SlackのデータをBigQueryで蓄積する仕組みをゼロから作る
背景
- 元々、Slack上の投稿データやその他メタデータをBigQuery上で管理していた
- 2/25 からSlackAPIの旧仕様が使えなくなったが、その対応がされておらず、しかもエラー通知もログ出力もしておらず、気づいた時(3/10)には時すでにおすし。
- 元々、スパゲッティコードかつメンテナンス性や可用性に優れないパイプラインの仕組みだったため、リプレイスしたいなとは思っていた
- そこで、これを機にゼロから作り直してみようと思う
作りたいもの
- ETL for Lake
- E:SlackからAPI経由で各種情報取得
- T:(極力そのまま保持したいので、なし)
- L:Cloud StorageにJSONファイルを保存
- ELT for Warehouse
- E:Cloud Storage Bucketから必要なJSONだけを抽出して、
- L:Cloud StorageのJSONをBigQueryに取り込む
- T:BigQuery上でSQLを使ってWarehouseの形式に変換する
やるべきこと
- == ロジックの設計 ==
- ✅
ウェアハウスにどんなデータを蓄積したいかざっくり考える - ✅
SlackAPIのdocを見て、所望のデータを(あるいは元となるデータを)取得するための方法を調べる - ✅
レイクに保存するデータを決める - ✅
レイクに保存するデータをテスト的にとってみる - ✅
実際のデータを見ながら、変換処理の設計とウェアハウスのデータモデリングをする - == パイプラインの設計 ==
- それぞれをどのようなやり方で実行するか決める(一応以下の想定)
-
Lake E / L
- CloudFunctions(Pub/Sub trigger) + Cloud Scheduler(target:Pub/Sub)で実行し、Cloud Storageに保存
- CloudStorageのライフサイクルは、Nearline365日→Archive永久
- オブジェクトのライフサイクル管理 | GCP
- ストレージクラス | GCP
-
Warehouse L / T
- CloudStorageを経由して、BigQueryのWarehouse用テーブルに保存
- SQLで変換処理を実装する、クエリ実行はPythonかなにかのクライアントライブラリを使用する
- ただし、GitHubでsqlファイルを管理する(こちらのブログが参考になりそう)
-
Lake E / L
- == パイプラインの実装 ==
- (考え中)
ロジックの設計
■ Warehouse に保存するデータめっちゃざっくり決める
※マスターデータの履歴をどうやってとるかが課題…特にユーザーの解除フラグ→Admin権限であれば、ユーザー解除イベントとれるかも?要調査
ざっくりほしい情報
- マスター系
- channels , users の属性情報、追加・削除イベントに関する情報
- トランザクション系
- messages , reactions
- 加工データ系(Transform for Warehouse 時点で作る情報)
- どのチャンネルで、いつ、だれから誰にメンションがあったのか
- どのチャンネルで、いつ、だれから誰のどんなメッセージにどんなリアクションがあったのか
(参考)以前のWarehouseベース
-
channel- id (ch id) / name / target_date
-
user- user_id / real_name_normalized / display_name_normalized / target_date
-
talk- channel_id / talk_id / ts / thread_ts / talk_user / text / target_date
-
mention- channel_id / talk_id / talk_user / mention_user / target_date
- talk_id が何なのか不明…
-
reaction- channel_id / talk_id / talk_user / reaction_user / emoji / target_date
-
profiles(使ってなさそう) -
replies_history(使ってなさそう) -
reply(使ってなさそう) -
test(使ってなさそう)
(参考)以前のテスト用Warehouseベース
-
channels: チャンネルマスタ- channel_id / channel_name / created_at / creator / is_archived / is_general / topic_val / purpose_val / loaded_at
-
