HTTPの転送効率を上げる技術について
HTTPの転送効率を上げる技術についてのメモ書きです。まずは前提の仕組みを確認してから(1)TCPコネクション、(2)データの分割/圧縮 と2つに分けて書いていきます。
HTTPの仕組み(前提)
リクエストレスポンス
まずはWebで情報をやり取りする仕組みからです。クライアントから「Webページを見せて〜」というリクエストに対し、サーバは「Webページどうぞ!」とHTMLを返却します。リクエスト/レスポンスの連続によってWebサービスは成り立っています。

1リクエスト1リソース
HTTPは一度のリクエストで1つのリソースしか取得できません。これはHTTPがたくさんの情報を処理することを目的として作られているからです。Webは世界中の人が利用するサービスであり、毎秒何万回ものリクエストが行わあれています。それら全てに対話型のような通信を行なっていては、サーバの処理が持ちません。そこで1リクエスト1リソースとし、出来るだけシンプルな実装を目指して作られたプロトコルとなっています。
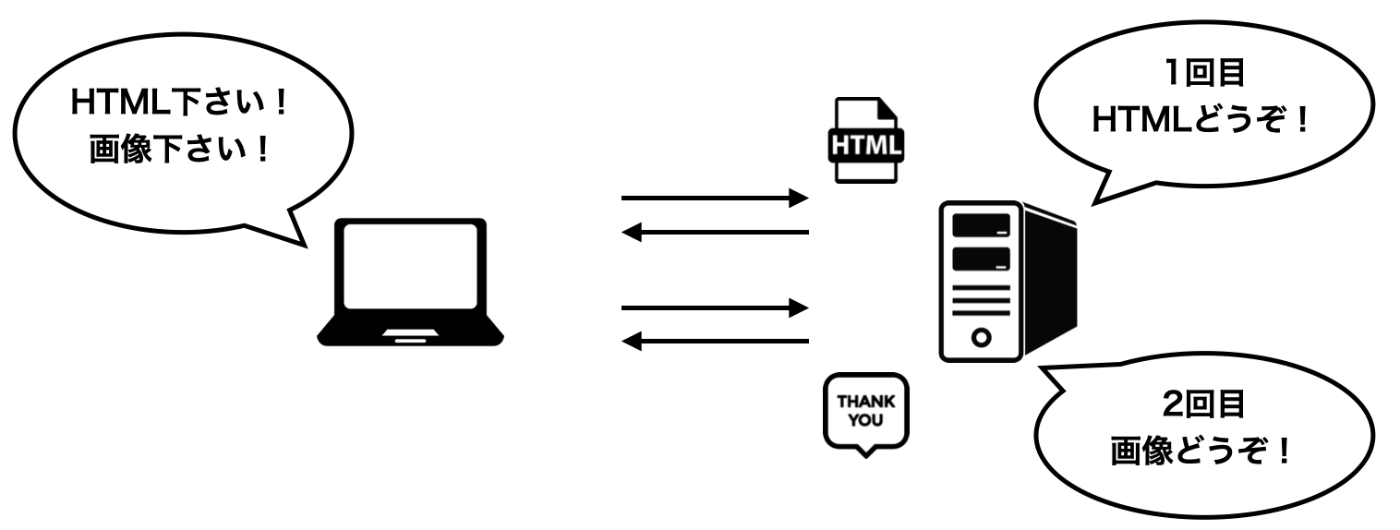
例えば画像を1枚含むWebページの場合、(1)HTML,(2)画像 と2回リクエストが行われることになります。
TCPコネクション
リクエストレスポンスが行われる前に、クライアントサーバの間でTCPコネクションが確立されます。実際にデータのやり取りをする前に、お互いが通信可能かどうか?を確認することになります。コネクションの確立は3回のメッセージのやり取りで行なわれます。これを「スリーウェイハンドシェイク」または「スリーメッセージハンドシェイク」と呼びます。
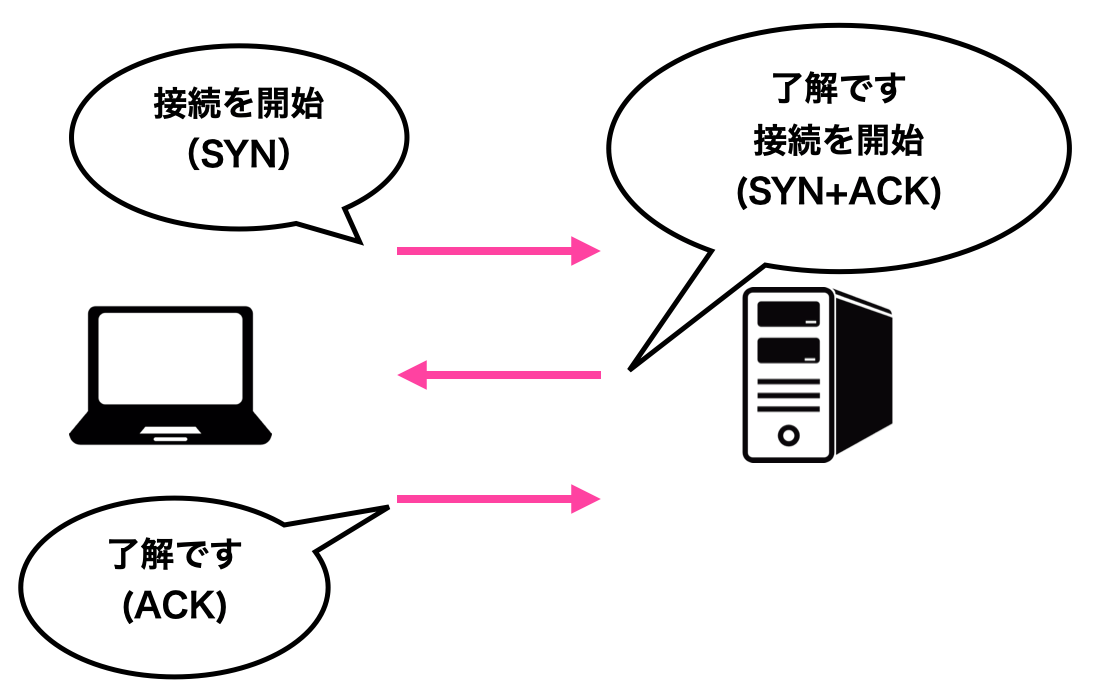
1回目:SYNパケット(受信できるか?を問合せ)
2回目:SYN+ACNパケット(受信できることを返答し、相手も可能かどうかを確認)
3回目:ACKパケット(受信できることを返答)
HTTP1.0までのリクエストレスポンス
HTTP1.0ではリクエストレスポンスの度に、TCPコネクションの接続切断が行われていました。クライアントがTCPコネクションを確立してリクエストを送信し、サーバがそれにレスポンスを返すとTCPコネクションは切断されています。TCPコネクションはWebサーバやネットワークに大きな負担がかかる処理でもあります。
HTTPが普及した当初は接続切断を繰り返しても問題ありませんでした。画像がたくさんあるページであったり、外部CSSファイルにたくさんリンクがあるページなどはあまりなかったからです。
しかし時代が進むにつれホームページにコンテンツがたくさん使われることになりました。1ページを表示させるために100個以上のリソースをダウンロードすることも珍しくありません。それだけTCPコネクションの接続/切断を繰り返していると、Webサーバやネットワークに大きな負担がかかります。
HTTP/1.1〜新しく導入
そこで転送効率を上げるためにHTTP1.1以降、様々な仕組みが導入されてきました。この記事では(1)TCPコネクション,(2)データの分割/圧縮という点から代表的な技術をいくつかご紹介します。
(1)TCPコネクション
持続的接続
TCPコネクションを継続して利用できる機能です。HTTPキープアライブ(HTTP Keep-Alive)とも呼ばれます。1つのTCPコネクションを使い回して、1回目に使用したものを2回目以降も再利用します。以下はHTTPリクエストのパケットをキャプチャしたサンプルです。
GET https://masahirotoba.com/web/text/text.html HTTP/1.1
