Rustで始めるwebフロント開発。フロントエンジニアのためのRustメモリ管理入門
この記事は、Supershipグループ Advent Calendar 2021の23日目の記事になります。
はじめまして。まさやんです。
普段はバックエンドをメインで書きつつ、フロント書いたり、AWSでインフラ構築したりと色々やらせてもらってます。
今回は、フロントエンドをメインにやってる人が、rustを始める時に参考になる記事を書こう!と思い立ち、書いてみました。
この前、JSConfの講演を聴いてて、rustの話もどんどん増えているなあと思ったのがきっかけです。
近いうちに、フロントの人もrust触れないとね〜、という時代になるかもなので、自身の学習も兼ねて整理してみました。
自分がつまずいたり、勉強する時参考になったなーという情報を整理して、最後にrustのフレームワークを紹介して終わりにします。
そこそこ長いので、休み休み読んでください。
対象読者
- フロントエンドを書いていて、最近rust聞くけど、まだ触ってないなーって人
- 触ってみたけど、メモリとかポインタ、ちょっと慣れなんかったなーって人
- TypeScript書いてるけど、rustとかwasmに興味あるわーって人
目次
- rustの特徴
- アプリケーションにおけるメモリ管理について
- rustの所有権システムをしっかり
- 型についてざっくり
- トレイトについてざっくり
- 式と文
- yewでSPAを構築してみる
- 終わりに
- 参考文献
※今回は、メモリ管理周りを重点的に書きました。他は結構ざっくりです。
rustの特徴
読み方はラストです。(英語発音はこれ?rəst)
Mozillaが中心にOSSで開発しており、世界的に好感度高めの言語として話題のようです。
日本のGoogleトレンドではじわじわって感じですね(Googleトレンド)
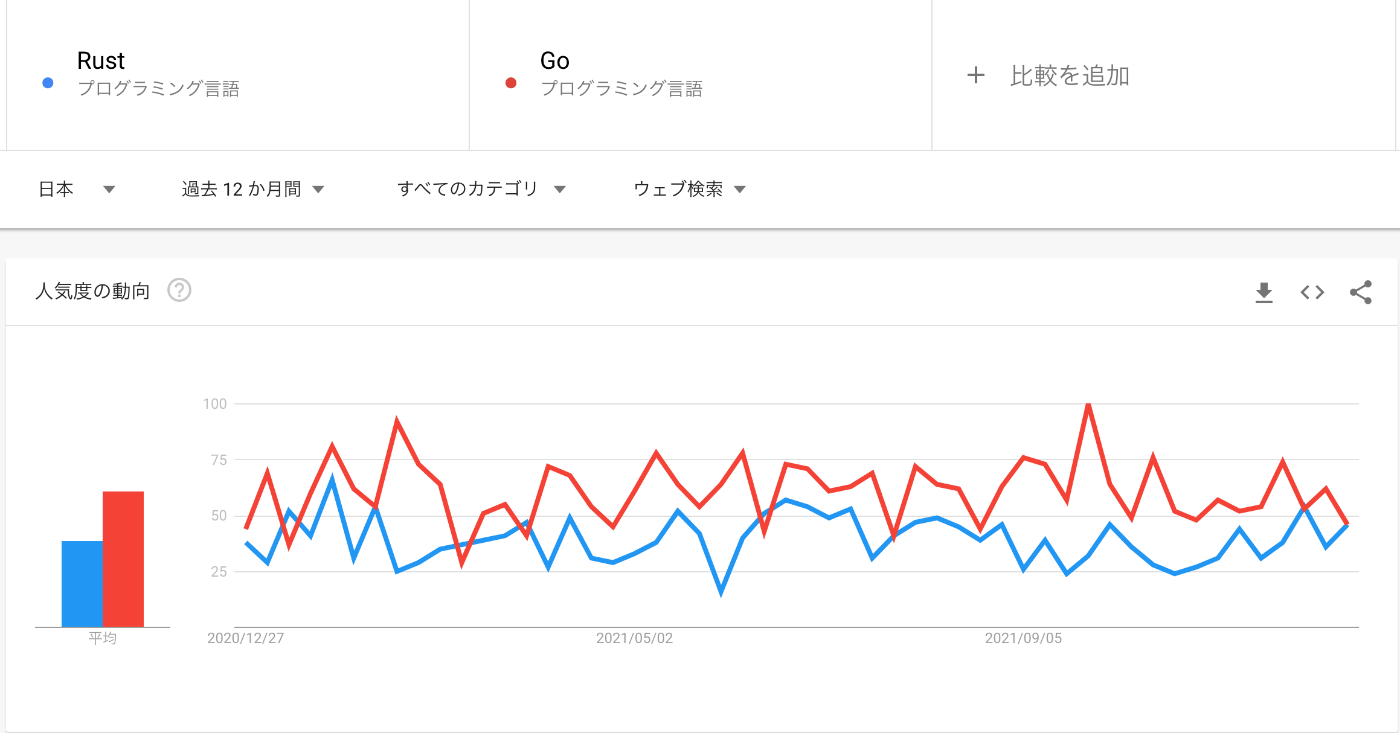
フロントエンドでは、wasm(web assembly)の文脈でよく耳にします。
rustのバイナリは、クロスコンパイルによって幅広いプラットフォームで動作します。(対応リスト)
さらに、FFI(他言語関数インターフェース)を通じて、Cやjsなどと連携が容易にできるのも特徴です。
rustは実行速度がめちゃ速い、みたいな話を聞いたことありませんか?
実際ベンチマークはC++やCと同レベルの速度が出るそうです。
Computer Language Benchmark Game
(めっちゃ速いな)
なぜ、rustで書かれたプログラムは高速なのでしょうか?
