😽
Jリーグのプレイヤーデータを可視化する
概要
Jリーグの新シーズンが開幕しましたね.以下のツイートを見て思い立ちJリーグの公式サイトに公開されているプレイヤーのデータの取得と可視化を行ってみたのでこの記事でまとめたいと思います.
注意
本記事ではRによるスクレイピングを通じてデータを取得しています.
JリーグのWebページに高負荷をかけたり,悪意のあるアクセスを行うなど行為はしないようにお願いします.
環境
- macOS Monterey 12.6 (Inter Core i7)
- R version 4.2.1
- RStudio 2022.12.0+353
- phantomjs 2.1.1 ※homebrew経由でインストール
データの準備
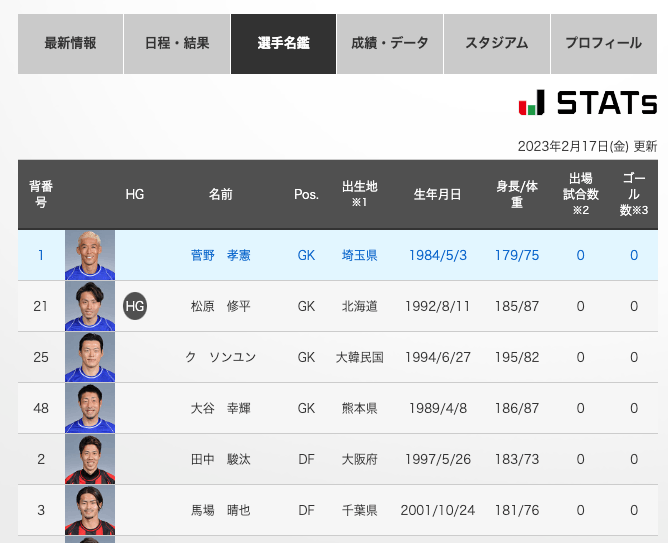
今回はJリーグの公式サイトのチーム個別ページに載っている選手名鑑のデータを利用しました.
Rの方で利用したパッケージなどの情報は以下です.
package:
- tidyverse
- rvest
- webdriver
- glue
- lubridate
- magrittr
- GGally
- ggridges
urls:
top: https://www.jleague.jp/
club-top: https://www.jleague.jp/club/
データの取得
今回はプレイヤーの情報に加えてチームのメタデータも取得してみました.
またプレイヤー情報を取得するページはURLのフラグメント(/#player)でコンテンツを出し分けていたため,rvestではうまく選手名鑑のテーブルをできませんでした.
アクセスした後のコンテンツ生成を待ってからスクレイピングをするため,webdriverでアクセスしてhtmlソースを取得しrvestで解析,データの取得という方法を取っています.
また,年齢を計算したり,体重と身長を分けたりと細かい処理も行っています.
少し長くなりますが以下のようになりました.
# packages
require(tidyverse)
require(rvest)
require(webdriver)
require(glue)
require(lubridate)
require(magrittr)
require(GGally)
require(ggridges)
# setting for using Japanese characters
theme_set(theme_bw(base_family = "HiraKakuPro-W3"))
# urls
top_url <- https://www.jleague.jp/
club_top_url <- https://www.jleague.jp/club/
club_top_html <- rvest::read_html(club_top_url)
# get team info
teams_html <- list(
j1_html = list(
html = html_elements(club_top_html, xpath = "/html/body/div[7]/div[1]/section/section[1]/ul/li"),
league = "J1"
),
j2_html = list(
html = html_elements(club_top_html, xpath = "/html/body/div[7]/div[1]/section/section[2]/ul/li"),
league = "J2"
),
j3_html = list(
html = html_elements(club_top_html, xpath = "/html/body/div[7]/div[1]/section/section[3]/ul/li"),
league = "J3"
)
)
teams_meta <- teams_html %>%
purrr::map(function(e){
team_text <- e$html %>% html_text()
team <- str_sub(team_text, end = str_length(team_text) %/% 2)
description_url <- e$html %>%
html_elements("a") %>%
html_attr("href") %>%
str_sub(start=2)
league <- e$league
res <- tibble(team = team,
description_url = description_url,
league = league)
return(res)
}) %>%
bind_rows() %>%
mutate(team_id = 1:n())
# player info
## generate webdriver session
pjs <- webdriver::run_phantomjs()
ses <- webdriver::Session$new(port = pjs$port)
## output format
detail_list <- list()
detail_colnames <- c(
"number", "omit", "is_HG", "name", "position", "birth_from", "birth_day",
"height_weight", "matchs_played", "goals"
)
## scraping team pages e.g) https://www.jleague.jp/club/ryukyu/day/#player
for(i in 1:nrow(teams_meta)) {
team_id <- teams_meta$id[i]
team_name <- teams_meta$team[i]
playerData_url <- file.path(top_url, teams_meta$description_url[i], "#player", fsep = "")
ses$go(playerData_url) # access a team page
Sys.sleep(3) # wait 3 sec for reading all content
detail_html <- ses$getSource() # get html source
update_date <- read_html(detail_html) %>%
html_nodes(".clubResultDate") %>%
html_text()
player_table <- read_html(detail_html) %>%
html_node(".playerDataTable") %>%
html_table(header = 1) %>%
magrittr::set_colnames(!!! detail_colnames)
player_table <- read_html(detail_html) %>%
html_node(".playerDataTable") %>%
html_table(header = 1) %>%
magrittr::set_colnames(detail_colnames) %>%
mutate(
team_id = team_id,
team = team_name,
update_date = update_date,
height = as.numeric(str_split(player_table$height_weight, "/", simplify = T)[,1]),
weight = as.numeric(str_split(player_table$height_weight, "/", simplify = T)[,2]),
is_HG = is_HG == "HG"
) %>%
select(-omit)
detail_list[[i]] <- player_table
# show progress info of for-loop
msg <- glue("team: {team_name} complete.")
message(msg)
}
# remove the phantomjs session
ses$delete()
remove(pjs)
# cleaning output
player_info <- detail_list %>% bind_rows()
player_info <- player_info %>%
bind_cols(
player_info$birth_day %>%
str_split("/", simplify = T) %>%
as_tibble() %>%
mutate(across(everything(), as.numeric)) %>%
magrittr::set_colnames(c("birth_year", "birth_month", "birth_date"))
) %>%
mutate(
update_date = update_date %>%
strptime("%Y年%m月%d") %>%
as.character()
) %>%
select(-height_weight) %>%
mutate(
birth_day = paste(birth_year,
str_pad(birth_month, side="left", pad="0", width=2) ,
str_pad(birth_date, side="left", pad="0", width=2),
sep="-"),
age = floor(lubridate::as_date(birth_day) %--% lubridate::today() / years(1))
)
# export data
teams_meta %>% write.csv("data/teams_meta.csv", row.names = FALSE)
player_info %>% write.csv("data/player_info.csv", row.names = FALSE)
簡単に可視化
データも無事揃ったのでいくつか図をプロットして本記事を終えたいと思います.身長の分布.
J1~J3全体の身長・体重・年齢の散布図行列
player %>%
select(height, weight, age) %>%
ggpairs(diag = list(continuous="barDiag"))

J1のチームごとの身長・体重・年齢のプロット
player %>%
left_join(team %>% select(team_id, league), by = "team_id") %>%
dplyr::filter(league == "J1") %>%
ggplot(aes(weight, height, color=age, group="team")) +
geom_point() +
facet_wrap(~team)

J1~J3のチームごとの身長の密度推定

もっと色々なデータがオープンにされると楽しくなりそうですね.
Discussion