users: ユーザーマスタ- user_id / display_name / real_name / deleted / profile_title / status_txt / status_emoji / image_48_path / is_bot / is_app_user / loaded_at
-
channel_users: チャンネルとユーザーの紐付け用中間テーブル- channel_id / user_id / loaded_at
-
messages: メッセージログ- ts / user_id / channel_id / text / thread_ts / is_thread_child
-
reactions: リアクションログ- msg_ts / name / user_id
■ SlackAPIのdocを見て、所望のデータを(あるいは元となるデータを)取得するための方法を調べる
- マスター系
- users.getPresence
- users.list
- conversations.list:Channel-likeなものの情報を全取得
- types : にて public, private などを指定することで取得対象を制御できる。デフォルトはpublic。private / mpim / im は、プライバシーを考慮して、除外する。
- トランザクション系
- admin.analytics.getFile:アナリティクスデータ(admin.analytics:readが必要)
- conversations.history:channel-id を指定して、Channel-likeオブジェクト内のメッセージイベントを全取得する
■ レイクに保存するデータを決める
上記APIに含まれる情報をそのまま保存
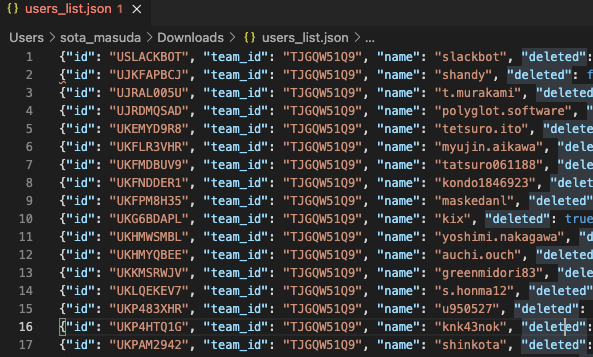
- users_list_YYYY-MM-DD.json
- users.listのレスポンス
- ※Pagenationで分割された情報を全てまとめて一つのファイルにする
- users_presence_YYYY-MM-DD.json
- users.getPresenceのレスポンス
- ※全ユーザーの取得結果を全てまとめて一つのファイルにする
- conversations_list_YYYY-MM-DD.json
- conversations.listのレスポンス
- ※Pagenationで分割された情報を全てまとめて一つのファイルにする
- conversations_history_YYYY-MM-DD.json
- conversations.historyのレスポンス
- ※全ChannelIDの取得結果を全てまとめて一つのファイルにする
- admin_analytics_YYYY-MM-DD.json
- ※メールアドレスは保存しないように配慮が必要
- ※admin.analytics:readスコープ内の権限付与依頼中
■ レイクに保存するデータをテスト的にとってみる
- 必要な設定
- API Token 取得(済み)
- 適切なスコープを設定
- 実行方法
- Testerを利用(例:users.list のテスター)
- 結果
- users.list ✅
- ※limit + cursor チェック完了
- users.getPresence ✅
- conversations.list ✅
- conversations.history ✅
- 割と細かい情報が入ってることがわかった。URL共有したときは、サイトの情報も解析して保持してくれてる。BlockKitの解析で、できるだけ解像度の高い情報を取れるように、Transform for Warehouse を実装した方が良さそう。ということがわかった。
- users.list ✅
■ 実際のデータを見ながら、変換処理の設計とウェアハウスのデータモデリングをする
この記事とかちょっと読んでみたので、まとめると
- ウェアハウスの好ましい状態=「分析用途に合った」&「秩序だった」構造になっていること
- レイクの好ましい状態=(ある程度の整理整頓と)とにかく「全てのデータが一元的に」「無加工状態」で保存されていること
- レイク→ウェアハウスへの変換処理が保守性高く管理されていることが重要。それができていれば、ウェアハウスのモデルの変更容易性が高まる
ということで、モデリングはとりあえず必要そうなものにとどめておき、今後拡張することを前提に考えて良い。変換処理をどのように管理するかに頭を使った方が良い。という結論になった。
変換処理をどのように管理するか
これについては、あと工程で考える。
なんか、思ったより大変…モデリングの基礎から勉強してたら終わらないな…
とりあえずどんなテーブルを作るかを記述してみよう。
モデリングざっくり完了、以下こちらのリポジトリで
(次にやることメモ)
ソースのフォルダ構成
- root
- docs/ : documents
- slack-to-lake/ <- new
- function_ingest/