- マシンコードへのコンパイル
- Cとかgoとかと一緒
- 静的型付け
- ゼロコスト抽象化(静的ディスパッチメイン)
- GCを行わない軽量ランタイム
- 所有権システムでGCを使わないメモリ管理を実現してる
といった理由が起因しています。
GCを行わない・所有権システム、という箇所については、この後詳細に書きます。
ゼロコスト抽象化はまた今度。
あと、個人的には関数型言語の機能をいっぱい持ってるところが好きです。
僕はScalaで初めてmatch式(パターンマッチ)に触れたのですが、便利すぎて感動しました。rustも同様にパターンマッチとかenumとかポリモーフィズムとか、他言語でもお馴染みの便利な機能が備わってます。
アプリケーションにおけるメモリ管理について
JavaScriptの場合、メモリ管理は言語がよしなにしてくれるので、あまり意識をしなくてもプログラミングが可能です。
しかし、rustでは意識する必要あります。所有権システムという仕組みで安全には扱えますが、メモリ管理について理解しておくとスムーズに実装ができると思います。
というわけで、メモリ管理の基礎的な部分から、整理しながら書いてみます。(※不要な方は読み飛ばしてください)
そもそも、メモリとはなんでしょうか?
我々プログラマーが扱う主なメモリは、メイン・メモリと言われるものです。
ハード的にはDRAM(Dynamic Random AccessMemory)チップが使われてる、あいつです。
あいつ。

メイン・メモリとは?
- 主記憶装置というやつです
- 役割的には、コンピューターに対する命令(プログラム)とデータを格納するための領域です
- 1byte(8bit)ずつにアドレス(番地)と呼ぶ番号がついてます
- CPUはこのアドレスを指定してメイン・メモリに格納されたデータを読み書きします
- 揮発性があるんで、電気通らなくなったら消えます
- 1byte(8bit)ずつにアドレス(番地)と呼ぶ番号がついてます
- メイン・メモリの管理者は、OS・アプリケーションのプログラムです
我々は特にメイン・メモリの中でも、スタック領域とヒープ領域を意識する必要があります。
JavaScriptで再帰関数とか呼びすぎてスタックオーバーフロー起きますよね。そのスタックです。
スタック領域、ヒープ領域はどちらも、プログラム実行時にコードが利用可能な、一時的なメモリ領域です。
メモリと聞くと身構えてしまうかもしれませんが、論理的なイメージとして建物のビルを想像すると分かりやすいです。
例えば、1KBのメモリは1024階建てのビルとしましょう。
このビルのフロアごとにデータが格納されるイメージです。
よく書籍とか記事で見かける図になりました。

さて、フロア(メモリ)に格納されるデータには型がありますよね。
例えば、rustのchar型はUnicodeの1文字を表す型で、常に4byteを使います。※英数字であっても4byteです。
charを束縛する変数を定義すると、ビルの4階層分のフロアが占拠されるわけです。
よく聞くポインタも、ビルで考えてみましょう。
ポインタはデータの値そのものではなく、データが格納されている番地を持つ変数です。
変数aに束縛された、charがメモリのどこにいるか?何階のフロアから入居してるか?を指し示している、という訳です。
ポインタのイメージとしてはこんな感じです。
スタック・ヒープは別のオフィス街にあるビルだと思うと良いかもです。用途の異なるメモリ領域になります。

スタック領域とヒープ領域は、どちらも一時的なメモリ領域であると説明しましたが、どのような違いがあるのでしょうか?
スタック領域とヒープ領域
それぞれの特徴の違いを整理すると、以下のようになります。(引用: 実践Rust入門 p.176)
| 領域 | 確保のタイミング | 解放のタイミング | 確保・解放の速さ | 領域の大きさ |
|---|---|---|---|---|
| スタック領域 | 関数の呼び出し時 | 関数から戻る時 | 速い | 小さい |
| ヒープ領域 | 任意の時点 | 任意の時点 | スタックと比べると遅い | 大きい |
なぜスタックは速いのか?どんなデータが格納されるのか?など、それぞれ特徴をリストにしてみました。
スタック領域の特徴
- 関数の引数やローカル変数など、関数内やスレッド内で使われるデータが格納される
- スレッドごとに用意されるメモリ領域
- 関数から抜けたり、スレッドが終了するとスタックの内容は破棄される
- マルチスレッドなどを実装すると、基本的にはスタック領域はスレッドごとに作成され、ヒープは共用のメモリとして扱われる
- ヒープより高速で読み書きできる
- 後入れ先出し(LIFO)だし、データのサイズも分かってるから
- お皿の山を想像すると分かりやすい
- 上にしか置けないし、上からしか取れない
