Dockerに改めて入門してみる
素人が学ぶ Docker 入門
はじめに
devcontainer に始まり、動作環境を構築する際コンテナを使用するのはもはや常識となっています。
しかし、実際に使用している私はコンテナがよく分かりません。
そのため、調べて出たコードをそのままコピペして、動けばラッキーという状態です。
これではいけない、せめてコピペしたコードが何をしたいのかくらいは説明できるようにしたいと思っていました。
そこで、今回は Docker を使用し、コンテナ技術の概要を簡単にですが学んでいこうと思います。
注意点ですが、Docker のインストールについては記載しておりません。
別途インストールをお願いします。
また、私は WSL2 で Docker を使用しており、Docker のバージョンは 20.10.21 です。
早くバージョンアップしないといけませんね。
それでは、始めます。
コンテナの特徴について、基本のキの一歩手前
① 独立した軽量な実行環境
かつて独立した環境を作る際は仮想マシンを用いていました。
独立した実行環境は確かに作成できるのですが、各環境ごとに OS を構築する必要があります。
そのため、リソース消費の激しさがデメリットとしてありました。
一方で、コンテナはそれ自体に OS カーネルは含まれていません。
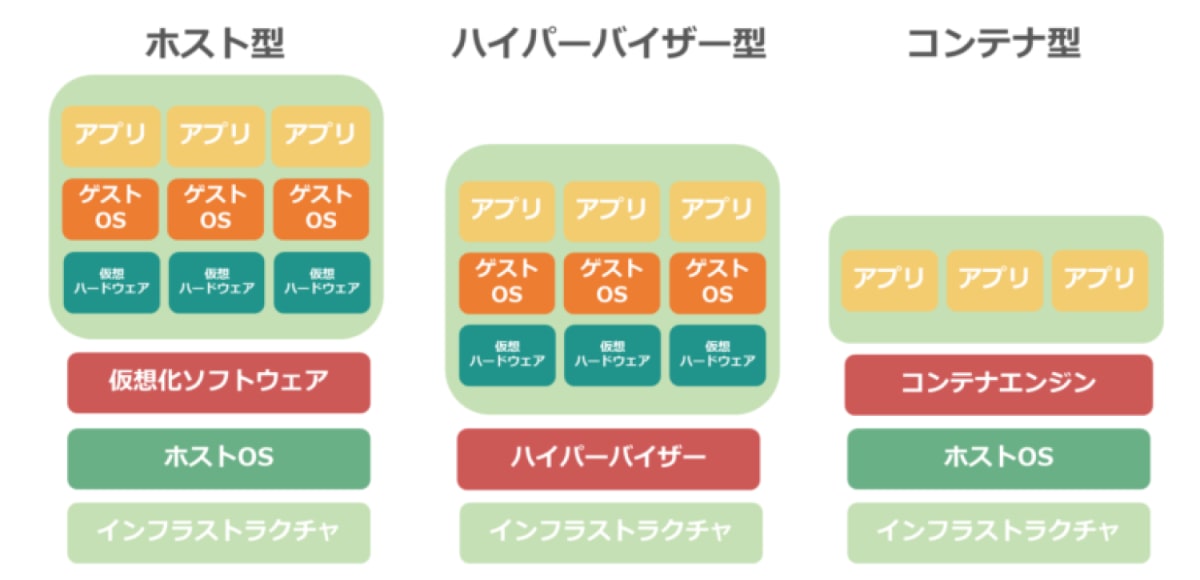
仮想環境(VMware)とは?仕組みやメリット・デメリットを解説より引用
コンテナ自体はプロセスの一部だからです。
ですが、コンテナを生み出しているプロセスはホスト OS の機能を使用して、通常のプロセスよりも強く隔離が行われているため、独自環境を構築が行えます。
以上が、コンテナの軽い理由と独立性持たせる方法の超簡単な概要です。
概念はわかったので、各コンテナが独立しており、互いに影響を及ぼさないのを実際に見てみましょう。
まず、docker run -it --name mycontainer1 ubuntuコマンド※でコンテナ名が mycontainer1 であるコンテナを作成します。
※docker をインストールしただけでは、このコマンドでコンテナを作成することはできません。コンテナを動かすための詳細は後ほど記載しますので、ここでは「mycontainer1」という名前のコンテナを作成したとだけ理解していただければ幸いです。
次に、docker run -it --name mycontainer2 ubuntuコマンドでコンテナ名が mycontainer2 であるコンテナを作成します。
これらを実行すると bash シェルが起動するので、mycontainer1 コンテナのほうにecho "test" > /test.txtコマンドを実行し、ファイルが存在することを確認します。

一方で、mycontainer2 コンテナのほうで test.txt ファイルを呼び出そうとすると、ファイルが存在しない旨のエラーが表示されます。

以上のことから、各コンテナは独立して存在することが分かります。
独立性を保つことができると、各 PC に依存せず簡単に環境構築ができます。(とはいえ環境構築は最難関事項であることに変わりないですが…)
② 高いポータビリティ
コンテナの素となるイメージは非常に配布しやすいものとなっています。
これはコンテナの独立性や軽量性に加えて、Docker や Kubernetes などコンテナ周りのツールが充実していることで配布先でも使いやすいためです。
この配布しやすいこと、配布先で環境を再現するためのツールが多く存在するのはコンテナの利点として挙げられます。
③ エコシステム
コンテナはインフラにおいて広く用いられる技術であり、コンテナに関わるツールや OSS は相当数あります。
さらには、Open Container Initiative(OCI)といったコンテナの標準仕様の策定を行っているプロジェクトや、Cloud Native Computing Foundation(CNCF)という OSS プロジェクトの成熟度を決めるプロジェクトがあります。
以上のようにコンテナに関わる情報が多く存在しているのも、コンテナ技術の特徴の一つです。
以上で超ざっくりとコンテナの特徴に触れたので、ここからは実際にコンテナを扱う際に広く使われる Docker を用いて、コンテナ周りを色々と触ってみます。
Docker に触れてみる
Docker コンテナを実際に動かしてみる
docker pull コマンド
pull コマンドは Docker イメージを取得するためのコマンドです。
イメージですが、git でコードを GitLab や Guthub から取得する際に使う「git pull」コマンドと似たいような感じです。
pull コマンドでこれから動かす Docker コンテナのコード群をとってきています。
今回は ubuntu イメージを取得してみましょう。
ターミナルでdocker pull ubuntuコマンドを実行します。
「Status: Downloaded newer image for ubuntu:latest」というメッセージが最後の方に表示されれば、正しくイメージをダウンロードできています。
では、イメージの詳細を確認してみます。
イメージに対して操作するときはdocker imagesコマンドを使用します。
まずはdocker image -aで自身の環境に存在しているイメージを確認してみます。

すると上記のような表示が出てきます。
それぞれ見てみましょう。
- REPOSITORY
- イメージの名前です。
- TAG
- イメージに対するタグです。
- イメージのバージョンを示すのに使われることが多いです。
- IMAGE ID
- イメージに割り振られた ID です。
- イメージを指定する時はこの ID を使用します。
- CREATED
- イメージが自身の環境に作られた時間を示します。
- SIZE
- イメージのデータサイズ
まだコンテナ化されていないとはいえ、LinuxOS の一つである ubuntu のサイズが 77MB ぐらいなのは驚きですね。
Docker は軽いと言われる由縁を少し感じました。
- イメージのデータサイズ
余談 Docker イメージはどこに保存されているの?
Docker からイメージを取得したい際はdocker pullコマンドを使いますが、このイメージはDocker Hubという Docker イメージ共有サービスに保存されています。
そのため、自分の Linux 環境に合わせたイメージやどのようなイメージのバージョンがあるのかなど、イメージの詳細が知りたい場合はこのサイトを参照するとよいです。
試しにMy SQL の Docker イメージについて軽く眺めてください。
イメージを pull する際のコマンドや、バージョン、コンテナの起動方法など色々な情報が記載されています。
このように、欲しいアプリや機能が搭載されているコンテナを実行したい場合は、Docker Hub から探し、ドキュメントを参照してコマンドを実行することになります。
ただし、一点注意することがあります。
Docker Hub にはアカウントを作れば、誰でもイメージをアップロードすることができます。
なので、メンテナンスされていないイメージや中には悪意のあるイメージがアップされている可能性があります。
とはいえ、Docker 素人がイメージの中身を見て問題があるのか判断するのは難しいです。
そこで、pull していいかを判断する目安に「Docker Official Image」の有無を挙げることができます。
先ほどのMy SQL の Docker イメージページを再度確認すると、イメージ名の横に「Docker Official Image」というバッチがあります。

これは、Docker 社がイメージの製作者にイメージの中身やドキュメントを確認し、ドキュメントの正しさやイメージの定期的なアップデートを保証されたイメージに対して付与します。
このバッチがあることはすなわち、Docker 社に正規イメージとしてお墨付きを貰ったイメージとなります。
私のようなイメージの是非を判断できない Docker 素人がイメージを pull する際は、「Docker Official Image」バッチが付いているイメージを pull すれば事故に繋がる可能性は低くなります。
Docker になれない内は、「Docker Official Image」バッチが付いているイメージのみ使用するようにしましょう。
ーーー以上余談ーーー
ここまでで自身の環境にイメージを取得することができました。
しかし、git の場合もそうですが実際にアプリを動かす際は、何かコマンドを実行しサーバーを起動すると思います。
Docker の場合も同様です。
イメージをコンテナとして起動するには別途コマンドを実行する必要があります。
それがdocker runコマンドです。
docker run コマンドを実行することで、イメージをコンテナとして起動し、イメージに含まれていたアプリケーションを実行できるようになります。
では実際に起動してみます。
docker run -it ubuntu コマンドを実行します。
ちなみにイメージ ID を使用して、docker run -it c6b84b685f35 のようなコマンドでも同様にコンテナを起動できます。
コマンドを実行すると「root@8e7f2480c9b7:/#」といったような感じで、bash シェルが起動すると思います。
余談 -it オプションについて
-itオプションをつけないと何も表示されずにコンテナが起動し、終了します。
これは-it オプションが標準入力(≒ キーボードからの入力を受け付ける)と標準出力(≒bash シェルを起動)を意味するからです。
上記オプションを指定して、コンテナを起動すると先ほどのように bash シェルが表示され、コマンドを入力できるようになります。
上記オプションに加え、コンテナを起動時に実行するコマンドを指定したり、タグを付与したりできますが、正直勉強用の環境構築する際しか使用した記憶がないので、ここでは割愛します。
そういったオプションにまつわる話は、後に解説する Docker Compose で間接的にお話します。
ーーー以上余談ーーー
