DagsHubに入門する
DagsHubとは
はじめに
MLflowやDVCを触っており、どうにか組み合わせて使えないか四苦八苦していたところに、ちょうどいいサービスを見つけた。しかし、新しいサービスのようで日本語での記事が見つからなかったためメモがわりに投稿する。
概要
DagsHubは、データサイエンスと機械学習プロジェクトのためのバージョン管理とコラボレーションを強化するプラットフォームである。Gitのような使い心地で、コード、データセット、MLモデルの管理を一元化し、プロジェクトの透明性と再現性を向上させることができる。

主な機能
-
バージョン管理: コード、データセット、機械学習モデルの変更をトラッキングし、履歴を保持する。
-
コラボレーション: プロジェクトメンバーとの効率的なコラボレーションを促進し、レビューやコメントを通じて意見交換が可能。
-
実験のトラッキング: MLflowと統合しており、実験の設定、結果、パフォーマンス指標をトラッキングし、比較することができる。
他のサービスとの比較・利点
GitHub/GitLabとの比較
DagsHubはデータサイエンスと機械学習プロジェクトのために特化しており、データとMLモデルのバージョニングに関して優れている。
DagsHubは、DVC(Data Version Control)とMLflowを統合したプラットフォームであり、データのバージョン管理と実験追跡を簡単に行える環境を提供している。
W&Bや他のMLプラットフォームとの比較
W&B(Weights & Biases)などの他のMLプラットフォームは、実験追跡と可視化に強みを持っているが、DagsHubはこれらの機能に加えて、DVCやMLflowといったオープンソースのツールとの統合を通じて、データとコードのバージョン管理にも重点を置いている。
これにより、プロジェクトのすべての側面を一元管理でき、チームメンバー間での協力が容易になる。
移行の容易さとOSSの強み
DVCやMLflowはオープンソースソフトウェア(OSS)として、広く利用されており、既存の技術スタックに統合したり、他のサービスからDagsHubへの移行を容易にする。
これは、既存のワークフローを大きく変更することなく、データ管理と実験管理を改善したいチームにとって大きなメリットとなる。
料金プラン

まとめ
個人での利用なら無料プランで十分すぎるくらい使える。
ただ、プライベートリポジトリだとコラボレーターが二人までなので、Kaggleコンペにチームを組んで参加するといった場合は2人*以内のチームでしか使えない。
