Supabase CLIでローカルデータベースを触る
2025年5月31日追記:
supabase db diff -f 【任意の文字列】
このスクラップを書いた当時は --use-migra が無いと安定しない印象(Supabase触りたてでごちゃごちゃ触ってた影響もあるかも...。)でしたが、現在は上記のように無しで十分かと思います。実際に最近は --use-migra を全く使っていません。
このコマンドでマイグレーションファイルを作っておくと、Github Actions 等の CI/CD でのデプロイが可能なります。デプロイ時にマイグレーションを実行するとテーブル構造が反映されます。
※ここで言うデプロイとは、Next.js等のフロントエンドではなく、Supabaseにテーブル構造の反映や Edge Functions を本番環境およびステージング環境に公開することを指します。
ついでにGithub Actionsでデプロイする例を書いておきます
name: ステージング環境(staging)へデプロイ
on:
push:
branches:
- staging
jobs:
deploy-to-staging:
name: ステージングへリリースを実行
runs-on: ubuntu-latest
environment: STAGING
env:
SUPABASE_ACCESS_TOKEN: ${{ secrets.SUPABASE_ACCESS_TOKEN }}
SUPABASE_DB_PASSWORD: ${{ secrets.SUPABASE_DB_PASSWORD }}
PROJECT_ID: 【ここにSupabaseのプロジェクトID】
steps:
- name: checkout
uses: actions/checkout@v4
- name: Supabase CLIを準備しています
uses: supabase/setup-cli@v1
with:
version: latest
- name: npmパッケージをインストール中
run: npm install
- name: デプロイを開始する準備をしています。(env / config.tomlの動的作成)
run: npm run env:staging
env:
MY_SUPABASE_URL: ${{ vars.MY_SUPABASE_URL }}
MY_SUPABASE_SERVICE_ROLE_KEY: ${{ secrets.MY_SUPABASE_SERVICE_ROLE_KEY }}
- name: ステージング環境に接続しています
run: supabase link --project-ref $PROJECT_ID
- name: データベース情報をpush反映しています
run: npm run deploy:migrate:staging
- name: 環境変数を Supabase Secrets にデプロイしています
run: supabase secrets set --env-file ./.env
- name: Supabase Edge Fucntionsをデプロイしています
run: npm run deploy:functions:staging
ちなみに、Edge Functions に環境変数の適用方法が分からなかったので力技で解決しています。 npm run env:staging( ts-node deployment/generate-env-file.ts ) というコマンドを叩いて、.envファイルを動的に吐き出す処理を入れています。
import "dotenv/config";
import fs from "node:fs/promises";
import path from "node:path";
import process from "node:process";
const envData = {
MY_SUPABASE_URL: process.env.MY_SUPABASE_URL,
MY_SUPABASE_SERVICE_ROLE_KEY: process.env.MY_SUPABASE_SERVICE_ROLE_KEY
};