bash シェルが開いたら、別のターミナルを開きコンテナの状態を確認します。
コンテナの状態を確認するには、docker psコマンドを使用します。
すると下記画像のような結果が表示されます。

STATUS の部分に「Up 5 seconds」と Up から始まる表示がされていれば、コンテナの起動は完了です。
その他の表示内容は次の通りです。
- CONTAINER ID
- コンテナに割り振られた ID
- コンテナを削除する際などはこの ID を指定します。
- IMAGE
- コンテナの基になっているイメージ名
- COMMAND
- コンテナを起動する時に指定したコマンド
- このコマンドが終了するとコンテナも終了します。
- CREATED
- コンテナを作成した時間
- STATUS
- コンテナの状態
- 起動中は「Up」、終了している時は「Exit」など複数の状態があります。
- NAMES
- コンテナの名前
- 名前を指定しなかった場合は、「形容詞_人の名前」というコンテナ名がわりふられます。
なお、docker ps コマンドには稼働・終了中すべてを含めたコンテナの状態を表示する-aオプションや、コンテナ ID を表示する-qオプション、最後に作成したコンテナ情報を示す-lオプションがあります。
コンテナの状態を確認したい時は適宜活用してください。
ここまででコンテナを起動が確認できました。
次にコンテナの削除を行っていきます。
コンテナの削除を行う理由は、コンテナを起動し続けると容量を圧迫してしまうからです。
以下の画像をみてください。

これは ubuntu コンテナを起動させ、別のターミナルでdocker ps --size コマンドを実行した結果です。
注目して欲しいのは SIZE の部分です。
SIZE を確認すると、ubuntu コンテナは 77.8MB の容量を使用しています。
「0B(virtual 77.8Mb)」と不思議な書き方をしていますが、とりあえず今動かしている ubuntu コンテナは 77.8MB のディスク容量を使用していると理解していただければ幸いです。
細かい話は後の余談で話ますので、一旦は飛ばします。
コンテナは軽いとはいえ、大量に動かし続けるとディスク容量を圧迫します。
そのため、使わないコンテナは適宜削除した方がよいです。
なので、これからコンテナを削除していきます。
今動かしている ubuntu コンテナ内でexit を実行し、コンテナを停止します。
また、話が飛んで恐縮なのですが、コンテナを停止したからディスクには影響ないと思われた方もいらっしゃると思います。
私はそう思いました。
しかし、docker ps -a --sizeコマンドで停止中のコンテナ一覧を見ると
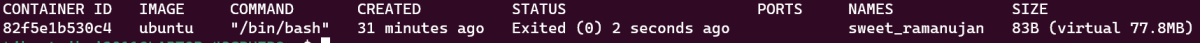
停止しているコンテナにもディスクの割りあてが行われています。
このようにコンテナを停止しただけでは、容量を圧迫したままなので、コンテナを使用しない場合は削除することが推奨されます。
コンテナを削除する場合は docker rm コマンドを使います。
先ほど確認したコンテナ ID「82f5e1b530c4」を使用して、docker rm 82f5e1b530c4コマンドを実行します。
完了後、docker ps -a コマンドを実行しても何も表示されなくなりました。
これで、コンテナの削除が完了しました。
ちなみに、使っていないコンテナを全部削除したい場合はdocker container pruneコマンドを実行すれば削除できます。
が、後ほど記載するデータボリューム・コンテナがあるとそれも消してしまうので、あらゆる場面で使用すべきものではありません
余談 コンテナの SIZE が「0B(virtual 77.8Mb)」と表現されたことについて
先ほどコンテナのサイズを確認した時に、virtual というよくわからないものが出てきました。
まずそれっぽいことがドキュメントに書いてあるので、見てみましょう。
size=(ディスク上の)データ総量。 各コンテナーの書き込みレイヤーが利用するデータ部分です。virtual size= コンテナーにおいて利用されている読み込み専用のイメージデータと、コンテナーの書き込みレイヤーのsizeを足し合わせたデータ総量。 複数コンテナーにおいては、読み込み専用イメージデータの全部または一部を共有しているかもしれません。 1 つのイメージをベースとして作った 2 つのコンテナーでは、読み込み専用データを 100% 共有します。 一方で 2 つの異なるイメージが一部に共通するレイヤーを持っていて、そこからそれぞれに 2 つのコンテナーを作ったとすると、共有するのはその共通レイヤー部分のみです。 したがってvirtual sizeは単純に足し合わせで計算できるものではありません。 これはディスク総量を多く見積もってしまい、その量は無視できないほどになることがあります。
なんのこっっちゃ?ですね。
語弊を恐れずにいうなら、sizeはコンテナ内で私が作成したデータの容量のことをさし、virtual sizeは Docker イメージの容量にsizeの値を足したものとなります。
そして、「0B(virtual 77.8Mb)」の 0B はsizeの値、77.8Mb はvirtual sizeの値となります。
先程ダウンロードした ubuntu イメージの容量は 77.8MB で、コンテナを起動しただけでは何もデータは作成されていないので、概ね上記理解で問題ないと思います。
念のため、dd if=/dev/zero of=test9M bs=1M count=9コマンドで約 9MB のダミーファイルを作成します。
その後、docker ps --size コマンドでコンテナの容量を確認すると下記の画像のように、sizeとvirtual sizeが共に 9MB ほど増えているのが分かります。

その他Github のイシューに同じような疑問を持たれた方に対する回答があるので、よければご確認ください。
以上がコンテナサイズを確認する際表示されていた「0B(virtual 77.8Mb)」の概要となります。
これで、コンテナ単体でどれほど容量を使っているのかを確認する方法がわかりました。
しかし、一点注意点があります。
複数のコンテナが使用してい容量の合計を算出する際は、単純にvirtualの値を足してはいけない場合があります。
コンテナは各環境が分離されており、他の環境には影響を及ぼしません。
これは先程コマンドで確認したように、片方のコンテナでの変更はもう片方に反映されません。
一方で、各コンテナは完全に分離されてはいません。
コンテナ内の Docker イメージで構成される部分は、同じ Docker イメージを使用している場合共有されています。
イメージを掴むために、下記画像をみてください。
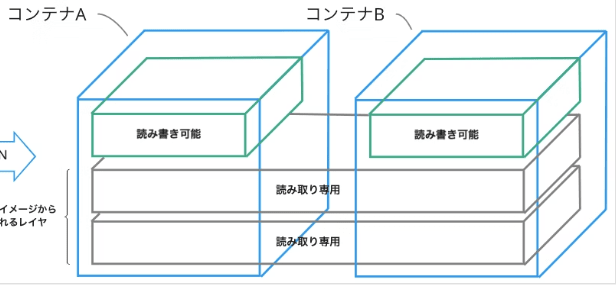 > Docker コンテナのレイヤ構造とは?から引用
> Docker コンテナのレイヤ構造とは?から引用
Docker はこのように、環境を動かすために使用する読み取り専用のファイル群は内容が一緒であれば使いまわすようにしています。
これは Docker イメージ部分をコンテナごとに新しく作ってしまうと、不必要に容量を使用してしまうのを防ぐのが理由です。
一方で、新しくコンテナ内で作成したデータは共有しないようにして、各コンテナで独自の部分は他に影響を及ぼさないようにしています。
軽量で動くという Docker の利点を壊さないために、動かすための下地はどのコンテナでも同じになるのだから一緒にしてしまって、肝心なところだけ独自で動かすようにしちゃえということです。
この技術は調べていて、「賢い~」と感動しました。
Docker に簡単なアプリを入れてみる
先ほど ubuntu コンテナを起動~削除までしました。
ここでは、ubuntu コンテナに ping をインストールして、ping コマンドが実行できるようにします。
とはいえ、節に分けるか悩んだくらい簡単です。
まず、docker run -it ubuntuコマンドで ubuntu コンテナを起動し、コンテナ内に入ります。
そのあと、apt updateでリポジトリを更新し、apt install iputils-pingコマンドで ping をインストールします。
インストールできたら、ping localhostを実行して、動くことを確認してください。
これで完了です。
ほぼ、WSL2 とかの Linux 環境でやるのと同じ流れでしたね。
違いと言えばコンテナ内のシェルは root ユーザーでしたが、普段は root ユーザーで操作しないことくらいです。
他の環境と隔離されつつ、ubuntu の機能を使えるのは非常に便利ですね。
コンテナって凄いなと改めて感じます。
Docker の基本のキを学習する
先程でコンテナを起動したり、削除したりとコンテナを中心に Docker へ触れました。
とはいえ、Docker にはまだまだ機能があります。
そこで、この章ではもう少し Docker の機能に触れることで、チュートリアルを学んだ状態から、Docker の基本のキを学習していきます。
Web サーバーの起動
ここでは、Apache コンテナを導入して、もう少しだけ実践的なコンテナを起動します。
web サーバーを動かし、web ページが表示できることをゴールにします。
まず、docker pull httpdコマンドで Apache の公式イメージを入手します。
次にdocker run -d httpdコマンドで Apache コンテナを起動します。
-d オプションはデタッチモードでの起動を意味します。
Apache は web サーバーなので、常に動いていることが要求されます。
そのため、デタッチモードで起動して、バックグラウンドで動作させるようにしています。
これによって、誤ってターミナルを消してしまってもサーバーが落ちたりしません。
docker psでコンテナが作成されていることを確認したら、コンテナが起動できました。
これで、Apache サーバーは動いているので、早速 http://localhost にアクセスします。
すると、なんと「このサイトにアクセスできませんでした」というエラー画面が出ます。
どこかコンテナに異常がおきているのでしょうか?