*プロジェクト作成者も人数に含めるか否かは読み取れなかったが、UIを見るとプロジェクト作成者もコラボレーター欄に含まれていたので最大2人と思われる。
以下詳細
無料プラン($0)
- パブリックリポジトリ: 無制限
- プライベートリポジトリ: 非商用利用なら無制限
- ML実験のトラッキング: 無制限
- コラボレーター: パブリックなら無制限、パブリックなら最大2人まで
- DAGsHubストレージ: 100GB
- その他: データのバージョン管理とリネージュ、パブリックリポジトリのアノテーションワークスペース、ノートブックのバージョン管理と比較、CI/CD/CTの統合、インタラクティブなパイプライン、コミュニティサポートが利用可能
チームプラン(月額$99/ユーザー数)
- 無料プランに含まれる全ての機能
- プライベートリポジトリ: 無制限
- ストレージ: 独自のストレージ接続可能
- データ容量: 最大1TBまたは最大200万ファイル(問い合わせで上限を上げることも可能)
- その他: プライベートリポジトリで最大5つのアノテーションプロジェクト、プライベートリポジトリ用のData Engine、チームアクセスコントロール、DAGsHubのメールサポート
エンタープライズプラン(要問い合わせ):
- チームプランに含まれる全ての機能
- データ容量: 無制限
- VPCまたはオンプレミスでのインストール
- LDAP認証
- 専門家によるダイレクトサポートやその他サービス
使い方
アカウント作成
サインアップ

サイトに飛び、真ん中のSTART NOWか右上のRegisterをクリックするとサインアップできる。
ちなみにこのトップページが最高にかっこいいのでサインアップしなくても一度飛んでみてほしい。
初期設定
パーソナライズ
アカウントが作れたらまずはパーソナライズという画面に飛ぶがここはスキップできる。
お好みで入力する。
オンボーディング
次にオンボーディングとして、DagsHubで何をしたいか聞かれる。
ここではバージョン管理を選択する。
- コードとデータのバージョン管理
- ML実験のトラッキング
- データセットの生成
- データのアノテーション
リポジトリ作成
すると、my-first-repoというパブリックリポジトリが自動で作成される。
また、「Get Started with xxx」という表示が画面上部に出てきて、それをクリックすることでどのように始められるかが分かるので、あとはそれに従って進めていける。
DagsHub+DVC
リポジトリの初期化
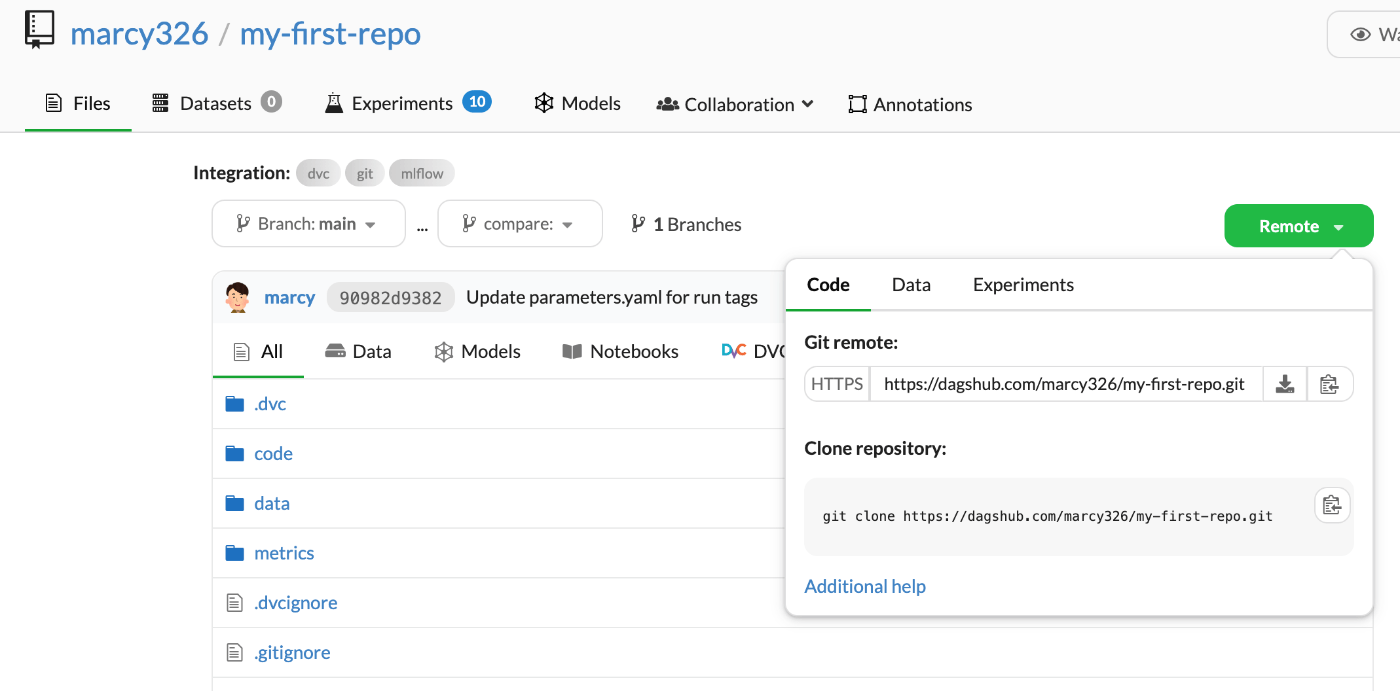
