GPT-5対応!OpenAI APIクイックスタートガイド
GPT-5が発表されたので、今一度、APIの使い方を一通り確認しておきます。
APIの使い方はOpenAIのクイックスタートで公開されています。
そちらを順に確認していきます。
テキスト生成
まずは、簡単なテキスト生成を行います。
(以下、.envファイルに環境設定を行っている前提のコードになっています)
import os
from dotenv import load_dotenv
from openai import OpenAI
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
response = client.responses.create(
model="gpt-5",
input="未来の自分から今の自分へ向けた励ましの一言を書いてください。"
)
print(response.output_text)
これまで通り、OpenAIクライアントを生成し、responses.createメソッドで日本語のプロンプトに基づくテキスト生成をリクエストします。
結果はresponse.output_textから取得・表示できます。
結果は以下の通り

画像とファイルの分析
マルチモーダルなAIアプリを作成する際に、必要となります。
4oモデルから利用できるようになっていましたが、GPT-5でも同じように利用可能です。
画像URLによる分析
import os
from dotenv import load_dotenv
from openai import OpenAI
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
# OpenAIクライアントを初期化
client = OpenAI(api_key=api_key)
response = client.responses.create(
model="gpt-5",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "この画像には何が映っていますか?",
},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/1/15/Red_Apple.jpg"
}
]
}
]
)
print(response.output_text)
マルチモーダル入力のリクエストとして、"type": "input_text"にユーザプロンプトを、"type": "input_image"に画像のURLリンクを送ることで、画像と質問を同時に送ることができます。
結果は以下の通り

ファイルURLによる分析
import os
from dotenv import load_dotenv
from openai import OpenAI
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
# OpenAIクライアントを初期化
client = OpenAI(api_key=api_key)
response = client.responses.create(
model="gpt-5",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "手紙を分析し、重要なポイントを要約してください。",
},
{
"type": "input_file",
"file_url": "https://www.berkshirehathaway.com/letters/2024ltr.pdf",
},
],
},
]
)
print(response.output_text)
ファイルの場合も画像と同じです。
"type": "input_text"にユーザプロンプトを、"type": "input_file"にファイルのURLリンクを送ることで、ファイルと質問を同時に送ることができます。
結果は以下の通り(要約文が長くなったので途中まで)
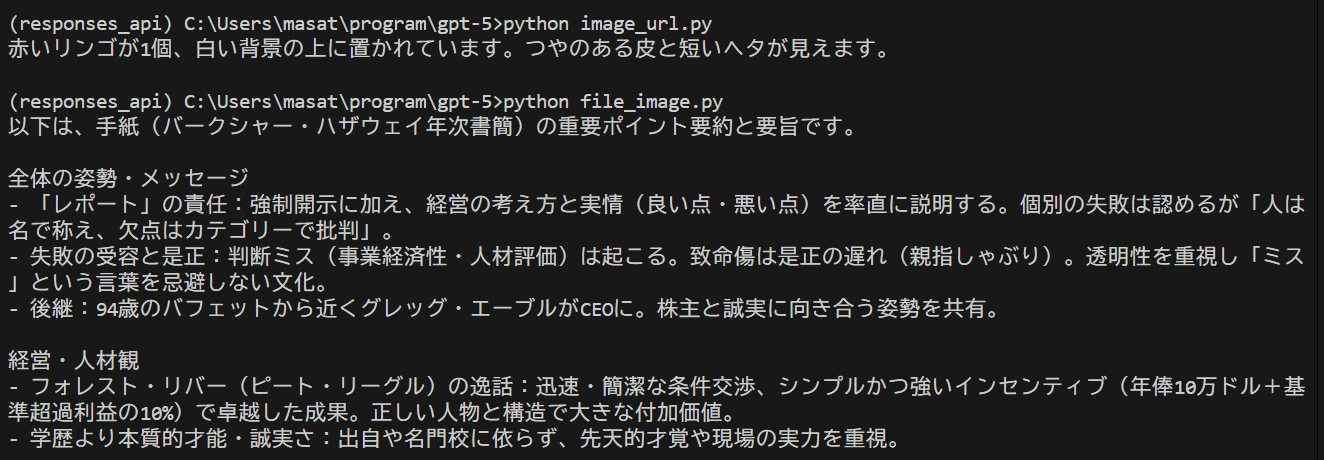
ファイルアップロードによる分析
import os
from dotenv import load_dotenv
from openai import OpenAI
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
# OpenAIクライアントを初期化
client = OpenAI(api_key=api_key)
file = client.files.create(
file=open("sample_doc.pdf", "rb"),
purpose="user_data"
)
response = client.responses.create(
model="gpt-5",
input=[
{
"role": "user",
"content": [
{
"type": "input_file",
"file_id": file.id,
},
{
"type": "input_text",
"text": "このファイルには何が書かれていますか?",
},
]
}
]
)
print(response.output_text)
まず、ローカルにあるファイルを、OpenAIのストレージにあげます。
"type": "input_text"にユーザプロンプトを、"type": "input_file"にストレージにあげたfileのfile.idを送ることで、ファイルと質問を同時に送ることができます。
今回使用したサンプルファイルは、以下のような勤怠管理規定(サンプル) 。