こちらですが、コンテナに異常は起きておりません。
コンテナは正常に動いており、Apache サーバーはコンテナ内でしっかり動いています。
しかし、先程のコンテナの起動方法ではブラウザでのアクセスがコンテナまで届かない状態になっています。
ブラウザから http://localhost にアクセスした時の対応はまずホスト OS が行います。
そして、そのホスト OS 上にある Docker Engine がアクセスを受けたポート番号をもとに、通信を送る対象のコンテナを判断して、コンテナと連携させます。
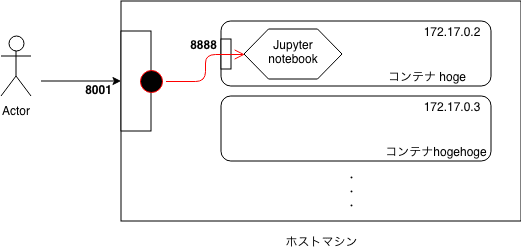
Docker 実践〜docker コンテナに外部からアクセスするためにポートフォワード設定を追加するから引用 画像内の赤矢印を設定していなかったので、アクセスが出来なかった。
以上の設定を行えば、ブラウザで http://localhost にアクセスしたら、コンテナの Apache サーバーに接続できます。
では、先程のdocker run -d httpdコマンドに戻ります。
上記コマンドはコンテナの起動はしていますが、Docker Engine にホスト OS が受けたアクセスのポート番号に対して接続するコンテナのポート番号を指定していません。
なので、コンテナは起動できてもブラウザで Apache サーバーに接続ができませんでした。
Docker Engine にポート番号の指定を行えばよいので、コンテナを起動する際にdocker run -p 80:80 -d httpdと-p オプションを起動してホスト OS が受けるポート番号と対応するコンテナのポート番号を紐づけます。
なお、ポート番号を指定する場合「ホスト OS のポート番号:コンテナのポート番号」という構成になりますのでご注意ください。
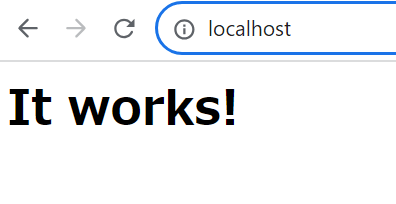
ポート番号の設定が完了したので、今一度 http://loalhost にアクセスすると馴染みのある「It Works!」が表示されます。
コンテナを使用している際のデータの扱いについて
コンテナの思想考え方として、コンテナ自体は使い捨てで、コンテナの利用が終わったらその時点で破棄するものという前提があります。
そのため、コンテナにデータを保存しておくことは適切な方法ではありません。
消えては困るデータをコンテナに残しておくと、コンテナを使い捨てすることが出来なくなるからです。
とはいえ、ログなど消えては困るデータは往々にしてあると思います。
そこで、この節ではコンテナを使いつつ上記のようなデータを永続的に保存する手法について学んでいきます。
データを永続的に保存するには二つの方法があります。
- Docker の管理外にあるホスト OS 側のディレクトリに保存する
- 「永続コンテナ」というデータ専用コンテナを作り、そこに保存する
それぞれ見ていこうと思いますが、その前に Docker がデータを永続的に保存する方法として使用するマウントについて確認していこうと思います。
データの保存方法「マウント」について
マウントとは、OS と異なるデバイスにある領域を OS 上のディレクトリ階層に組み込み、アクセスできるようにする技術です。
イメージを掴むためにパソコンに USB を指すことをイメージしてください。
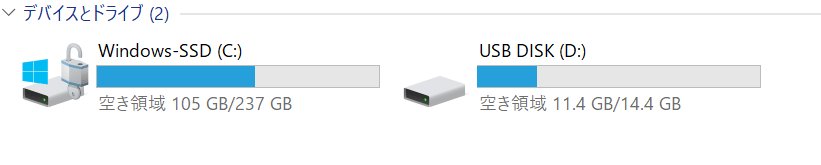
上記画像のように、Windows パソコンに USB メモリを指すと USB 内のデータへアクセスできるディレクトリが表示されます。
これによって、パソコンから USB へのアクセスが可能となります。
まさにこの他の機械である USB にアクセスするための結合点となるディレクトリを設定することがマウントといいます。
今回でいうと、ホスト OS である Linux やボリュームとコンテナの結合点となるディレクトリを作成することで、コンテナを削除して再度起動しても以前のデータを取得できるようになります。
ちなみに、結合点のことをマウントポイントといい、つながった先のディレクトリをマウントディレクトリといいます。
マウントについて触れましたので、実際にデータを永続的に保存する方法について見ていきましょう。
Docker の管理外にあるホスト OS 側のディレクトリに保存する
ここではデータの保存場所をコンテナの外にあるホスト OS にして、データが残るようにしていきます。
先程 Apache を使用していることからログの保存をすると言いたいところですが、今回はとりあえずサクッと確認したいので web サイトのトップに位置する公開ディレクトリである DocumentRoot をマウントします。
まず Docker コンテナでは DocumentRoot ディレクトリをマウントポイントにします。
Apache の DocumentRoot ディレクトリのデフォルト値は/usr/local/apache2/htdocs/なので、こちらを指定します。
次にホスト OS 側は/root/webContents ディレクトリを作成し、これら二つのフォルダをマウントします。
ホスト OS 側で以下のコマンドを順番に行い、「hello world」と記載された index.html ファイルを作成します。
cd /root
mkdir webContents
cd webContents
echo "hello world" > index.html
作成したら、コンテナを起動しますが、マウントをしながらコンテナを実行する必要があります。
その際に使用するオプションが-v オプションです。
このオプションの後に「ホスト側ディレクトリ:コンテナ側のディレクトリ」を記載して、マウントを行います。
その他は「Web サーバーの起動」で指定した内容と同じです。
では、docker run -v /root/webContents/:/usr/local/apache2/htdocs -p 80:80 -d httpdコマンドを実行して http://localhost にアクセスしてみましょう。
すると、画面に先程 webContents ディレクトリで作成した index.html の内容が反映されていることが確認できます。
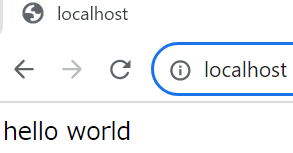
このようにコンテナ側のディレクトリをホスト側のディレクトリにマウントすることで、コンテナが破棄されてもデータは残ったままになります。
しかし、このホスト OS を使ったデータの永続化は、Docker において非推奨です。
理由は下記二点があります。
- Docker コンテナとホスト OS 側でアカウントや権限の違いで、意図しない動作をする可能性がある。
- ホスト OS の環境に依存することになり、Docker コンテナの利点である独立性を保つ足かせとなる。
上記デメリットがあるため、Dockerfile などではそもそもホスト OS 側のディレクトリにマウントすることはできないようになっています。
よって、コンテナでデータを永続化するならこの後解説するデータボリュームやデータボリュームをコンテナ化したボリューム・コンテナを使用します。
ただし、ホスト OS のディレクトリに対して永続データを出力することは非推奨でも、docker のデータボリュームのバックアップを保存しておくことはあります。
なので、ホスト OS とコンテナのやり取りについて存在を知っておくことで損はしません。
データボリューム、データボリューム・コンテナを使用してデータを永続化する
ここでは、データの永続化をデータボリュームや、データボリュームをコンテナ化したデータボリューム・コンテナを使用して行います。
データボリュームとはデータを保存する領域のことをさします。
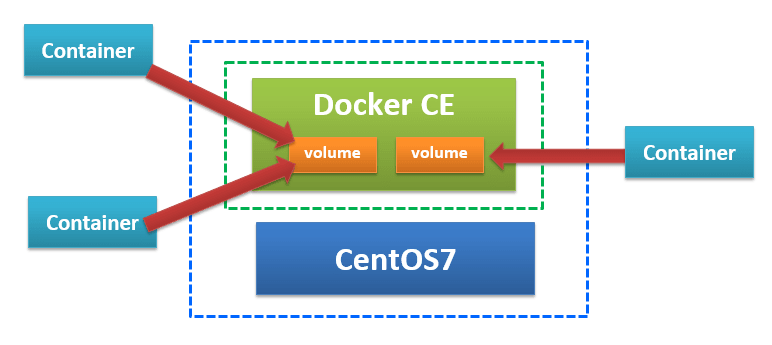
【Docker】第 6 回 マウントについて(volume)から引用
そのため、まずデータボリュームを作成して、その後にコンテナとデータボリュームをマウントするようにします。
なお、複数のコンテナで一つのデータボリュームを共用する場合は、データボリューム・コンテナを使用します。
では、データボリュームを作成してみます。
docker volume create --name=datavolumeコマンドを実行します。
このコマンドでデータボリュームを作成することができました。
docker volume lsで作成したボリュームが表示されていることを確認します。

なお、ボリュームを作成することに重要なこととして—name オプションでボリューム名を指定することです。
指定しないと、ランダムなボリューム名が付与されますがコンテナから接続する際に、ボリュームの種類が分からないと不便です。
そのため、どういう意図で作られたボリュームなのかを理解するためにも、—name オプションでボリューム名を指定するのがよいです。
ボリュームが作成できたので、マウントを設定しつつコンテナを起動します。
今回は ubuntu コンテナを起動し、マウントポイントとして/tmp ディレクトリを指定します。
docker run -it -v datavolume:/tmp/ ubuntuを実行して、コンテナ内に入ります。
そして、touch /tmp/data.txtで tmp ディレクトリに data.txt ファイルを作成します。
その後、exitでコンテナを停止して、docker rm コンテナIDを使ってコンテナを破棄します。
通常であれば、コンテナ内の tmp ディレクトリに作成した data.txt はコンテナが破棄されたタイミングで消失します。
しかし、今回はデータボリュームとマウントしているため、データはそのまま残っています。
上記を確認するためにdocker run -it -v datavolume:/tmp/ ubuntuを再度実行して、コンテナを起動します。
コンテナ内に入ったら、ls /tmp/を実行するとなんと先程作成した data.txt ファイルが表示されています。
このように、データボリュームはコンテナの生成・破棄によらず残り続けます。
そのため、データを永続化したい場合はデータボリュームを使用するようにしましょう。
データボリュームの作成と利用ができたので、コンテナと同様に使わないボリュームは削除します。
注意点として、データボリュームを削除するにはデータボリュームを使用しているコンテナを先に削除する必要があります。
なので、docker rm コンテナIDを実行後dokcer volume rm ボリューム名でボリュームを削除します。
以上でデータボリュームの概要と作成・削除方法について学びました。
今度はデータボリューム・コンテナというデータ専用のコンテナを使用してデータの永続化を行います。
まず、データボリュームに再度確認します。
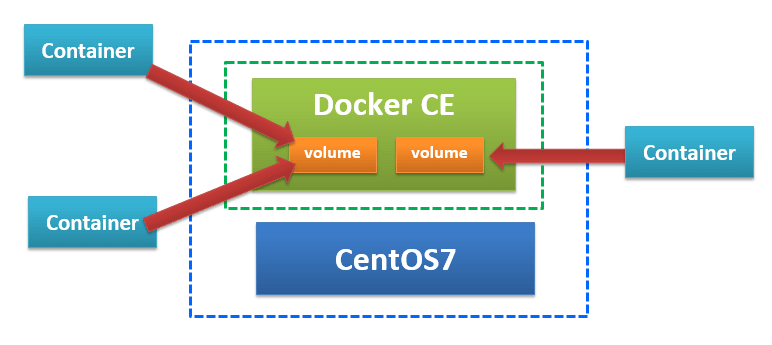
データを保存する用の領域を作り、コンテナとマウントすることでデータを永続化できるものでした。
そして、異なるコンテナでもマウント先が同じであればデータを取得できます。
しかし、マウントのパスがコンテナごとに少しでも異なるとデータの共有先が変わってしまい、同じボリュームを使用していても想定したようにデータが取得できなくなります。
上記問題を解消するために、データボリューム・コンテナを使います。
データボリューム・コンテナは予めデータボリュームとマウントしたコンテナで、他のコンテナはデータボリューム・コンテナを経由してボリュームデータとやり取りを行うことができます。
データボリューム・コンテナはすでにマウント先が指定してあるので、コンテナごとにデータボリュームとのマウントを行う必要がなくなり、マウント先の間違いを防ぐことができます。
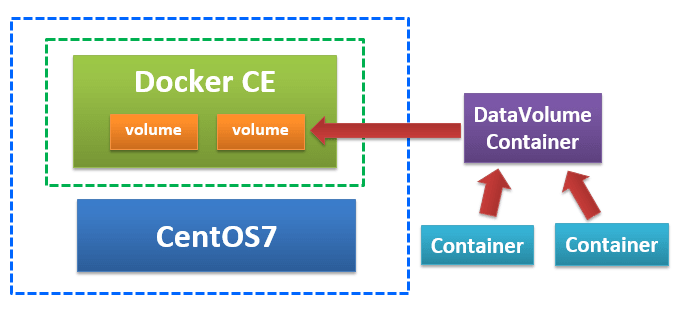
【Docker】第 7 回 マウントについて(データボリュームコンテナ)より引用
では早速やってみます。
まず、docker volume create --name=datavolumeでデータボリュームを作成します。
次に、docker run --name=data-container -v datavolume:/tmp ubuntuでデータボリュームとデータを共有するコンテナを作成します。
このコンテナがデータボリューム・コンテナとなります。
そのため、他のコンテナと連携しやすいように—name オプションでコンテナに名前を設定しています。
データボリューム・コンテナ連携したコンテナを作るには—volumes-from オプションを使用します。
なので、docker run --volumes-from data-container -it ubuntでコンテナを起動すると data-container 経由で、データボリュームとやり取りができるようになりました。
どのコンテナからもアクセスできることを確認するために、もう一つ同様のコマンドを実行しそれぞれのコンテナでマウント先のディレクトリにファイルを作成してみてください。
すると、お互いのコンテナでデータが共有されていることが確認できると思います。
以上でデータボリューム・コンテナを作成することができました。
コンテナの数がそこまで多くない今は、それほど有効だと感じませんでしたが、今後コンテナの数が増えると恩恵を受けられそうだなと思います。
なお、データボリューム・コンテナを使用している場合、起動していないコンテナを削除するdocker container pruneコマンドには注意してください。
データボリューム・コンテナは常に停止中の扱いになるので、上記コマンドを実行するとデータボリューム・コンテナも削除されてしまいます。
削除されたのはコンテナだけなので、データボリュームには影響はなく、再度マウント先が同じなデータボリューム・コンテナを作成すれば復活することはできます。
