API Gateway×LambdaでS3のデータをzip圧縮してフロントエンドにバイナリとして返す
API Gateway + Lambdaでバイナリデータを扱ったり、zipデータを扱うのに色々な壁にぶち当たったのでまとめておきます。
本記事のゴール
フロントエンドからAPI Gatewayにリクエストを送り、LambdaでS3にあるデータをzip圧縮し、ダウンロードできるようにします。
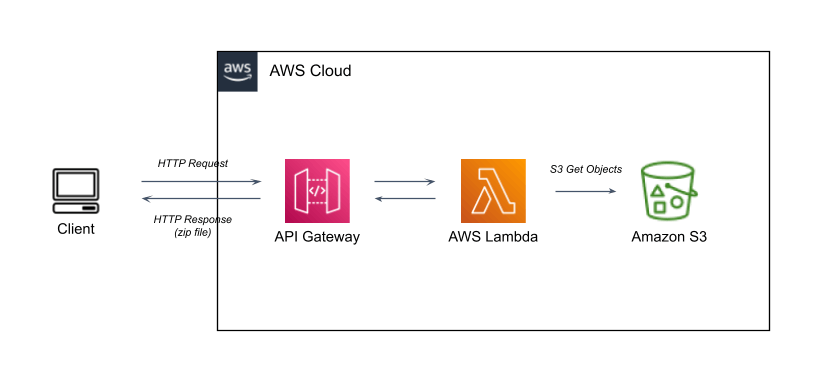
最終的に出来上がるもの
前提
S3
以下のS3バケットとオブジェクトが存在する前提で進めていきます。
- バケット名
- sample-bucket
- オブジェクト
- folder/data1.pdf
- folder/data2.pdf
- folder/data3.pdf
- folder/data4.pdf
- folder/data5.pdf
なお、今回検証で使用したテストデータはこちらからお借りしました。
もし本記事の内容をプロダクションで運用する場合は、要件に合わせてもっとデータの件数を増やしたり、サイズの大きなデータで検証することをオススメします。
AWS CDK
今回はAWS CDKを使ってAPI GatewayとLambdaをデプロイします。
バージョンは2.10.0です。
$ cdk --version
2.10.0 (build e5b301f)
なお、詳細な使い方については割愛させていただきます。
また、デプロイのためにはAWS CLIがインストールされており、かつCredentialsが設定されている必要があります。
API Gateway & Lambdaの準備
プロジェクトの作成
まずはCDKでプロジェクトを作成します。
$ mkdir apigateway_binary && cd apigateway_binary
$ cdk init app --language=typescript
Lambda Functionの実装
次にLambda Functionを用意します。
今回はプロジェクト直下にlambda/zip_downloadというディレクトリを用意し、Pythonで実装しました。
やはり純正のboto3が扱いやすいですね。
import base64
import boto3
import zipfile
s3 = boto3.resource("s3")
bucket = s3.Bucket("sample-bucket")
def handler(event, context):
prefix = "folder/"
# BucketにあるオブジェクトのうちPrefixが "folder/" で始まるものに絞り込む
object_summaries = bucket.objects.filter(Prefix=prefix).all()
# Lambdaで一時ファイルを扱う場合は/tmp下に配置する
zip_path = "/tmp/data.zip"
# zipファイルを作成する処理
with zipfile.ZipFile(zip_path, "w", compression=zipfile.ZIP_DEFLATED) as new_zip:
for summary in object_summaries:
# folder/も一つのオブジェクトになるので拡張子のあるオブジェクトだけ対象にする
if summary.key.endswith(".pdf"):
# ファイル名を取り出す folder/data1.pdf
filename = summary.key.split("/")[1]
# S3オブジェクトを取得する
s3_object = summary.get()
# バイナリデータ部分取得
body = s3_object["Body"].read()
new_zip.writestr(filename, body)
# 作成したzipをレスポンスとして返す処理
with open(zip_path, "rb") as zip_data:
zip_bytes = zip_data.read()
return {
"statusCode": 200,
"headers": {"Content-Type": "application/zip"},
"body": base64.b64encode(zip_bytes).decode("utf-8"),
"isBase64Encoded": True,
}
実装内容は以下の公式サンプルを参考にしました。
ポイントは
- Lambdaで一時ファイルを利用する時は
/tmp配下を利用する。 -
Content-Typeを指定する(今回はapplication/zip) - バイナリデータはbase64でエンコードした文字列にする。
- レスポンスに
isBase64Encoded: Trueを含める。
です。
この辺りはお作法と思っておくのが良さそうです。
CDK側の実装
次にCDK側で各種リソースを定義します。
import { Duration, Stack, StackProps } from "aws-cdk-lib";
import { Cors, LambdaIntegration, RestApi } from "aws-cdk-lib/aws-apigateway";
import { ManagedPolicy } from "aws-cdk-lib/aws-iam";
import { Code, Function, Runtime } from "aws-cdk-lib/aws-lambda";
import { Construct } from "constructs";
import * as path from "path";
export class ApigatewayBinaryStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
// Lambdaの定義
const LAMBDA_FUNCTION_DIR = path.join(__dirname, "../lambda");
const zipDownloadFunction = new Function(this, "ZipDownloadFunction", {
code: Code.fromAsset(`${LAMBDA_FUNCTION_DIR}/zip_download`),
