生成AIを活用したGitHubイシューの効率的な検索・生成術
はじめに - GitHubイシュー検索の課題
GitHubのイシューは、プロジェクト管理において非常に重要な役割を果たしています。
バグ報告、機能要望、タスク管理など、多岐にわたる用途で活用されていますが、イシューの数が増えてくると欲しい情報を見つけるのが困難という課題があります。
私自身、GitHubの標準検索機能を使っていて、以下のような限界を感じることがありました:
- キーワード検索の精度の問題:単純なキーワードマッチングでは、文脈を理解した検索ができないことがあります
- 複雑な検索条件の組み合わせの難しさ:AND/OR条件を駆使しても、求めている情報にたどり着けないことがあります
- 似たような問題の発見の困難さ:既に報告されている類似イシューを効率的に見つける方法が限られています
- 関連性の把握の難しさ:イシュー間の関連性や背景情報を考慮した検索ができれば便利です
こういった状況から、知らずに同じ問題を重複して報告してしまったり、既存の解決策を見落としたりすることがあります。
これは開発者自身の時間の無駄になるだけでなく、リポジトリ管理者への負担という面でも大きな問題なので、今回はこのイシューの扱いについて自分がやっていることと記事にしました。
解決アプローチ:生成AI + ローカルデータ活用
これらの課題を解決するため、生成AIとローカルデータを組み合わせたアプローチを試してみました。
このアプローチでは、GitHubのイシューデータをローカルに取得し、生成AIの言語理解能力を活用して、より詳細に検索などができるようにしました。
なぜこの手法を選んだのか
GitHub APIを使った直接のアクセスや、GitHub Copilotなどの専用ツールも存在します。
ただ、以下の理由から今回のアプローチを選びました:
- 手軽さと導入のしやすさ:今回のやり方は特別なAPIキーや複雑な設定が不要です
- カスタマイズの自由度:自分のニーズに合わせて検索条件や出力形式を調整できます
- プライバシーとセキュリティ:センシティブなデータをAPI経由で外部サービスに送信する必要がありません。なので、色々なケースで拡張できるかと思います。
- コスト効率:既存の生成AIサービスを活用するため、追加のサブスクリプションが不要です
MCPやAPIを使った連携も検討しましたが、より多くの人が気軽に試せるよう、シンプルな方法を優先しました。(後は実際に組むのがちょっと面倒だったのもあります…)
イシューデータの収集・準備
実際にイシューデータを収集し、生成AIで活用する方法を詳しく見ていきます。
前提条件
このアプローチを試すには、以下のものが必要です:
- GitHub CLIのインストール
- 対象リポジトリへのアクセス権限
- 任意の生成AIサービス(Claude, ChatGPT, Bard など)へのアクセス
GitHub CLIの設定と認証
まず、GitHub CLIをインストールし、ghコマンドを使用するために認証を行います。
Mac OSであれば、brew install ghでインストールできると思います。
Windowsであれば、winget install --id GitHub.cliでインストールができると思います。