しかし、上記のことを把握していないとdocker container pruneコマンドでデータボリューム・コンテナが消えた際、データを全て消してしまったと思い焦りそうなので共有しました。
データボリュームの内容をバックアップ・リストアする
ここまでで、データボリュームやデータボリューム・コンテナの基本的な使い方を解説してきました。
データの永続化をする際に活用でき、コンテナを破棄しても再度データへアクセスできるようになりました。
しかし、現状データはデータボリュームにしか存在せす、データボリュームが消えてしまったらデータがなくなってしまいます。
そのため、バックアップを取っておくと考えるのは当然の流れで実際 Docker にはその機能があります。
そこで、データボリュームに保持しているデータをバックアップ・リストアできる方法について見ていきます。
バックアップの順序としては以下のようになります。
- データボリューム・コンテナと接続し、かつホスト OS のディレクトリと接続しているコンテナを作る
- 1 のコンテナでデータボリューム・コンテナとやり取りしているディレクトリ配下の内容を tar ファイル化する。
- 作成した tar ファイルをホスト OS とのマウントポイントであるディレクトリに配置する。
リストアはバックアップで作成したファイルをもとに戻すことで完了します。
以上を踏まえたコマンドがそれぞれ下記のようになります。
バックアップ
docker run --volumes-from data-container -v /root/:/backup ubuntu tar cvf /backup/container-bkup.tar -C / tmp
リストア
docker run --volumes-from data-container -v /root/:/backup -it ubuntu tar xvf /backup/container-bkup.tar -C /
Docker に関わる部分はこれまで解説したものを使用しています。
そして、「ubuntu」から後ろはコンテナを起動した時に実行するコマンドを指定しています。
今回でいうと tar ファイル化したり、もとに戻したりするためのコマンドを実行しています。
コマンドの中身は Docker の範囲ではないので、ここでは割愛します。
各自確認をお願いします。
以上で、Docker の基本のキを触れました。
今まで呪文のような言葉やコマンドが意味のあるものとして、とらえられるのは楽しいですね。
とはいえ、これまのコマンドを一々打つのは面倒です。
そこで、次からは今まで実行していたコマンドをまとめて実行できる Dockerfile について解説していきます。
ようやく、実際の開発でもそれなりに使用するものが出てきました。
Dockerfile を活用する
これまで Docker イメージをダウンロードして、コンテナを起動して、時にはデータボリュームをマウントするなどを行ってきました。
しかし、それらは全てコマンドで実行しています。
小規模なコンテナの場合、コマンドでも問題ないかもしれませんが、コンテナの規模が大きくなるとコマンド入力の手間や入力ミスが多くなります。
そこでコマンド操作をバッチ処理できるようにするためのファイルが Docker にはあります。
それが Dockerfile です。
Dockerfile は以下のことを行うことができます。
- Docker イメージの取得
- コンテナの生成
- アプリケーションの導入
- 新規イメージの生成
Dockerfile を用いることで、複雑なイメージの作成が容易になり、他のホスト OS でも同じような環境の用意が容易になります。
Docker を実際の開発で使う際に使用する可能性が高く、実用性があるので実際に使ってみましょう。
Dockerfile を作成する際の注意点
Dockerfile を作成する前に以下の 3 点は
① ファイル名は Dockerfile とすること
Docker は build をという機能があります。
これは build を実行したディレクトリに存在する Dockerfile を読み込み、Dockerfile の内容をもとに独自のイメージを作成します。
一応オプションで Dockerfile という名前以外でも読み込むことはできますが、原則として Dockerfile という名前で作成するのが推奨だそうです。
②Dockerfile を配置したディレクトリには余計なものをおかない
Dockerfile を build をする際、Docker は Dockerfile があるディレクトリ以下にあるファイルを Docker Daemon に送り、処理を行います。
そのため、ディレクトリに余計なものが存在するとそれらもまとめて送ってしまうため不必要に重くなってしまいます。
以上のことから、既存のプロジェクトに Dockerfile を作るのではなく、新規のディレクトリにまず Dockerfile を作って必要なものを build するのが良いです。
なお、余計なものをおくべきでないと言いましたが、既存のプロジェクトに Dockerfile を導入するなどどうしても余計なものをおく必要がある場合もあります。
その際は.dockerignore というファイルを作成し、そこにディレクトリやファイルのパスを記載すると build の際に無視することができます。
③ コマンドはなるべく 1 命令でまとめる
Dockerfile はイメージを取得したら、そのイメージをもとにコンテナを生成し、Dockerfile に記載しているアプリケーションのインストールなどを行います。
アプリケーションのインストールなどが行われると、一つの命令に対して一つのレイヤというものが作成されます。
このレイヤ数には上限あるため、処理を追加しすぎて制限がかかることを防ぐためになるべく命令の数を減らしておく必要があります。
こちらのブログで検証していますが、筆者の環境では上限は 125 だったそうです。
案外少ないので、なるべく命令は一つにまとめることは大切だと感じました。
以上で Dockerfile を作る際の注意点を記載したので、実際に作成していきます。
余談 レイヤって何
先程レイヤ数に上限があると記載しましたが、そもそもレイヤとは何かを確認していこうと思います。
結論を先にいうと、レイヤーとは差分ファイルのことです。
もう少し具体的に見ていきます。
まず以下の Dockerfile を作成して、docker イメージを生成します。
FROM ubuntu
Dockerfile の書き方などは後の章で記載するので、一旦雰囲気だけ感じもらえたらと思います。
イメージを作成したら、docker save testimage | sudo tar -xC ../dumpimageで docker イメージを tar ファイルにして、dumpimage ディレクトリに書き込みます。
書き込んだら、tree ../dumpimage でファイル構造を確認すると以下のようになります。
../dumpimage
├── 29c4a2abb1c31c1d2f9a94ba2dd21b5678659799fecdf6df8c207d2d8854f9b4
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── c6b84b685f35f1a5d63661f5d4aa662ad9b7ee4f4b8c394c022f25023c907b65.json
├── manifest.json
└── repositories
これらのファイル群はそれぞれ、以下の特徴があります。
- layer.tar : コンテナが用いるルートファイルシステムのデータ
- c6b…(略)..b65.json : 実行コマンドや環境変数など、実行環境を再現するための情報
- manifest.json,repositories : イメージの構成に関する情報
- VERSION,json : 過去の仕様との互換性を保つためのファイル群
そして、layer.tar こそが今回の主題である差分ファイル、すなわちレイヤとなります。
今回は無の状態から、ubuntu イメージを pull してきたので、それに関わる差分が layer.tar に含まれています。
次に、この差分ファイルがどう増えていくのかをみていきます。
dumpimage 内の tar ファイルを削除して、先ほど作成した Dockerfile を以下のように変更して、再度イメージを作成します。
FROM ubuntu
RUN echo "Hello World" > /tmp/hello
なお、この変更によって、/tmp/hello が作成され、そこに「Hello World」という文字列が書き込まれます。
docker イメージを作成したら、同様にイメージの tar ファイルを dumpimage ディレクトリに書き込み、ファイル構造確認すると以下のようになります。
../dumpimage
├── 1c824fc1e048bc5bd521060d4c3509a368a94273fa544c9687a662eb8e683cee
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── e76ae430a50a74b56a12319d7ff27d371796b7602650214f2341bffeb295e60c
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── f9d9f3163e46ebeeccf044beacbc465481621a1a1856ce966766626b9919b89b.json
├── manifest.json
└── repositories
先ほどは layer.tar を含むディレクトリは一つしかありませんでしたが、今度は二つになっています。
tar --list -f ../dumpimage/e76ae430a50a74b56a12319d7ff27d371796b7602650214f2341bffeb295e60c/layer.tar | headで中身を確認すると、画像のように
tmp/hello への作成・書き込みの差分が表示されます。
このように、書き込みなどディレクトリ構造やファイルの中身が変更された場合、差分ファイル、すなわちレイヤが追加されます。
ただ、この差分ですが一回の処理で複数の変更があっても差分ファイルは一個しかできず、その一個に複数の差分が含まれています。
それを確認するために、Dockerfile を以下のように変更します。
FROM ubuntu
RUN echo "Hello World" > /tmp/hello && echo "Hello World2" > /tmp/hello2
その後イメージを再生成して、差分ファイルを確認すると以下のようになります。
../dumpimage
├── 0002dfa61bedba5e5c99a05cb97a45f8791b299b9035a38553a3e0e92cdc2f0b.json
├── 1c824fc1e048bc5bd521060d4c3509a368a94273fa544c9687a662eb8e683cee
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── dce77e3bdc12f9f180c2f7c48729989393b73561076b753c3b61f278a1d90f07
│ ├── VERSION
│ ├── json
│ └── layer.tar
├── manifest.json
└── repositories
書き込みの処理を追加したにもかかわらず、差分ファイルができておりません。
これは、処理が複数あってもコマンド自体は一行であれば、全て一つの layer.tar へ集約されるためです。
以上から、レイヤとはイメージを作成するときにできる差分ファイルで、差分ファイルは一行の処理に対して一つできることが分かりました。
この節の内容によって、「Dockerfile を作成する際の注意点」で命令を一行にする理由がイメージできそうですね。
処理を何行にも分けて書いてしまうと、差分ファイルが多くできてしまい、いずれ Docker では管理できないほど作成できてしまいます。
そのため、命令は一行になるべく納めることで差分ファイルの数を少なくして、レート制限にかからないする必要があるんですね。
理由は理解できましたが、実際の現場でこのエラーに出くわしても気づける自信はないですね。
Dockerfile を作って動かす
それではまず ubuntu イメージに ping をインストールしたものを Dockerfile で実現します。
任意のディレクトリ内に Dockerfile を作成し、以下のコードを記載します。
FROM ubuntu
RUN apt-get update && apt-get install -y iputils-ping
FROMは Dockerfile でイメージを作成する際にベースとなる Docker イメージを指定します。
RUNはイメージを作成するときに実行するコマンドを指定します。
RUNで記載した内容はレイヤーとして積み重ねられていきます。
今回は ubuntu のイメージをベースにして、iputils-ping をインストールしています。
なお、注意点として一般的な今回のような Dockerfile はスクリプト処理になるので、iputils-ping をインストールする際は-y オプションをつけて確認なしでインストールするようにします。
そして、RUNの部分で&&を使ってコマンドをまとめています。
先程記載したように Docker のレイヤーには制限があるので、まとめられる部分は上記のように&&などを使ってまとめるようにしてください。
ここまで完了したら、docker build -t ping-image .を実行してイメージを作成します。
-t オプションはイメージ名やイメージ名に付与するタグを指定できます。