まずは自動作成されたリポジトリをgit cloneする。
git clone https://dagshub.com/<user_name>/<repo_name>.git
GitHub等と似たような場所にあるあのボタンをクリックするとリポジトリのURLやクローンのコマンドが出てくる。
続いてREADME.mdを作成して、git pushまで実行
cd my-first-repo
echo "# my-first-repo" >> README.md
git add README.md
git commit -m "first commit"
git branch -M main
git push -u origin main
環境作成
今回はpyenv+venvでパッケージ管理をする。
pyenv local 3.11
python -m venv .venv
source ./.venv/bin/activate
venvを作成したらgitignoreも書いておく。
公式チュートリアルを参考にvenv以外もついでに追加しておく。
.venv/
__pycache__/
# /data/
/outputs/
のちのdvc addコマンドでエラーが出るため、この時点では/data/はgitignoreに含めない。
DVCの初期設定
DVCをインストールする。
pip install dvc dvc-s3
まずはDVCの初期化を実行する。
dvc init
続いてDVCのリモートリポジトリを設定する。
dvc remote add origin s3://dvc
dvc remote modify origin endpointurl https://dagshub.com/<username>/<repo-name>.s3
dvc remote modify origin --local access_key_id <token>
dvc remote modify origin --local secret_access_key <token>
このコマンド内のトークンはDagsHubのUIから確認できる。
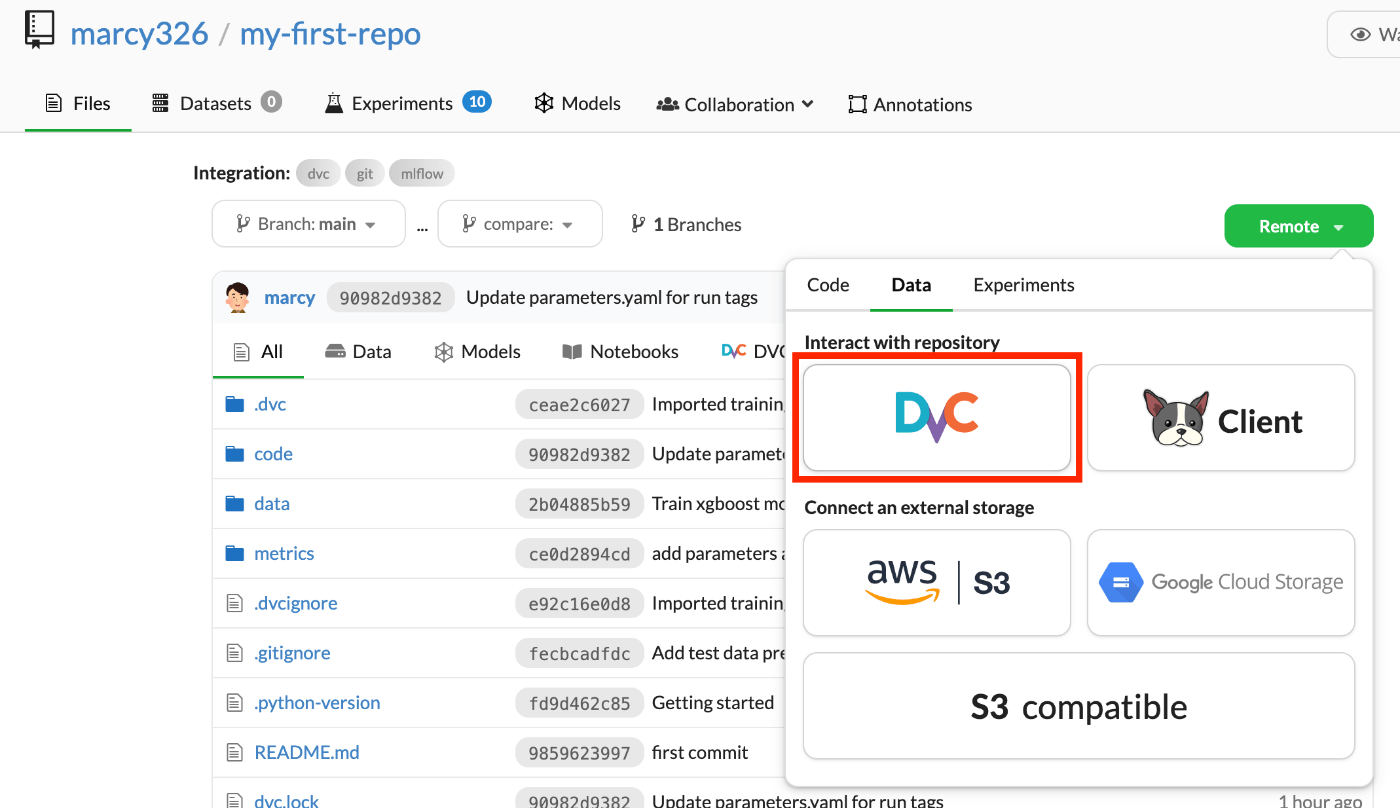

枠内右のボタンをクリックすることでトークンを含めたコマンドをそのままコピーできる。
DVCにデータの登録
DVCのデータはこちらのタイタニックを題材とした記事を参考にしている。
Kaggleからデータをダウンロードして、以下のように配置する。
- my-first-repo
- data
- raw
- train.csv
- test.csv