- なので、置きやすく、取り出しやすい
- あちこちメモリを飛ばなくていい
- 既知の固定サイズのデータのみ扱う
- コンパイル時にデータのサイズが分かってるもの
- サイズは小さい
- 値が格納しきれなくなると、スタックオーバーフローが発生する
- プログラムから好きに削除とか追加はできない
- コンパイラやOSが割り当てを決める
- データの値が可変でヒープ領域にあったとしても、ポインタが持つアドレス自体は固定長なので、スタック領域に積める
LIFOはこんなイメージです。
真ん中から抜けないなどの制約はあるが、簡単に出し入れできるの想像できますね。
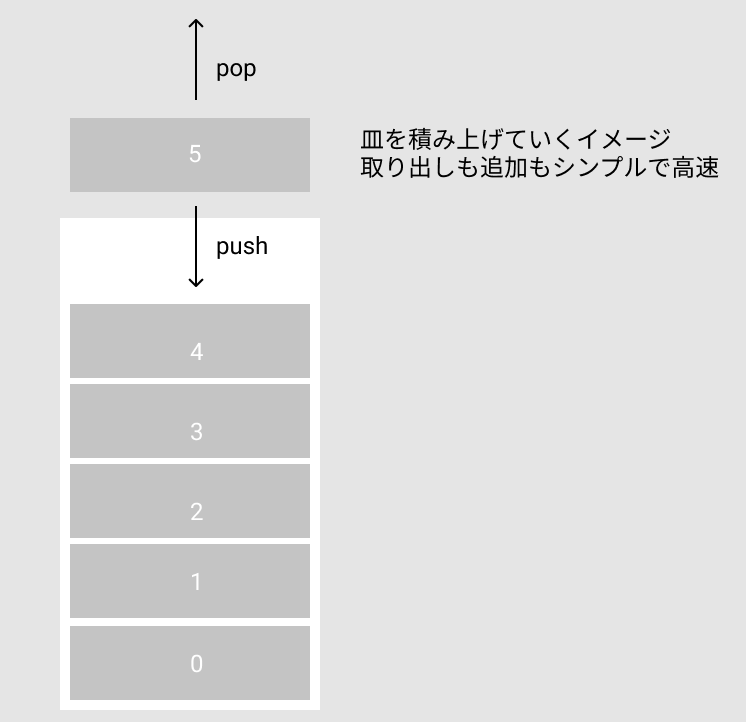
ヒープ領域の特徴
- 動的に確保され、プログラム内で共有されるデータが置かれる
- データ量が分からない可変な値を、アプリケーションからOSに依頼して都度メモリを用意してもらう
- allocating on the heap(ヒープにメモリを確保する)
- free(ヒープからメモリを解放する)
- プログラムから必要な時に確保と解放ができる
- 可変
- スタックより低速
- ポインタを追って、実際の値を参照しなきゃいけないから
- レストランで、先に来ている友達を探すみたいなもの
- ポインタを追って、実際の値を参照しなきゃいけないから
- サイズは大きい
プログラムを書く上で、意識しなければいけないメモリ領域について書いてみました。
スタック領域とヒープ領域があり、それぞれ役割が異なっています。
次は、実際にどのように確保・解放がされているのか考えてみましょう。
実際、メモリはどう扱われる?
メモリのライフサイクル自体の考え方は、多くのプログラミング言語で共通しています。
- 必要なメモリを割り当てる
- 割り当てられたメモリを使用する(読み込む, 書き込む)
- 必要なくなったら、割り当てられたメモリを開放する
ただ、プログラミング言語によって、1~3の実装が異なります。
CやC++など、mallock関数やfree関数など1~3を扱う実装がある言語
- メモリの割り当てから、解放まで意識して行います
- グローバル変数、静的変数、ブロックスコープの自動変数の生存期間 + 動的確保
- 各変数でスタックとヒープ、参照などを意識して値を扱います
- C++などはスマートポインタという、自動リソース解放の仕組みもあります
- 実装は様々ありますが、メモリ安全性を意識したプログラミングが必要になります
JavaScriptやpythonなどガベージコレクションの機能を持つ言語
- 値の生成時に自動でメモリが割り当てられ、ガベージコレクション(GC)という仕組みでメモリが解放されます
- 不要になったリソースを自動で解放してくれるすごいやつです。自動でメモリ安全性を担保してくれるますが、実行速度に影響する場合があります
- mallocやfreeを内部で呼んだり、それらに相当する実装を持っていたりと、言語がよしなにカバーしてくれている訳です
- なので、jsのコードを書く時、メモリ管理を特別意識しなくても書くことができたわけです
- ※仕組みとしては理解しておかないと、重いコードやスタックオーバーフローを引き起こすことにはなります
- ガベージコレクションについても、参照カウンタやマークアンドスイープアルゴリズムなど、複数の実装方法があります(具体的な実装は勉強中なので省略)
rustは以下のようにメモリを管理します。
- GCではなく、所有権とライフタイムいう仕組みでメモリを扱う
- スコープを抜ける時にdropという特殊な関数を呼び出して、メモリを解放している
- スマートポインタ(RAII)のような仕組み
- CやC++と近く、同じ実装も使われているが、より安全に扱える仕組みが提供されている
- 参照自体の生存期間を安全な範囲に制限する
- スコープを抜ける時にdropという特殊な関数を呼び出して、メモリを解放している
rustの所有権システム
所有権システムは、rustのメモリ管理の仕組みです。
正しく理解しないと、数多くのコンパイルエラーを経験することになります。
具体的には、メモリへの参照自体の生存期間を、安全な範囲に制限する仕組みです。
どのような仕組みなのか、ざっくりまとめてみました。
- コンパイル時にメモリがちゃんと扱えてない場合はコンパイルエラーになる
- コンパイル時にメモリ安全性を担保してくれるので、C系より安全にコードを書ける
- スマートポインタ(RAII)や自動変数といったメモリ管理の手法 + ライフタイムというデータの生存期間(寿命)
- コンパイル時に検査されるため、GCのようにプログラムの実行時に走るものではない
- そのため、アプリケーションの実行性能に影響を与えづらい
メモリ安全性を担保する、とは?