今回はタグの指定はせずに ping-image というタグ名を付与しています。
また、最後にピリオドを記載しております。
これは build する Dockerfile のパスを指定します。
今回はカレントディレクトリなので、それを示す「.」として指定しています。
上記コマンドを実行すると画像のように、Dockerfile の内容に合わせて処理を実行します。

build が完了したら、Docker イメージがターミナルに存在することを確認して、docker run -it ping-imageでコンテナを生成します。
コンテナ内に入れたら、ping localhostで ping が動くのを確認できれば Dockerfile を使用したコンテナの生成は完了です。
Dockerfile の文法
先程 Dockerfile を軽く触ってみて、大まかな流れを把握しました。
そこで、ここでは Dockerfile の中身を細かく見るために、Dockerfile 内で使用できるコマンドについて見ていきます。
Dockerfile の書式
Dockerfile は基本的に以下のような書式です。
#コメント
命令 引数
命令は大文字と小文字の区別をしませんが、慣習として命令は大文字で引数は小文字で表します。
1 行の命令が長くなった場合は、「(バックスラッシュ)」を使って新たな命令をせずに改行することができます。
shell 形式と exec 形式
shell 形式は「Dockerfile を作って動かす」や「Dockerfile の書式」で記載したような
命令 引数
の形式をとります。
なお、この書式はシェル(/bin/sh)を通してコマンドが実行されるので、$HOMEといった環境変数が使えます。
一方で、exec 形式は
命令 ["実行バイナリ","パラメータ1","パラメータ2"]
の形式をとります。
「Dockerfile を作って動かす」で記載した RUN 命令を exec 形式で記載すると
RUN ["/bin/sh","-c","apt-get update && apt-get install -y iputils-ping"]
となります。
Dockerfile の命令一覧
ここでは Dockerfile 内で使用できる命令の一部を確認していきます。
全てを確認したい方は適宜ドキュメントなどを確認お願いします。
命令 ①: FROM
Dockerfile でイメージを作る際にベースとなるイメージを指定します。
Dockerfile で記載する時は一番最初に記載します。
命令 ②: RUN
コンテナ上の OS に対して命令を実行します。
shell 形式と exec 形式の二通りの書き方があります。
命令 ③: CMD
コンテナが実行される際にコンテナがデフォルトで実行する命令を記載します。
なお、CMD は Dockerfile では一回しか記載できません。
仮に二つ CMD 命令を書いたとしても、最後の CMD しかイメージ作成時には反映されません。
ちなみに、RUN と CMD はどちらもコマンドを入力するので似ています。
しかし、RUN と CMD は実行するタイミングが違うので注意してください。
RUN はイメージを生成するときに反映され、CMD はコンテナを実行したときに反映されます。
タイミングの違いを見るために、先程作成した ping 入りの Dockerfile をいじってみます。
Dockerfile の RUN 命令を以下のように、ping を実行するコマンドも追加したものに変更してください。
RUN apt-get update && apt-get install -y iputils-ping && ping localhost
そして、docker build -t ping-image2 .でイメージを作成しようとしますが、ping [localhost](http://localhost) が実行されつづけ build が完了しません。
処理を中断したとしても、Docker 的には build が完了していないので、イメージはできていません。
このように、RUN はイメージを作る際に実行するコマンドなので、動かし続ける必要があるものなどを記載するのは適切ではありません。
次に、CMD を試してみましょう。
先程 RUN に記載した ping localhost を削除します。
そして、CMD ping [localhost](http://localhost) という命令を追加してください。
その後、docker build -t ping-image2 .で build すると、RUN に追加した場合と違い build が完了し、イメージが作成されます。
上記イメージをdocker run -it ping-image2でコンテナを起動すると、CMD で指定したping localhostが実行することを確認できると思います。
以上のことから、RUN と CMD の実行タイミングが違うことを確認しました。
RUN はイメージを作る際に実行されるので、パッケージのインストールやファイルのコピーなど処理が完了するコマンドを記載した方が良さそうです。
一方で、CMD はコンテナが起動された時に実行されるので、web サーバー起動など動き続いて欲しいコマンドを指定すると良さそうです。
命令 ④: LABEL
これは Docker イメージの動作に直接影響はしませんが、コンテナに関する情報を付与できます。
命令 ⑤: EXPOSE
コンテナを実行したときに、ポート番号を付与して解放します。
これに設定を行うことで、ホスト OS や他のコンテナから接続することができます。
命令 ⑥: ENV
ENV は環境変数を設定するための命令です。
キーと値を設定することで、環境変数を設定できます。
環境変数を設定した値はdocker inspect で確認できます。
命令 ⑦、⑧: COPY,ADD
COPY と ADD はイメージを build するときにホスト OS 上にあるファイルをコンテナ内のディレクトリにコピーする際に使用します。
どちらもホスト OS ファイルをコンテナにコピーするのは同じですが、各命令は以下の点で異なります。
- COPY はそのままファイルをコピーします。
- ADD はホスト OS の tar や zip などの圧縮ファイルを展開しながら、コンテナにコピーします。
COPY と ADD の書き方は以下のように書きます。
COPY コピー元のパス コピー先のパス
ADD コピー元のパス コピー先のパス
コピー先は絶対パス、相対パスで記載できます。
ただし、相対パスは後ほど記載する WORKDIR 命令からの相対パスになるのは注意してください。
また、コピー元のパスですがルートディレクトリは Dockerfile を build した時のディレクトリになります。
そのため、上記ディレクトリより上の階層を参照することはできないので、ご注意ください。
パスの指定方法によるコピーの違いですが、コピー先がディレクトリの場合コピー元のファイルをコピー先のディレクトリにおきます。
コピー元がディレクトリの場合はコピー元の全ファイルをコピー先におきます。
命令 ⑨: ENTRYPOINT
ENTRYPOINT は CMD 命令と同じように、コンテナを生成したときに実行される命令です。
おおよそ CMD と同じですが、違う部分はdockr runを実行したときにコマンドを指定したとしても、上書きがされず確実に実行できる点です。
そして、ENTRYPOINT は Exec 形式を用いると CMD と組み合わせて使用できます。
例えば以下のような ENTRYPOINT 命令を書きます。
ENTRYPOINT ["/bin/bash","-c"]
こうすることで、docker run -it イメージ を実行した時実質docker run -it イメージ /bin/bash -c を実行していることになります。
そのため、実際にコンテナを実行する時はdocker run -it イメージ pwdだけで、docker run -it イメージ /bin/bash -c pwdを実行したことになります。
現状のままだとdocker runの時に引数を指定しないとエラーが出てしまうので、ここで CMD 命令を使います。
ENTRYPOINT ["/bin/bash","-c"]
CMD ["echo no-value"]
上記のように CMD を使用して、デフォルトの引数を設定すれば、引数を指定せずとも Docker コンテナを起動できます。
命令 ⑩: VOLUME
VOLUME は指定したディレクトリをマウントポイントにして、ホスト OS やコンテナからマウントできるようにします。
ボリューム自体の説明は先程行っているので、ここでは割愛します。
命令 ⑪: WORKDIR
Dockerfile で RUN,CMD,ENTRYPOINT,COPY,ADD の命令で実行する際の基準となるディレクトリを指定するものです。
何度でもこの命令は使用可能で、WORKDIR 命令を書いた際が作業ディレクトリとなるので、一個の Dockerfile で作業ディレクトリを切り替えることができます。
命令 ⑫: ONBUILD
ONBUILD は build 時に実行するコマンドを指定します。
ただし、ONBUILD を記載した Dockerfile を build した時は実行されません。
ONBUILD を記載した Dockerfile をベースにした Dockerfile を build するときに、指定したコマンドが実行されます。
もう少し見ていきます。
まず Dockerfile を二つ用意します。
一つめの Dockerfile には以下のように記載します。
FROM ubuntu
RUN apt-get update && apt-get install -y iputils-ping
ONBUILD RUN echo "This is a onbuild command"
これをdocker build -t onbuild-image .で実行します。
特に何も起きませんが、build は完了します。
二つ目の Dockerfile に以下のコードを記載します。
FROM onbuild-image
CMD echo "Hello World!"
先程 build したイメージを使用して、Dockerfile を構築しています。
ではこの Dockerfile をdocker build -t onbuild-image .で実行します。
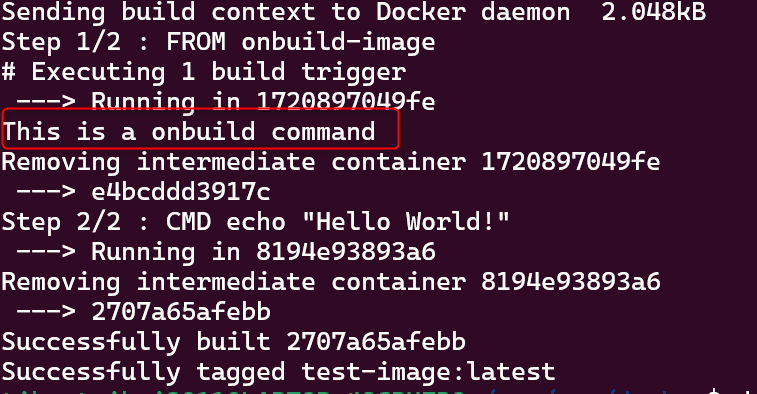
画像赤枠内を見て頂くと、一つ目の Dockerfile で指定したコマンドが実行されていることを確認できます。
このように、ONBUILD があるイメージを用いて、再度イメージを作成した際 ONBUILD で指定したコマンドが実行されます。
ONBUILD の意味は分かりましたので、最後に ONBUILD の利点について記載します。
ONBUILD が活用できるのは、インフラのイメージとアプリケーションのイメージを分ける際です。
基本的にインフラの構成は大きく変わることは少ないです。
とはいえ、アプリ側の都合で conf などの設定が多少変更するなど細かい修正はたまにあります。
その際に、conf の設定を反映するコマンドをインフラ用の Dockerfile に記載すると変更の際に build を行う必要が出ます。
しかし、上記変更で再度 build を行うと別のイメージとして扱われてしまうので不必要にリソースを消費します。
そこで、ONBUILD を用いてコマンドの実行自体はアプリケーションのイメージの方で行うようにします。
それによって、不必要なリソースの消費を抑えることができます。
Dockerfile のキャッシュの扱いについて
Dockerfile では build の時間短縮のために、すでに同様のイメージがある場合はそれを使用する仕組みがあります。
具体的に見ていきましょう。
まず最初に下記の Dockerfile を作成します。
# Dockerfile①
FROM ubuntu
RUN apt-get update && apt-get install -y iputils-ping
CMD /bin/bash
次にもう一つの Dockerfile を下記の通りに作成します。
# Dockerfile②
FROM ubuntu
RUN apt-get update && apt-get install -y iputils-ping
CMD ping localhost
そして、最初作った Dockerfile を build してイメージを作成します。
次に二つ目の Dockerfile を build します。
すると下記のように共通部分は一つ目で生成したものを使用しています。
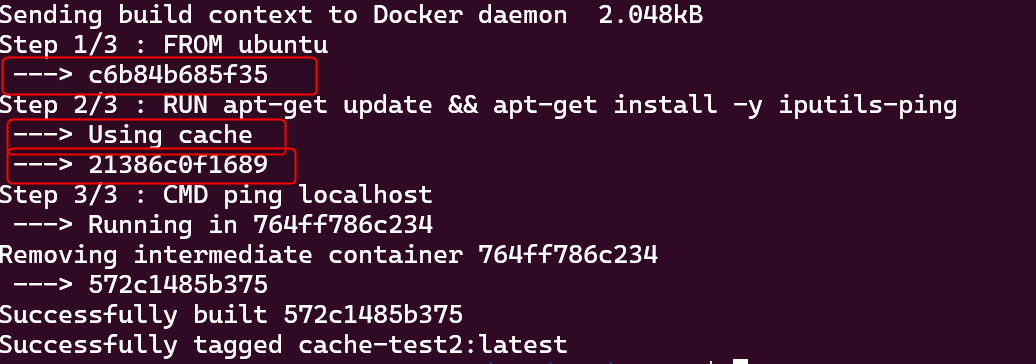
これは Docker 側の機能で、先に同じイメージが作られていれば、再度イメージを作らずに過去のイメージをキャッシュとして再度利用するためです。
構成が同じであれば同じものを使っても動作は変わらないので、リソース効率を上げるために上記機能があります。
このように Docker は build 時にキャッシュを使うことで、処理の高速化やリソースの消費を抑えています。
しかし、キャッシュ機能が弊害となる場合もあります。
それはリポジトリやインストールするアプリケーションが更新された時場合です。
更新されたタイミングで、そのバージョンを反映するために Dockerfile を再度 build します。
ですが、同じコマンドを使用している場合 Docker はキャッシュあるイメージを使用してしまうので、再度 build しても更新が反映されません。
上記問題に対応するために以下の二点が一例として挙げられます。
対応策 ① キャッシュを使わない
一つ目の回避策はそもそもキャッシュを使わずに build することです。
