CS50 Lecture3 Algorithms
ハーバード大学のコンピューターサイエンスの授業CS50のlecture3自分用メモ
review
配列を導入することでscoreというサイズ3の1つの変数だけで複数の値を格納できた。
コンピュータのメモリに連続して物事を保存できるという性質を活用することで、さまざまな機能の実装を可能にする。
配列には問題点がある。
コンピューターはどんなに強力であっても、技術的には1度に配列の中の1つの場所しかみることができない。
まず入力が与えられる。
例えば数字の配列だったり、googleの検索であれば、Webページの配列あったりする。
そして目的は何らかの出力を得ること。
問題の入力値が配列であれば、出力値はbool値のような単純なのになるかもしれない。
線形探索
電話帳を1ページずつめくって目的の電話番号を探していく方法
線形探索と二分探索
7つのドアがあり、扉を開けるとランダムな数字が現れる。

どのようにして0を探すのが効率が良いか??
まずは線形探索の擬似コードで実装してみる。
For i from to n-1
If number befind i'th door
Return true
Return false
なぜn-1かというと、もし7つ(n)のドアがあり、0から数え始めるので、最後は6となるから。
Return falseはelseの一部ではない
ある数字が現在のドアの後ろにないからといって早々に処理を中断したくないから。
n個のドア全てをチェックし、該当の数字がなければfalseを返すようにしたい。
下記は探索実行時間の最大を表す式
線形探索の実行時間の上限は下記の中だとO(n)になる
O(n^2)
O(n log n)
O(n)
O(log n)
O(1)
アルゴリズムの実行下限はオメガを使って表される
この中で線形探索の実行下限はΩ(1)となる。
(最初に開けた扉から運良く0が現れる場合)
Ω(n^2)
Ω(n log n)
Ω(n)
Ω(log n)
Ω(1)
線形探索の実行時間の範囲
Ω(1) < 線形探索の実行時間 < 0(n)
二分探索(バイナリサーチ)
今回はドアの向こう側の数字はソートされている