Cなどは基本的に開発者が手動でメモリ管理を行うため、メモリ安全性が担保されてないコードを書いてしまうことがあります。
rustでは、コンパイル時にメモリがちゃんと扱えているか?を見て安全性を担保してくれるのです。
メモリ安全性の保証内容
- メモリの二重解放による未定義動作
- 未定義動作とは、言語に動作の定義がない命令を実行した結果生じる動作です
- 予測不能のバグやクラッシュが発生する可能性があります
- 不正なポインタ(ダングリングポインタ)の作成
- 開放済みの領域など無効なメモリをさすポインタのこと
- マルチスレッドにおけるデータ競合がないこと
メモリ管理の問題はバグや脆弱性の原因になります。
特にメモリ管理に慣れてないプログラマにとって、rustの仕組みが非常に助かるものであることは間違いないと思います。
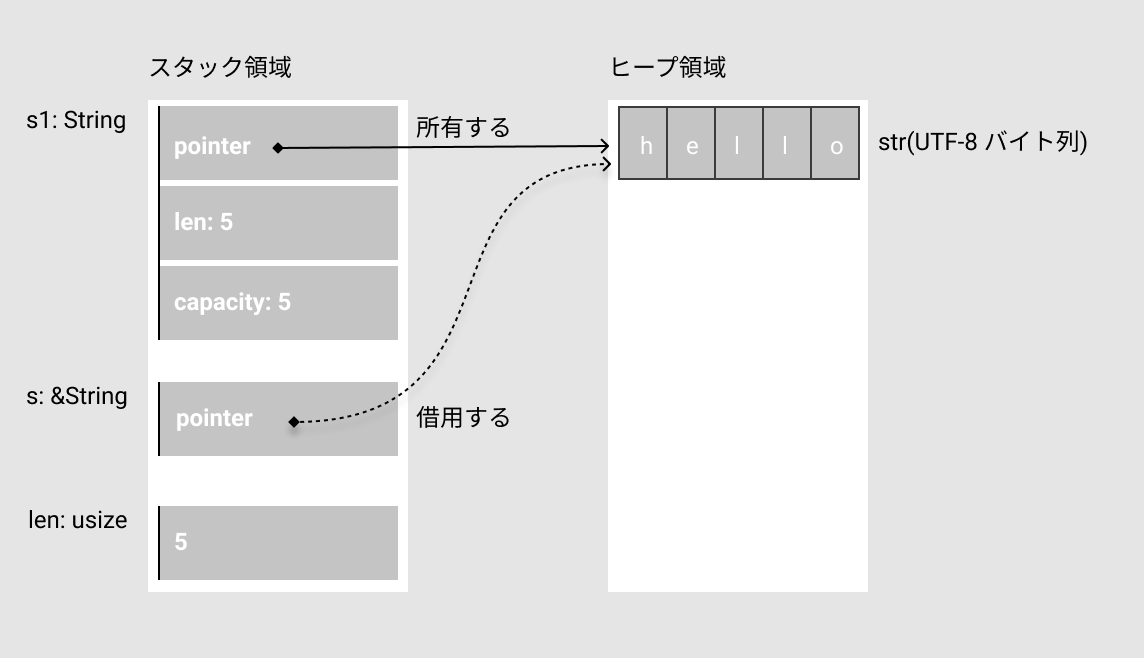
実際に、コードと合わせてメモリの状態を見てみましょう。
スタックとヒープの状態をコードから追う
ヒープへの参照はどのような関係になっているか、図に書いてみました。
(やっとrustのコードが出てきた)
rustは、main関数がエントリポイントになります。
println!は関数のようですが、マクロです。(rustでは!マークがついてるものはマクロです)
コンパイル時にテンプレート({})に文字列を埋め込んでくれます。フォーマットの種類はこちらを参照。
今回は、公式ガイドの説明コードを参考にしています。
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
// '{}'の長さは、{}です
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
println!行時点のメモリの状態はこんな感じです。
ダングリングポインタ(不正なポインタへのアクセス)を再現してみましょう。
実際、このコードはrustではコンパイルエラーになります。
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello"); // 関数スコープの中で変数sにStringを束縛
&s // 変数sへの参照を返している
}
&をつけると参照(reference)を作成することができます。
参照型は、メモリ安全なポインタです。ポインタは、メモリの番地(ビルのどこに入居してるか?)でしたね。
ポインタをもとに、実際の値を照らし合わせにいく訳です。
rustでは、全ての値に所有権という概念があります(後で説明します)。参照することは、所有権の観点から言えば、借用しているとも言えます。別の人が持ってるものを借りてるってことです。
rustの文脈では、よく借用という単語も出てきますが、実態としては参照と同じで観点の違いと理解して大丈夫かと思います。
参照の仕組みなどはCやGolangなどと一緒です。
ポインタがさす値を取り出したり、ポインタがさす値を変更する時には、参照型に対してデリファレンス(*をつける)をする必要があります。
さて、参照から話を戻して、このダングリングが発生するコードの場合、メモリはどのようになるでしょうか?

メモリ安全性を担保する仕組みによって、破棄される予定の参照がある場合、コンパイルエラーになる訳です。
実例を見たところで、所有権システムについて深掘ってみたいと思います。
所有権システムの特徴
- リソースを自動開放してくれる。値が不要になった時、使っていたリソースを一度だけ(重要)開放する
- 開放漏れによるメモリリークを防止してくれる
- 二重解放による未定義動作を防止してくれる
- 所有権システムの扱うリソースは実はメモリだけではない。ファイルディスクリプター、ソケットなども対象であり、そういったクローズ処理も扱ってくれる
- ダングリングポインタを防止してくれる
Cなどのメモリ管理で辛い部分を、言語仕様がサポートしてメモリ安全性を担保してくれる、という感じですね。
どうやって実現するのでしょうか?
rustはコンパイル時に以下の概念に沿って、コードをチェックします。
- 所有権
- ムーブセマンティクス・コピーセマンティクス
- ライフタイムの追跡と借用規則
ひとつずつ確認しましょう。
所有権
- ある値を所有できる権利です(そのまんまですね)
- 値の所有権を持つ所有者になれるのは、変数か値自身です
- 値自身てどゆこと?