- gender_submission.csv
配置したデータをDVCに登録する。
dvc add data/raw/train.csv data/raw/test.csv data/raw/gender_submission.csv
パイプラインの登録
パイプライン実行用に、data/processedとcode, modelディレクトリ、dvc.yamlとcode/preprocess.py, `code/train.pyファイルを作成する。
- my-first-repo
- dvc.yaml
- data
- processed
- code
- preprocess.py
- train.py
- model
stages:
preprocess:
cmd: python code/preprocess.py data/raw/train.csv data/processed/processed_train.csv
deps:
- code/preprocess.py
- data/raw/train.csv
outs:
- data/processed/processed_train.csv
train:
cmd: python code/train.py data/processed/processed_train.csv model/model.pkl
deps:
- code/train.py
- data/processed/processed_train.csv
outs:
- model/model.pkl
import pandas as pd
import click
from sklearn.impute import SimpleImputer
def fill_missing_values(df, label, strategy):
imputer = SimpleImputer(strategy=strategy)
df[label] = imputer.fit_transform(df[[label]]).ravel()
return df
@click.command()
@click.argument('input_path')
@click.argument('output_path')
def preprocess(input_path, output_path):
# データを読み込む
df = pd.read_csv(input_path)
# 前処理の実行
df = df.drop(columns=['Name', 'Ticket', 'Cabin'])
