SnowflakeでAWS VPC FlowLogs分析ダッシュボードを作成する
SnowflakeでSecurity Field CTO Officeに所属しているMasayaです
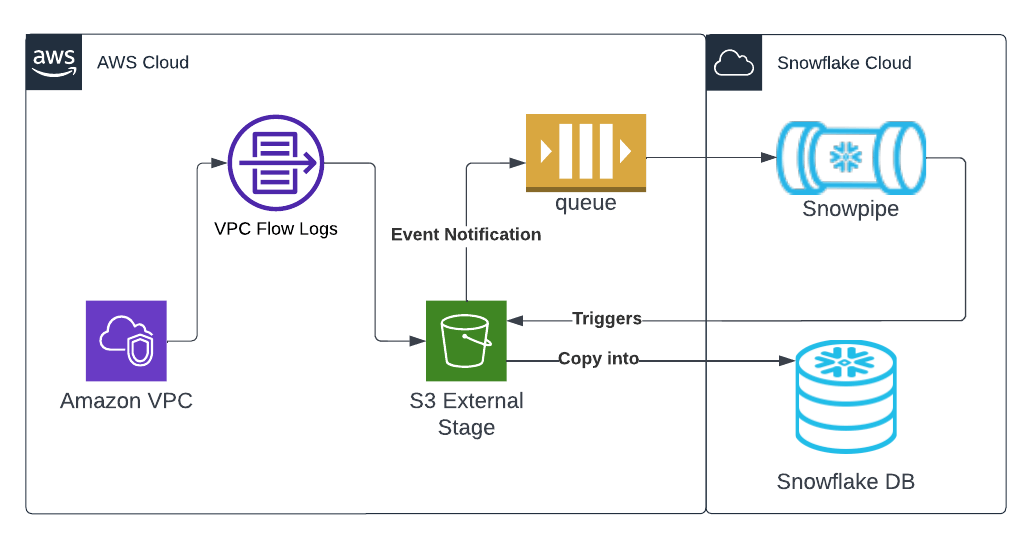
今回はAWSのVPC内のトラフィックログが取れるVPC Flow LogsをSnowflakeに自動取り込み可視化ダッシュボードを作成して分析していきます。
本方法は、Snowflake公式QuickStartで紹介されており本記事はこのQuickStartの和訳版です
手順についてはQuickStartと同じ内容です
流れとしては
- VPC Flow LogsをS3にExportする設定
- 対象S3に対してSnowflakeからアクセスできるようにする設定
- 対象S3にデータがPUTされた場合Snowflakeに通知し、Snowflakeに自動取り込みする設定
という流れで設定していきます
より本格的なアプリケーション作成もStreamlit in Snowflakeを使えば可能ですが、こちらは別記事にて紹介します
VPC Flow Logsを有効化し、S3にPUTする設定
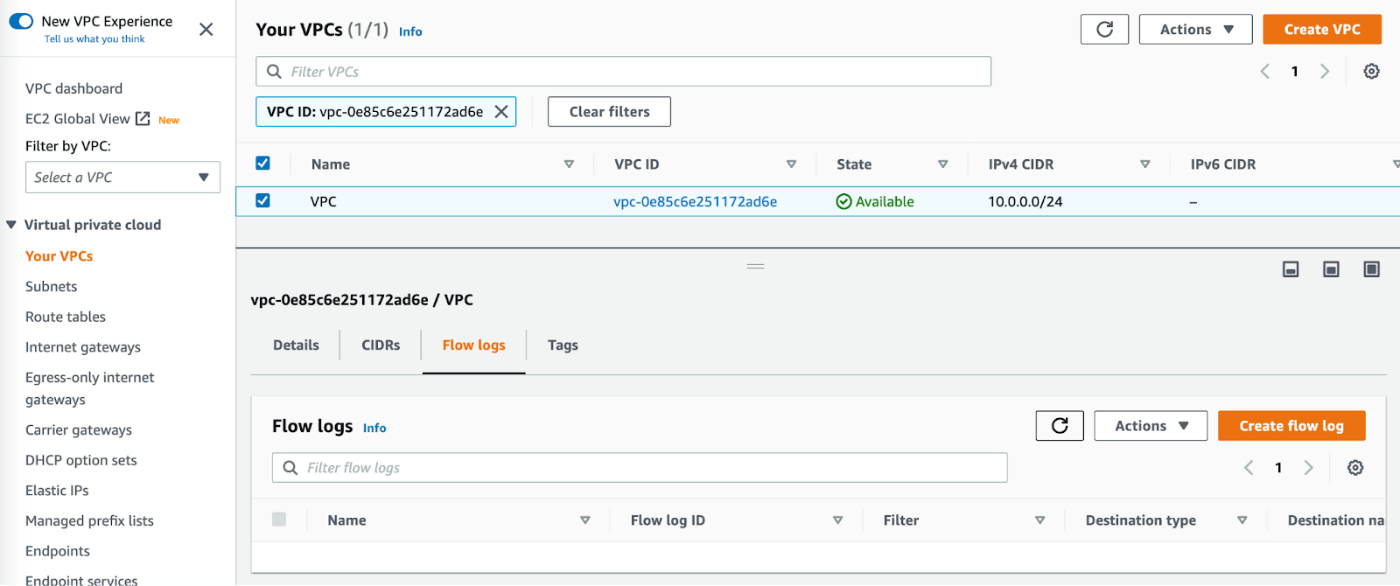
AWSコンソールのVPCページから、Flow Logsを有効にしたいVPCを選択します。
「Flow Logs」タブを選択し、"Flow Logsの作成"を押します
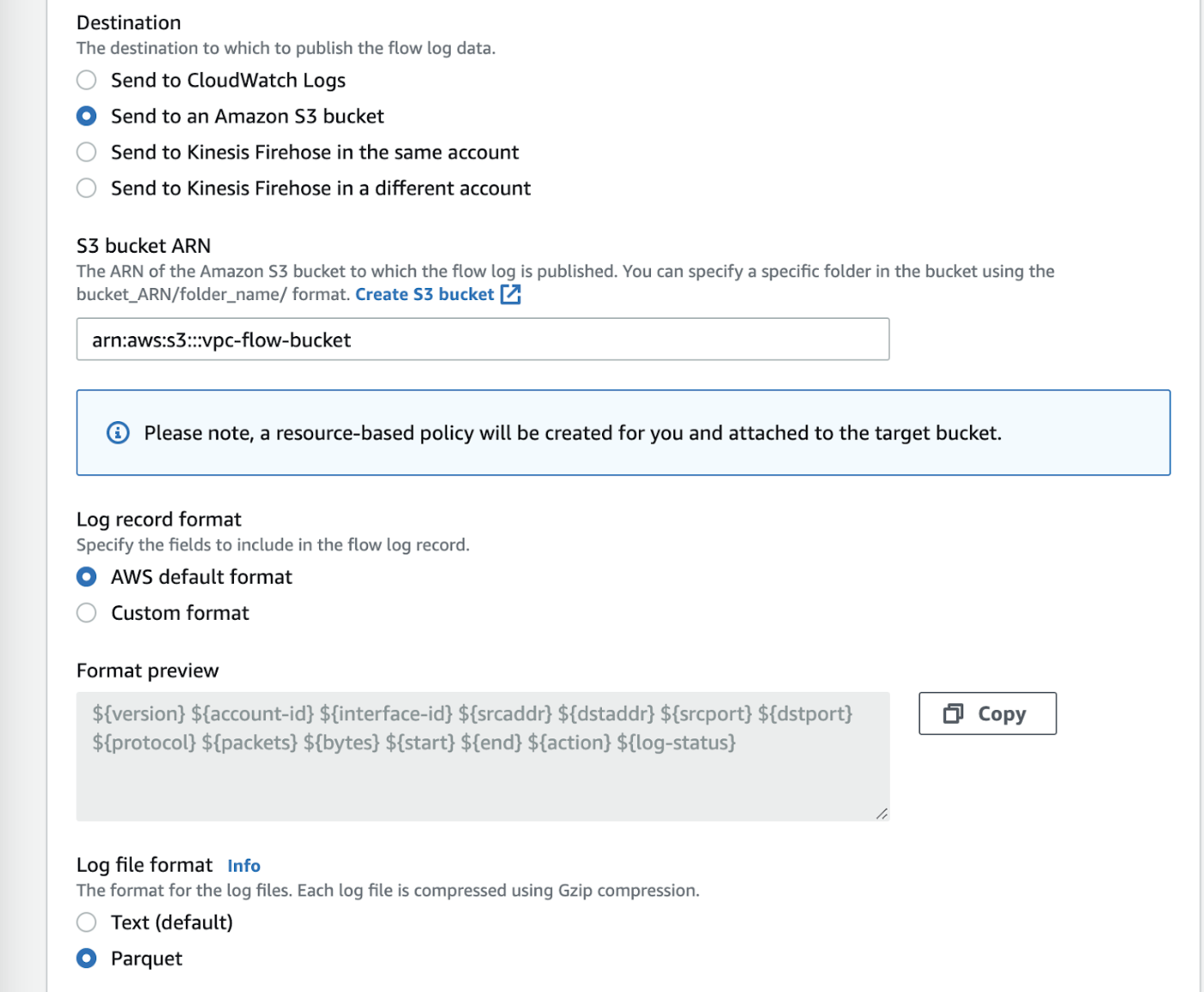
必要に応じてVPCフローログを設定します。
-送信先 Amazon S3バケットに送信
-S3バケットARN: S3バケットARNと既存のバケットのプレフィックス(または "create s3 bucket "リンクを押して新しいバケットを作成)