Linuxなどについては、ドキュメントに方法が記載されているので、それを元にインストールをお願いします。
GitHub CLIをインストールして、ghコマンドが使えるようになったら、以下のコマンドを実行します。
gh auth login
すると、認証する方法や認証プロトコル、認証する場所を聞かれますので都度やりたい選択肢を選びます。
今回は、以下の選択をしています。

上記にしてEnterを押すと、ブラウザ上でデバイスコードを入力するGitHubの画面が開きます。
開くと以下の画面が表示されるので、認証したいアカウントを選びます。
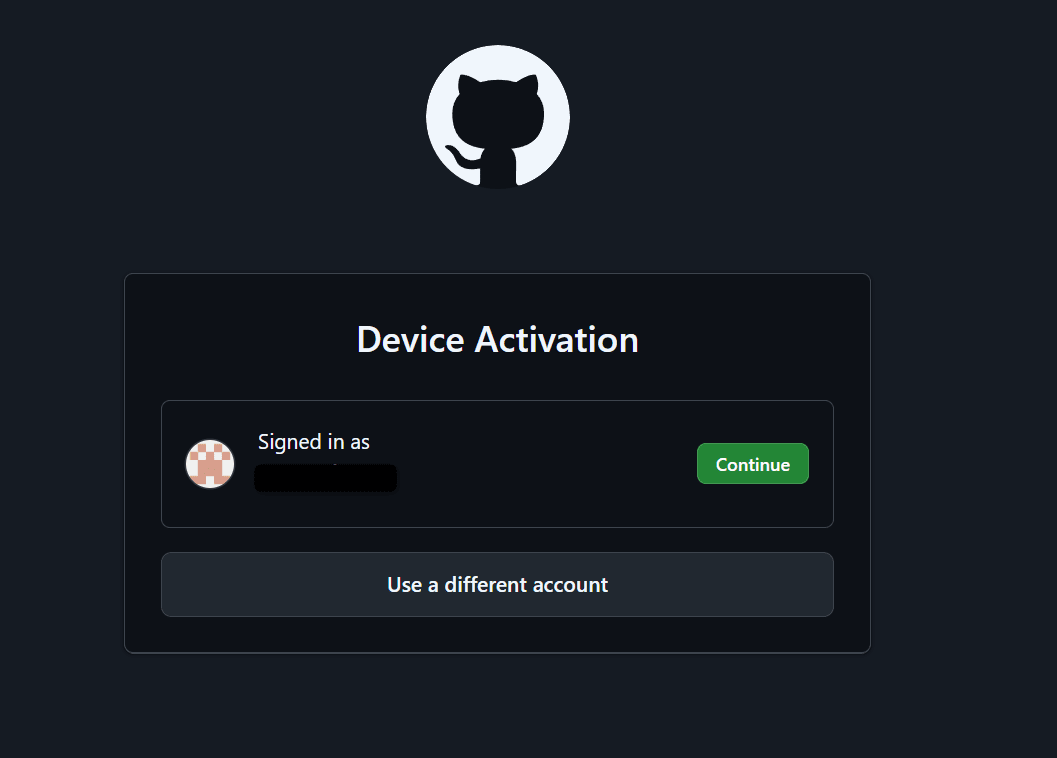
なお、WSL上ではEnterでブラウザが立ち上がらなかったので、その場合はターミナルに書かれている「https://github.com/login/device」に自分でアクセスしてください。
アカウントを選ぶと以下のようにコードを入力する画面になるので、「 First copy your one-time code:」の後に書かれたコードをコピペします。
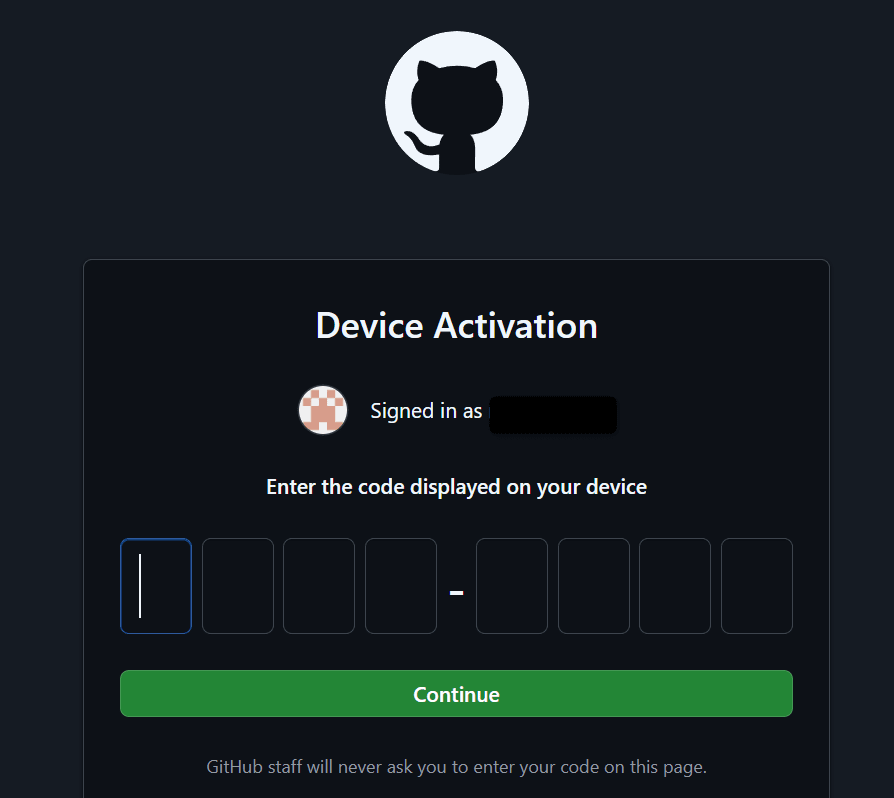
コードを入力後、連携する権限などが書かれた画面が表示されるので、問題なければ「Authorize github」をクリックします。
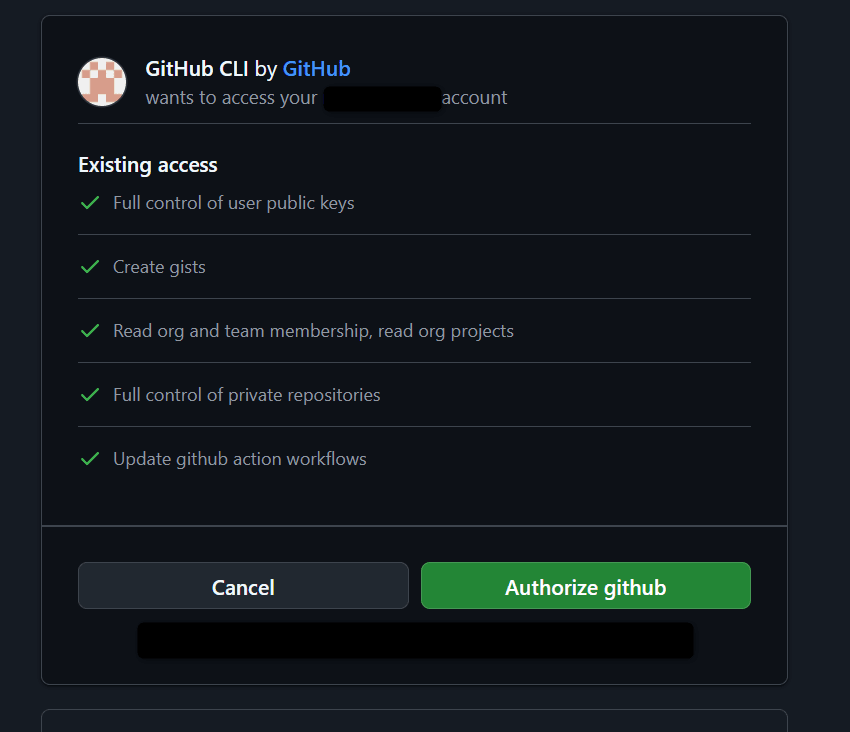
最終的に以下のような形にターミナルがなっていれば、準備は完了かと思います。
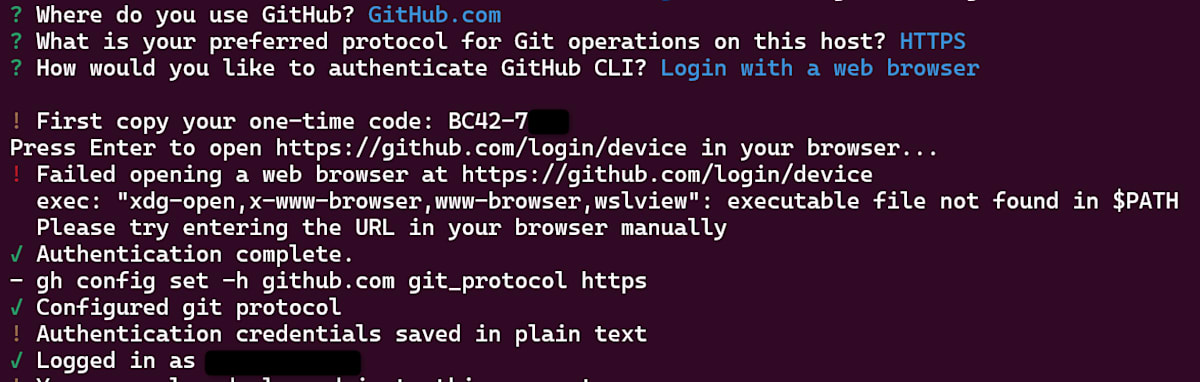
リポジトリのクローン
すでにご存知の方は読み飛ばしてください。
イシューを調べたいリポジトリにアクセスをします。
アクセスをしたら、Codeボタンをクリックし、表示されているURL横のクリップボードをクリックしてURLをコピーします。
コピー後、コードを配置したいディレクトリでgit clone リポジトリのURLでコードをクローンしてください。
諸事情でGitコマンドが使えない場合は、ZIPファイルをダウンロードしてそれを解凍してください。
データ収集コマンドの詳細解説
ここまででイシューを集める準備は完了したので、実際に集めていきます。
まず、先程クローンしたリポジトリのディレクトリ配下に移動します。
そこで、GitHub CLIを使って、リポジトリのイシューデータを収集します。基本的なコマンドは次のとおりです:
gh issue list -s all --json number,title,body,comments -q '[.[] | {issue_number: .number,issue_title: .title,issue_body: .body,comment_bodies: [.comments[].body]}]' -L 100 > issues.json
このコマンドをカスタマイズするための各オプションを軽く解説します:
基本的なオプション
-
gh issue list: GitHubイシューの一覧を取得するコマンド -
-s all: すべての状態(open, closed)のイシューを取得。-s openとすると未解決のイシューのみ取得 -