- automatic_ingest.sh
- 通常時実行するスクリプト
- バッチ実行時の属する日付の前日=処理対象日(target_date)
- manual_ingest.sh
- 初回実行時、処理確認時、通常実行に失敗した時のリカバリ実行時などに利用
- バッチ実行日によらず、処理対象日を自由に設定できる
- deploy_ingestion.sh
- deploy_cloudstorage.sh
- lake-to-warehouse/ <- new
- extraction/
- main.py
- transform/
- xxx.sql
- yyy.sql
- deploy_extracter.sh
- exec_transform_sql.sh
- extraction/
slack-to-lake 実装
Slackクライアントライブラリとして、Boltを使うのが便利そう。(Bolt for Python docs)
- Bolt for Python docs tutorial
- Slack Bolt は slack-sdk に依存している。WebClientクラスとかはこっちに実装されてる。
- https://github.com/slackapi/bolt-python/blob/main/docs/_basic/web_api.md
- https://github.com/slackapi/bolt-python/blob/main/examples/google_cloud_functions/main.py
- https://github.com/sota0121/mentaiko-slashcmd/blob/main/DEPLOYMENT.md
- https://github.com/GoogleCloudPlatform/python-docs-samples/tree/master/functions/slack
- https://cloud.google.com/functions/docs/deploying?hl=ja
実装手順
slack-to-lake
- ローカルマシンでSlackAPI経由で所望のデータをダウンロードできるようになる(チャンネルマスタ、ユーザーマスタ) ✅
- ローカルマシンでSlackAPI経由で所望のデータをダウンロードできるようになる(チャット履歴トランザクションデータ)✅
- latest, oldestから出力フォルダ名生成、各ファイルを当該フォルダに出力する ✅
- テスト書く…
- 完全別で、「任意日付latest/oldest」を入力したら、1日ずつ区切って当該functionの呼び出しを当該日数分実行するスクリプトを作る
- ローカルマシンのメモリ上のデータを(ファイル出力を経由せず)CloudStorageにアップロードできるようになる
- 上記の関数をCloudFunctionsとしてデプロイして実行できるようになる
- CloudFunctionsに必要な認証:Slackの認証、CloudStorageの認証
チャット履歴データをもれなく、ダブりなく、無駄なく取得する方法メモ
タイムスタンプの設定と(必要ならば)tempfileをどううまく使うかが肝かなぁ
とりあえず流れはこんな感じ
関数名とかは雰囲気。実際はチャット履歴もページネーションされてて、ページ単位でAPI呼び出すけど、一旦全ページを一括で取得するイメージでメモを書く。
channels = extract_channel_id_list(conversations_list)
latest_unix_time = "???" # うまく設定
oldest_unix_time = "???" # うまく設定
for channel in channels:
slack_response = client.conversations_history( channel=channel, latest=latest_unix_time, oldest=oldest_unix_time )
messages = slack_response.get("messages")
「うまく設定」のところを考える
要求としては、
- デイリーデータ収集の入力は、「収集時刻(tzは形式は未定)」であって、1日分のデータをとる
- 初回実行時は、「最古の時刻」「収集時刻」それぞれ明示的に設定できるようにしたい
Slack側のタイムスタンプ仕様は、全てUNIXタイムらしい
結果として、処理の呼び出し部分はこんな感じか
import pytz
from datetime import datetime, timedelta
# Main function for cloud functions
def ingest( latest_unix_time: float=None, oldest_unix_time:float=None ):