- 例えば、structという構造体はフィールド値の所有者になります
- JavaScriptのclassはrustにはないです
- 名前付きのフィールド構造体(struct)が、classに近い扱い方ができます
- 値の所有権は1つだけ。つまり、所有者は基本的には1人だけ、ということです
- 共同所有者を実現する方法はあります(RC型、Arc型)
- Rc型は参照カウンタで実装されています
- ざっくり言うと、何人が参照してるかチェックしてて、使う人いなくなったら解放する仕組み
- マルチスレッドで使うならArc型です
- Rc型は参照カウンタで実装されています
- 共同所有者を実現する方法はあります(RC型、Arc型)
- 所有権は貸し出せます(借用)
- 借用の場合、貸しているだけなんで、もちろん所有者は所有権を失わないです
- 所有権は譲渡もできます
- あげちゃってるんで、所有者は所有権を失います
- 所有権の移譲をムーブと言います
- 所有者がスコープを抜ける時、値のライフタイムがつき、そのタイミングで値が破棄されます
- 具体的には、ブロックの終端閉じ括弧(
})で、自動的にdrop関数が呼ばれて、リソースが破棄されます - ライフタイムは値の寿命・生存期間です。後述します。
- 具体的には、ブロックの終端閉じ括弧(
所有、借用のイメージです。
参照の補足で書きましたが、所有権の観点からすると参照は借用と言い換えることができます。
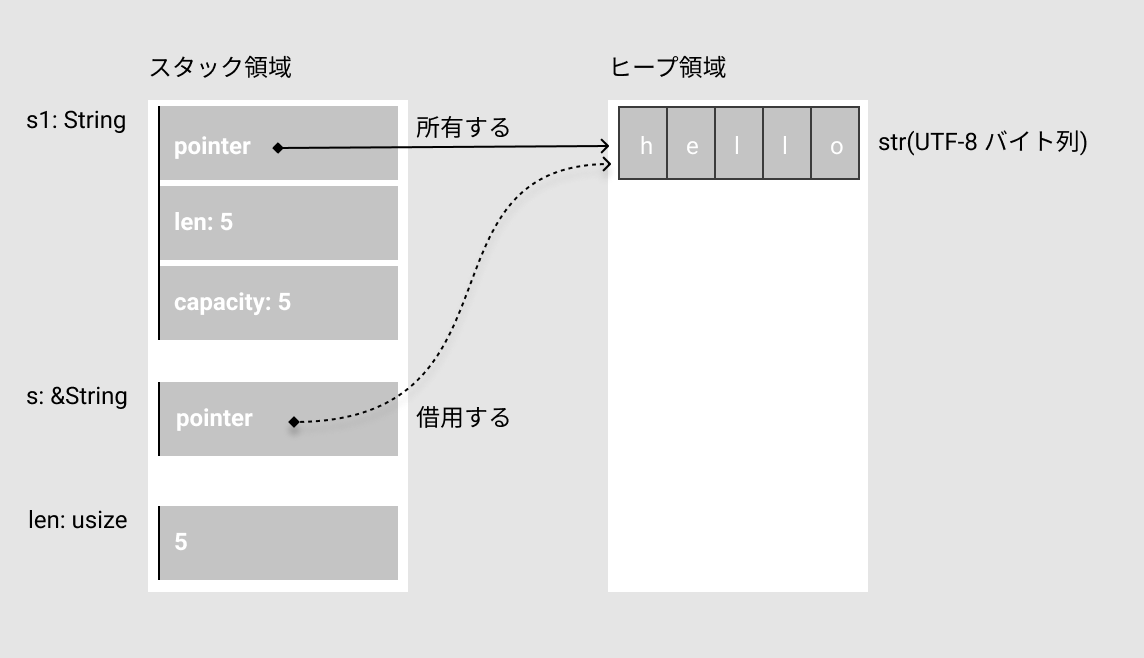
公式の参考コードと説明が充実しているので、そちらも参考にしてみてください(The Rust Programing Language 日本語版 4. 所有権を理解する)
ムーブセマンティクス
- 所有権を移動することです
- つまり、値をまるっと移譲する感じです
- shallow copy感があるかもしれませんが、所有権がうつるため以前の変数は使えません
コードと図を見てみましょう。
fn main() {
let mut s1 = "hello".to_string();
let s2 = s1; // 値の所有権がムーブ
println!("s2: {}", s2);
// println!("s1: {}", s1); // コンパイルエラー。s1はすでに値の譲渡している
s1 = "world".to_string();
println!("s1: {}", s1); // 新しい値を所有しているのでエラーにならない
}
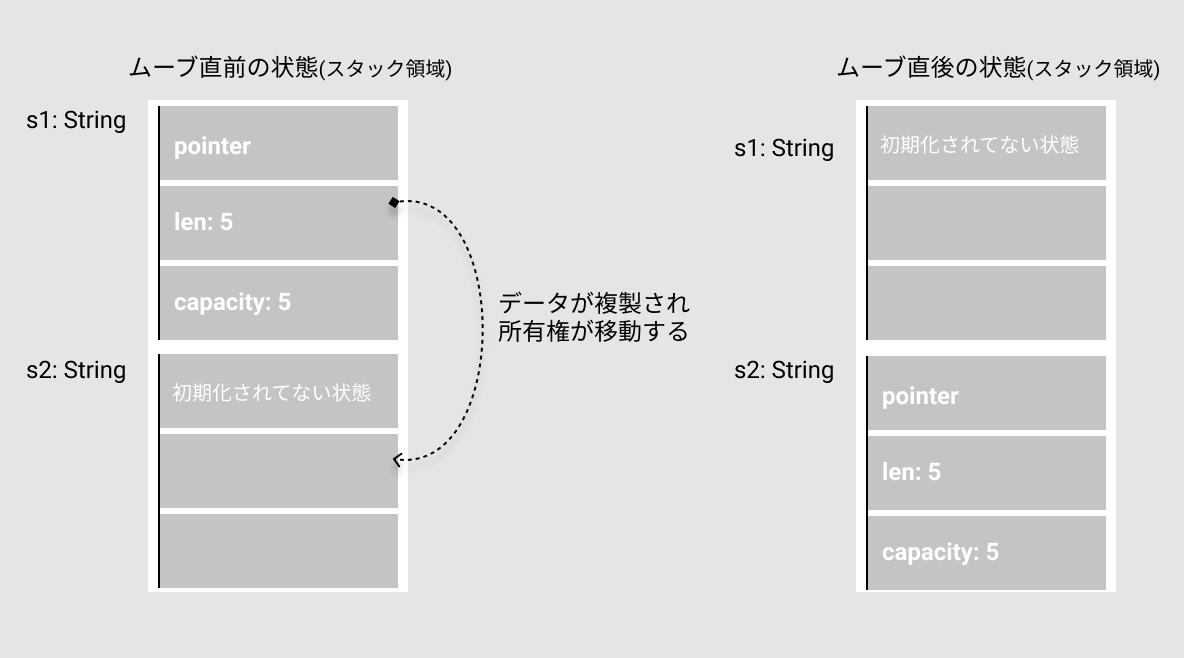
コードの中に、mutという単語がありますが、後述します。変数の不変・可変を示すものです。
コピーセマンティクス
- deep copyっぽいやつです
- 実際に値を複製します
- なので、所有権が移動することもなく、コピー元の変数も参照できます
コードと図です。
fn main() {
let i1 = 1;
let i2 = i1; // 値の所有権がコピー
println!("i2: {}", i2);
println!("i1: {}", i1);
}
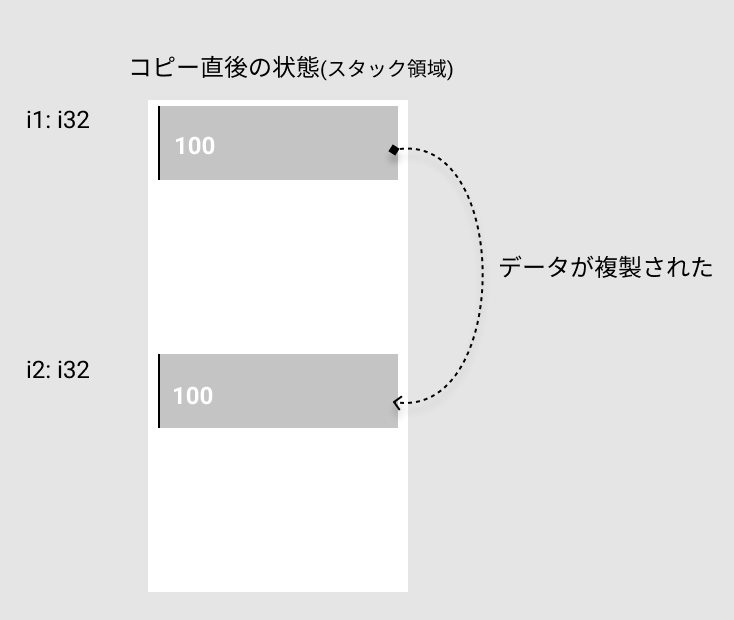
コードを見る限り、ムーブとコピーで使う関数が違う、とかそういう話ではないですよね。
変数に束縛する型によって挙動が変わっているようです。
この違いがどこから生まれるのか、確認しましょう。
コピーセマンティクスが発生する条件
- Copyトレイト(std::marker::Copy)が実装されていること
- トレイトとはTypeScriptで言うInterfaceのようなものです
- 共通の振る舞いを定義します
- つまり、Copyできる準備できてる型はコピーセマンティクスになります
- Copyトレイトを実装できる条件もありますが、省略します(Copyトレイト)