-L 100: 取得するイシューの最大数(この例では100件。必要に応じて調整可能) -
> issues.json: 出力結果をJSONファイルに保存
JSONデータの形式を指定するオプション
-
-json number,title,body,comments: 取得するフィールドを指定-
number: イシュー番号 -
title: イシューのタイトル -
body: イシューの説明文 -
comments: イシューに対するコメント
-
-
q '[.[] | {...}]': jqクエリで出力形式を整形-
.[]: 配列の各要素に対して処理を行う -
{...}: 出力するJSONオブジェクトの構造を定義
-
追加のフィルタリングオプション
イシューを絞り込むための追加オプションも使用できます:
# 特定のラベルが付いたイシューのみ取得
gh issue list -s all --json number,title,body,comments -q '...' --label "bug" > bug_issues.json
# 特定の期間に作成されたイシューのみ取得
gh issue list -s all --json number,title,body,comments -q '...' --created ">2025-03-01" > recent_issues.json
# 特定のユーザーが作成したイシューのみ取得
gh issue list -s all --json number,title,body,comments -q '...' --author "username" > user_issues.json
より詳細なデータを取得するカスタマイズ
イシューに関する追加情報(ラベル、アサイン情報、作成日時など)も取得したい場合は、JSONフィールドを拡張できます:
gh issue list -s all --json number,title,body,comments,labels,assignees,createdAt,updatedAt -q '[.[] | {issue_number: .number,issue_title: .title,issue_body: .body,comment_bodies: [.comments[].body],labels: [.labels[].name],assignees: [.assignees[].login],created_at: .createdAt,updated_at: .updatedAt}]' -L 100 > detailed_issues.json
このように、GitHub CLIを使用することで、イシューデータを柔軟にカスタマイズして取得できます。
出力されるJSONの構造
コマンドを実行すると、以下のような構造のJSONファイルが生成されます:
[
{
"comment_bodies": [
"イシューに対するコメント1の本文",
"イシューに対するコメント2の本文"
],
"issue_body": "イシューの本文",
"issue_number": 1,
"issue_title": "イシューのタイトル"
},
{
// 2つ目のイシュー
}
]