df = fill_missing_values(df, 'Age', "median")
df = fill_missing_values(df, "Embarked", "most_frequent")
df = pd.get_dummies(df, columns=['Sex', 'Embarked'])
# 処理済みデータを保存
df.to_csv(output_path, index=False)
if __name__ == '__main__':
preprocess()
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pickle
import click
@click.command()
@click.argument('input_path')
@click.argument('output_path')
def train(input_path, output_path):
# データの読み込み
df = pd.read_csv(input_path)
X = df.drop('Survived', axis=1)
y = df['Survived']
# 訓練データとテストデータに分割
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの訓練
model = RandomForestClassifier()
model.fit(X_train, y_train)
# モデルの保存
pickle.dump(model, open(output_path,'wb'))
# モデルの評価
y_pred = model.predict(X_valid)
accuracy = accuracy_score(y_valid, y_pred)
if __name__ == "__main__":
train()
足りないライブラリもインストールする。
pip install click pandas scikit-learn
パイプラインの実行
登録したDVCのパイプラインを実行する。
dvc repro
成功したら、gitでリモートにプッシュする。
git add .
git commit -m "First DVC repro"
git push
DVCもリモートにプッシュする。
dvc remote default origin
dvc push
DagsHubを確認
Gitがプッシュされていることが確認できるとともに、DVCにデータがプッシュされていることも確認できる。
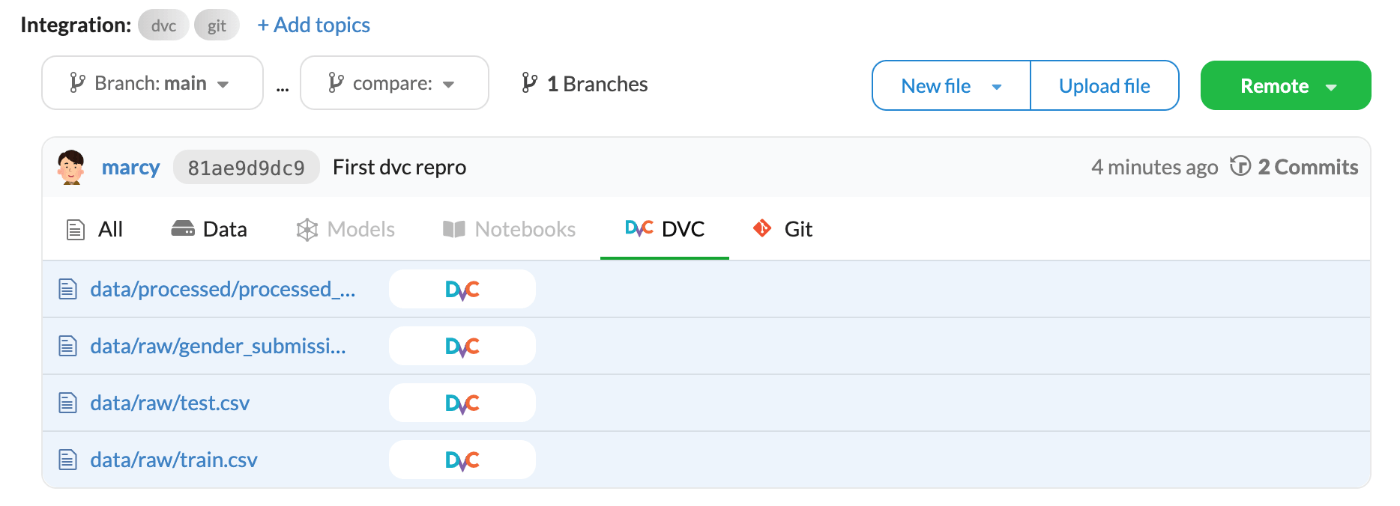