結果は以下の通り(要約文が長くなったので途中まで)

ツールによるモデルの拡張
AIにツール機能を持たせて、外部データや関数を利用できるようにします。
Web検索
import os
from dotenv import load_dotenv
from openai import OpenAI
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI()
response = client.responses.create(
model="gpt-5",
tools=[{"type": "web_search_preview"}],
input="本日の日時と、大阪の天気/気温を教えてください。"
)
print(response.output_text)
toolsに、使用するツールを追加します。
今回は、tools=[{"type": "web_search_preview"}] により、モデルが外部のWeb検索を利用できるようになります。
inputにユーザの質問を入力し、回答を生成します。
結果は以下の通り

ファイル検索
import os
from dotenv import load_dotenv
from openai import OpenAI
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
# OpenAIクライアントを初期化
client = OpenAI(api_key=api_key)
response = client.responses.create(
model="gpt-5",
input="勤怠管理規定に記載されていることは何ですか?",
tools=[{
"type": "file_search",
"vector_store_ids": ["<vector_store_id>"]
}]
)
print(response.output_text)
ファイル検索については、OpenAIのファイル検索機能(File Search Tool)を使って、アップロード済みの文書群から質問に回答します。
そのため、事前にOpenAIのダッシュボード上で、ベクトルストア(vector store)を作成しておく必要があります。
type: "file_search"` で、アップロード済みファイルや事前に作成したベクトルストア(vector store)を検索対象にする指定します。
そして、vector_store_idsに、検索対象となるベクトルストアのIDを指定します。
ファイル検索機能を用いることで、簡易的なRAGシステムを簡単に構築できます。
結果は以下の通り

関数呼び出し
import os
from dotenv import load_dotenv
from openai import OpenAI
import json
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
# OpenAIクライアントを初期化
client = OpenAI(api_key=api_key)
# ツール(関数定義)
tools = [
{
"type": "function",
"name": "get_weather", # 関数名
"description": "指定された地域の現在の天気を取得します。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "都市名と国名(例: 東京, 日本)",
}
},
"required": ["location"], # locationは必須
"additionalProperties": False,
},
"strict": True,
},
]
# 応答を生成
response = client.responses.create(
model="gpt-5",
input=[
{"role": "user", "content": "今日の東京の天気はどうですか?"},
],
tools=tools,
)
# レスポンス全体を確認
print(json.dumps(response.model_dump(), indent=2, ensure_ascii=False))
関数呼び出しについては、toolsで関数を定義することで、カスタム関数を用いた回答を生成を行うことができるようになります。
type: "function"で、モデルが呼び出せる関数を定義します。
name: "get_weather" で関数名を定義します。
descriptionにて 関数の説明を記載します。この記載内容が、モデルがどの関数を選ぶか判断する材料になります。
parameters:には、関数が受け取る引数をjson形式で記載ます。
今回の場合だと、locationが引数になり、都市名, 国名が入ることになります。
client.responses.createにて、ユーザー質問と関数定義を渡すことで、モデルが「この質問には get_weather 関数を使うべき」と判断すると、関数呼び出し用の出力を生成します。
結果は以下の通り
{
"id": "resp_68997312726c8199910eb7c932d24e270ded49061904f478",
"created_at": 1754886930.0,
"error": null,
"incomplete_details": null,
"instructions": null,
"metadata": {},
"model": "gpt-5-2025-08-07",
"object": "response",
"output": [
{
"id": "rs_68997312c8d481999fa940f00a67ec970ded49061904f478",
"summary": [],
"type": "reasoning",
"status": null
},
{
"id": "fc_689973146db48199995463ddabedb6eb0ded49061904f478",
"arguments": "{\"location\":\"東京, 日本\"}",
"call_id": "call_sY2NJ7AadpNhjMWCFszeqRzO",
"name": "get_weather",
"type": "function_call",
"status": "completed"
}
],
"parallel_tool_calls": true,
"temperature": 1.0,
"tool_choice": "auto",
"tools": [
{
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "都市名と国名(例: 東京, 日本)"
}
},
"required": [
"location"
],
"additionalProperties": false
},
"strict": true,
"type": "function",
"description": "指定された地域の現在の天気を取得します。"
}
],
"top_p": 1.0,
"max_output_tokens": null,
"previous_response_id": null,
"reasoning": {
"effort": "medium",
"generate_summary": null,
"summary": null
},
"status": "completed",
"text": {
"format": {
"type": "text"
},
"verbosity": "medium"
},
"truncation": "disabled",
"usage": {
"input_tokens": 74,
"output_tokens": 150,
"output_tokens_details": {
"reasoning_tokens": 128
},
"total_tokens": 224,
"input_tokens_details": {
"cached_tokens": 0
}
},
"user": null,
"background": false,
"max_tool_calls": null,
"prompt_cache_key": null,
"safety_identifier": null,
"service_tier": "auto",
"store": true,
"top_logprobs": 0
},
"user": null,
"background": false,
"max_tool_calls": null,
"prompt_cache_key": null,
"safety_identifier": null,
"service_tier": "auto",
"store": true,
"top_logprobs": 0
"prompt_cache_key": null,
"safety_identifier": null,
"service_tier": "auto",
"store": true,
"top_logprobs": 0
"service_tier": "auto",
"store": true,
"top_logprobs": 0
"top_logprobs": 0
}
リモートMCP
import os
from dotenv import load_dotenv
from openai import OpenAI
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
# OpenAIクライアントを初期化
client = OpenAI(api_key=api_key)
resp = client.responses.create(
model="gpt-5",
tools=[
{
"type": "mcp",
"server_label": "deepwiki",
"server_url": "https://mcp.deepwiki.com/mcp",
"require_approval": "never",
},
],
input="MCP 仕様の 2025-03-26 バージョンではどのようなトランスポート プロトコルがサポートされていますか?",
)
print(resp.output_text)
リモートMCP(Model Context Protocol)サーバーに接続し、その情報を使って質問を回答させます。
toolsのtype:"mcp"とすることで、モデルがMCPサーバーにアクセスできるようになります。
server_urlに接続先のMCPサーバーのURLを追加し、require_approvalでアクセス許可確認の有無を設定します。
上記コードを書くことで、MCPにも対応したシステムの構築ができます。
結果は以下の通り

