UnicodeとUTF-8: 文字エンコーディングとJavaによるファイル内容出力処理の実装
はじめに
今回は、Javaを用いてファイルの内容を標準出力する方法と、文字コードに関する基礎知識について解説します。
Unicodeについて
Unicodeとは?
Unicodeは、世界中の文字を一つの標準で統一し、国際化対応のアプリケーションを容易にするための重要な技術です。さまざまなエンコーディング方式があり、開発者はその特性に応じて最適な方式を選択して文字データを扱います。
UTF-8とは
UTF-8は、Unicodeで割り振ったコードポイントをコンピュータが理解できる別の16進数の数字(符号)に変換する方法の1つです。
「コードポイント → 符号」に変換する方法 の1つ。

UTF-8のエンコーディング方法について
・具体的な例として、「い」のUnicodeはU+3044です。
・UTF-8では、コードポイントによって異なるバイト数を使用してエンコードします。
- 1バイト: U+0000からU+007F(ASCII)
- 2バイト: U+0080からU+07FF
- 3バイト: U+0800からU+FFFF
- 4バイト: U+10000からU+10FFFF
U+3044はU+0800からU+FFFFに該当するため、3バイトで表現されます。
・UTF-8ではアルファベットは1バイトでひらがなは3バイトです。
U+の後に続く文字はその文字に対応するコードポイントを指します。
3044を2進数に変換すると、
0011 0000 0100 0100
エンコードフォーマット
1バイト 0xxxxxxx
2バイト 110xxxxx 10xxxxx
3バイト 1110xxxx 10xxxxxx 10xxxxxx
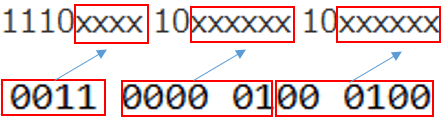
この赤枠に変換した2進数を当てはめます。
11100011 10000001 10000100
この3バイトのフォーマットに3044の2進数を3バイトのフォーマットに当てはめ、1バイトごとに4ビットに分けます。
11100011 10000001 10000100 → 1110|0011 1000|0001 1000|0100
それぞれの4ビットを16進数に変換します。
2進数:1110 → 16進数:E
2進数:0011 → 16進数:3
2進数:1000 → 16進数:8
2進数:0001 → 16進数:1
2進数:1000 → 16進数:8
2進数:0100 → 16進数:4
E3 81 84
ファイルを読み込んで、標準出力する方法
ファイルを読み込んで、ファイルの内容を出力する方法について、解説していきます。
事前準備
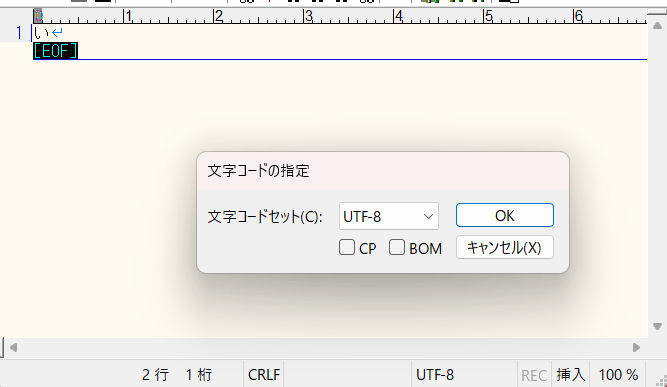
出力対象のファイルの文字コードをさくらエディタを使用して、UTF-8に設定します。
ソースコード
package practice;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
public class practice01 {
public static void main(String[] args) {
try {