二分探索では最初に真ん中の扉を開ける。
ソートされてるのでおそらく左側は5より小さく、右側は5より大きい。
次に右側の真ん中の扉を開けると7が出てきて、おそらくその右側に目当ての6が出てくる。
このように、事前にソートされていれば、二分探索のような優れたアルゴリズムを適用することができる。
これをどのように実現するのかアルゴリズム的に考えてみる。
二分探索では次のような擬似コードを書いてみる。
If number behined middle door
Return true
Else if number < middle door
Search left half
Else if number > middle door
Searcch right half
二分探索の上限はO(log n)で表される
下限はΩ(1)
実際、コンピューターのCPUを考えてみると、ヘルツを単位として計測される。
おそらくGHz、つまり十億Hzという単位で測られている。
コンピューターの頭脳であるCPUは1GHzであれば、1度に10億のことができるということになる。
#include <cs50.h>
#include <stdio.h>
int main(void)
{
//代入したい数字があらかじめわかっていれば、コンパイラが自動的に計算してくれるので、大括弧([])に数字を入れる必要はない
int numbers[] = {4, 6, 8, 2, 7, 5, 0};
for(i = 0; i < 7; i++)
{
if(numbers[i] === 0)
{
printf("Found\n");
//見つかった時の終了ステータス
//0は成功のステータス
return 0;
}
}
printf("Not Found\n");
//見つからなかった時の終了ステータス
//1は失敗のステータス
return 1;
}
#include <stdio.h>
#include <cs50.h>
#include <string.h>
int main(void)
{
string names[] = {"Bill", "Charile", "Fred", "Geroge", "Ginney", "Preacy", "Ron"};
for (int i = 0; i < 7; i++)
{
if(strcmp(names[i], "Ron") == 0)
{
printf("Found\n");
return 0;
}
}
printf("Not Found\n");
return 1;
}
もしname[i] == “Bill”の場合、Ronよりも前にあるので、負の数を返す。
ブール式の問題点は、0のみが偽だということ。
負の1でも正の1でもtrueになる。
C言語のようなコンピュータ言語では0以外は全て真とみなされ、真値(truthy)になる。
データをカプセル化する
電話番号やクレジットカード番号など、数値だけど、途中でハイフンや記号が入っていたりする可能性のある、数値で扱いたくないものはstringで設定する
二つの異なるデータ型をカプセル化いた独自のデータ型Personを作る。
typedef struc
{
string name;
string phonenumber;
}
person;
structureは中に、一つ以上のデータを持っている。
typedefで複数のデータ型を組み合わせた独自のデータ型を作ることができる。
#include <stdio.h>
#include <cs50.h>
#include <string.h>
typedef struct
{
string name;
string number;
}
person;
int main(void)
{
string names[] = {"David", "Brian"};
string numbers[] = {"+81-4442-5553", "+81-3421-4234"};
for (int i = 0; i < 2; i++)
{
if(strcmp(names[i], "David") == 0)
{
printf("Found %s\n", numbers[i]);
return 0;
}
}
printf("Not Found\n");
return 1;
}
しかしこのコードだと、書くべき名前と電話番号が多い場合、人間なので間違う可能性がある。
それを防ぐために下記のように書き換える。
関連するデータはまとめておく。
そのために、personという独自の型を定義する。
#include <stdio.h>
#include <cs50.h>
#include <string.h>
typedef struct
{
string name;
string number;
}
person;
int main(void)
{
person people[2];
people[0].name = "Brian";
people[1].number = "+81-4442-5553";
people[1].name = "David";
people[1].number = "+81-3421-4234";
for (int i = 0; i < 2; i++)
{
if(strcmp(people[i].name, "David") == 0)
{
printf("Found %s\n", people[i].number);
return 0;
}
}
printf("Not Found\n");
return 1;
}
personの型を作ることで、気にかけるべき全ての情報をカプセル化している。
実際、GoogleやFacebookが多くの情報の保存する方法はこのようなもの。
SNSのアカウントは、ユーザー名、パスワード、投稿履歴、フォロワーなど複数のデータが関連づけられている。
もし企業が、これらの情報を集めた配列を持っていたら、これらの全ての順序が正しいとは限らなくなる。
これらの気にかけるべき情報(ユーザー名、パスワード、投稿履歴、フォロワーなど)を全てある種のデータ構造の中にカプセル化し、それをデータベースのバックエンドの中に格納する。
カプセルかはC言語の特徴であり、データ構造を作成して、関連するデータまとめるために使用できる。
並び替えるアルゴリズム
線形探索と二分探索とでは、明らかに二分探索が勝者である。
しかし、このアルゴリズムを適用するにはあらかじめデータがソートされていなければならない。
いつものように、これを解決すべき問題として捉えれば、入力と出力があり、目標は、入力をとって、出力を出すこと。
この場合、入力とは何か?
→ソートされていないデータ
出力とは何か?
→ソートされたデータ
今回は検索ではなくソート

並び替えるアルゴリズム
選択ソート
For i from 0 to n-1
Fiind smallest item between i'th item and last item
Swap smallest with i'th item
i番目の要素(0を起点とする要素1)と最後の要素の間の最小の要素を見つける。
n + (n - 1) + (n - 2) + ... + 1
= n(n + 1)/2
= n^2/2 + 2/2
nが大きくなればなるほど総数が大きくなる
オーダ記法を使えば、O(n^2)に当てはまる

選択ソートは、実行時間のリストの最上位にある。

バブルソート
最大の数字がリストの地番上、あるいは最後、棚の右側に向かって泡のように押し寄せてくるという事実を暗示している。
ソートされてない配列で、隣り合った数字同士を比較し、小さいものを右に、大きいものを左に置いていくソートの方法。
配列を一通り見終わるとき、n-1回の比較をしている。つまり、n個の要素について隣接関係を比較している。
その後、n-1,n-2,n-3,n-4...、2つまたはつが残るまで比較を続け、その時点で終了となる。
マージソート