少し下にスクロールするとパイプラインのリネージュも確認できる。
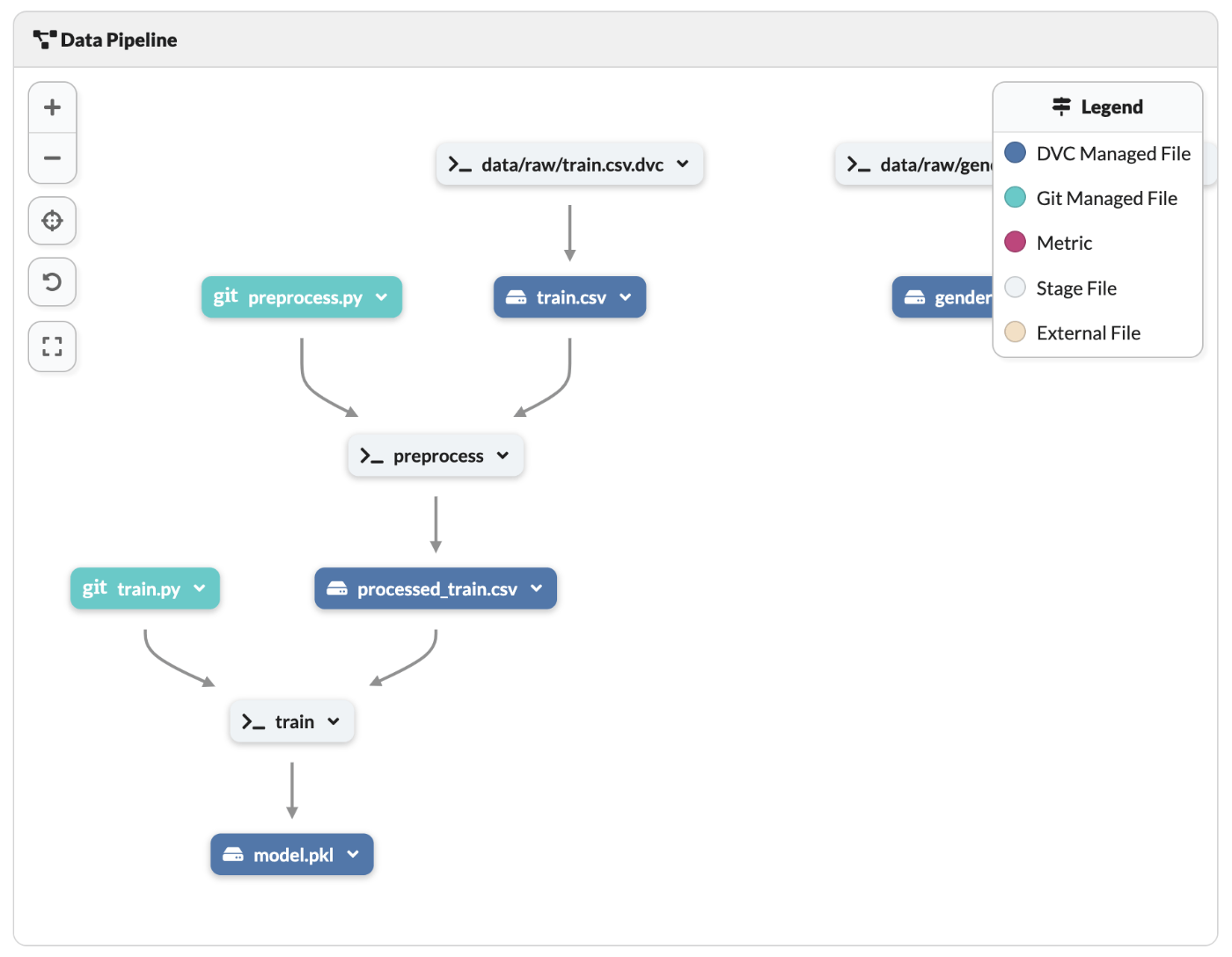
まとめ
これにてDagsHubとDVCを用いたコードとデータのバージョン管理が完了。
次回はここにMLflowをプラスして、ML実験のトラッキングを体験していく。
zenn初すぎてスクラップの使い方ズレてる気がするな。
1コメントの情報量が多すぎる。
あとで記事にまとめる前提でやってるから、もっと細々と上げていこう。
DagsHub+DVC+MLflow
環境変数の設定
MLflowのトラッキングサーバーに紐づけるために、URLと認証情報が必要になるので、環境変数に設定していく。
プロジェクト毎に変わる環境変数なので、dotenvで設定する。
まずはプロジェクトディレクトリ直下に.envファイルを作成する。
MLFLOW_TRACKING_URI=https://dagshub.com/<username>/<repo_name>.mlflow
MLFLOW_TRACKING_USERNAME=<username>
MLFLOW_TRACKING_PASSWORD=<token>
設定値は例のごとく、DagsHubのUI上から確認できる。(改行用のバックスラッシュやPythonコマンドは除外する)
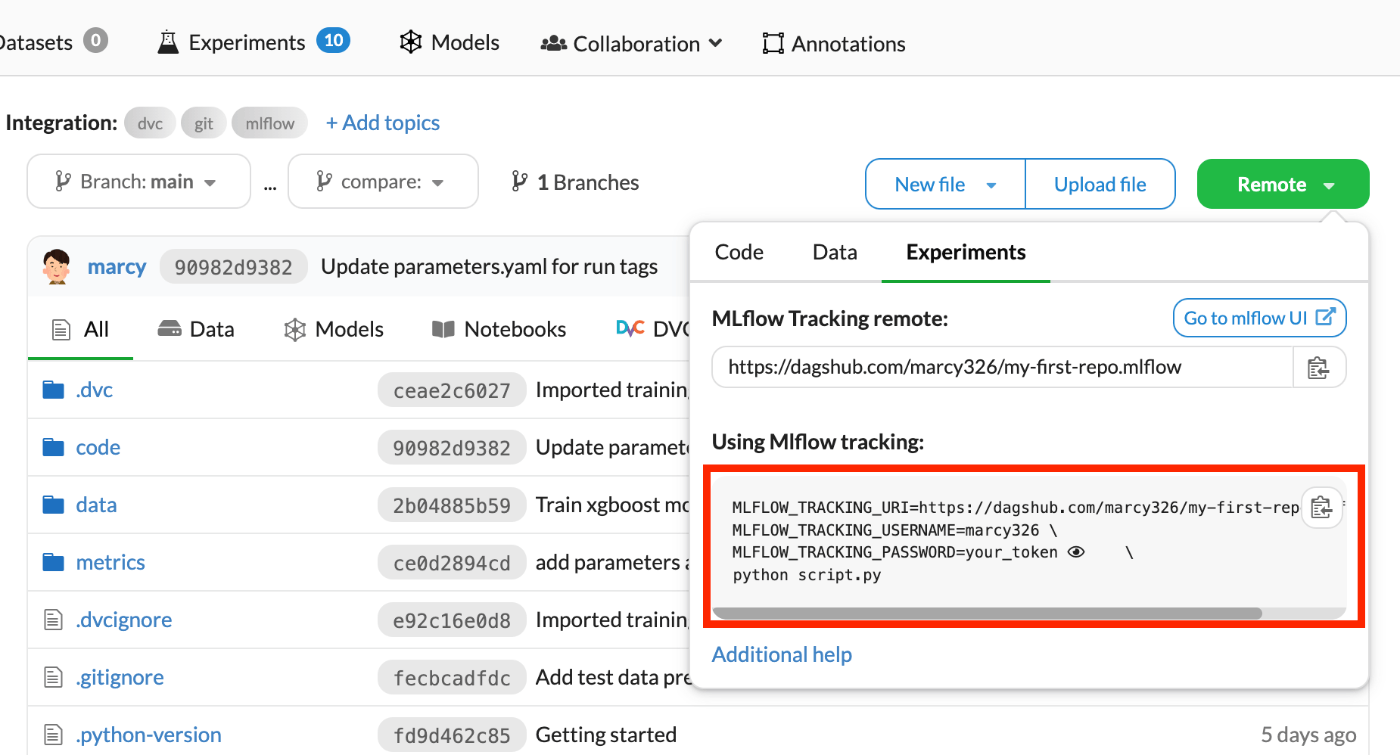
.envには認証情報も含まれているため必ず.gitignoreに追加
echo ".env" >> .gitignore
ライブラリのインストール
追加のライブラリをインストールする。
pip install python-dotenv mlflow
Trainスクリプトを更新
追加のライブラリをインポートします。
import mlflow
from dotenv import load_dotenv
.envを環境変数として読み込みます。
load_dotenv()
パラメータとメトリクスの変数を追加します。
params = {
"n_estimators": 100,
"max_depth": 5,
"random_state": 1,
}
model = RandomForestClassifier(**params)
metrics = {
"accuracy": accuracy,
}
MLflowのロギングを追加します。
with mlflow.start_run() as run:
mlflow.log_params(params)
mlflow.sklearn.log_model(model, "model")
