Open8
influxdbやってみる
-
pubsub -> influxdbやってみる
-
送りつけるデータは例えば以下のようなものとする
{
"device": "device1",
"temperature": 10.5,
"humidity": 50.1
}
-
pubsub
- 適当にトピックとサブスクリプションを作っておく
-
influxdbは適当にGKE上に立てた
telegraf config > telegraf.conf
- 以下のような感じで編集する
- コメントアウトして編集
[[outputs.influxdb_v2]]
urls = ["http://127.0.0.1:8086"]
token = "自分のトークンをUIから取得して貼る"
organization = "作成したorganization名を貼る"
bucket = "データをいれたいバケット名を貼る"
- デフォルトで有効化されているinputプラグインを削除(大体以下のあたり)
[inputs.cpu]
...
[inputs.disk]
...
など
- cloudpubsubプラグインの有効化
[[inputs.cloud_pubsub]]
project = "pubsubのあるGCPプロジェクト名"
subscription = "サブスクリプション名"
credentials_file = "/opt/config.json" # default credentialが通らなかったのでsaのjson作って配置したけどやり方ありそうな気がする
data_format = "json"
json_name_key = "device" # measurementになるjsonのキーを書く。これを書かないとcloudpubsubみたいになるので注意
-
編集後に/etc/telegraf/telegraf.confへコピーしておく
-
service再起動
service telegraf restart
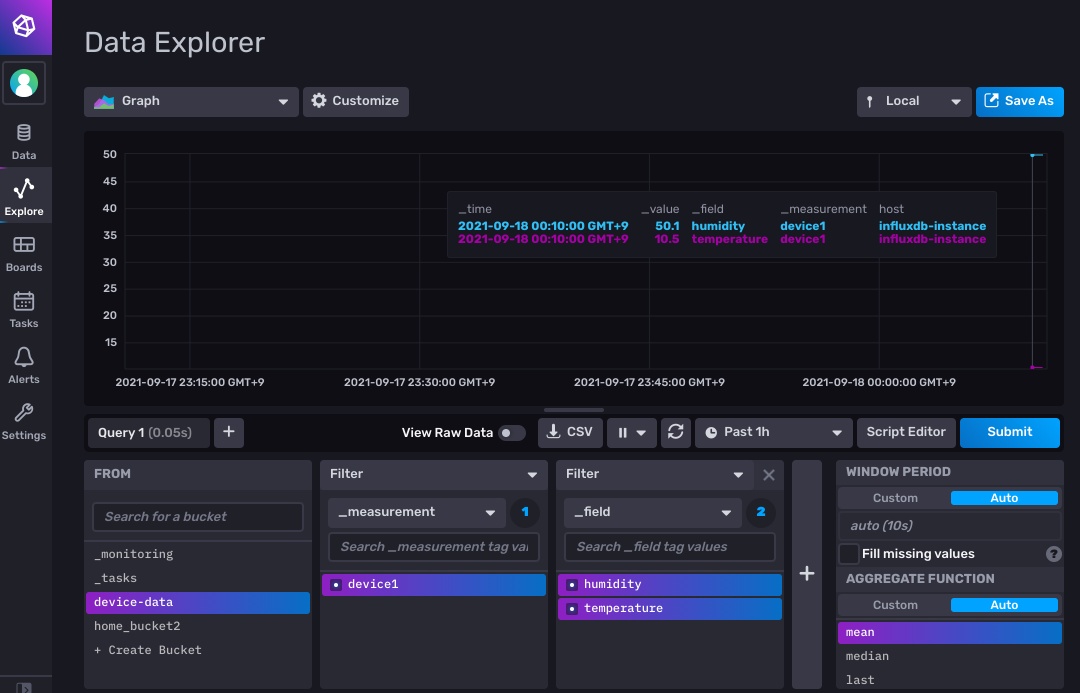
- 見るとそれっぽい感じで入ってる!