# 収集対象時刻の暗黙的実行(通常のデイリー処理はこっち)
if latest_unix_time is None or oldest_unix_time is None:
tz = pytz.timezone('Asia/Tokyo')
start_of_today = datetime.now(tz).replace(hour=0,minute=0,second=0,microsecond=0)
latest_unix_time = start_of_today.timestamp()
start_of_yesterday = start_of_today - timedelta(days=1)
oldest_unix_time = start_of_yesterday.timestamp()
else:
# 収集対象時刻の明示的実行(初回とかデバッグとか緊急時などはこっち)
Slack API のドキュメントに書いてない、というか見つけられていないのだが
not_in_channel というエラーは、(Botトークンでアクセスしている場合)当該チャンネルにBotアプリを招待していないと発生する模様。
はじめてだけど、pytest でテストを書く
ルールというかパターンをさっと確認するなら↓が良さそう
実装手順(再掲)
slack-to-lake
- ローカルマシンでSlackAPI経由で所望のデータをダウンロードできるようになる(チャンネルマスタ、ユーザーマスタ) ✅
- ローカルマシンでSlackAPI経由で所望のデータをダウンロードできるようになる(チャット履歴トランザクションデータ)✅
- latest, oldestから出力フォルダ名生成、各ファイルを当該フォルダに出力する ✅
- テスト書く…✅
- 完全別で、「任意日付latest/oldest」を入力したら、1日ずつ区切って当該functionの呼び出しを当該日数分実行するスクリプトを作る✅
- ローカルマシンのメモリ上のデータを(ファイル出力を経由せず)CloudStorageにアップロードできるようになる
- 上記の関数をCloudFunctionsとしてデプロイして実行できるようになる
- CloudFunctionsに必要な認証:Slackの認証、CloudStorageの認証
以下の感じでやれそう。
- ローカルでテストするときは、Cloud Strageへのアクセストークンを使う
- デプロイ後は、Cloud FunctionsのサービスアカウントにCloud Strageへのアクセス権限を付与する
Cloud Functions では一時保存用 /tmp フォルダだけ書き込み専用領域が用意されているらしい。
cloud storage にデータを直接アップロードする方法ずっとわからなかったけど
・メモリ上のデータ(dict)
→json.dumps でstrに
→io.StringIO でFileストリームに
→Fileストリームをファイルオブジェクトのようにして、Clien Library の upload_from_file() を使う
ならいけそう
get_blob って return blob if exists なので、新規作成のときに使うもんじゃねえのか
upload_from_fileの例を見ると、bucket.get_blob でblobつくってない。blob = Blob( … )って感じでオブジェクト作ってるので、Blobクラスのコンストラクタを見たほうが良さそう。ファイルパス指定したいよね
完全にこれやろ
cloud functions at http-trigger の関数を作るとき、第一引数にrequestって書くと、
gcloud functions call するとき、--data オプション設定しないと、400エラーになる。リクエストの形式が正しくないって怒られる。
デプロイできたあああああああああ
出会った問題いっぱい
- デプロイ失敗
- ファイル構成
- 実行失敗
- Exception間違い
- エンコーディングミス
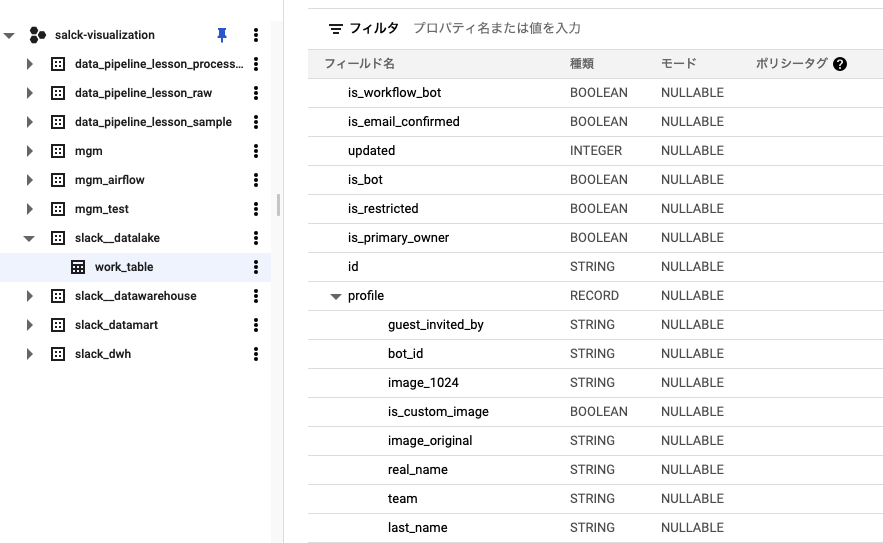
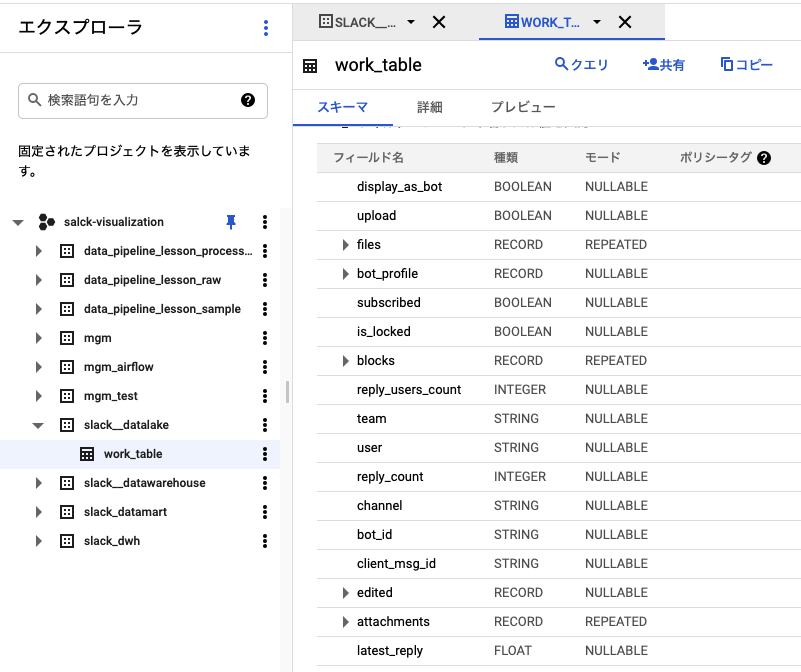
Cloud StorageにあるJSON群をLakeとして、DataWarehouseをBQにELTで構築する。この手順は、Google Cloudではじめる実践データエンジニアリング入門の5.4節にほぼそのまま載っている。
- Cloud Storage→BQの作業用テーブルにロード
-
bq load {table-name} {gcs-blob-path}でいける
-
- SQLで整形、集計
- 作業用テーブルを削除
bq load でCloud StorageのJSONをBQに入れられるけど、以下注意点
- location=asia の場合、bq load がサポートされてないっぽい。動かん
-
--autodetectフラグを使って自動でパースさせる場合、こちらのルールに則ってないと上手く行かないことを覚えておこう(実際、だめだった) - 自動パースがだめな場合は、スキーマを定義しよう
