Node.js + Playwrightでスクレイピングしつつ、Supabaseにデータを溜めていくには?
Node.js + Playwrightでのスクレイピングは定番ですが、
ここにSupabaseにデータを格納していくとなると、どこにも情報が書かれていないので試行錯誤しながらメモ書きしていきます。
この記事(スクラップ)では、 @supabase/supabase-js の createClient() を使ってやっていきます!
なお、この記事では
余計なものは削ぎ落としながら、単純化したものを書いています。
実際に使うときは .env ファイルを用意したり、効率的な書き方を意識しましょう。
あくまでチュートリアル的な立ち位置です。
分からないことがあれば、各セクションでコメントを残して貰えれば回答します!
まずはローカル環境でSupabaseが動くようにしておこう。
Supabase CLI を利用すれば、 supabase init した後に supabase start するだけで簡単にローカル環境を作れます。この辺りは公式ドキュメントや様々な記事が存在するので、そちらを参照して頂くとして、
https://localhost:54323 で Supabase Studio(Supabaseのダッシュボード) が開く状態になった前提で進めていきます。
今回使うディレクトリ
📁scraping/
├─ 📁app/
│ ├─ 📁main/
│ │ ├─ scraping-run.ts
│ ├─ package.json
├─ 📁supabase/
scraping-run.ts
スクレイピング周りの処理が書かれたファイルです。
ここでPlaywrightを実行したり、要素取得などを行っていきます。
scraping/supabase
Supabaseのローカルディレクトリです。
これは supabase init と supabase startで生成されたディレクトリです。
scraping-run.ts を実行するには?
npx ts-node scraping-run.ts
を叩いて実行します。 ts-node というものを経由して実行するので予め動かせるぐらいにはなっておきましょう。
Node.jsからSupabaseに接続できるように準備する
appディレクトリにて下記を実行して Supabase を使えるようにします。
npm i @supabase/supabase-js
scraping-run.ts から Supabase に接続できるように記述をしておきましょう。
import { createClient } from "@supabase/supabase-js";
const supabase = createClient(
"【①ここにSupabaseのURL】",
"【②ここにanon key】",
{
auth: {
persistSession: false,
autoRefreshToken: false,
},
}
);
上記に入れるのは、supabase start を実行した後に出てくる下記からの文字列を使います。

【①ここにSupabaseのURL】には、 API URL を、
【②ここにanon key】には、 anon key を入れてください。
これで準備は整いましたが、一応データベースに接続できるかだけでも確認しておきましょう!
Node.jsからSupabaseに接続できているかを確認する
前項で作った記述で、問題なくSupabaseに接続できているか確認します。
SupabaseのSQL Editor 上で下記を入力して実行してください。
create table "public"."hoges" (
"id" bigint generated by default as identity not null,
"contents" text not null default ''::text,
"created_at" timestamp with time zone not null default now()
);
alter table "public"."hoges" enable row level security;
CREATE UNIQUE INDEX hoges_pkey ON public.hoges USING btree (id);
alter table "public"."hoges" add constraint "hoges_pkey" PRIMARY KEY using index "hoges_pkey";
create policy "Enable read access for all users"
on "public"."hoges"
as permissive
for select
to public
using (true);
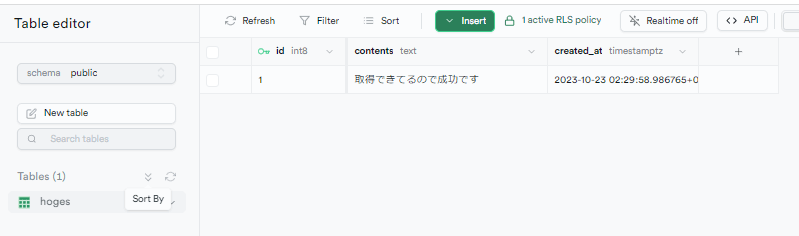
http://localhost:54323/project/default/editor にアクセスし、 hogesテーブルと1行だけレコードが入っているか確認しておきましょう。
このデータを取得できればSupabaseと接続できていると判断できますよね!
それではやっていきましょう。
scraping-run.ts のを下記に書き換えます。
追加したのは最後の4行だけです。
import { createClient } from "@supabase/supabase-js";
const supabase = createClient(
"【①ここにSupabaseのURL】",
"【②ここにanon key】",
{
auth: {
persistSession: false,
autoRefreshToken: false,
},
}
);
(async () => {
const { data, error } = await supabase.from("hoges").select(`*`);
console.log(data, error);
})();
では、実際にNode.js側で実行してみましょう。
npx ts-node scraping-run.ts

無事にデータが取得できているので成功です!
途中で書くの面倒くさくなっちゃったのでここで止めますが、
上記をやればDBへのINSERTはNode.jsからも可能であることが分かるかと思います。
あとはPlaywrightでスクレイピングした内容を上記の記述を参考にして
INSERTしてデータをためていけばOKです!