handler: "index.handler",
runtime: Runtime.PYTHON_3_9,
// 念のためタイムアウトを30秒に設定
timeout: Duration.seconds(30),
});
zipDownloadFunction.role?.addManagedPolicy(
ManagedPolicy.fromAwsManagedPolicyName("AmazonS3ReadOnlyAccess")
);
// API Gatewayの定義
const api = new RestApi(this, "BynaryDataApi", {
// CORSの設定。状況に応じて適宜変える
defaultCorsPreflightOptions: {
allowOrigins: Cors.ALL_ORIGINS,
allowMethods: ["GET", "OPTIONS"],
allowHeaders: Cors.DEFAULT_HEADERS,
disableCache: true,
},
// デプロイする環境 状況に応じて適宜変える
deployOptions: {
stageName: "dev",
},
// 【重要】バイナリメディアタイプの指定
binaryMediaTypes: ["application/zip"],
});
api.root
.addResource("zip-download")
.addMethod("GET", new LambdaIntegration(zipDownloadFunction));
}
}
API Gatewayでバイナリデータを扱う場合、バイナリメディアタイプを指定する必要があります。
公式ドキュメントの以下のページに記載があります。
デプロイ & 動作確認
ここまでできたらとりあえずデプロイしてみましょう。
# 初回実行時はcdk bootstrapする必要がある
$ npm run build
$ cdk deploy
成功すればAPI Gatewayのパスが表示されます。
Outputs:
ApigatewayBinaryStack.BynaryDataApiEndpointXXXXXX = https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/
curlで取得してみましょう。
$ curl https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/zip-download > data.zip
実はこのまま解凍すると失敗してしまいます。
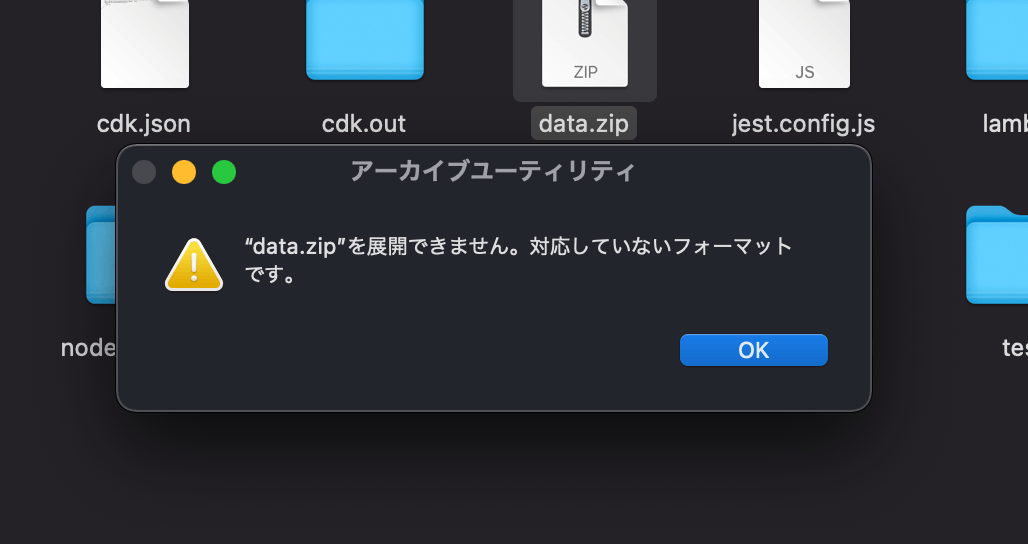
以下の注釈に記載があるように、Acceptヘッダーを設定する必要があります。
(サンプルコード的なものが無いのでサラッと読み飛ばしてました・・・)
ということでAcceptヘッダーにバイナリメディアタイプを設定してリクエストする必要があります。
$ curl -H "Accept: application/zip" https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/zip-download > data.zip
API Gateway側だけでなく、クライアント側の設定も必要になるので忘れないようにしましょう。(重要)
フロントエンドから利用する
curlから利用できたので概ね完成ですが、フロントエンド(特にaxios)から利用する際にもハマったので一応続きます。
CORSの設定を行う
今回は別オリジンのフロントエンドから利用するので、そのための設定をLambdaにも適用する必要があります。
「CDK側の実装」の章でAPI Gateway側にはCORSの設定をしていますが、Lambdaの方にも必要になります。
ということでlambda/zip_download/index.pyのheadersに手を加えます。
import base64
import boto3
import zipfile
s3 = boto3.resource("s3")
bucket = s3.Bucket("sample-bucket")
def handler(event, context):
prefix = "folder/"
# BucketにあるオブジェクトのうちPrefixが "folder/" で始まるものに絞り込む
object_summaries = bucket.objects.filter(Prefix=prefix).all()
# Lambdaで一時ファイルを扱う場合は/tmp直下に配置する
zip_path = "/tmp/data.zip"
# zipファイルを作成する処理
with zipfile.ZipFile(zip_path, "w", compression=zipfile.ZIP_DEFLATED) as new_zip:
for summary in object_summaries:
if summary.key.endswith(".pdf"):
# ファイル名を取り出す folder/data1.pdf
filename = summary.key.split("/")[1]
# S3オブジェクトを取得する
s3_object = summary.get()
# バイナリデータ部分取得
body = s3_object["Body"].read()
new_zip.writestr(filename, body)
# 作成したzipをレスポンスとして返す処理
with open(zip_path, "rb") as zip_data:
zip_bytes = zip_data.read()
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/zip",
+ "Access-Control-Allow-Headers": "Content-Type",
+ "Access-Control-Allow-Origin": "*",
+ "Access-Control-Allow-Methods": "GET",
},
"body": base64.b64encode(zip_bytes).decode("utf-8"),