余談
GCEあまりつかったことなかったけど、gcloud周りがやっぱり便利だった
port-forward
gcloud compute ssh --zone asia-northeast1-b "influxdb-instance" -- -N -f -L 8086:localhost:8086
ssh接続
gcloud beta compute ssh --zone "asia-northeast1-b" "influxdb-instance"
- うちで飼っているメダカの水温計のロガーが壊れたままだったのでこっちに載せ替えてみる
-
こんな感じで取得結果を標準出力にjsonで吐き出すようなものを書く
- なお使っている製品はたぶんこれである。たぶんというのはだいぶ前にaliexpress経由で買ったので正確なところを覚えてない・・・
- そして、以下のような感じでコマンドを実行するとinflux dbまで取り込まれる
gcloud pubsub topics publish influx --message "$(python engbird.py --macaddr XX:XX:XX:XX:XX:XX)"
- ので、これをcronに仕込んでおく
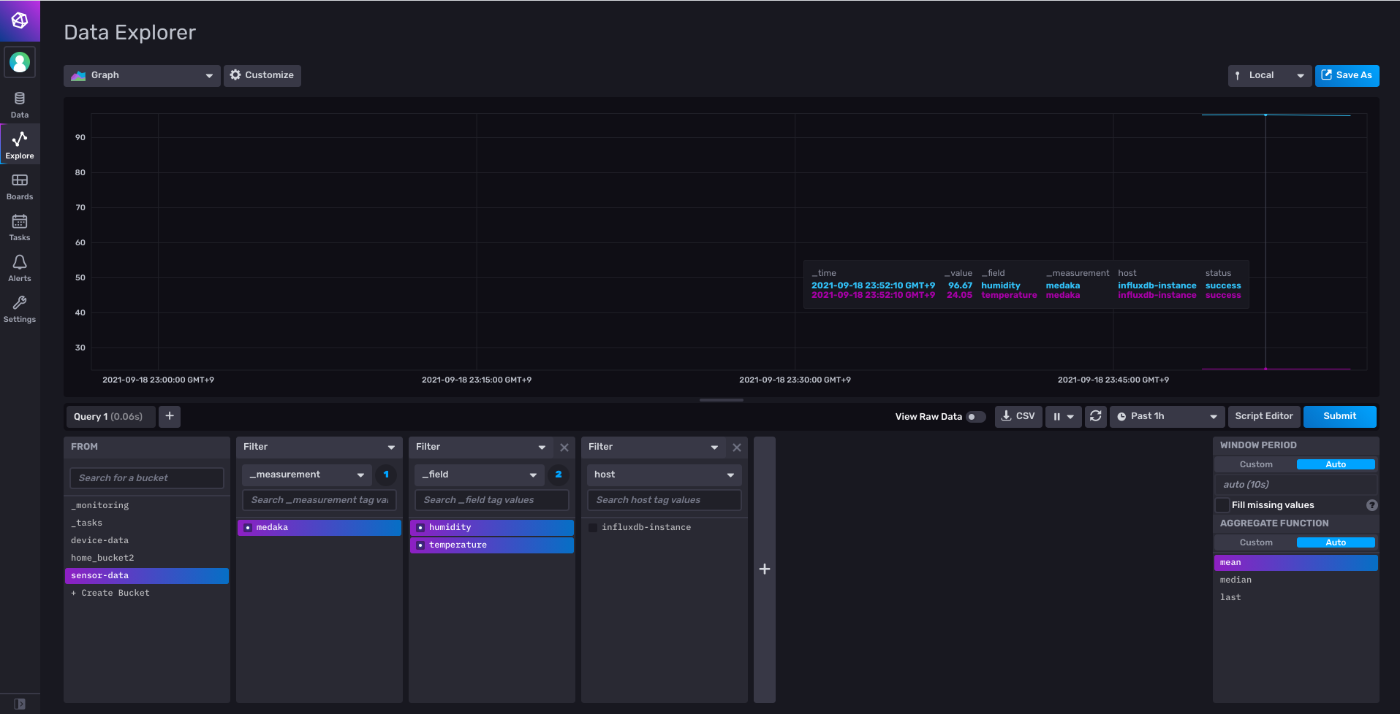
- 全く迫力がないのでしばらくしたらまた撮り直そう
アラートを仕込んで見る
-
対象のメトリックスを選んで