今回のエラーは、
BigQuery error in load operation: Error processing job 'salck-visualization:bqjob_r653eabcba4548b04_00000179c658891f_1': Error while reading data, error message: Failed to parse JSON: No
object found when new array is started.; BeginArray returned false; Parser terminated before end of string
ということ。
どうも、「各JSONオブジェクトごとに1行になってなければならない」というルールに則ってないのが原因と思われる。
to-lake のfunctions での blob.upload_from_file のところで、indent=4 みたいなのを設定すべきだったか?
indent 設定してみたけど、エラー内容はあまり変わらずだった。一つ消えたかな。
Error while reading data, error message: Failed to parse JSON: No
object found when new array is started.; BeginArray returned false
これを調整するのは、ちと大変なので、スキーマを明示的に定義するようにアプローチを変えようと思う。
jsonファイルからjqとかつかって、スキーマを生成する方法ないかなって調べたら、いろいろわかった
とりあえずjqでできる
jqには、自作関数を登録する機構がある ~/.jq にこんなスクリプトをおいてやれば、呼び出せるようになる
んで、「絶対だれかが作ってるはず!」と思って探したら、オンラインツールがあった
Online Json to Json Schema Converter
初手はこれでいい。かゆい所に手が届かないけど
bq load --autodetect が通るようにjsonを調整するのを諦めて、
スキーマを明示的に設定するよう試みたが相変わらず
ちなみに、構造体のスキーマをどう書けばいいかわからない(Doc通りにやったけどinvalid value と怒られ、jobすら作られない)
その上で、構造体部分除外して実行したけど
BigQuery error in load operation: Error processing job 'salck-visualization:bqjob_r40e483c7f5fb457c_00000179c7622a63_1': Error while reading
data, error message: Failed to parse JSON: No object found when new array is started.; BeginArray returned false
エラー内容は変わらなかった。つまり、スキーマを明示的に定義すれば上手くいくという想定が崩れたので、根本的にjsonを修正するアプローチに戻る。その代わりパースはBQに任せて、スキーマを書かないようにする。長期的に見てもソッチのほうが良い。スキーマファイルもメンテしなくちゃならなくなるから。
ここまでを整理しよう。
- Failed to parse JSON: No object found when new array is started.; BeginArray returned false; Parser terminated before end of string
- ==JSONをindentするようにすると==
- Failed to parse JSON: No object found when new array is started.; BeginArray returned false
- 太字部分のエラーメッセージがなくなた
- 文字列末尾前でParser処理が終了してしまう、という問題が解決されたようだ。わからんけど。
BeginArray returned false bq load でググると、以下の記事が見つかった
これまでちゃんと理解することを逃げていた、JSONL(bqが求めているJSON仕様)について触れている。
ここを見ると、
これまで使ってきたJSONは、Concatnated-JSONという流儀らしい。
json.dumps を
jsonline に対応した jsonl とか?のパッケージに差し替えて
jsonl.dumps みたいなノリでできないかな
これでいけそう
fp = io.BytesIO() # writable file-like object
writer = jsonlines.Writer(fp)
writer.write(...)