AIエージェントの構築
最後に、OpenAIのエージェントSDKとLLM:GPT-5を用いたAIエージェントの作成を確認します。
import asyncio
import os
from dotenv import load_dotenv
from agents import Agent, Runner
# .env ファイルから API キーを読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
# 日本語→英語 翻訳エージェント
translator_agent = Agent(
name="English Translation Agent",
instructions=(
"あなたは高度な英訳者です。入力は日本語のみが与えられます。"
"自然で正確な英語に翻訳してください。意訳は最小限に、固有名詞は保持。"
"出力は英語のみ。余計な説明は書かない。"
),
model="gpt-5",
)
# 文章要約エージェント(日本語テキストを日本語で要約)
summarizer_agent = Agent(
name="Summarization Agent",
instructions=(
"あなたは優秀な要約者です。入力は日本語テキストです。"
"重要なポイントを落とさずに、簡潔で読みやすい日本語で要約してください。"
"箇条書きが適切なら短い箇条書きにしてもよい。"
"出力は日本語のみ。"
),
model="gpt-5",
)
# トリアージエージェント(翻訳 or 要約 を判定してハンドオフ)
triage_agent = Agent(
name="Triage Agent",
instructions=(
"ユーザーの依頼が『翻訳』か『要約』かを判断し、適切なエージェントにハンドオフする。"
"ルール:\n"
"1) 『英訳』『英語にして』など翻訳意図→ English Translation Agent へ。\n"
"2) 『要約』『まとめて』など要約意図→ Summarization Agent へ。\n"
"3) 曖昧な場合:文章の長さと文脈を見て、要約が自然なら要約、翻訳要求が明確なら翻訳。\n"
"4) ハンドオフ後は最終回答のみを返す。メタな説明は出力しない。"
),
handoffs=[translator_agent, summarizer_agent],
model="gpt-5",
)
async def main():
# 例1:翻訳リクエスト
result1 = await Runner.run(
triage_agent,
input="次の文を英語に翻訳してください:本日の会議は15時開始に変更になりました。"
)
print("【翻訳結果】")
print(result1.final_output)
print()
# 例2:要約リクエスト
ja_text = (
"生成AIは、設計レビューやドキュメント作成の効率化、問い合わせ対応の自動化などで効果を発揮している。"
"一方で、情報漏洩や出力の妥当性確認といった課題もあるため、運用プロセスとガバナンスの整備が不可欠である。"
"まずは限定領域でPoCを行い、指標を設定しながら段階的に適用範囲を広げることが望ましい。"
)
result2 = await Runner.run(
triage_agent,
input=f"要約してください:{ja_text}"
)
print("【要約結果】")
print(result2.final_output)
if __name__ == "__main__":
asyncio.run(main())
AgentSDKを用いてマルチエージェント構成を作成しています。
Translator Agent:日本語→英語翻訳のエージェント
Summarizer Agent:日本語要約のエージェント
Triage Agent:入力が翻訳か要約かを判定し、指定のエージェントへhandoffしています。
これまで通り、model="gpt-5"と指定することで、LLMでgpt-5を使用することができます。
結果は以下の通り

まとめ
今回、GPT-5の発表を機に、OpenAIのクイックスタートで紹介されている主要なAPI機能を一通り確認しました。
当たり前ではありますが、どの機能もGPT-5に対応しており、modelを変更するだけで、LLMとしてGPT-5をすることができそうです。
引き続き、GPT-5を使用して、AIアプリ開発・技術調査を進めていこうと思います。
Discussion