Azure Cognitive Search REST API における JSON 定義形式の基礎
Azure Cognitive Search のインデックス作成を行う際に、Azure Portal では対応していない機能があるため、REST API や SDK でインデックス作成を行うことが多くなります。REST API を使用する場合、設定内容は JSON 形式で定義するため、JSON 形式による定義の構造を理解しておく必要があります。
各 JSON 定義の関連性
Azure Cognitive Search でインデックスを作成する際には、以下の定義を行います。
- データソース定義
- スキルセット定義
- インデックス定義
- インデクサー定義
これらの定義情報は JSON 定義内のプロパティで、以下のように関連付けられます。
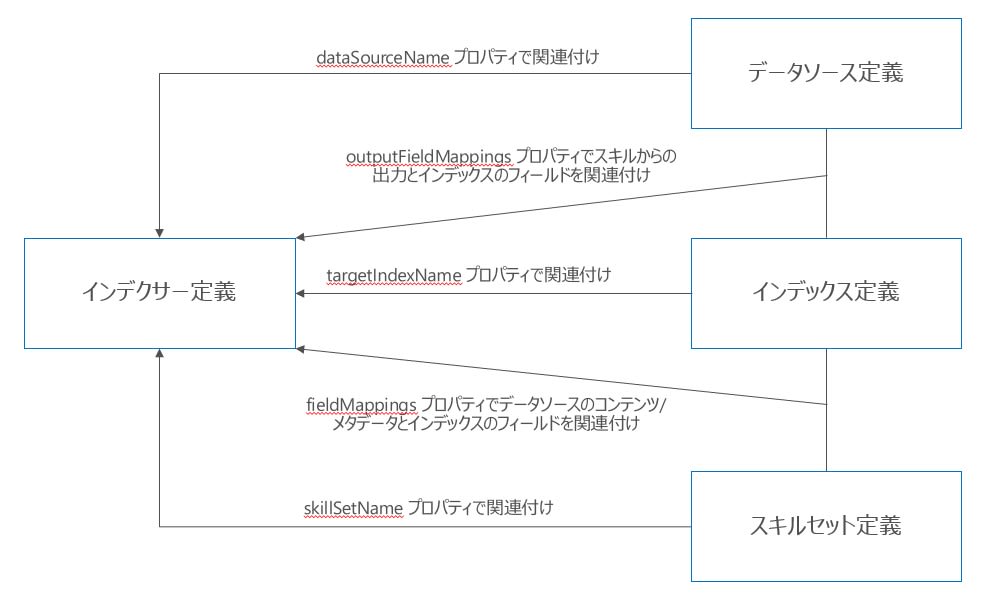
以下では、これらの定義において特に重要な項目について解説します。詳細については、以下のドキュメントを参照してください。
- データソース
- インデックス
- スキルセット
- 組み込みのスキル
- AI エンリッチメントで画像からテキストや情報を抽出する
- インデクサー
データソース