mlflow.log_metrics(metrics)
全体
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pickle
import click
import mlflow
from dotenv import load_dotenv
load_dotenv()
@click.command()
@click.argument('input_path')
@click.argument('output_path')
def train(input_path, output_path):
# データの読み込み
df = pd.read_csv(input_path)
X = df.drop('Survived', axis=1)
y = df['Survived']
# 訓練データとテストデータに分割
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
params = {
"n_estimators": 100,
"max_depth": 5,
"random_state": 1,
}
# モデルの訓練
model = RandomForestClassifier(**params)
model.fit(X_train, y_train)
# モデルの保存
pickle.dump(model, open(output_path,'wb'))
# モデルの評価
y_pred = model.predict(X_valid)
accuracy = accuracy_score(y_valid, y_pred)
metrics = {
"accuracy": accuracy,
}
# mlflowロギング
with mlflow.start_run() as run:
mlflow.log_params(params)
mlflow.sklearn.log_model(model, "model")
mlflow.log_metrics(metrics)
if __name__ == "__main__":
train()
パイプラインの実行
パイプラインの実行をするということでdvc reproを実行したいがその前にGitをコミットする。
git add .gitignore .env code/train.py
git commit -m "Add mlflow tracking"
その後パイプラインを実行する。
dvc repro
成功したら、dvcの変更もcommit&pushする。
git add .