ちなみに、スカラ型などは実装されています。そのため、コード例のi32型はコピーの挙動になりました。
ムーブの例に出した、rustのString型は可変文字列であり、図にあるようにヒープ領域に値を保持します。ヒープ領域を使う型はサイズを予想しづらく、大きなサイズでのコピーが発生する可能性あるためCopyトレイトは実装されていません。
structなども構造体も同様ですが、条件を満たせばCopyトレイトを独自で実装することは可能です。
ライフタイム
- データの生存期間です
-
- 値のライフタイム
- 値がメモリに確保されてから破棄されるまでの期間
-
- 参照のライフタイム
- 値への参照が仕様される期間
-
- 例えば、関数の中で定義された値は、ブロックの終了と共に破棄されるため、以降参照することはできません
- ダングリングポインタの例で見た通りですね
借用規則
- コンパイラが以下の規則に沿っていることを確認する。それによって、メモリ安全性が保証される
-
- 不変・可変を問わず、参照のライフタイムが値のライフタイムよりも短いこと
- 値がもう生存してないのに、参照してたらおかしいよね?と言うこと
-
- 値が共有されている間(不変の参照が有効な間)は値の変更を許さない
- 不変前提で参照してる人がいるのに、値変わったら困るよね?と言うこと
-
不変の参照や、不変・可変、といった単語が出てきました。
これは、読んで字の如く変数を変更できるか、できないか?という意味です。
rustの変数は、デフォルトで不変として扱われます。
可変にしたい場合は、mutという宣言をつけることで、可変の変数として扱えます。
この仕様は安全性を考慮されて設計されており、変数の状態も含めてコンパイラによるチェックが効いてきます。
借用規則で許される状態は、以下のいづれか1つです。
- 任意個の不変の参照 &Tを持つ
- ただ1つの可変の借用 &mut Tをもつ
不変の参照を見てるのに、変わるなんて聞いてないよー、というコード
let mut s = "hello".to_string();
let r1 = &s; // 変数sへの不変の参照
let r2 = &mut s; // 変数sへの可変の参照
println!("{}, {}", r1, r2);
データ競合するからダメだねー、というコード
let mut s = "hello".to_string();
let r1 = &mut s; // 変数sへの可変の参照
let r2 = &mut s; // 変数sへの可変の参照
println!("{}, {}", r1, r2);
どっちも借用規則に違反してるので、コンパイルエラーです。
このように、誰(変数、値)がデータを所有していて、誰に貸し出していて、それらの所有者がスコープ抜けてライフタイムが尽きる前に、よしなにしてくれてるよね?というのをコンパイラがチェックすることで、メモリ安全性を担保しているという訳です。
すげーですね。
なお、メモリ安全性を担保するための機能でありますが、特殊な構造体を扱う場合やFFI(他言語関数インターフェース)を通して別言語と連携する際など、この機能が制約になってしまうことがあります。
そのためunsafeという、最低限の所有権システムのチェックを保ちつつ、コンパイラに大丈夫だから信じてね!と伝えて、一部の制約から外れた実装をする仕組みも用意されています。
具体的な説明はここでは省くので、公式ドキュメントをご参照ください。(The Rust Programing Language 日本語版 19. 高度な機能)
型についてざっくり
さて、JavaScript経験者がRustを触る時に壁になりそうな(自分はそうだった)、Rustのメモリ管理について説明しました。
記事も長くなってきたので、ここからはざっくりでいかせていただきます。(また記事書くので...)