-ログレコードのフォーマット: このチュートリアルでは、デフォルトのログフォーマットを想定しています。利用可能なフィールドの詳細は、https://docs.aws.amazon.com/vpc/latest/userguide/flow-logs.html#flow-logs-fields
-ログファイル形式 Parquet
Snowflake上でS3ベースのステージ統合と外部ステージを作成
Snowflake上でS3ベースのステージ統合と外部ステージを作成してSnowflakeからVPC FLow Logsファイルが保管されているS3に対してアクセスできるように設定します
具体的な設定方法は、公式ドキュメントや色々なブログで公開されているため割愛します
SnowflakeからS3バケットにアクセスさせるためのIAMロールなどの設定も上記サイトにて公開されていますので、参考にしながらIAMロールも設定します
テーブルの作成とデータの取り込み
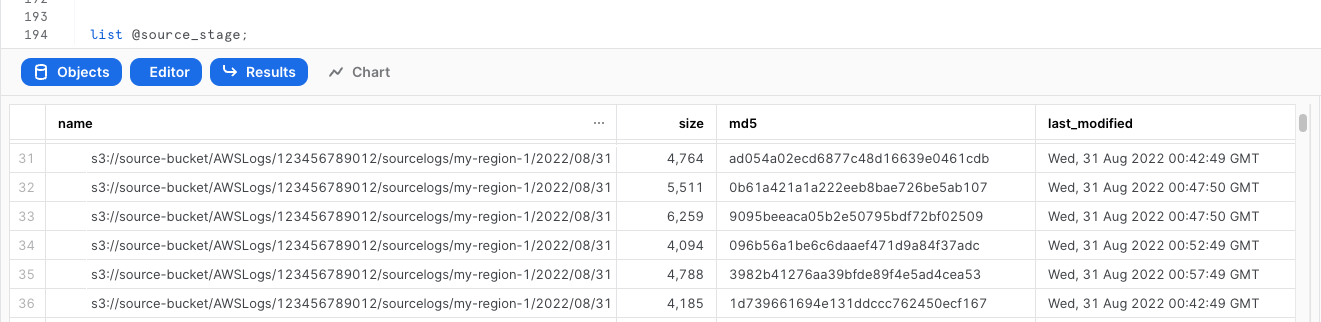
外部ステージの作成が完了したら、念の為VPC FLow Logsファイルがリストアップすることができるか確認します。
list @<外部ステージ名>;
データを取り込む先のテーブルを作成します。元データがParquetなので、テーブルの対象カラムのタイプはVARIANTに指定します
create database log_analysis;
create table public.vpc_flow(
record VARIANT
);
S3のParquetファイルを1つ取り込みしてみます。
copy into public.vpc_flow
from @vpc_flow_stage