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream("C:/Users/UsrMan/Documents/SAMPLE/practice.txt"), "UTF-8"));
int ch;
String str;
while((ch = br.read()) != -1){
System.out.print((char)ch);
}
br.close();
}catch(FileNotFoundException e){
System.out.println(e);
}catch(IOException e){
System.out.println(e);
}
}
}
BufferedReaderの初期化
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream("C:/Users/UsrMan/Documents/SAMPLE/practice.txt"), "UTF-8"));
・FileInputStreamを使って指定したファイルを開きます。このストリームはバイトストリームです。
・InputStreamReaderを使ってバイトストリームを文字ストリームに変換し、指定したエンコーディング(この場合はUTF-8)で読み込みます。
・BufferedReaderを使用して、効率的に文字を読み込むためのバッファリング機能を提供します。
・第1引数
new InputStreamReader(new FileInputStream("C:/Users/UsrMan/Documents/SAMPLE/practice.txt"), "UTF-8")
説明
この引数には、ファイルからデータを読み込むためのInputStreamReaderオブジェクトを指定します。
具体的には、FileInputStreamを使用して指定したパスのファイルをバイトストリームとして開き、そのバイトデータを文字ストリームに変換します。
・第2引数
"UTF-8"
説明
この引数には、文字データがエンコードされている方式を指定します。
この場合、ファイルがUTF-8エンコーディングで保存されていることを示しています。
この設定により、InputStreamReaderはファイルの内容を正しく解釈し、文字データとして読み込むことができます。
文字の読み込み
int ch;
while ((ch = br.read()) != -1) {
System.out.print((char) ch);
}
・br.read()メソッドを使って1文字ずつファイルから読み込みます。read()は次の文字が存在する場合はその文字のUnicode値を返し、終端に達すると-1を返します。
・読み込んだ整数値をキャストして文字に変換し、標準出力に表示します。
結果
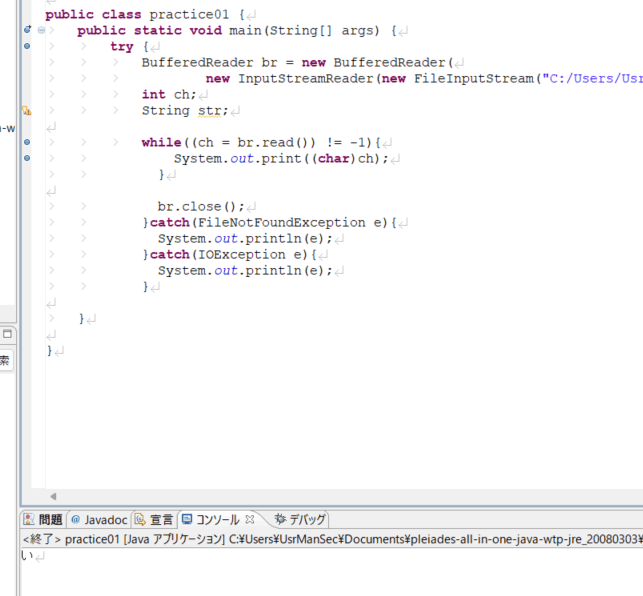
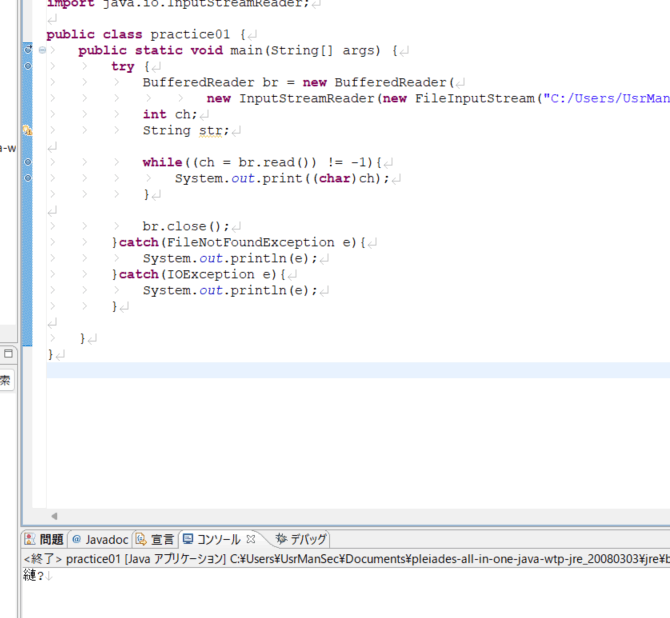
文字化け
InputStreamReader の第2引数にUTF-8以外の文字コードを指定すると、下記画像のように文字化けが発生します。
例:第2引数をSJISに設定。
まとめ
いかがだったでしょうか。今回、文字コードの解説と、それに伴ったJavaを用いた出力方法を実装しました。新しい技術を学習することは重要ですが、同時に不変的なIT技術を理解することも大切だと再認識しました。
Discussion