルからして効率的であること、トランザクションを考慮した上で複数ワーカーで実行するなど、お手軽さを除けばこっちを使った方が良さそう。
クライアントライブラリはJava, Pythonが記載されていますが、調べると公式でnode.jsとphpもあるようです。
あとはgRPCを直接読むこともできます。
ストリーミング
Storage Write API
バッチと同様にストリーミングでも可能。
Dataflow
データ処理パターンの実行するマネージドサービスです。Apache Beam SDKを利用
BigQueryのデータ操作
ざっと以下の3つを使ってます。
BigQueryコンソール
Cloud ConsoleでBigQueryを開くことで使える、Webコンソールです。
SQLクエリを発行したり、簡単な操作でテーブルの作成からデータ取り込みまでできます。
特に、SQLクエリを書いたら実行しなくても文法エラーや消費するバイト数を教えてくれるのが割と便利なので思ったより使います。
CLIツール
bqコマンドラインツールを使ってBigQueryの各種操作ができます。
スクリプトを組むときにだいたい使います。
SQLの発行したい時はこんな感じです。
※use_legacy_sql=falseは前述したレガシーSQL使わないよオプション
bq query --use_legacy_sql=false \
'SELECT
COUNT(*)
FROM
`bigquery-public-data`.samples.shakespeare'
クライアントライブラリ
主要な言語はクライアントライブラリが用意されています。
- C#
- Go
- Java
- Node.js
- PHP
- Python
- Ruby
ちなみにNode.jsを使ってみましたが、クライアントライブラリでは対応しきれていないオプション等が一部ありそうです。
例えば、CREATE TABLEするときにNUMERICの桁数を最大長以外で定義することができなかったです(DDLではできたのに)
const datasetId = "my_dataset";
const tableId = "my_table";
// ⏬ 有効数字少数2桁にしたいけどNUMERICとしか定義できない・・・
const schema = 'Name:string, Age:integer, Weight:numeric, IsMagic:boolean';
const options = {
schema: schema,
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigquery
.dataset(datasetId)
.createTable(tableId, options);
そこまで気にならないですが、リリースの頻度も高いのでこういうこともあるかもと思っておきます。
SQL書くときに気をつけること
基本的にはSQLのアンチパターンは概ねBigQueryでも適用されますが、列指向データベース並びにBigQuery特有っぽいものを列挙しておきます。
-
列指向なので1行単位での更新が苦手
基本はCREATE TABLE AS SELECT(CTAS)です。(更新という概念は極力忘れよう) -
SELECT * FROM tablenameが苦手
よく言われるやつですが、カラムは指定するようにしましょう。 -
パーティショニングとクラスタリングが有効に使われているか確認する
パーティショニングは大きいテーブルを特定のカラムの値をもとに分割して小さいテーブルで管理することを指します。これによって、そのカラムをWHEREなどでフィルタしたときに不要なテーブルへの読み込みをスキップすることができます。
クラスタリングは特定のカラム(複数可)に対して、並び順を定義します。つまりそのカラムでフィルタしたときにスキャン対象が絞り込めます。 -
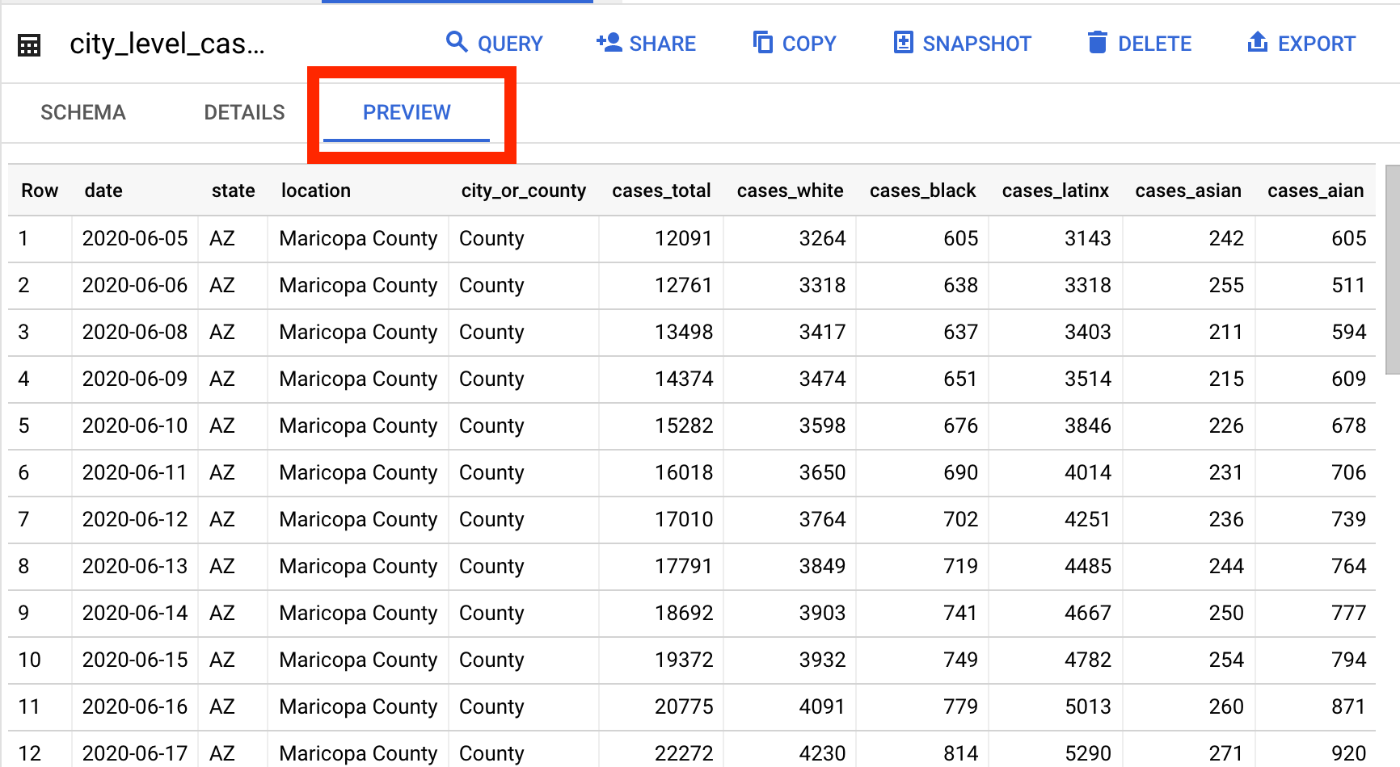
ざっとどんなデータが入ってるか見たいだけならデータプレビューを使う
BigQueryコンソールからテーブルを開くとプレビュータブがあるのでそこからさっと無料でデータを確認できます。(SELECT * FROM ...しなくてもいい!)
-
だいたいの結果が分かればいい場合は「近似集計関数」を使用する
カウントなどで別に厳密な結果を求めていない場合は近似集計関数を使用を使うとメモリが節約できます。
たとえば、COUNT(DISTINCT)の代わりにAPPROX_COUNT_DISTINCT()など。 -
クエリのキャッシュが効くもの効かないもの
BigQueryはデフォルトで結果をキャッシュします。(最大 24 時間)同じクエリなら基本キャッシュから返しますが、実行の都度結果が変わる関数が使用されていたり、元のテーブルが更新されているとキャッシュが効かないので考慮してみるといいかもしれないです。
さいごに
特にチュートリアルとかも確認せず使い始めたBigQueryですが、さらっと概要だけ知ってから使っていれば・・・という思いから改めて調べつつ使ってみてこの情報は欲しかったなという点をまとめてみました。
次はBigQueryで知ってると便利な機能&コンソールショートカット集を書きたいと思います👋
2022-01-08 書きました!
Discussion