files=('テスト取り込みしたいファイル名')
file_format = (type = parquet);
テーブルに取り込まれているか確認します
select * from public.vpc_flow limit 10;

データに問題なければ、対象S3バケットにあるファイルをすべて取り込みます
copy into public.vpc_flow
from @vpc_flow_stage
file_format = (type = parquet);
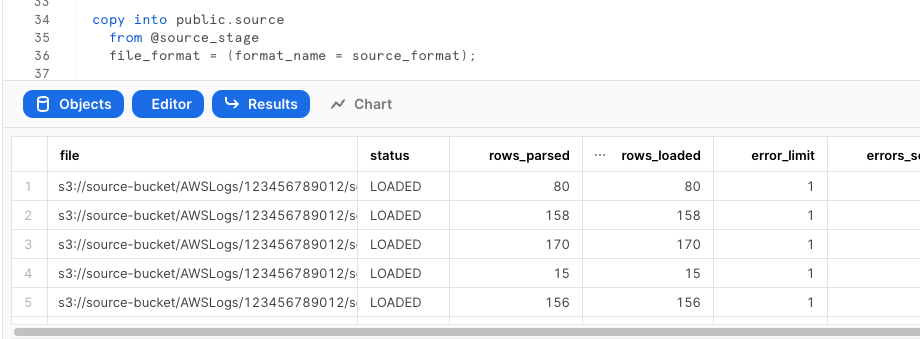
データの自動取り込み設定 = Snowpipe
これまでのSTEPでS3にあるすべてのVPC FLow Logsのファイル取り込みは終了しましたが、時間が経つにつれてログファイルは生成され、Snowflakeに都度取り込む必要があります。
都度手動で取り込むのは手間ですので、S3にデータが置かれたらSnowflakeに通知を行い自動的にSnowflakeに取り込ませるSnowpipeを設定します
S3とSnowpipeの連携設定は、外部ステージ作成と同じく公式ドキュメントや各種ブログで詳細に解説されていますので割愛します
非構造化データ形式から構造化データ形式に = View
parquetファイルを取り込んだvpc_flowテーブルは、非構造化データとして取り込まれているため、分析はできるものの、どのような要素があるのかを把握しづらい状態になっています。

また半構造化データに直接アクセスする場合、record:account_idのようにカラム名と要素名を指定する必要があり、分析しやすいカラム名でアクセスできるようにさせた方が作業効率が上がります。