"isBase64Encoded": True,
}
※追記
CDK側でも設定できそう。
フロントエンドアプリケーションの作成
適当にReactアプリケーションを作成して動かします。
$ npx create-react-app my-app --template typescript
$ cd my-app
$ npm install axios
App.tsxを以下のように編集します。
import axios from 'axios';
import React from 'react';
import './App.css';
async function download() {
const response = await axios.get<ArrayBuffer>('https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/zip-download', {
headers: {
Accept: "application/zip",
},
})
// レスポンスからバイナリデータを取り出してダウンロードする処理
const objectURL = URL.createObjectURL(new Blob([response.data]));
const downloadLink = document.createElement('a')
downloadLink.href = objectURL;
downloadLink.download = "data.zip"
downloadLink.click();
}
function App() {
return (
<div className="App">
<header className="App-header">
<button onClick={download}>ダウンロード</button>
</header>
</div>
);
}
export default App;
ちゃんとaxiosのヘッダーにもAccept: "application/zip"が設定されていますね。
これで動かしてみましょう。起動してボタンをクリックします。
npm run start
はい。
zipダウンロードはできますが、残念ながら不適切なフォーマットで取得されます。(2回目)

axiosでバイナリデータを取得する場合は以下の記事にあるようにresponseType: "arraybuffer"を指定する必要があるようです。
この辺りはクライアントの仕様なので、使用しているクライアントによって適切な設定をする必要があります。
ということで修正版が以下になります。
import axios from 'axios';
import React from 'react';
import './App.css';
async function download() {
const response = await axios.get<ArrayBuffer>('https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/zip-download', {
headers: {
Accept: "application/zip",
},
+ responseType: "arraybuffer"
})
// レスポンスからバイナリデータを取り出してダウンロードする処理
const objectURL = URL.createObjectURL(new Blob([response.data]));
const downloadLink = document.createElement('a')
downloadLink.href = objectURL;
downloadLink.download = "data.zip"
downloadLink.click();
}
function App() {
return (
<div className="App">
<header className="App-header">
<button onClick={download}>ダウンロード</button>
</header>
</div>
);
}
export default App;
ここまでしてやっと完成です!
その他のハマりどころ
Lambdaでzip圧縮をするにあたって、当初はNode.jsで実装しようかと考えていました。
Node.jsで楽にzip圧縮しようと思うと大抵外部ライブラリを使用することになります。
当時はarchiverというライブラリの使用を検討していました。
こちらのライブラリで実装までしたのですが、S3のデータ数が一定以上になると上手くzip圧縮ができない事象が発生してしまいました。
(自分が観測したのはfinalizeというAPIが何のエラーも吐かず終了するという事象。あとから知ったけどissueもちらほら起票されていそう)
自分の使い方が良くない可能性はありますし、他のライブラリを選定するということも考えましたが、あまり外部ライブラリの選定や使い方で悩みたくない(ライセンスの話とかも入ってくるとさらにややこしそう)、かつPythonであれば標準ライブラリで十分対応可能なので途中からPythonに路線変更しました。(比較的直感的なAPIなのもGood)
さいごに
API Gateway自体はそもそもRESTでJSONを扱う用途が中心だと思っています。
バイナリデータが扱えること自体は素晴らしいことではありますが、API Gatewayの方の設定だけに留まらずクライアント側にも設定が必要だったり、そもそもzip関係のサポートが言語によって異なっていたり、色々なハマりどころがある印象を受けました。(慣れの問題もあるかもしれない)
要件次第ではありますが、S3の署名付きURLを使うことなどで済むのであればなるべくそちらに寄せた方が楽になることも多そうです。URLは単純な文字列として扱えるので・・・。
zip圧縮もS3イベント等で済むのであればそちらを使っても良さそう。
あるいは以下の記事のようにCloudFrontを経由でヘッダーを設定するのも良さそう。
ということで今回紹介した方法はあくまで一つのやり方に過ぎませんが、悩める方の参考になれば幸いです。
おまけ(お片付け)
不要になったリソースは削除しておきましょう。
$ cdk destroy
参考
Discussion