writer.write_all([
...,
...,
...,
])
writer.close()
fp.close()
でも、conversations_historyについては
{ “channel”: xxx , “message”: { } }
{ “channel”: xxx , “message”: { } }
:
{ “channel”: zzz , “message”: { } }
{ “channel”: zzz , “message”: { } }
と変形しないといけないかも
jsonlinesというパッケージを使えば、jsonl形式にできるらしい。
とりあえずやてみたが、jsonlines.Writer( f ).write( obj ) このobjには、オブジェクトそのままいれないといけない。write関数は、encodeもwrite to fp も一気にやってくれるので、気を使って、write( json.dumps( d ).encode( “utf-8” ) )とかしたら、むしろ怒られる
blob.upload_from_file にて、ValueError: Stream must be at beginningというエラーがでた。バイナリオブジェクトがなんかおかしいんだろうな、と思ったけどそのとおりで。ここのStackoverflowによると、バイナリファイルのヘッダ情報がないから、みたいに書かれてた。
裏技として、blob.upload_from_file( obj, rewind=True )
ってやるといけるって書いてるから、やってみる。
ちなみに、rewind=Trueってのは、
Docによると、
rewind (bool) – If True, seek to the beginning of the file handle before writing the file to Cloud Storage.
らしい。ちなみに、rewindとは、「巻き戻す」という意味らしい。推測だけど、現状指しているfpの位置から、無条件で先頭にseekした上でuploadしますよ、ってことなのかな。
完璧じゃん。天才かな
では、こいつをBQにロードしてみよう
上手く言ったら、conversations_historyの修正にうつるぞ
しゃあああああああ
できたあああああああ
しかもstruct型(profile)もちゃんとパースしてるうううう
完全勝利
list of dict の各dict に一律同じkvペアを追加したい
よし、修正できたぞおおおお
って思ったけど、ちがう!
思ったのと違う。
- メッセージ0件のチャンネル(図中の[] の行)はなくしたほうがええな。
- あと、list of channel-msgs がappend されていってるみたい。ちがう、extendしないと
きたあああああああああああ
よし、次は
- Cloud Storage の更新が終わったら、BQジョブ(Cloud Storageからのロード)が実行されるようにしたい
- そのためのスクリプトを書く。できればシェルにしたいが、Pythonで書くならPythonで
調べてみたが、以下の理由から ingest_slack_lake でファイル書き込み完了時に、Pub/Subトピックセット
それをトリガーに別途用意したfunctionsでlake-to-warehouse and Transform on BQ を実行すると良さそう。
- Cloud Storage Trigger finalize →更新されるたびに呼び出される。書き込み終わってから、みたいな制御はできなさそうだった。
topic.create では、すでに存在する場合の対処とか ここにちゃんとのってて最高
クライアントライブラリはこれね
そういえば、絶対忘れちゃいけないのがエラーにきづけるような仕組みにすることね
Slackに通知することも考えたけど、ひと手間ありそう。まずはError Reportingとやらでシンプルにメールで通知しよう
Error Report のダッシュボードに行けばエラーがでる。
Functionは一つのAPPとして認識される。
通知をONにすると、(ログイン中アカウント)に通知されるようになった。通知先を変更できるような仕組みはない。
プロジェクトのオーナーだから?それともログインしたユーザーに通知するようになる仕様?わからない
BQ Client Library をつかって、bq load に該当する処理を書く際に参考になるのはここね 具体的なCloud Storage→BQ読込については個々を見てねって書いてた
cloud functions pubsub triggered に gcloud functions call での実行時に、--data で渡す引数は、functions のkwargs には入らないようだ。これはhttptrigger の関数と挙動が違うな
調べてみる
天才的発想
publish するコマンドをたたけばいいんだ。functionsを呼ぶんじゃなくてね。そうすればfunctionsのIFもいじらなくて良くなるし、一石二鳥じゃん。
コマンドはこれな。