具体的にはdocker build -t イメージ名 . —no-cache=trueと—no-cache オプションを付ければキャッシュを使いません。
ただし、この方法はすべて 1 から build するのでリソースを多く消費しますので、全ての場合において推奨ではないです。
対応策 ② Dockerfile の記述を変更する
二つ目は LABEL 命令を使用して、build の際にキャッシュを使う命令と使わない命令を分けることです。
Dockerfile は先頭から命令を読み込んで、同じ箇所までキャッシュにある同じイメージを使います。
そこで、LABEL などを用いて処理に関わらない命令を置き換えて、build することで該当箇所からはキャッシュを使わないようにできます。
もう少し具体的に見ていきます。
まず、Dockerfile① を再度 build してください。
すでに、イメージが作成されているので全てキャッシュを使用しています。
次に Dockerfile① を次のように変更します。
FROM ubuntu
RUN apt-get update && apt-get install -y iputils-ping
LABEL cacheTest="test"
CMD /bin/bash
これを再度 build してみてください。
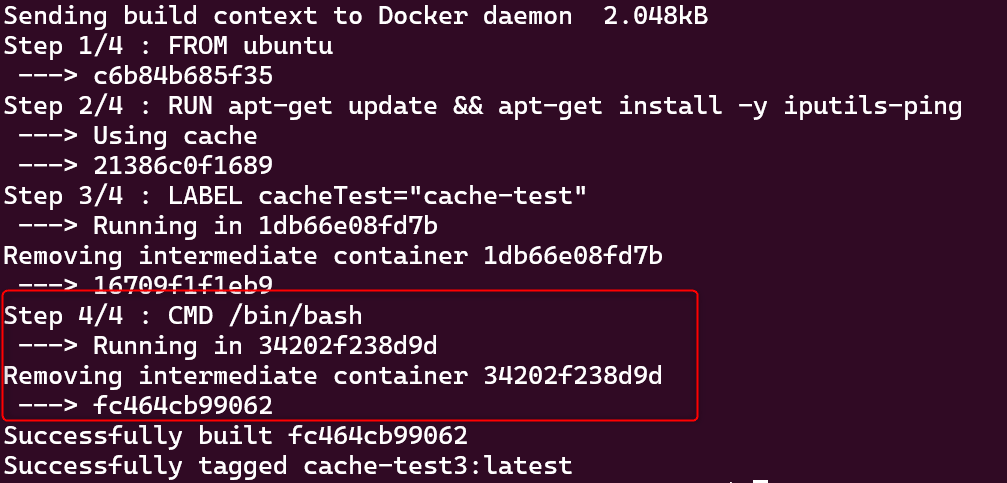
すると先程まではキャッシュを使用していたものが、新たにイメージを再生成しています。
このように Dockerfile 内で、キャッシュを使用する箇所と使用しない箇所を分けることで更新頻度が少なく、ダウンロードに時間がかかるものは先頭のほうに記載して、キャッシュを使用するようにできます。
一方で、更新が必要となるものは LABEL 命令より後に記載して、更新が必要なタイミングで LABEL を書き換えてイメージを再生成することができます。
ここまで Dockerfile についての概要について見てきました。
次からはこの Dockerfile などを用いてもう少し複雑なアプリケーションの構築を行っていきます。
Docker でちょっと複雑なコンテナを作ってみる
この章ではこれまで学んだ内容を活かして、様々なコンテナを作成します。
コンテナ ① ログの保存設定をした Apache コンテナ
ここではログをボリュームに保存する設定が付与されている Apache コンテナを作成します。
手順としては以下のとおりになります。
- Apache の設定を行う httpd.conf を取り出す用の httpd コンテナを作成。この際、ホスト OS 上にマウントしたディレクトリを持たせておく。
- コンテナ内の httpd.conf をホスト OS 上に取り出す。
- 取得した httpd.conf を編集し、ログの出力先をデータボリューム・コンテナのディレクトリに変更する。
- Apache コンテナを作成するために Dockerfile を作成し、build する。
- データボリューム・コンテナを作成する。
- 4 の Docker イメージからコンテナを作成する。
では始めます。
まずは、ホスト OS 側の任意のディレクトリに httpd.conf を保存するディレクトリを作成します。
今回は/root 配下に httpd ディレクトリを作成しました。
その後、docker pull httpdで Docker イメージを pull します。
pull が完了したら、docker run --rm -v /root/httpd/:/tmp/ -it httpd /bin/bashを実行します。
ちなみに、上記コマンドの場合最後に/bin/bash を付与しないとコンテナ内でコマンド操作ができないので注意してください。
また、—rm オプションを設定してコンテナを起動した場合、コンテナを停止した瞬間にコンテナ自体が削除されます。
このコンテナはホスト OS に httpd.conf をコピーするだけのコンテナなので、—rm オプションを付与して起動しています。
コンテナ内に入ったら、cp /usr/local/apache2/conf/httpd.conf /tmp/を実行して、コンテナ起動時に設定したマウントポイントへ httpd.conf をコピーします。
上記完了したら、exitでコンテナを停止して、ホスト OS 上の/root/httpd 内に httpd.conf ファイルがあることを確認します。
httpd.conf を取得したら、任意のエディターで httpd.conf を開きます。
httpd.conf 内にある
CustomLog "logs/access_log" combined
を探し、コメントアウトを外します。
保存したら、Dockerfile を作成し、下記のように記載します。
FROM httpd
COPY ./index.html /usr/local/apache2/htdocs/
COPY ./httpd.conf /usr/local/apache2/conf/httpd.conf
EXPOSE 80
COPY 命令で index.html ファイルを DocumentRoot ディレクトリへコピーしていますが、現在 index.html がないので作成します。
今回は以下の index.html を Dockerfile と同一階層に作成しました。
<h1>Hello Docker</h1>
では、docker build -t apache-image .でイメージを作成します。
イメージを作成したら、docker run -v apachelog-volume:/usr/local/apache2/logs --name=apachelog-container busyboxを実行して、ログ用のデータボリューム・コンテナを作成します。
上記でデータボリューム・コンテナを作成しましたが、ここで一つ疑問が思い浮かびます。
先程 Dockerfile では VOLUME 命令があり、ボリュームコンテナを作成するならこの命令を使用した Dockerfile を使用すれば良さそうでし、実際に作成できると思います。
しかし、Dockerfile を使用してボリュームを設定するとボリューム名がランダムになってしまい、任意の名前を付与できない問題があります。
ボリューム用のコンテナは更新することはめったにないので、Dockerfile でボリュームを作る旨味がなく、ボリューム名がランダムになるという欠点があるので、今回はコマンドで作成しています。
データボリューム・コンテナを作成したら、docker run --volumes-from apachelog-container -p 80:80 -d --name=apache-container apache-imageを実行して、データボリューム・コンテナと紐づけて、ホスト OS の port 番号 80 とコンテナの port 番号 80 をつなげた apache-contaienr という名前のコンテナを作成します。
http://localhost へアクセスすると、「Hello Docker」が表示されていることを確認できます。
ここまでコンテナの作成はできたので、最後にログの確認をします。
なお、データボリューム・コンテナを作成したので、新しいコンテナからでもログを確認できることを確認したいため、先程作成したコンテナは削除します。
docker run --volumes-from apachelog-container -it ubuntu を実行して、コンテナ内に入ったら/usr/local/apache2/logs 内に access_log があれば完了です。
コンテナ ② nginx をリバースプロキシにした Apache コンテナ
ここでは nginx と Apache を組み合わせたリバースプロキシ環境を作成します。
なお、リバースプロキシなどの概念についての記載はありませんので、ご了承ください。
上記リバースプロキシ環境を作るには、以下の二点を考える必要があります。
- Apache は外部へポートを開いていおらず、nginx 介してしか外部ユーザーへのコンテンツ提供をできないようにする。
- nginx と Apache の二つのコンテナで、通信する仕組みを構築する。
では、実際に行っていきます。
まずは、nginx からリバースプロキシ設定に必要な defult.conf ファイルを取得するために、docker run --rm -v /root/rproxy:/tmp -it nginx /bin/bashでコンテナを起動します。
コンテナ内に入ったら、cp /etc/nginx/conf.d/default.conf /tmp/で default.conf ファイルを取得します。
コピー出来たことを確認したら、default.conf をエディターで開きます。
開いたら下記のlocation / という記載がある箇所を探し、proxy_pass と値を追加します。
location / {
# 略
# 下記を追加
proxy_pass http://web-container/;
}
その後以下の Dockerfile を作成し、docker build -t rproxy-image .でイメージを作成します。
FROM nginx
COPY ./nginx.conf /etc/nginx/conf.d/default.conf
EXPOSE 80
次に Apache イメージを作成するために同一階層で、任意の内容が記載された index.html と以下の Dockerfile を追加して、docker build -t web-image .を実行します。
FROM httpd
COPY ./index.html /usr/local/apache2/htdocs/
EXPOSE 80
ここまでコンテナを作成する準備はできたので、次に Docker 上で network を作成して、nginx コンテナと Apache コンテナが通信できるようにします。
docker network create web-networkを実行して、コンテナ同士が同一ネットワークに存在できるような場を作成します。
以上で準備が整ったので、コンテナを起動していきます。
まずdocker run --name=web-container --net=web-network -d web-imageで Apache コンテナを起動します。
この Apache コンテナを起動するコマンドは以下の理由から、オプションなどを付与したりしなかったりを行っています。
① コンテナ名を付与する
nbinx が通信相手とする Apache コンテナだとすぐわかるように、--name=web-containerでコンテナ名を書いています。
②-p オプションは書かない
ポートの紐づけを行う-p オプションですが、このオプションはホスト OS と紐づけを行うときのみ指定します。今回は接続先がコンテナなので、-p オプションは付与しません。
③ ネットワークを設定する
先程作成したネットワークと紐づけを行うために、—net オプションを設定しています。
Apache コンテナは作ったので、nginx コンテナを作成します。
docker run --name=rproxy-container --net=web-network -p 80:80 -d rproxy-image を実行します。
nginx はホスト OS と通信するので、-p オプションを設定しています。また、Apache の時と同様にネットワークの連携をしています。
以上両方のコンテナを作成したら、http://localhost にアクセスして、Apache 側で作成した index.html が表示されていることが確認できると思います。
なお、注意点として Apache 側のコンテナを先に生成してから、nginx 側のコンテナを生成してください。
nginx 側から起動してしまうと、ホスト OS 側とは接続できてもコンテナ側とで接続するコンテナが存在しないためエラーが発生するからです。
以上で、Docker を使ってリバースプロキシの構築を行いました。
コンテナ ③ MySQL を使用したデータベースコンテナ
先ほどまでは、サーバー側の設定を行っていました。
そこで、今回はアプリケーションに欠かせないデータベースを Docker で構築していこうと思います。
これができると、アプリケーション開発へさらに近づいていきます。
なお、今回は MySQL を使う場合欠かせない phpMyAdmin の設定も行います。
では早速行います。
まず MySQL の構築を行います。
任意のディレクトリを作成し、移動します。
今回は/root/mydatabase で作業をします。
移動後、データを保存できるようにするためデータボリューム・コンテナをdocker run -v db-volume:/var/lib/mysql/ --name=db-container busyboxで作成します。
次に phpMyAdmin と接続するために、docker network create mysql-nwでネットワークを作成します。
これで、事前準備は完了なので MySQL コンテナを作成します。
MySQL 用のイメージを作るために、/root/mydatabase 配下に任意のディレクトリ(今回は mysql)を作りし、以下の Dockerfile を作成します。
FROM mysql:8
ENV MYSQL_ROOT_PASSWORD=dbpass01
CMD ["mysqld", "--character-set-server=utf8mb4", "--collation-server=utf8mb4_unicode_ci"]
docker build -t mysql-image .でイメージを作成します。
ちなみに、今回はデータベースの設定ファイルである/etc/mysql/my.cnf をホスト OS に取り出して、設定するのではなくコンテナ起動時に直接設定を追加するようにしています。