6385,2741
同じアルゴリズムであるマージソートを使えば左半分をソートし、右半分をソートし、ソートした半分をマージすることができる。
まず、6285の4つの数字の左半分をソートする
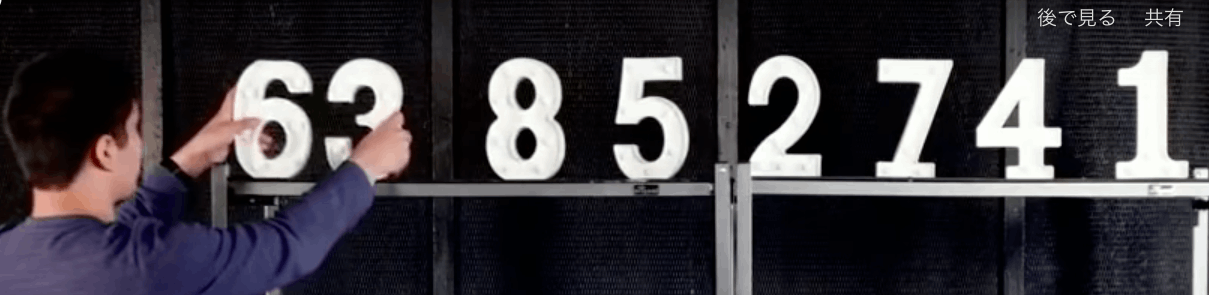
この6、3をどうソートするか?
人間の直感からすれば、6と3を入れ替えるだけで明確ではあるが、このアルゴリズムを適用すれば、次は右半分8、5をソートする
数字が一つしかなければ中止する
サイズが1で数字が6のリストはソートされている
サイズが2で数字が6、3のリストの右半分をソートする
右半分は3しかないので1つの数字なので中止
サイズ1の2つの配列(6が1つ入ってる配列と、3が1つ入ってる配列)を持っていて、それをマージする
6と3の間では3の方が小さいので3を最初に置く

6を取り出してその隣に置く
次に、元の4つの数字の配列(6、3、8、5)のうちの右半分(8、5)をソートする必要がある。
右半分のうちの左半分、つまり左半分(8)を見ると、数字は一つ(8)しかないので中止。
右半分も数字は一つ(5)しかないので中止。
これらをマージすると、8と5の間では、5が小さいので5を先におく

8はその隣に置く。
サイズ2の二つ目の配列(8、5)もソートされた状態になった。
今、全体(6385,2741)から見て左半分と、左半分の左半分と右半分がソートされた状態になっている。
第三ステップでは、それらのサイズ2の配列同士をマージしなければならない
それぞれの最小の数字を比較してみると、

3と5を比較する。
3の方が小さいので先に入る。

残りの[6],[5,8]でそれぞれで最小のものは6、5なので、その間で小さい方は5なので、次に5が入る

6、8との間では6が小さいので6、次に8が入る。

同様に右半分も同じ処理を繰り返す。

これをさらにマージする。
二つの配列([3、5、6、8]と[1、2、4、7])のうち、それぞれの配列で小さいものは3と1。
その3と1の間で小さい方は1なので1を最初に置く。
残りの[3、5、6、8]と[2、4、7]のうち、それぞれの配列で小さいものは
3と2。この二つのうち小さい方は2なので2を置く。

残りの[3、5、6、8]と[4、7]のうちそれぞれの配列で小さいものは3と4。
3の方が小さいので3を置く。
という風にマージしていく。
8個のリスト(配列)からサイズ4のリストが2つ。サイズ2のリストが4つ、サイズ1のリストが8つ。
棚にある数字を8→4→2→1と3回移動させた。
そして、それぞれの棚で何回統合させたかというと、それぞれの棚で異臭的に8つの数字全てに触れた。
まず一番小さい数字を入れ、次に小さい数字を入れ、三番目に小さい数字を入れた。
しかし、選択ソートとは異なり、半分ずつの数字をすでにソートしていたので1つずつ取り出していた。何度も繰り返したわけではなく、常に半分ずつのリストかの最初からとっていた。つまり、全ての棚でnステップを行っていた。なぜなら、全ての棚のn個の要素を全てマージしたから。
しかし、n個の要素を何回マージしたか?全部で3回。 しかし、二分探索やより一般的な統合統治のプロセスについて考えてみると、何かと半分にする時はいつもそう。それが対数(log_2 )それは見事に棚の数と一致する。棚の上に8つの要素があるとすると、棚の数3は、log_2 8の計算で得られるもの。つまり、n個のことをlog n回やったということ。つまり、つまりオーダ表記で考えると、バブルソートや選択ソートより優れていることになる。
かかる最大値

最小値

nが大きくなればなるほど、マージソートの恩恵を享受できる。
また、実行時間の最大値と最小値が同じであれば、シータを使って表現も可能

Discussion