これをまとめて実行するスクリプトを組めばええ。気になるのは、非同期で実行されたとき、BQのテーブル書き込みがちゃんと排他されるかってとこだな。
gcloud pubsub topics publish の --message オプショナル引数に設定する内容をprevious フローで作ったメッセージと同じにすればいい。
value はdouble quoate で囲むこと
中にjson string を書くわけだが、double quote は \ でエスケープしよう。ShellScriptだからね。
さて、datawarehouse のテーブル設計をするわけだが、パーティショニングせんといかんな。基本的に処理実行時の日付?をクエリで取得して、カラムに追加する感じだろう。
んで、そのカラムを使ってパーティショニングしてくれ、っていう命令をどう渡せばいいんだろう、ってとこが疑問なので、調べる。
→GoogleDE本の3.6節を読んだ。結果、テーブル設計全体を学ぶ必要がありそう。
以下、ポイント
- BQでは、インデックスがないので、パフォーマンスを決めるのはテーブルの設計
- ①パーティション分割
- カラムベース→主流
- 取り込み時間ベース→衰退
- ②クラスタ化
- 各パーティション内で指定したカラムの値によりソートして、もっと高速にするやつ
- ③マテリアライズドビュー
- ビュー(論理ビュー)とは違う
- ちょっとよく理解できてない、いまはあまり深ぼらなくて良さそう
一旦整理
TODO(実行順)
- Cloud FunctionsにおけるSQL別ファイル化検証
- Datawarehouseのテーブル設計
- Transform処理 in SQL の実装 on BQ
- Transform処理 in Cloud Functions
- 3->4をテーブルごとに繰り返す
Cloud FunctionsにおけるSQL別ファイル化検証
- 検証したいこと
- Cloud Functionsで関数を記述したpyファイルとは別のファイルを関数実行中に読み込めるか
- 目的
- SQL文をpyファイルとは別に切り離したいが、それができるか確認するため
- 検証方法
- main.pyと同一ディレクトリに
test.txtを用意し、一緒にデプロイ - main.py内で、
test.txtを読み込んで、中身をprintする
- main.pyと同一ディレクトリに
- 結果
- 読み込める
SQLファイルを関数本体とは別ファイルにして、bqクライアントにクエリを投げる仕組みはできた。あとは、これを整理する+SQL文を試行錯誤しながら作る。でOK。
フォルダ構成
- sample.sql
- main.py
- .env.yaml
- ...
ファイルの中身
sample.sql
SELECT name, name_normalized, num_members
FROM `{PROJECT}.{DATASET}.{TABLE}`
LIMIT 20
main.py
# 中略
bq_client = bigquery.Client(project=PROJECT_ID)
with open('./sample_query.sql', 'r', encoding='utf-8') as f:
query_str = f.read()
query_job = bq_client.query(query_str) # Make an API request.
print('The query data.')
print(f"query_job type is ... {type(query_job)}")
for row in query_job:
print(row)
結果

SQL 実装前準備
やること
- SQL文、ファイル分割可否チェック
- SQLを別ファイルから呼び出して、実行確認 on Cloud Functions
-
load_gcs_json_to_bq_tbl()実行時に、
target_dateカラムを追加して、全行に当該日付を設定するクエリを実行する
テーブル設計
-
これをベースに、必要そうなものがあれば追加して、
docs/lake-to-warehouse.mdのテーブルカラム記載欄を最終形の状態にアップデートする
channels
- SQL実装 on BQ
- SQL実装 on GCF
users
- SQL実装 on BQ
- SQL実装 on GCF
channel_users
なし
messages
- SQL実装 on BQ
- SQL実装 on GCF
reactions
- SQL実装 on BQ
- SQL実装 on GCF
固定値のカラムを追加するには
SELECT A AS name, "Blue" AS color
FROM table
とすればよい。こうすると、全てが"Blue"という値のcolorというカラムが追加される。
そして、Query結果を永続テーブルに書き込むにはこうする
from google.cloud import bigquery
# Construct a BigQuery client object.
client = bigquery.Client()