例の如く、大枠は公式ドキュメントをご参照ください。
(The Rust Programing Language 日本語版 3. 一般的なプログラミングの概念)
JavaScript、TypeScriptと比較した時、これなんぞ?ってなりそうな箇所を補足しておきます。
配列表現の型
js、tsと異なり、配列を表現する型が複数あります。
固定長と可変長、実データの所有の有無や要素の追加・削除の可否で複数表現があるのでややこしいかもです。
配列を表現する型(引用: 実践Rust入門 p.180)
| 型 | 役割 | 実データを格納するメモリ領域 | 要素数が決定されるタイミング | 要素の追加・削除 | 実データを所有するか |
|---|---|---|---|---|---|
ベクタ Vec<T>
|
サイズ可変の配列 | ヒープ領域 | 実行時 | 可 | 所有する |
配列 [T; n]
|
サイズ固定の配列 | スタック領域 | コンパイル時(型に現れる) | 不可 | 所有する |
ボックス化されたスライス Box<[T]>
|
サイズ固定の配列 | ヒープ領域 | 実行時 | 不可 | 所有する |
その他のスライス &[T]、&mut [T]
|
ベクタや配列へのアクセスを抽象化 | ヒープまたはスタック。参照先に依存 | 実行時 | 不可 | 所有しない |
実践Rust入門さんにとても有難いまとめがあったので、引用させていただきます。
役割やできることが異なるので、用途に応じて使い分けます。
ベクタって何?
配列を表現する型で固定長の配列と違って、要素の追加や削除ができます。
また、配列型([T; n])はコンパイル時点でサイズが分かるので、スタック領域に置かれますが、ベクタは可変長なのでヒープ領域にデータが置かれます。
let v1: Vec<i32> = Vec::new();
let v2 = vec![1, 2, 3]; // vec!はマクロでベクタを初期化してくれる
let mut v3 = Vec::new();
v3.push(5);
v3.push(6);
ボックス化って何?
Box<T>でボックス型を作れます。
ボックスはメモリ安全なポインタで、それだけ聞くと参照(&)型と同じですが、異なる特徴があります。
-
Box<T>で包んだT型のデータをヒープ領域におきます - ポインタでありながら、実データを持っています
言い換えると、間接的な参照とヒープ領域のメモリ確保をやってくれるだけの型です。
値を丸ごとスタックからヒープに移動してくれます。
どこで使うの?って感じかもしれませんが、再帰的なデータ構造を実現する際や、大きなデータをコピーすることな他者へ移動したい時などに使います。
ポインタであるということは、サイズが分かるということなので、コンパイラが必要な計算が明確になります。
詳しくは公式ドキュメントの説明を参考にしてください。
(The Rust Programing Language 日本語版 15. スマートポインタ)
※ちなみに、スマートポインタとは、メモリ管理機能を持つ賢いポインタです。具体的には、自身が破棄される時に、必要に応じてリソース解放するような機能を持っています。通常のポインタを生ポインタと言います。
※rustの標準型の多くは、スマートポインタとしての実装になっています
スライスって何?
配列要素や、連続したメモリ領域におなじ型要素が並んでるデータ構造に対して、効率的にアクセスするためのビューです。
具体的には、配列やベクタ、文字列など。
データ全体ではなく、そのうちの一連の要素だけを参照します。
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
println!("1: {}", hello);
println!("2: {}", world);
スライスにも不変・可変の概念があり、ソートなどしたい場合は可変のスライスを作成する必要があります。
let mut a = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1];
&mut a[0..5].sort();
スライスの長さは実行時に決まるので、ヒープ領域にデータは置かれます。
(The Rust Programing Language 日本語版 4. 所有権を理解する)
その他の型
あとは、Stringとstrなど、ややこしい箇所あるんですが、記事が長くなったのでまたの機会にします...。
考え方としては配列表現とおなじで、文字列についても固定・可変やデータの所有について異なっていると分かれば、ドキュメントなどスムーズに読めるのではないかと思います。
構造体(struct)など、基本的な使い方はドキュメントをご参照ください。
ここら辺は大きくつまづく部分はなさそうです。
(The Rust Programing Language 日本語版 5. 構造体を使用して関係のあるデータを構造化する)
トレイトについてざっくり
JavaScript, TypeScriptだと、traitはあまり聞き慣れないかもしれません。
TypeScriptだと、Interfaceやmixinに近い概念です。
rustには継承という概念はないですが、traitを使うことでアドホックポリモーフィズムを実現できます。
共通の振る舞いを定義したり、引数の型に応じた関数定義したりと、構造体が一層便利に扱えます。
構文と使い方は、以下のような感じです。
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
structのデフォルト値を実装など、幅広く応用ができるのでトレイトの仕組みは学習しておくと良さそうです。
(The Rust Programing Language 日本語版 10. ジェネリック型、トレイト、ライフタイム)
その他、enumやパターンマッチなどたくさんあるのですが、長くなってきたのでまた別の機会に譲ります。
あとは、JavaScriptに慣れているとちょっと混乱するかもな、と思った式と文だけ整理しておきます。
式と文
rustにおける文とは、()(ユニット型と言って、空を表すvoidみたいな表現)を返すコードです。文末にセミコロン(;)がつきます。
文は2種類あります
- 宣言文
- 変数を導入するlet文
- use宣言で、ライブラリ(※rustではクレートと言う)を読み込む
- 関数定義
- など
- 式分
- 式の末尾に;をつけることで、式を分に変換したもの
- 式なので、値を返す
- 式は末尾の;を省略できるものもある
- 式の末尾に;をつけることで、式を分に変換したもの
式とは、ユニット型()以外の値を返すコードで、文以外のものは全て式と考えてOKのようです。
式分があるお陰で、このようにフロー制御の結果を変数に束縛することができます。
fn main() {
let condition = true;
let number = if condition {
5
} else {
6
};
// numberの値は、{}です
println!("The value of number is: {}", number);
}
このような表現はJavaScriptではできませんが、あると便利です。
Scalaで初めて、評価して値を返す式に触れた(Scalaでは式)のですが、感動しました。Rustも式分できます。
yewでSPAを構築してみる
最後に、実際にフロントエンドでrustを使う時の参考情報として、フレームワークを紹介します。
今回は簡単な紹介だけで。