また、この後 phpMyAdmin に接続する予定ですが、EXPOSE を設定していません。
これは、公式の MySQL イメージを作成する際は自動で、ポート番号 3306 が解放されるためです。
イメージを作成したら、docker run --volumes-from=db-container --net=mysql-nw --name=mysql-container -d mysql-imageでコンテナを起動します。
コンテナが正常に動作していることを確認したら、docker exec -it mysql-container /bin/bashでコンテナ内に移動します。
なお、docker execはコンテナに対してコマンドなどを実行するときに使用します。
先ほどから、ずっと使用しているdocker runはイメージに対してなので、コマンド自体は似ていても対象が違うのでご注意ください。
コンテナ内に移動したら、mysql -uroot -pdbpass01で MySQL データベースにログインします。
ログインした後、statusを実行して画像赤枠内の部分が utf8mb4 になっていれば正常にコンテナを生成できています。
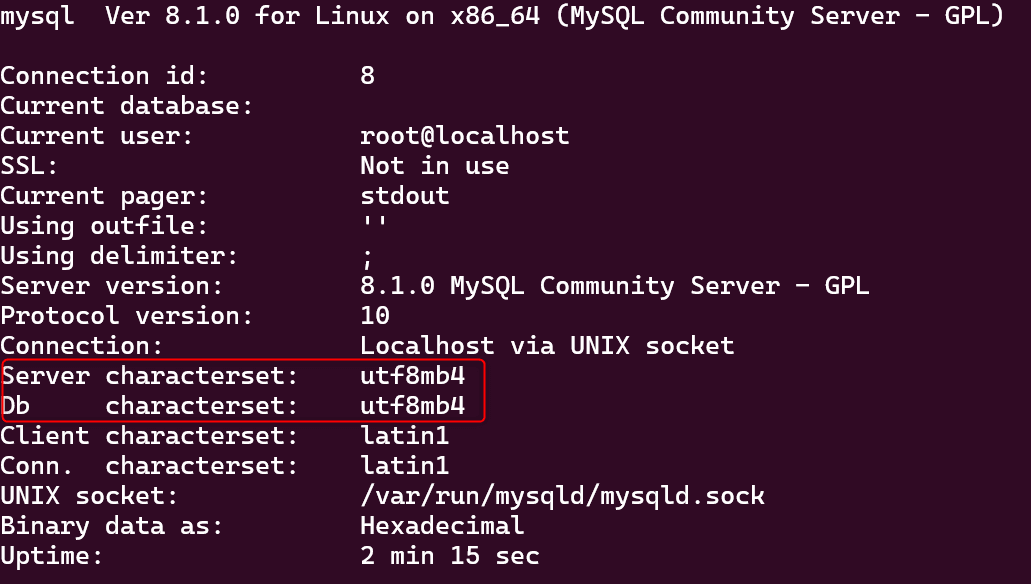
ここまでで、MySQL の設定はできました。
なので、CUI 操作であればデータベースへの操作は可能です。
しかし、実際に使用する際は CUI では運用がしにくいため、GUI でデータベースを操作することが多々あります。
MySQL で GUI 操作する際によく使用されるのが、この後構築する phpMyAdmin です。
具体的な機能についてここでは触れませんが、多様な機能が存在します。
なので、ここからは先ほど作成した MySQL コンテナと phpMyAdmin コンテナでやり取りができるようにします。
まず、/root/mydatabase 配下に phpMyAdmin コンテナ用のディレクトリ(今回は phpmyadmin)を設定し、以下の Dockerfile を作成します。
FROM phpmyadmin/phpmyadmin
ENV PMA_HOST=mysql-container \
PMA_USER=root \
PMA_PASSWORD=dbpass01
なお、phpMyAdmin イメージはデフォルトでポート番号 80 が割り当てられていて、今回はその番号を使用するので EXPOSE を記載していません。
docker build -t pma-image .でイメージを作成します。
イメージを作成後、docker run --net=mysql-nw --name=pma-container -p 8080:80 -d pma-imageで MySQL コンテナが属するネットワークを紐づけつつ、ホスト OS とポートの連携を行いながらコンテナを起動します。
コンテナが生成されているのを確認できたら、http://localhost:8080 にアクセスすると、phpMyAdmin の画面が表示されます。
ここまでデータベースの構築ができたので、最後にコンテナを破棄しても DB の設定が残っていることを確認します。
まず、docker stop mysql-container pma-container でコンテナを停止したら、docker container pruneで停止中のコンテナを全て削除します。
その後、docker run -v db-volume:/var/lib/mysql/ --name=db-container busybox、docker run --volumes-from=db-container --net=mysql-nw --name=mysql-container -d mysql-image、docker run --net=mysql-nw --name=pma-container -p 8080:80 -d pma-imageの順で再度 MySQL コンテナと phpMyAdmin コンテナを起動します。
コンテナ作成後、http://localhost:8080 にアクセスするとコンテナを一度破棄する前に作成したデータベースがそのまま残っています。
以上で、Docker を使ってデータベースの環境構築ができました。
コンテナ ④ Redmine コンテナ
先ほどデータベースのコンテナを作成しました。
これによって、アプリケーションを動かすための準備はかなりできています。
そこで、ここでは Redmine を使って実際にデータベースと接続したアプリケーションをコンテナで構築します。
なお、データベースコンテナは先程作成した MySQL コンテナやディレクトリを使用します。
それでは始めます。
まず、いい加減飽きてきましたが/root/mydatabase 配下に任意のディレクトリ(今回は redmine)を設定し、下記コードを記載した Dockerfile を作成します。
FROM redmine
ENV MYSQL_ROOT_PASSWORD=dbpass01 \
MYSQL_USER=root \
MYSQL_PASSWORD=dbpass01
docker build -t rm-image .でイメージを作成して、docker run --net=mysql-nw --name=rm-container -p 3000:3000 -d rm-imageで MySQL コンテナが属するネットワークとの紐づけとホスト OS のポート番号 3000 との紐づけを行いながらコンテナを起動します。
コンテナが生成されているのを確認したら、http://localhost:3000 にアクセスすると、Redmine のトップページにアクセスできます。

以上で、コンテナを使用してサーバーの構築やアプリケーションの環境構築まで完了しました。
Docker のコンテナをまとめて管理する ~Docker Compose を使ってみよう~
ここまでで、Docker の入門的なことは一通りやってきたと思います。
そのため、コンテナの操作自体はある程度馴染んできました。
しかし、同時にいちいちコンテナごとに Dockerfile を作成して build して、その後順番にdokcer runでコンテナを起動するのは面倒だと感じます。
個人で遊ぶくらいなら面倒で済みますが、業務で使用している場合仮にサーバーが停止してしまい、コンテナの再起動が必要となると非常に大変です。
順番を気にしながら一つ、一つコンテナを起動していく必要があるためです。
このようにコンテナが増えて行くと管理が非常に大変となります。
Docker Compose は上記のようなコンテナが増えることによる、管理の問題を解消するために存在します。
具体的な書き方などは後ほど記載しますが、Docker Compose を使えばコンテナを少ないファイルでまとめて管理でき、一括操作を行うことができるようになります。
よって、コンテナが増えたとしても管理の負担がそれほど大きくなりません。
Docker Compose の利点が見えて来たので、具体的に書き方を見ていきます。
なお、ここでは「Docker でちょっと複雑なコンテナを作ってみる」の内容を Docker Compose で表現するようにします。
そのため、Docker Compose に関わる構文は解説しますが、コンテナの内容自体の説明はしませんのでご了承ください。
また、Docker Compose のインストールについても調べれば数多の良記事が出てくるので、ここでは記載しません。
では始めます。
余談 Dockerfile と Docker Compose の違い
これまで作ってきた Dockerfile と Docker Compose の違いを軽く説明します。
下記の画像のように Docker Compose は Dockerfile の機能も備えた、Docker の拡張機能です。

Docker コンテナ構築手順 ② Docker Compose 編より引用
Dockerfile は Docker Hub からイメージを取得し、独自の設定を反映させ一つのコンテナイメージを作るためのファイルです。
そのため、Dockerfile が関わるのはイメージの作成までです。
一方で、Docker Compose は「docker-compose.yml」という定義ファイルを用いて、以下の内容を複数のコンテナに対して行うことができます。
- Dockerfile が行うイメージを取得するための build
- Volume の設定
- オプションを設定しながらのコンテナ生成
- etc…
以上が Dockerfile と Docker Compose の違いです。
Docker Compose は Dockerfile の機能も含め、Docker でする様々な機能を「docker-compose.yml」に集約できます。
そのため、現場などで Docker を使用する場合は Docker Compose でコンテナを管理すべきです。
実際、ネット検索で「任意のアプリケーション docker 環境構築」で調べるとほぼほぼ Docker Compose を使用した内容しか出てきません。
それほどコンテナを扱う際に、Docker Compose を使用することは当たり前となっているのでしょう。
今回は Docker の概要を学ぶために、docker コマンドに始まり Dockerfile について見ていきましたが、開発するときは Docker Compose で管理するのが当たり前と言えそうです。
Docker Compose を動かしてみる
ここでは「Docker でちょっと複雑なコンテナを作ってみる」で作ったコンテナを Docker Compose で表現する前に、単純な ubuntu コンテナを Docker Compose で作ってみます。
まず、任意のディレクトリ(今回は/root/docker-compose)に docker-compose.yml を作成します。
作成したら、下記のコードを記載します。
version: "3"
services:
ub-test:
image: ubuntu
簡単にそれぞれの内容を見ていきます。
まず version ですが、これは docker-compose.yml のバージョンです。
特に理由が無ければ 2023/09 時点で 3 が最新なので、3 を指定します。
services はサービスを定義するブロックです。
services ブロックに所属するものは基本的にコンテナ定義となるので、services はコンテナ定義の開始を示すためのコードという認識で良さそうです。
ちなみに、docker-compose.yml はインテンドで階層を表します。
なので、ub-testはservicesの子供で、image:ubuntuはservicesの孫でub-testの子供となります。
ub-test はコンテナ名です。
ただ、実際に作成されるコンテナ名は「YAML のディレクトリ名コンテナ名連番」となる点はご注意ください。
image はコンテナが元とするイメージを指定します。
今回は ubuntu イメージを設定しています。
これで準備ができたので、docker-compose.yml があるディレクトリで、docker-compose upを実行します。
docker ps -a かdocker-compose psで「docker-compose_ub-test_1」という名前のコンテナが確認できれば完了です。
次に、ubuntu の/bin/bash を実行してみます。
これは、-it オプションとコマンドに/bin/bash を設定してコンテナを生成するということです。
docker-compose.yml の場合、-it オプションに相当する命令がtty:trueとstdin_open:true です。
また、コマンドを指定する場合はcommandを使用します。
これは Dockerfile の CMD 命令と同じ認識で良さそうです。
では、実際に docker-compose.yml に反映します。
version: "3"
services:
ub-test:
image: ubuntu
tty: true
stdin_open: true
command: /bin/bash
記載したら、docker-compose run ub-testでコンテナを起動して、コンテナ内に入ったことを確認できれば完了です。
なお、docker-compose upとの違いですが、docker-compose upは定義ファイルに書かれた全体を起動しますが、docker-compose runは特定のコンテナを起動します。
docker-compose upではコンテナ内に入れないので、今回はdocker-compose runを使用しています。
ここまでで、Docker Compose について軽く触れたので、次からは「Docker でちょっと複雑なコンテナを作ってみる」のコンテナを Docker Compose で表現していきます。
「Docker でちょっと複雑なコンテナを作ってみる」を Docker Compose で表現する
Docker Compose で表現するコンテナ ① ログの保存設定をした Apache コンテナ」
ログを複数のコンテナで確認できるようにする前に、Apache を動かせるか確認します
なお、docker-compose.yml を動かす前に、設定ファイルの httpd.conf と画面表示用の index.html は用意しておきます。
詳細は「コンテナ ① ログの保存設定をした Apache コンテナ」を参考にしてください。
docker-compose.yml を作成し、以下のコードを記載します。
version: "3"
services:
web-container:
image: httpd
# docker run における-pに相当
ports:
- "80:80"
# DockerfileのEXPOSEに相当
expose:
- 80
# ローカルのファイルをコンテナへマウント
volumes:
- ./index.html:/usr/local/apache2/htdocs/index.html
- ./httpd.conf:/usr/local/apache2/conf/httpd.conf
volumes についてですが、docker-comopse.yml には Dockerfile の COPY に代わるようなコマンドがありません。
そのため、docker-compose.yml ではその代替方法としてファイル単位でコンテナへマウントさせる形がとられます。
すなわち、やりたいことは Dockerfile における以下のコードと同じです。
COPY ./index.html /usr/local/apache2/htdocs/
COPY ./httpd.conf /usr/local/apache2/conf/httpd.conf
ここまでできたら、docker-composer up -dでコンテナを生成します。
なお、今回は web サーバーなので、-d オプションを使用してバックグラウンドで実行させます。
http://localhost にアクセスして、先程作成した index.html が表示されている確認します。
そして、docker-compose exec web-container /bin/bashでコンテナ内に入り/usr/local/apache2/logs/access_log が存在して、ログを確認できればいったん完了です。
Docker Compose で Apache を起動できたので、次は他のコンテナからもログを確認できるようにするためのデータボリューム・コンテナを設定していきます。
まず、dokcer-compose downという便利なコマンドを使用して、コンテナの停止と削除を行います。
コンテナを停止・削除したのは、コンテナを起動したまま docker-compose.yml を編集するとコンテナの状態が変化することになり、正しく処理できなくなるためです。
なので、docker-compose.yml 周りをいじる時はまずコンテナを止めてから行うようにします。
コンテナを止めたら、docker-compose.yml の services ブロック配下に以下のコードを追記します。
log-container:
image: busybox
volumes:
- log-volume:/usr/local/apache2/logs/
これは、データボリューム・コンテナを作る際に実行していたdocker run -v apachelog-volume:/usr/local/apache2/logs --name=apachelog-container busyboxを dokcer-compose.yml で表現したものです。
次に以下の新しいブロックを作成します。
volumes:
log-volume:
docker コマンドではデータボリューム・コンテナを作る際に、データボリュームが無ければそのままボリュームも作成してくれました。
しかし、docker-compose.yml では合わせてボリュームを作成してはくれないので、明示的に volume を作成するブロックを選択する必要があります。
そして、web-container ブロックに以下のコードを追加します。
volumes_from:
- log-container
web-container にこのコードを追加することで、データボリューム・コンテナと紐づけを行う—volumes-from オプションを設定しながらコンテナを生成します。
全体のコードは以下の通りです。
version: "3"
services:
web-container:
image: httpd
ports:
- 80:80
expose:
- 80
volumes:
- ./index.html:/usr/local/apache2/htdocs/index.html
- ./httpd.conf:/usr/local/apache2/conf/httpd.conf
volumes_from:
- log-container
log-container:
image: busybox
volumes:
- log-volume:/usr/local/apache2/logs/
volumes:
log-volume:
では、docker-compose up -dで再度起動し、http://localhost にアクセスします。
その後、docker-compose downでコンテナを停止・削除して、再度docker-compose up -dで起動し、docker-compose exec web-container /bin/bashでコンテナ内に入りログを見ます。
すると、一つ前のコンテナでアクセスした際のログが確認できます。
Docker Compose で表現するコンテナ ② nginx をリバースプロキシにした Apache コンテナ
続いては「コンテナ ② nginx をリバースプロキシにした Apache コンテナ」を dockr-compose.yml でコンテナを生成します。
ただ、今回は「Docker Compose で表現するコンテナ ① ログの保存設定をした Apache コンテナ」」の時と同様に行うのではなく、docker-compose.yml と Dockerfile を用いて行っていきます。
これによって、コンテナ内の設定は Dockerfile で、コンテナの起動やコンテナ間の接続については docker-compose.yml でとファイルの分割を行いながら管理ができます。
コンテナ内の設定がかなり多い場合、docker-compose.yml のコードが長くなってしまうので、Dockerfile との分割方法を把握しておくのは利点がありそうです。
では始めます。
まず、「コンテナ ② nginx をリバースプロキシにした Apache コンテナ」をもとに nginx 側は Dockerfile と proxy_pass 追記した defautl.conf を準備して、特定のディレクトリに格納します。
Apache 側も、nginx の設定を入ったディレクトリと同階層にディレクトリを作成し、同様に Dockerfile と画面表示用の index.html を準備します。
その後、各ディレクトリの一つ上に docker-compose.yml も作成しておきます。
全体の構成は以下の通りです。
.
├── docker-compose.yml
├── httpd
│ ├── Dockerfile
│ └── index.html
└── rproxy
├── Dockerfile
└── default.conf
docker-compose.yml に以下のコードを記載します。
version: "3"
services:
rproxy-container:
build: ./rproxy
ports:
- "80:80"
web-container:
build: ./httpd
今回重要なのは build の部分です。
この build ブロックは Dockerfile が存在するパスを指定します。
これによって Dockerfile を読み込んで実行するので、イメージを作成する作業は Dockerfile に任せることができます。
以上を行えば、docker-compose up -d でコンテナを生成して、http://localhost にアクセスしたら httpd ディレクトリ配下の index.html が表示されます。
Docker Compose で表現するコンテナ ③ MySQL を使用したデータベースコンテナ&Redmine コンテナ
最後に「コンテナ ③ MySQL を使用したデータベースコンテナ」と「コンテナ ④ Redmine コンテナ」を Docker Compose で実行します。
とはいえ、大体やることは同じなので先にコード全体を示します。
version: "3"
services:
db-container:
image: busybox
volumes:
- db-volume:/var/lib/mysql
mysql-container:
image: mysql:8
environment:
- MYSQL_ROOT_PASSWORD=dbpass01
- MYSQL_DATABASE=redmine
command: --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
depends_on:
- db-container
volumes_from:
- db-container
restart: always
pma-container:
image: phpmyadmin/phpmyadmin
environment:
- PMA_HOST=mysql-container
- PMA_USER=root
- PMA_PASSWORD=dbpass01
ports:
- 8080:80
depends_on:
- mysql-container
restart: always
redmine-container:
image: redmine
environment:
- MYSQL_ROOT_PASSWORD=dbpass01
- MYSQL_USER=root
- MYSQL_PASSWORD=dbpass01
ports:
- 3000:3000
depends_on:
- mysql-container
restart: always
volumes:
db-volume:
注目する点は depends_on ブロックと restart ブロックです。
environment ブロックは新しく出てきましたが、コード的に環境変数を設定するものだと推測できるので、詳しい説明は割愛します。
まず、depends_on ブロックについてです。
docker-compose.yml は複数のコンテナを起動しますが、デフォルトでは起動順は決まっておらず順不同です。
しかし、今回の設定では MySQL コンテナが起動する前にデータボリューム・コンテナが存在しないとエラーが発生し、コンテナが起動できません。
そのため、コンテナの起動順を指定する必要があります。
そこで使うのが depends_on ブロックです。
このブロックの値にコンテナ名を指定することで、指定したコンテナが起動した後に、コンテナ起動を実行する処理を追加できます。
今回は mysql-container にdepends_on:db-containerを記載しているので、データボリューム・コンテナが起動した後にコンテナ起動が始まるので、エラーが発生しにくいです。
ただし、depends_on ブロックはあくまでも起動のタイミングをずらすだけであって、depends_on ブロックで指定したコンテナの作成が完了した後にコンテナ起動するわけではありません。
なので、データボリューム・コンテナの作成が完了していないのに mysql-container の起動が始まってしまい、エラーが発生する可能性は 0 ではありません。
上記状況の対処法としては、mysql-container を再起動する方法があげられます。
そこで活用できるのが、restart ブロックです。
restart ブロックはコンテナが異常などで停止した場合に、再度起動するオプションです。
今回は restart ブロックに always を指定しており、エラーが発生したら都度再起動するようにしています。
上記設定のおかげで、少なくともデータボリューム・コンテナの作成が完了していないことによるエラーは無くなります。
以上補足でした。
では、docker-compose up -dでコンテナを起動すると、http://localhost:8080 で phpMyAdmin に、http://localhost:3000 で redmine にアクセスできることが確認できます。
ついでに、Dockerfile を使用したバージョンの docker-compose.yml も記載しておきます。
それぞれの Dockerfile の中身は「コンテナ ③ MySQL を使用したデータベースコンテナ」と「コンテナ ④ Redmine コンテナ」で記載したものを使用しています。
version: "3"
services:
db-container:
image: busybox
volumes:
- db-volume:/var/lib/mysql
mysql-container:
build: ./mysql
depends_on:
- db-container
volumes_from:
- db-container
restart: always
pma-container:
build: ./phpmyadmin
ports:
- 8080:80
depends_on:
- mysql-container
restart: always
redmine-container:
build: ./redmine
ports:
- 3000:3000
depends_on:
- mysql-container
restart: always
volumes:
db-volume:
おわりに
今回は Docker 周りについて色々と見ていきました。
調べていく中で、様々な機能が Docker にはあったので、まだまだ全然素人からは抜け出せていないなと感じました。
とはいえ、以前よりも Dockerfile や docker-compose.yml が何をしているかは分かるようになったので、一歩前進です。
コンテナ自体はとても便利な技術なので、引き続き使い方などを学んでいきあわよくば Kubernetes にも触れていこうと思います。
かなり長文になってしまいましたが、ここまで読んでいただきありがとうございました。
Discussion