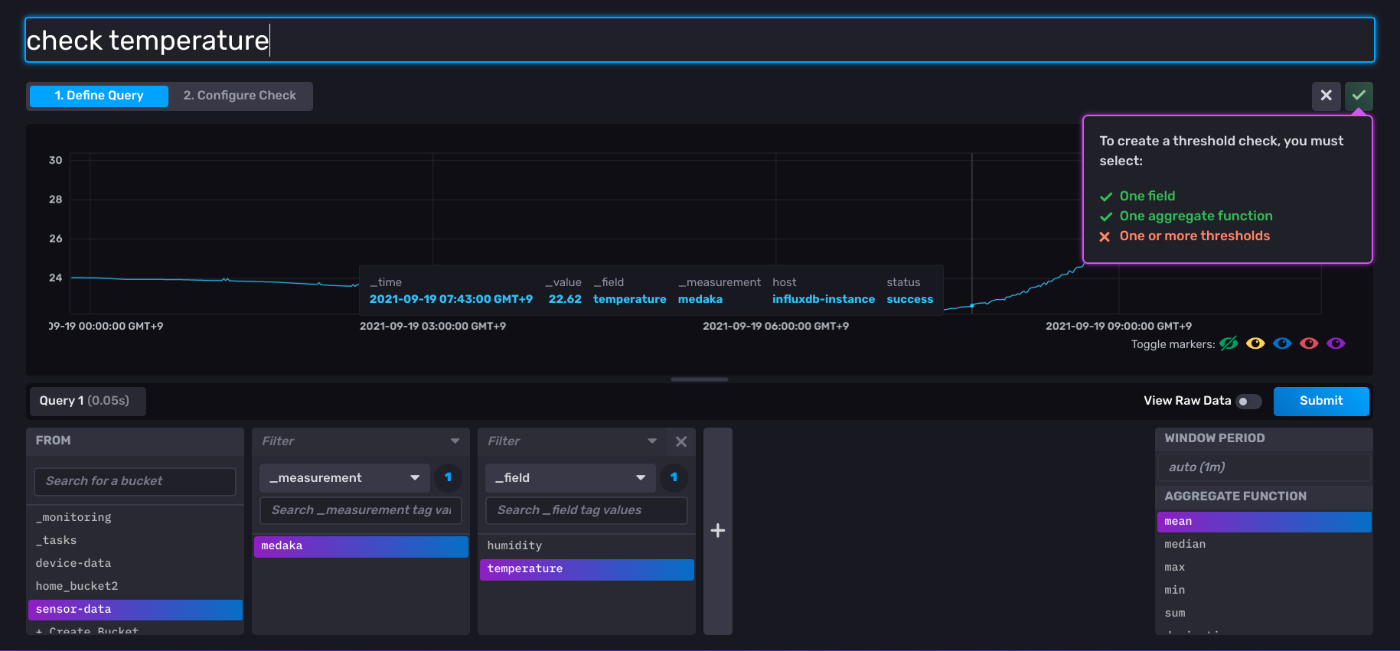
-
thresholdを指定(あと、特定ログが送られてきたとき、みたいなこともできるっぽ)
- とりあえず、32度でCRITICAL, 29度でWARNINGにした
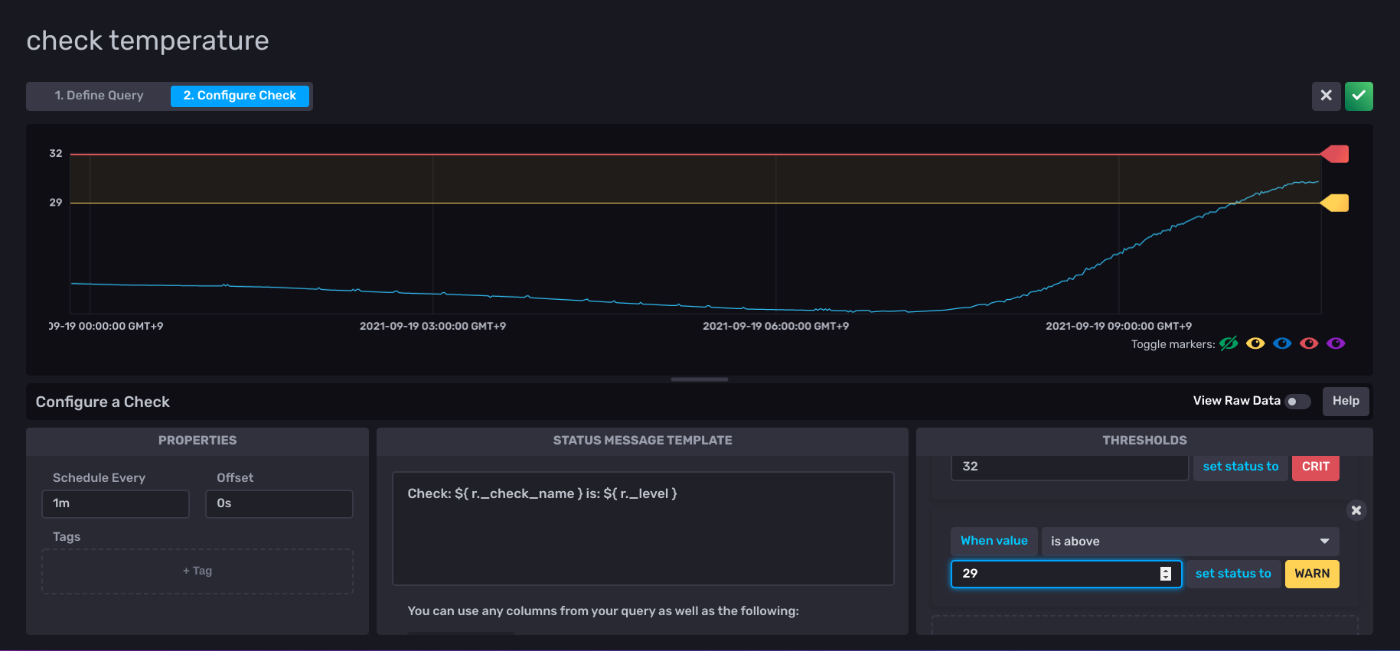
- とりあえず、32度でCRITICAL, 29度でWARNINGにした
-
機械学習モデル食わせるのってどうやるんだろう。さすがにできる気がする
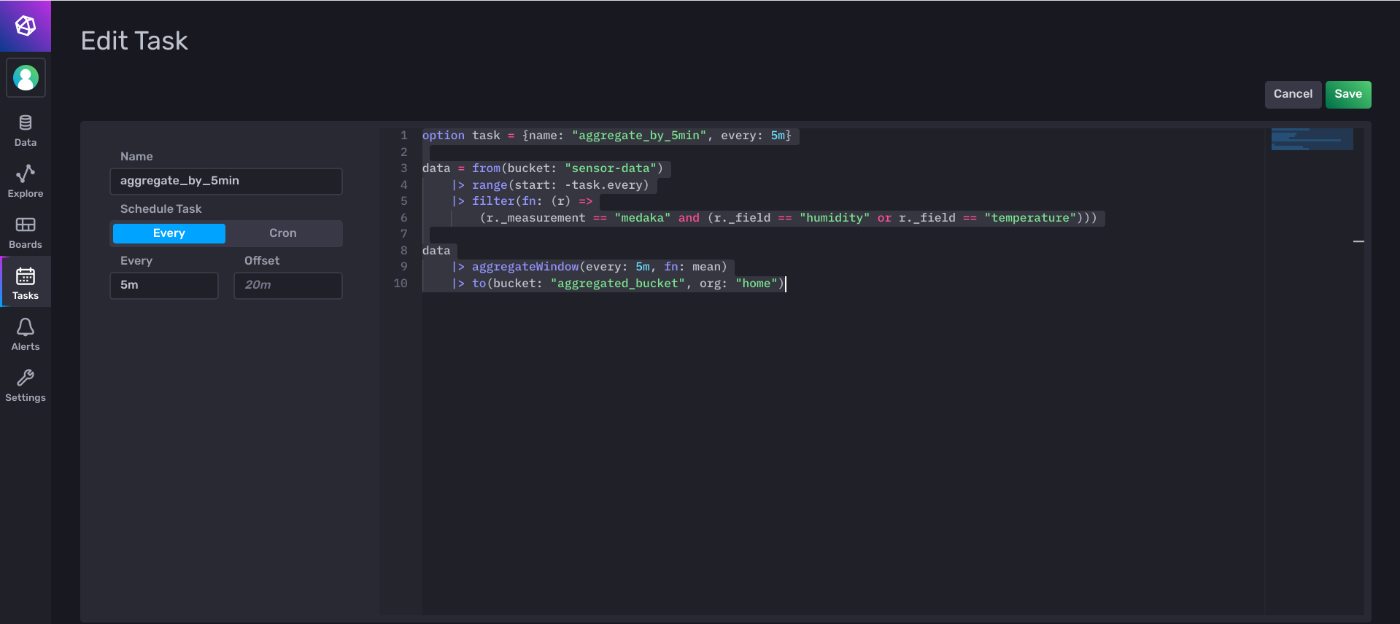
- 今のデータは1分間隔なので5分間隔の移動平均にする
option task = {
name: "aggregate_by_5min",
every: 6m,
}
data = from(bucket: "sensor-data")
|> range(start: -task.every)
|> filter(fn: (r) =>
r._measurement == "medaka"
and (
r._field == "humidity"
or r._field == "temperature"
)
)
data
|> aggregateWindow(
every: 5m,
fn: mean
)
|> to(bucket: "aggregated_bucket", org: "home")
- UIからだとこんな感じでいれられるけど、クエリのテストやりようないのかな?
-
これやっぱやめた
-
過去データを使ってモデルを学習させ、翌日分を予測するみたいなことを考える
-
モデルの学習、サービングは外部でやるしかなさ気なので、1日でサンプリングデータをcloudfunctionsにPOSTして保存し、その後学習 & 予測してinfluxdbに書き戻す
-
今段階で十分なデータがないので、とりあえず日時でデータを書き出すところまで作っておく
- cloudfunctionsメモ
- VPC内からしか接続できなくすればまあ安全なのでこれを使う
-
そもそもDBなので普通にタイミングでクエリ書けばいいことに気づいた。
-
bucketとDBをマッピングする
influx v1 dbrp create --db 設定したいDB名 --rp 設定したいRP名 --bucket-id BUCKET_ID --org-id ORGANIZATION_ID --token 発行したトークン
- クエリの例。例えば直近10分分の全データを取るならこう
curl --get 'http://localhost:8086/query' --header "Authorization: Token 発行したToken" --data-urlencode "db=設定したDB名" --data-urlencode 'q=SELECT * FROM 設定したDB名.設定したRP名.measurement名 WHERE time > now() - 10m;'