今度あたらめて、実装・tailwindやwebpackの設定など絡めた記事を書かせていただきます。
rustフロントエンドのフレームワークでは、かなりStar多いのがyewです。
yewstack/yew
最近のReactやvueを書いていれば、理解しやすいと思います。
HTMLのDOMとHTMLタグって、親子関係ある、特定の属性を保持する値だから、関数で表現できるじゃん的な。状態もイベントでリアクティブに管理できるじゃん的な。
HTMLタグを返すコンポーネント関数を定義し、状態管理やルーターと合わせてHTMLのUIを実装できます。
これはyew/examplesにある画面です。

このように、yewだけでも、webページを作成することができます。
ちょいちょい省略してますが、参考コード。
use yew::{Component, Context, html, Html, Properties};
mod state;
pub struct Model {
state: State, // 状態管理
focus_ref: NodeRef,
}
impl Component for Model { // yewのコンポーネントを実装する
type Message = Msg;
type Properties = ();
// ライフサイクルフック関数を定義する
fn create(_ctx: &Context<Self>) -> Self {
let entries = LocalStorage::get(KEY).unwrap_or_else(|_| Vec::new());
let state = State {
entries,
filter: Filter::All,
edit_value: "".into(),
};
let focus_ref = NodeRef::default();
Self { state, focus_ref }
}
// ~~
// viewフックはDOMを返す
fn view(&self, ctx: &Context<Self>) -> Html {
let hidden_class = if self.state.entries.is_empty() {
"hidden"
} else {
""
};
// html!はマクロ。JSXみたいに扱える
html! {
<div class="todomvc-wrapper">
<section class="todoapp">
<header class="header">
<h1>{ "todos" }</h1>
{ self.view_input(ctx.link()) }
</header>
<section class={classes!("main", hidden_class)}>
<input
type="checkbox"
class="toggle-all"
id="toggle-all"
checked={self.state.is_all_completed()}
onclick={ctx.link().callback(|_| Msg::ToggleAll)}
/>
<label for="toggle-all" />
<ul class="todo-list">
{ for self.state.entries.iter().filter(|e| self.state.filter.fits(e)).enumerate().map(|e| self.view_entry(e, ctx.link())) }
</ul>
</section>
<footer class={classes!("footer", hidden_class)}>
<span class="todo-count">
<strong>{ self.state.total() }</strong>
{ " item(s) left" }
</span>
<ul class="filters">
{ for Filter::iter().map(|flt| self.view_filter(flt, ctx.link())) }
</ul>
<button class="clear-completed" onclick={ctx.link().callback(|_| Msg::ClearCompleted)}>
{ format!("Clear completed ({})", self.state.total_completed()) }
</button>
</footer>
</section>
<footer class="info">
<p>{ "Double-click to edit a todo" }</p>
<p>{ "Written by " }<a href="https://github.com/DenisKolodin/" target="_blank">{ "Denis Kolodin" }</a></p>
<p>{ "Part of " }<a href="http://todomvc.com/" target="_blank">{ "TodoMVC" }</a></p>
</footer>
</div>
}
}
例えば、レンダリングのライフライクルは以下です。
create() → view() → yew renders to page → mounted()
イベントが発生した時は、このように伝播していきます。
trigger event / callback / send message → update() → (optional) view() → yew renders to page
(参考: 公式ドキュメント)
※ライフライクルはもっと理解を深めたら、図解してみます!
stateやpropsが扱えたりと、割と馴染みやすいのではないかなとは思っています。
コンポーネントの共通化や、tailwindの導入・webpackの設定など、別途紹介させていただきますね。
今回紹介したyewのコードはexampleにあるので、もし興味があればのぞいてみてください。
yew/examples/router
おわりに
JavaScript、TypeScriptをメインに書いてるフロントエンドエンジニア向けに、rustの言語仕様を整理してみました。
僕自身、まだまだ学習途中なので、もし間違っている箇所などあればご指摘いただけると助かります。
rust、たのしー!!
最後に誤解がないように書いておきますが、言語自体の性能が早いからといって、webサイトのパフォーマンスが絶対良くなるよ、という話ではないと思っています。
webクライアントのユースケースやチームメンバーに応じた、適切な選択をすべきです。
個人的にはrustという言語はすごく楽しいので、プライベートではバックエンド・フロントエンド問わず積極的に書いてます。
AtCoderとかもrustで始めてみようかなと。
公式ドキュメントが充実してたり、本がたくさんあったり、rustコミュニティには感謝です!
参考文献
The Rust Programing Language 日本語版
実践Rust入門
Software Design 2021年9月号
プログラムはなぜ動くのか 第二版
Mozila Web Docs メモリ管理
Imos Lab Rustは何が新しいのか
yew 公式ドキュメント
最後に宣伝
Supershipではプロダクト開発やサービス開発に関わる人を絶賛募集しております。
ご興味がある方は以下リンクよりご確認ください。
Supershipグループ 採用サイト
是非ともよろしくお願いします。
Discussion