より詳細なデータを取得した場合は、次のような構造になります:
[
{
"assignees": [
"username1",
"username2"
],
"comment_bodies": [
"コメント1の本文",
"コメント2の本文"
],
"created_at": "2025-05-15T10:30:45Z",
"issue_body": "イシューの詳細な説明...",
"issue_number": 42,
"issue_title": "機能Aが特定の条件下で動作しない",
"labels": [
"bug",
"priority-high"
],
"updated_at": "2025-05-20T14:22:33Z"
}
]
このJSON形式は、イシュー番号、タイトル、本文、およびすべてのコメントを含んでおり、生成AIが文脈を理解するのに十分な情報を提供します。
生成AIを活用した検索・分析
イシューデータを収集したら、次は生成AIを使って検索・分析を行います。
ファイルアップロードと基本的な使い方
多くの生成AIサービス(Claude, ChatGPT)では、直接ファイルをアップロードして参照させることができます。
なので、先程作成したjsonファイルを生成AIにアップします。
後は、適宜知りたい情報をプロンプトとして記載していきます。
今回手法を活用したケースの紹介
ここでは実際に活用したケースを見ていきます。
活用ケースとしては、以下の通りです。
活用ケース:新規イシュー作成前のチェック
シナリオ:Cookieの扱いについて議論されたことがあるかをチェックしたい
アプローチ:
- 既存のイシューで当該Cookieを話題にしたものを検索させる
- 求めるものではなかったので、疑問点をまとめ再度検索をさせる
- 関連するイシューがなかったので、疑問点を踏まえてイシューを作成させる
実際の生成AIとのやり取りはこちらに展開しておきますので、気になった方は参照ください。
対象のリポジトリはDBSCについてのリポジトリです。
DBSCが失敗した時のために、フォールバック用の有効期限が長いCookieを使用するというケースがあるのですが、その取り扱いについてシューがないかを探していました。
なので、まず先程紹介したやり方でイシューを集め、以下のプロンプトを記載しました。
添付したファイルはDBSCについてのイシューとそれに対するコメントがまとまったものです。
この中で、DBSCを開始する前に発行する有効期限の長いCookieの取り扱いについて話をしたものはありますか?
有効期限が長いCookieについて言及しているイシューはあり、そのイシューについて概要などを説明してくれました。
しかし、その内容は自分の知りたいことではなかったので、次のように再度質問してみました。
了解です。
では以下の内容をイシューとして起票したいので一緒に考えて。
* DBSCを開始する前に発行する有効期限の長いCookieについて
* DBSCによる有効期限が短いCookieに変更後、ブラウザを閉じるとする。
* その後、少ししてブランチを開き再度アプリを起動すると有効なCookieは存在していない。
* また、ブラウザを閉じているのでCookieの再発行の処理も走らない
* なので、再認証を求める必要が出てしまう。