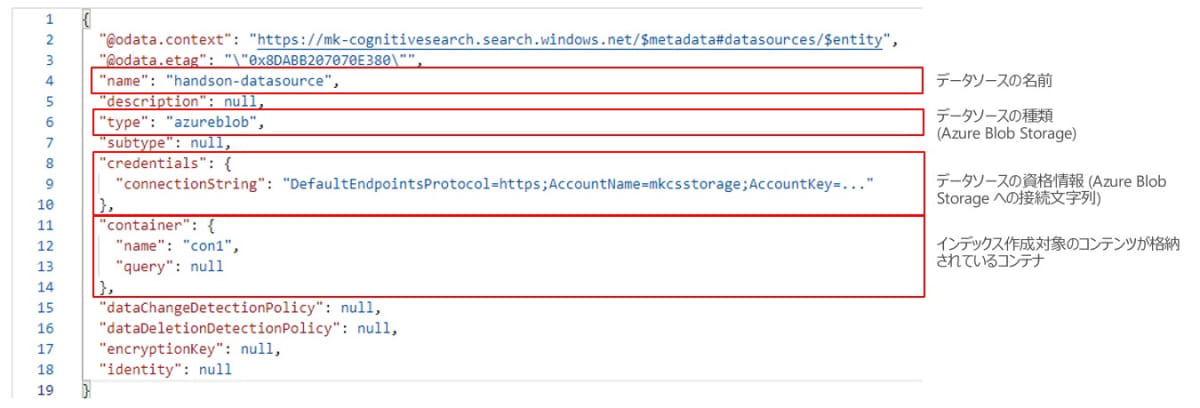
データソースでは、インデックスを作成するコンテンツが格納されているソースを定義します。下図は、Azure Blob Storage をデータソースとしたときの定義例になります。
スキルセット
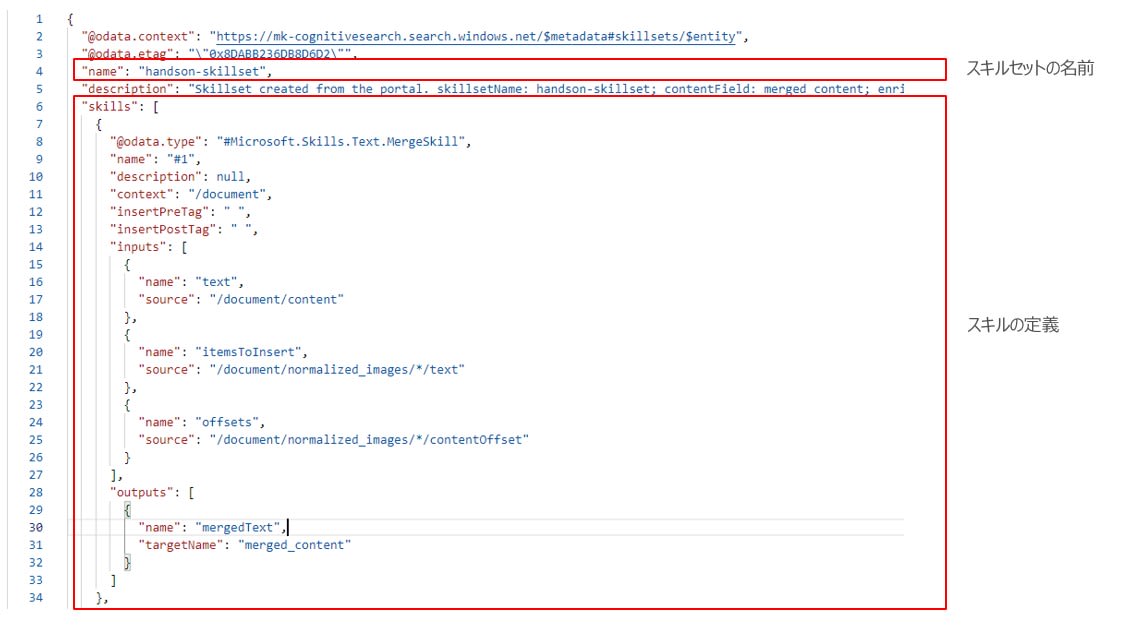
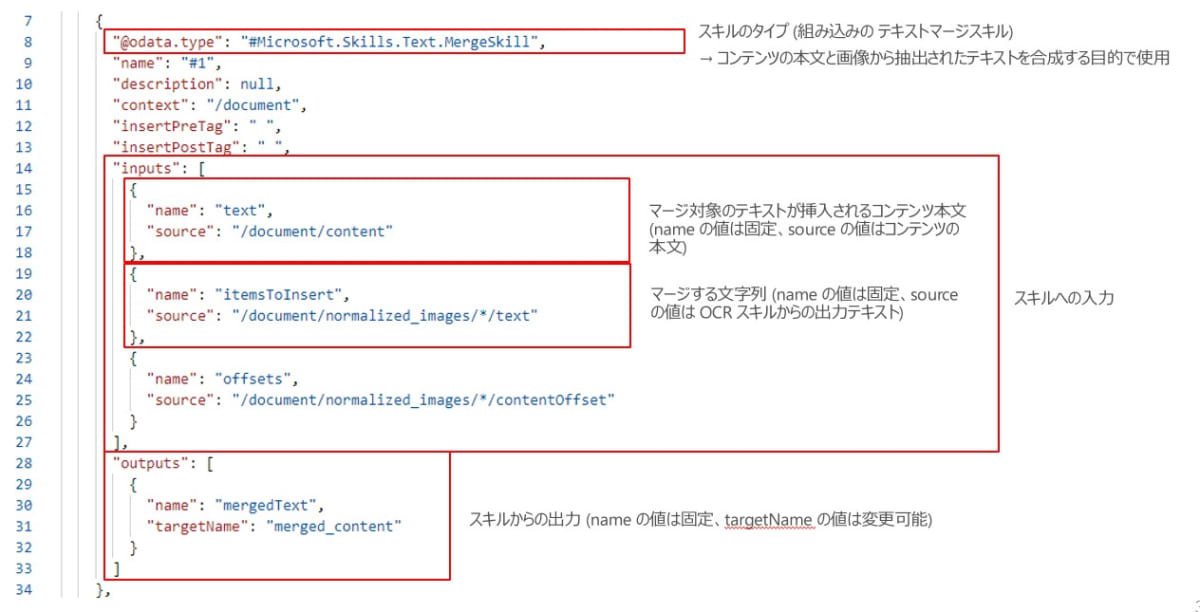
スキルセットでは、組み込みのスキルもしくはカスタムスキルを定義します。下図は、スキルセットの定義全体及び、OCR スキルの定義、テキストマージのスキルの定義例になります。
スキルセット定義の全体
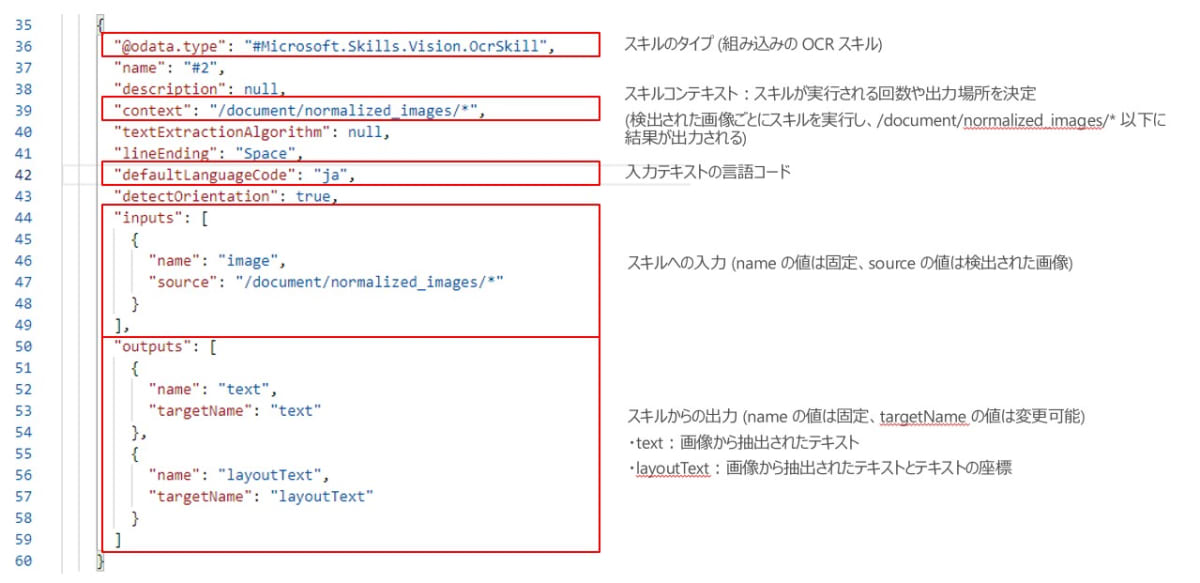
OCR スキルの定義
テキストマージスキルの定義
インデックス
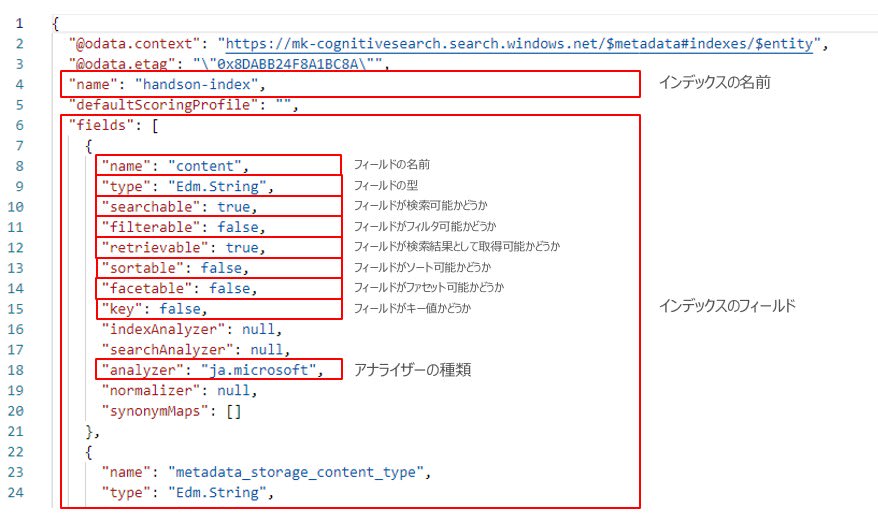
インデックスでは、インデックスのフィールドとその属性を定義します。下図は
- 文字型
- 検索可能
- フィルタ不可
- 検索結果として取得可能
- ソート不可
- ファセット不可
- キー値ではない
- アナライザは日本語マイクロソフトアナライザ
という属性のフィールドを持つインデックスの定義例になります。
インデクサー
インデクサーでは
- データソースから取得されたコンテンツやメタデータとインデックスのフィールドのマッピング
- スキルからの出力とインデックスのフィールドのマッピング
を行います。
下図は以下のマッピングを行ったインデクサーの定義例になります。定義内のプロパティ値を上述した定義内容と見比べてみると、関連がわかると思います。
- データソースから取得された
metadata_storage_pathメタデータを、Base64エンコードしたmetadata_storage_pathフィールドと、urlフィールドにマッピング - OCR スキルで画像から抽出されたテキストを、
textフィールドにマッピング - OCR スキルで画像から抽出されたテキストとテキストの座標を、
layoutTextフィールドにマッピング - テキストマージスキルで、ドキュメントの本文とOCR スキルで抽出されたテキストをマージしたテキストを、
merged_contentフィールドにマッピング

JSON 形式での定義は一見とっつきにくいように見えがちですが、構造をいったん理解してしまえばあとは自在に活用できるようになります。ここで記述した内容をもとに、様々な場面で Azure Cognitive Search をご利用いただければと思います。
Discussion