それぞれの要素をわかりやすく表示させるため、vpc_flowテーブルをベースにしたvpc_flow_viewというViewを作成します。Viewは元テーブルを参照するだけのオブジェクトなので、データ量が二重になるということはありません。
create view vpc_flow_view as
select
record:account_id::varchar(16) as account_id,
record:action::varchar(16) as action,
record:bytes::integer as bytes,
record:dstaddr::varchar(128) as dstaddr,
record:dstport::integer as dstport,
record:end::TIMESTAMP as "END",
record:interface_id::varchar(32) as interface_id,
record:log_status::varchar(8) as log_status,
record:packets::integer as packets,
record:protocol::integer as protocol,
record:srcaddr::varchar(128) as srcaddr,
record:srcport::integer as srcport,
record:start::TIMESTAMP as "START",
record:version::varchar(8) as version
from public.vpc_flow;
Viewが作れたらデータが構造化形式で表示されるか確認してみます
select * from vpc_flow_view limit 10;
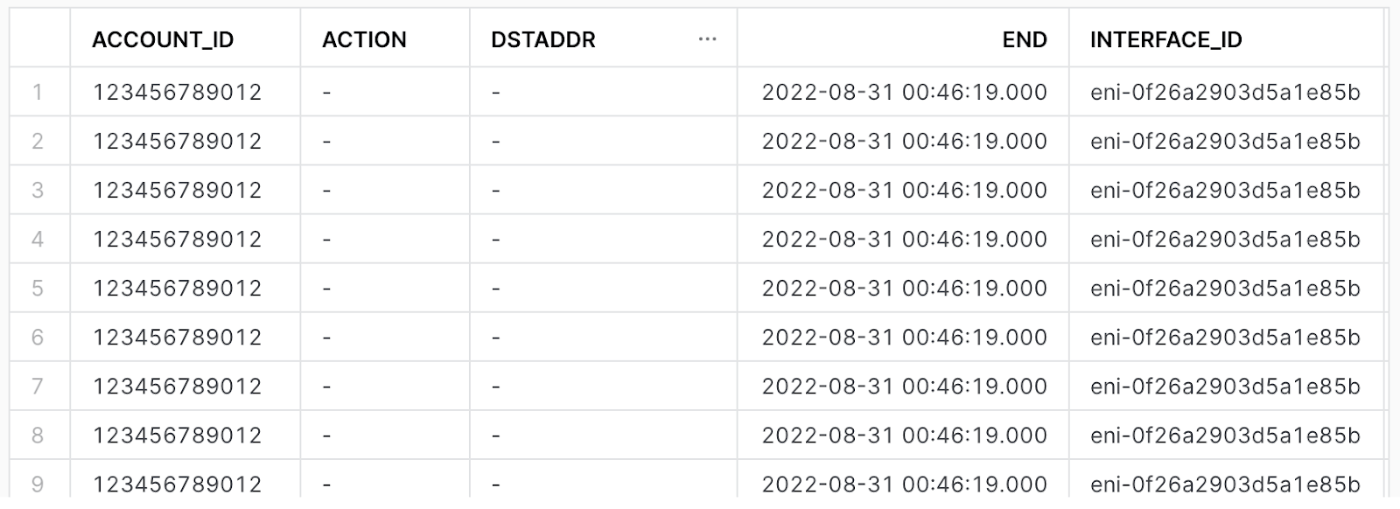