Host: masahirotoba.com
Connection: keep-alive
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="101", "Google Chrome";v="101"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: https://masahirotoba.com/
Accept-Encoding: gzip, deflate, br
Accept-Language: ja
ヘッダ中でConnection: Keep-Aliveと宣言することでTCPコネクションが維持され続けるようになり、その後のやり取りも継続して行うことができます。HTTP/1.1以降からは特に指定がなければコネクションが継続され、ヘッダ中でConnection: Closeを宣言すると切断されます。
HTTPパイプライン
レスポンスを待たずに続けてリクエストを送信できる仕組みです。リクエストを1つ送信しそれに対するレスポンスを受け取るまでは、次のリクエストを送信することができません。しかしHTTPパイプラインはレスポンスを待つことなく複数のリクエストを送信することができます。
(2)データの分割/圧縮
やり取りするデータ自体を加工することで、通信の効率を改善することもできます。
圧縮転送
圧縮転送とはコンテンツを圧縮してサイズを小さくしてから転送する仕組みです。ネットワークにかかる負担を抑え大量のデータ転送を可能にします。サーバーやクライアントの処理能力が低い場合は圧縮や展開が大きな負担となりますが、現在では性能が格段に向上したためそれほど負担をかけずに実行できるようになりました。コンテンツを圧縮転送するにはクライアントからサーバーへのリクエスト時に accept encoding ヘッダでクライアントが対応する圧縮方式をサーバーに通知しますそれに対するレスポンスとしてコンテンツ encoding ヘッダで実際に使用した圧縮方式が記述され無理には圧縮されたデータが埋め込まれますレスポンスを受け取ったクライアントかボディを解凍しリソースを取り出します19日のような元から圧縮されたコンテンツでは効果が薄いもののテキストデータのような圧縮効果が高いファイルには有効な手段です
分割転送
大きなサイズのデータを分割してから転送する仕組みです。クライアントはデータの転送完了を待たずに、受信したデータから順番に処理できます。大きなサイズの画像データで分割転送を用いれば、全データの受信完了を待たずに受信データから順番に画面に表示できるようになります。
もし分割転送できなければ全てのデータのダウンロードが完了するまでブラウザで表示できません。しかし分割転送であれば分割で受け取るたびにブラウザでの表示を更新できます。ユーザーのストレスを低減できるとともに、サーバーの負担も軽くできます。また全てのデータが用意されていない場合も既にある部分から転送できるためファイル全体の生成が完了するまでバッファに貯めておくことなどが必要なくなります。
CPUの高性能化、メモリの大容量化によって実現
Web上で情報をやり取りする際、クライアントはリクエストを送るだけですが、サーバはHTMLファイルなどのコンテンツを作成して返却する必要があります。見る側のクライアントよりも提供する側のサーバの方が仕事量は多くなります。上記でご紹介した技術はサーバでどれもデータを加工する技術です。そのため結果的にはサーバの処理負担増につながります。しかし最近ではCPUの高性能化やメモリーの大容量化などが進んだことによって以前と比べると負担は軽くなっています
Discussion