(async () => {
const outputFilePath = path.resolve(`./.env`);
const lines = Object.entries(envData).map(([key, value]) => `${key}=${value}`);
const content = lines.join("\n");
await fs.writeFile(outputFilePath, content, "utf-8");
})();
マイグレーションファイルを作成する
supabase db diff --use-migra -f 【任意の文字列】
これを実行すると、既に持っているマイグレーションファイルと現在のDB状況の差分を元にマイグレーションファイルを生成してくれる。
マイグレーションファイルとは、テーブル構造を持つだけで、レコード自体は持たない。あくまで構造だけをチーム間で共有できる状態になるということ。テーブルの構造の変更履歴をファイル化してくれているようなイメージ。開発が進むとファイル数が増えてしまうのはデフォらしいので気にする必要は無い模様。
実践
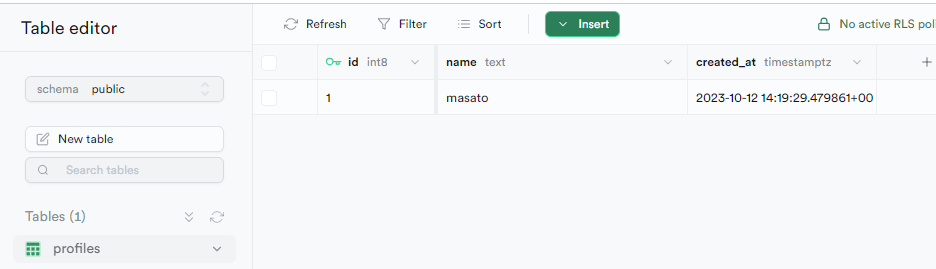
こんな感じのテーブルを作成し、 supabase db diff --use-migra -f public_schema を実行する。
supabase/migrationsディレクトリ内に下記のマイグレーションファイルが生成された。
create table "public"."profiles" (
"id" bigint generated by default as identity not null,
"name" text,
"created_at" timestamp with time zone not null default now()
);
alter table "public"."profiles" enable row level security;
CREATE UNIQUE INDEX profiles_pkey ON public.profiles USING btree (id);
alter table "public"."profiles" add constraint "profiles_pkey" PRIMARY KEY using index "profiles_pkey";
次に、先程作ったテーブルに description というカラムを追加してみることにする。
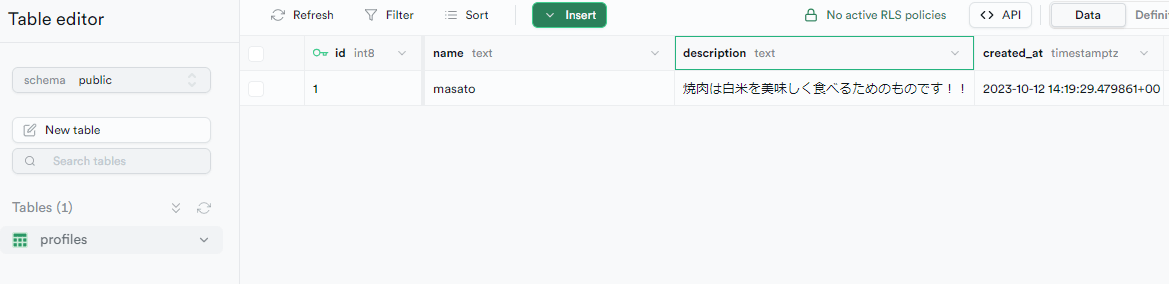
そして、同様に supabase db diff --use-migra -f public_schema を実行する。
alter table "public"."profiles" add column "description" text;
また新しくマイグレーションファイルが生成されるが、今度は記述が短い。
descriptionカラムが追加されたことを検出し、その差分を出力してくれている。
マイグレーションファイルを1つにまとめる
上記のようにマイグレーションをしまくると、ファイルがかなり増えてしまう。
それぞれのタイミングの作業履歴が分かってとても良いが、1つにまとめたくなるだろう。
そんなとき用のコマンドも用意されている。
supabase migration squash --local
Windows11環境では上記のコマンドが動かなかった。下記にしたらなぜか動いた
supabase migration squash --local -p postgres --debug
--debugを付けたら動いたんご...。
これでローカルのマイグレーションファイルをまとめてくれる。
ただし、天才AIのBardさん曰くマイグレーションファイルをまとめるのはあまりオススメしないとのことでした。

Claudeさん的には一人で開発しているのであれば実行してもいいよ、とのことでした。
データベースの中身を削除してテーブル構造だけ復元する
ゴミのレコードが溜まってしまい邪魔になったら下記を実行すると良い。
supabase db reset