VPC Flow LogsダッシュボードをSnowflake上に作成
データが出来上がりましたので、Snowflake上で簡単な分析ダッシュボードを作成していきます。
本格的なアプリケーション作成もStreamlit in Snowflakeを使えば可能です。
こちらについては別記事にてStreamlit in Snowflakeを使ったアプリケーションコードを紹介する予定です。
ダッシュボードの作成
Snowflake WebUI上で「ダッシュボード」を選択し、右上の「ダッシュボード作成」をクリック。ダッシュボードの名前を入力します。
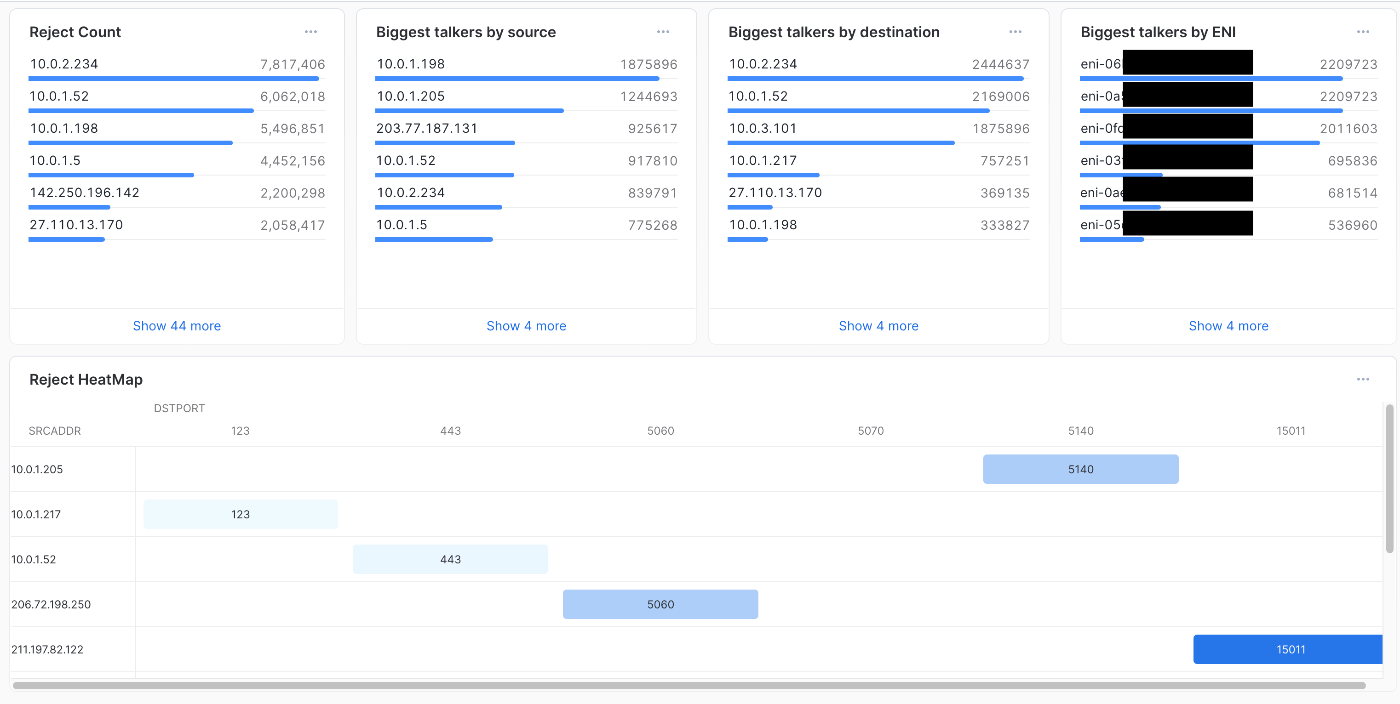
30日間のRejectカウント タイル
ダッシュボードの作成が完了すると何もないダッシュボードが作成されますので、左上の+ボタンで「新しいタイル」を選択します
SQLワークシートに以下のSQLをペーストし、実行
select
srcaddr,
count(srcaddr) as srcaddrcount
from log_analysis.public.vpc_flow_view
where
"START" > dateadd(day, -30, current_date())
and action = 'REJECT' group by srcaddr
order by count(srcaddr) desc
limit 10;
結果が表示されたらチャートを以下の設定にします
-チャート型:バー
-データ:バー:BYTES合計
-データ:Y軸:SRCADDR
-外観:オリエンテーション:横棒グラフ
-外観:バーの順序:バーのサイズ
-外観:順序の方向:降順
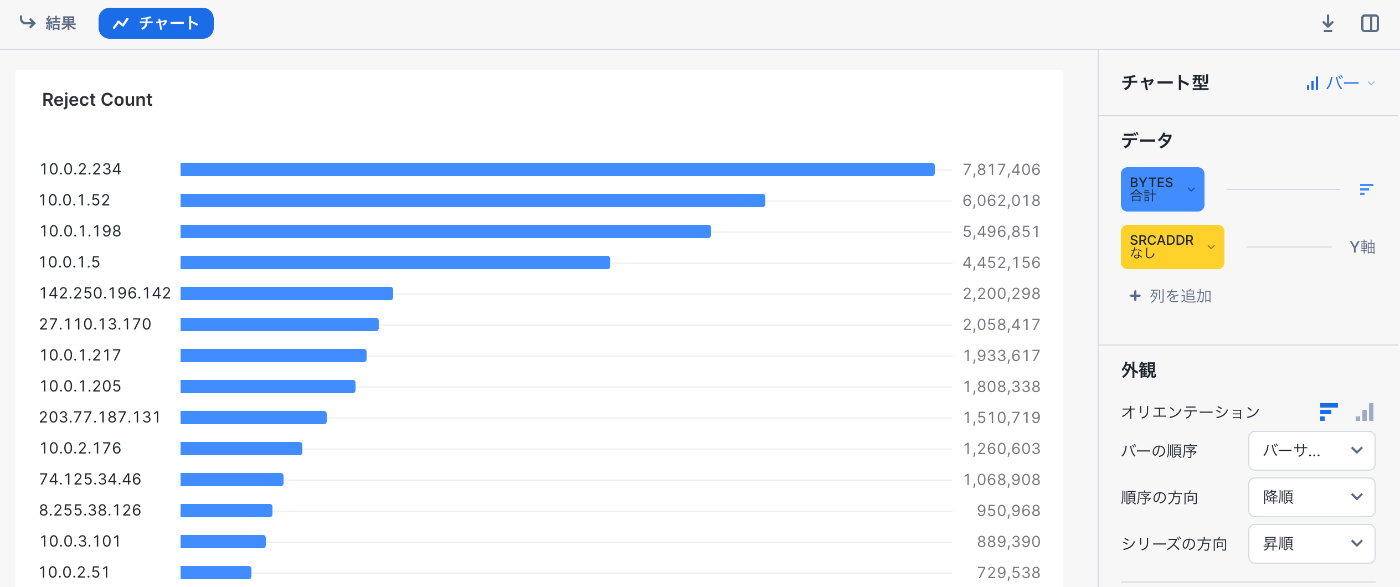