* このことから、よくあるアプリはブラウザを閉じても数日は認証せずアプリを使用できるが、DBSCを設定すると都度認証が必要になる可能性が高い。
* 上記に対応するために、アプリにアクセスした最初は有効期限が長いCookieを使用し、その有効性が確認できればDBSCによるCookieに変更することが求められると考えている。
* ただ、最初に有効期限が長いCookieを使用してしまうと、Cookieの盗難の問題が発生してしまう。
* このような、一回ブラウザを閉じて、再度ブラウザを開きアプリにアクセスした時、ユーザーへ再認証を都度求めない要件はあると思います。
* 上記のような要件が求められるアプリに対してDBSCを設定する場合、どのようなアプローチが適切なのでしょうか。
* そして、そもそもこのようなアプリにDBSCは必要なのでしょうか。
とりあえず、似たようなことを話題にしているイシューがあるかを探して。
結果、自分の疑問点に一致するイシューはないとの回答でした。
実際に自分で検索してみても、ブラウザを閉じて再度開いた後有効期限の長いCookieをDBSCの文脈でどう扱うか言及した内容はなさそうでした。
そのため、疑問点を解消するため・DBSCとしてどういう方向性が正なのかを話したいと思い、生成AIの力を借りてイシューを作成しました。
作成したイシューは以下の通りです。
この手法を使用することで、ある程度自分の中で話題にしたことがないイシューだと確信を持てた状態で起票することができました。
制限事項と対処法
ここまで活用方法を見てきましたが、このアプローチにも制限事項があります。
主な課題と一応の対処法を紹介します。
大量イシューがある場合の対応
課題: 大規模リポジトリでは、イシュー数が数千に達することもあり、一度に全データを取得・処理することが難しい場合があります
対処法:
効率的なデータ収集戦略
イシューが多い場合は、以下のようなデータ収集戦略が効果的です:
- 期間ごとの分割取得:
# 2025年1月〜3月のイシュー
gh issue list -s all --json number,title,body,comments -q '...' --created "2025-01-01..2025-03-31" > issues_q1_2025.json
# 2025年4月〜6月のイシュー
gh issue list -s all --json number,title,body,comments -q '...' --created "2025-04-01..2025-06-30" > issues_q2_2025.json
- 状態別の取得:
# オープン状態のイシュー
gh issue list -s open --json number,title,body,comments -q '...' > open_issues.json
# クローズ状態のイシュー
gh issue list -s closed --json number,title,body,comments -q '...' > closed_issues.json
- ラベル別の取得:
# バグに関するイシュー
gh issue list -s all --json number,title,body,comments -q '...' --label "bug" > bug_issues.json
# 機能要望に関するイシュー
gh issue list -s all --json number,title,body,comments -q '...' --label "enhancement" > feature_issues.json
- 複合フィルタの使用:
# 重要度の高いオープンバグ
gh issue list -s open --json number,title,body,comments -q '...' --label "bug,priority:high" > high_priority_bugs.json
生成AIのファイルサイズ制限への対応
多くの生成AIサービスには、アップロードできるファイルサイズに制限があります。
実際に、protobufのイシューを全部(約6500件)集めて、それをClaudeに渡しましたが、Proプランでは容量制限に引っかりました。
これを回避するための方法として:
データ量の削減:
# コメントを除外して軽量化
gh issue list -s all --json number,title,body -q '[.[] | {issue_number: .number,issue_title: .title,issue_body: .body}]' > issues_no_comments.json
# 最新の100件のみに限定
gh issue list -s all --json number,title,body,comments -q '...' -L 100 > recent_issues.json
上記のように必要な情報を選択して、生成AIに渡すデータを軽量化すると対応できます。
ただ、これらのようなテクニックを駆使することが必要なら、そもそもの手軽にという本懐から外れている気もします。
なので、すべてのプラン・リポジトリに対して使用できる手法というわけではないのが、注意がいりそうです。
おわりに - 開発コミュニティへの貢献
今回はghコマンドと生成AIの組み合わせで、イシューの検索などがより高機能でできるかもしれないという記事を書きました。
生成AIとGitHub CLIを組み合わせたこのアプローチは、イシュー管理の効率を向上させる可能性があると思います。
このメリットは個人の作業効率だけでなく、同じイシューが乱立しないといったOSSの管理者側にもメリットがあるかと思います。
いつも丁寧に返信とかくれるOSSを作成・管理している人たちが「また解決済みの同じイシューが来てる…」と感じることを軽減させるのに、貢献できたらと思います。
とはいえ、やはりイシューを見てもらうということ自体、管理者側に負担を強いることにはなります。
なので、今回イシューを作る手法的な障壁が低くなったとはいえ、何でもかんでもイシューを作るべきではないと感じます。
重複したイシューがないことを確認した上で、そもそもイシューにすべき話なのかなどを考える必要があります。
そして、イシューに対して反応してくれた際には、感謝を示すことを忘れずに行っていこうと思います。
ここまで読んでいただきありがとうございました。
Discussion