実行することで、データベースのデータを削除し、マイグレーションファイルを元にテーブルを再構築してくれる。余計なデータが消えてくれるので、やり直しがしやすい。
実践
supabase db reset を実行すると、データベースを削除した後、マイグレーションファイルを元にテーブル構造を復元してくれる。
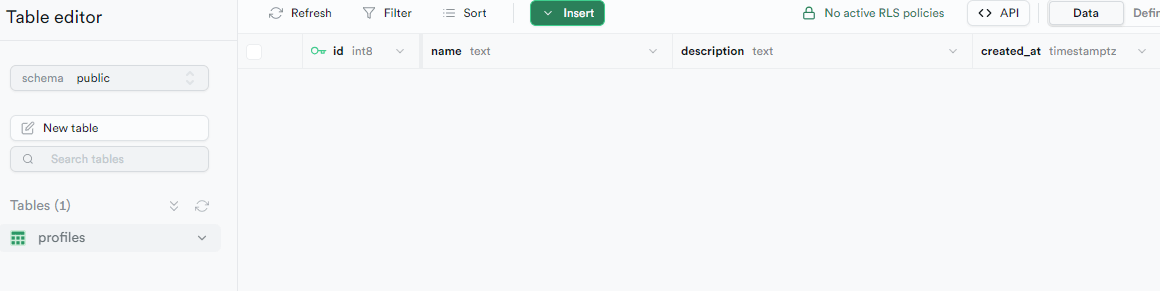
このようにテーブル構造だけが保持され、レコードは削除されている。
レコードをSQLファイルとして保存する
ローカル環境でデータを構築していて、後から作業を再開したいときには、
念のためSQLファイルとして保存しておいた方が安心感がある。
supabase db dump --local --data-only -f seed.sql
seed.sql という名前にしたが、これは何でも良い。
ダンプしたデータを supabase db reset のタイミングで自動で復元するために seed.sql という名前にしている。
dump したデータを supabase db reset のタイミングで復元するには?
supabase db reset ではテーブル構造だけが復元された。
レコード内容も一緒に復元する方法も用意されている。
supabase/seed.sql というファイルがあるが、これが復元の際にDBに対して実行されるSQLファイル。つまり、ここに INSERT 文などを用意してやれば、そのデータを勝手に入れてくれる。
そこで、上のdumpの例として seed.sql として出力したのだ。
既に存在するseed.sqlを上書きする形で移動させておき、 supabase db reset を実行すれば、マイグレーションファイルが実行された後、seed.sqlが実行され、テーブル構造+レコードが復元されるという仕組みだ。
Windows勢は supabase link --project-ref で躓くかも
Windows勢なのですが supabase link --project-refを実行する際にドキュメント通りに実行しても動いてくれない問題がありました。
この問題は下記の情報通りに行った結果、正常にリンクできました。
$env:SUPABASE_DB_PASSWORD="【ここにデータベースのパスワード】"; supabase link --project-ref 【ここにproject-ref】
Windows勢とSupabaseの相性がちょくちょく悪いですね...。
何かとバグりやすい
Supabase CLIは何かとバグりやすい印象です。
特にローカルでデータを溜め込んで何かをする場合、データのバックアップだけはしっかりとっておきましょう。確実な現象の再現ができませんが、パソコンを再起動するだけでもデータが消えてしまうことも過去にありました。また、Supabase CLIをアップグレードしただけで消えてしまうこともありました。
時間をかけて溜め込んだデータは本番DBに移しておくなどの対策が必要です。
消えてしまうという前提のもと取り扱うようにしましょう!
SupabaseのGUIからユーザーを作成しようとするとエラーが発生した
Supabaseの管理画面からユーザーを追加しようとすると、 Database error checking email というエラーが発生した。
ログを確認すると、 unable to find user email address for duplicates: error finding user: ERROR: column users.is_anonymous does not exist (SQLSTATE 42703) というメッセージがあった。このエラー文の通り、 auth.users テーブル内に is_anonymous カラムが存在しないということだったので、boolean型で default値 false として is_anonymous カラムを追加。
これで実行してみたところ無事に追加できた。
Supabaseはアップグレードに伴うちょっとした問題が発生しがちなのが辛いところだなぁ。(今回のケースは匿名認証の機能追加に伴う問題だったと思われる。)