完了したらタイルに「Reject Count」と入力して、タイルを閉じます
最も通信している送信元 タイル
同じく左上の+ボタンで「新しいタイル」を選択します
SQLワークシートに以下のSQLをペーストし、実行
select
srcaddr,
sum(bytes) as total_bytes
from log_analysis.public.vpc_flow_view
where
"START" > dateadd(day, -30, current_date())
and action = 'ACCEPT'
group by srcaddr
order by total_bytes desc
limit 10;
結果が表示されたらチャートを以下の設定にします
-チャート型:バー
-データ:バー:TOTAL_BYTES合計
-データ:Y軸:SRCADDR
-外観:オリエンテーション:横棒グラフ
-外観:バーの順序:バーのサイズ
-外観:順序の方向:降順

完了したらタイルに「Biggest talkers by source」と入力して、タイルを閉じます
最も通信している送信先 タイル
同じく左上の+ボタンで「新しいタイル」を選択します
SQLワークシートに以下のSQLをペーストし、実行
select
dstaddr,
sum(bytes) as total_bytes
from log_analysis.public.vpc_flow_view
where
"START" > dateadd(day, -30, current_date())
and action = 'ACCEPT'
group by dstaddr
order by total_bytes desc
limit 10;
結果が表示されたらチャートを以下の設定にします
-チャート型:バー
-データ:バー:TOTAL_BYTES合計
-データ:Y軸:DSTADDR
-外観:オリエンテーション:横棒グラフ
-外観:バーの順序:バーのサイズ
-外観:順序の方向:降順

完了したらタイルに「Biggest talkers by destination」と入力して、タイルを閉じます
最も通信しているENI タイル
同じく左上の+ボタンで「新しいタイル」を選択します
SQLワークシートに以下のSQLをペーストし、実行
select
interface_id,
sum(bytes) as total_bytes
from log_analysis.public.vpc_flow_view
where
"START" > dateadd(day, -30, current_date())
and action = 'ACCEPT'
group by interface_id
order by total_bytes desc
limit 10;
結果が表示されたらチャートを以下の設定にします
-チャート型:バー
-データ:バー:TOTAL_BYTES合計
-データ:Y軸:DSTADDR
-外観:オリエンテーション:横棒グラフ
-外観:バーの順序:バーのサイズ
-外観:順序の方向:降順
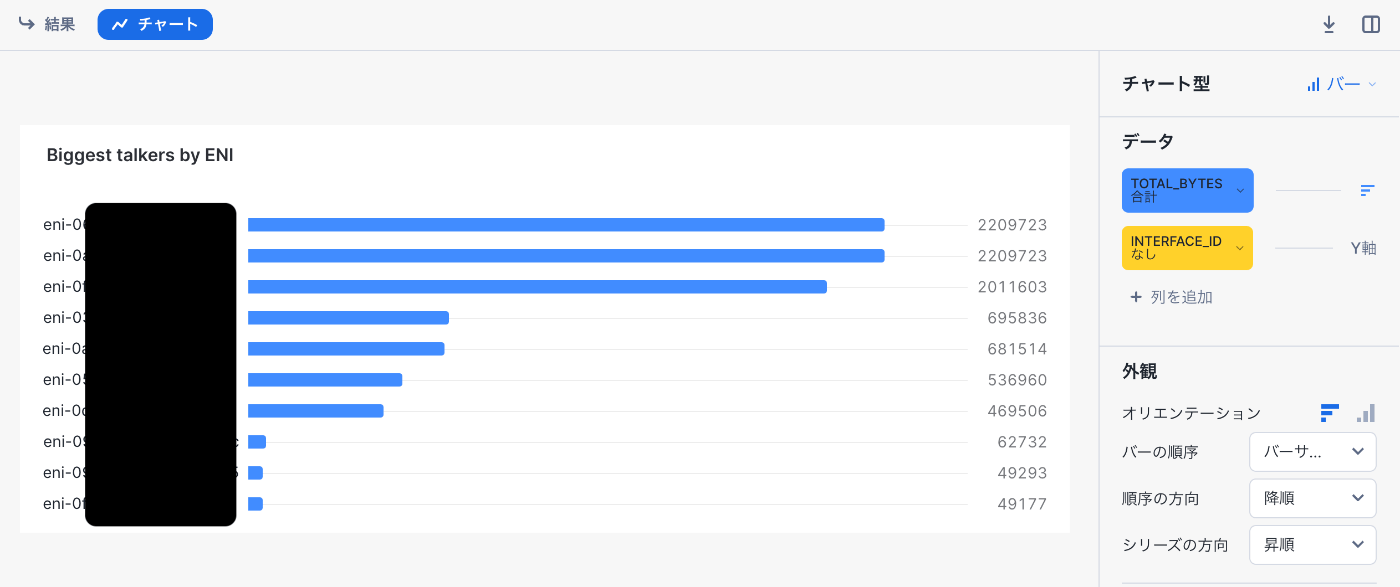
完了したらタイルに「Biggest talkers by ENI」と入力して、タイルを閉じます
まとめ
以上でAWS VPC Flow LogsをSnowflakeに取り込み、可視化するダッシュボードを作成することができました。
ダッシュボード自体はSQLを変更すれば、もっと深い分析も可能ですのでカスタマイズしてみてください。
Discussion