# TODO(developer): Set table_id to the ID of the destination table.
# table_id = "your-project.your_dataset.your_table_name"
job_config = bigquery.QueryJobConfig(destination=table_id)
sql = """
SELECT corpus
FROM `bigquery-public-data.samples.shakespeare`
GROUP BY corpus;
"""
# Start the query, passing in the extra configuration.
query_job = client.query(sql, job_config=job_config) # Make an API request.
query_job.result() # Wait for the job to complete.
print("Query results loaded to the table {}".format(table_id))
すでに存在するテーブルに書き込むときは、下記のようにQueryJobConfigの引数 write_disposition で既存テーブルへの挙動を指定しなければならない。何も指定しない場合、409 Already Exists : table ... というエラーになる。
BigQueryにおいて、配列のデータを展開する方法
「構造体の中に配列がある」みたいなより複雑な状況での記述方法(わかりやすい)
なんか上手くいかない。UNNESTしても、Flattenされない。
以下のように空レコが入ってるから上手く行かないのでは?
上記ドキュメントで上がっている例は、構造体内にNULLがなかった。
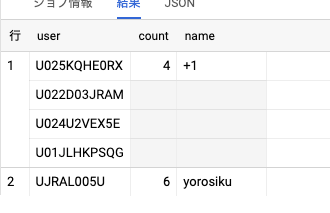
| row | reactions.users | reactions.count | reactions.name |
|---|---|---|---|
| 1 | xxxx | 3 | waiwai |
| yyyy | |||
| zzzz | |||
| 2 | aaaa | 2 | yoroshiku |
| bbbb |
よく見ると、できてるっぽい?
SELECT
reaction.users AS user,
reaction.count AS count,
reaction.name AS name
FROM
`{project}`.`{dataset}`.`work_conversations_history` AS t
CROSS JOIN
UNNEST(t.reactions) AS reaction
ただ見方を理解してなかっただけなのかも。グレーのところはなくて、
各カラムは、ARRAY, INT, STRINGという形になってるのかも。であれば、これをWITH句として、もう一度ARRAY(users)をUNNESTしてなんとかすればいけるかも。
あとは、ARRAYをFlattenすればいい。
どうするのか?
これ
unnest array の後に、各値とCROSS JOINとればいいんかな?
各行の他の列の値を維持したまま ARRAY の列全体をフラット化するには、CROSS JOIN を使用して、ARRAY 列を含むテーブルとその ARRAY 列の UNNEST 出力を結合します。
うん。やっぱそうだ。
まとめると、
- structを展開する
- UNNESTしてCROSSJOIN
- ARRAYを展開する
- UNNESTしてCROSSJOIN
これらを一つずつやっただけ。
INSERT SLECT で WITH 使うときは
INSERT INTO XXXX
WITH...
とする。
存在しない場合のみテーブル作るときは、
CREATE TABLE IF NOT EXISTS mydataset.newtable (x INT64, y STRUCT<a ARRAY<STRING>, b BOOL>)
OPTIONS(
expiration_timestamp=TIMESTAMP "2025-01-01 00:00:00 UTC",
description="a table that expires in 2025",
labels=[("org_unit", "development")]
)
処理はほぼ実装完了した。
あとは、まとめてマニュアル実行するときの注意
- 一気に実行したらTimeoutになった
考えられる理由、一気にJOBが追加されて、関数一つひとつのパフォーマンスが下がった。
-
対策
-
gcloud functions deploy --timeout=TIME_ENOUGHtimeoutを長めに設定- 上限は540秒らしい(参考箇所)
- 関数の実行スクリプト(厳密にはトリガーとなるPublishの実行)において、各Publishの間にSleep時間を設ける。シェルの
sleepコマンドでOK
-
-
結果
- 大丈夫そう
- 現状は、1日分のLT処理にはおよそ50秒ぐらいかかってる
- timeout=300 は十分
晴れて、実装完了!!!!!