git commit -m "DVC REPRO: Add mlflow tracking"
git push
dvc push
MLflow ソースバージョンの更新
DagsHubのUIから結果を確認、、、の前に、個人的に気になるところを修正したい。
それは、MLflowにロギングされるソースバージョンとGitコミットに差が生じることである。
再現性確保のために、MLflowの実行結果とそのソースとの関連付けは重要である。
しかし、DVCとMLflowを組み合わせて、特にDVCパイプライン中でMLflowのトラッキングを実行すると、DVCパイプライン実行前のコミットをソースとしてロギングしてしまう。
DVCパイプライン実行後にはDVC管理のファイルが更新されるため、MLflowのソースとしてロギングされたコミットとは差が生じてしまう。
そのため、ここではDVCパイプライン実行後、MLflowのソースバージョンを更新する。
まずはスクリプト作成
from dotenv import load_dotenv
import mlflow
from mlflow.tracking import MlflowClient
import click
import git
load_dotenv()
@click.command()
@click.option("--experiment-id", default=0, show_default=True)
@click.option("--run-id", default=None, show_default=True, help="if value is None, use the latest value")
@click.option("--commit-hash", default=None, show_default=True, help="if value is None, use the latest value")
def update_tag(experiment_id, run_id, commit_hash):
if run_id == None:
all_runs = mlflow.search_runs(experiment_ids=[experiment_id])
run_id = all_runs.at[0, "run_id"]
if commit_hash == None:
repo = git.Repo(search_parent_directories=True)
commit_hash = repo.head.object.hexsha
client = MlflowClient()
client.set_tag(run_id, "mlflow.source.git.commit", commit_hash)
if __name__ == "__main__":
update_tag()
その後スクリプト実行
python update_source.py
順番でいうと、dvc repro実行後にこのスクリプトを実行する。
DagsHubかMLflowのUIから確認すると、sourceが更新されていることが分かる。
MLflow実行結果の確認
まずはDagsHubのUI上から確認する。
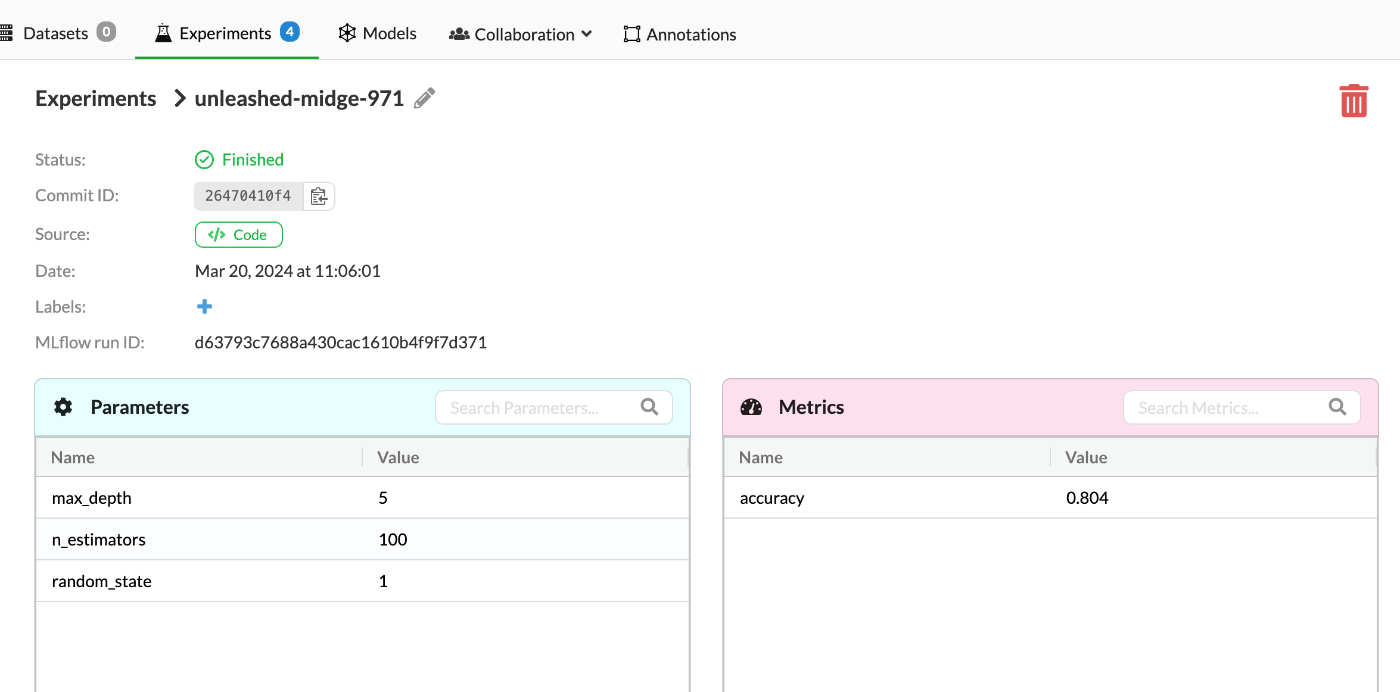
上部タブで[Experiments]をクリックすることで確認することができる。
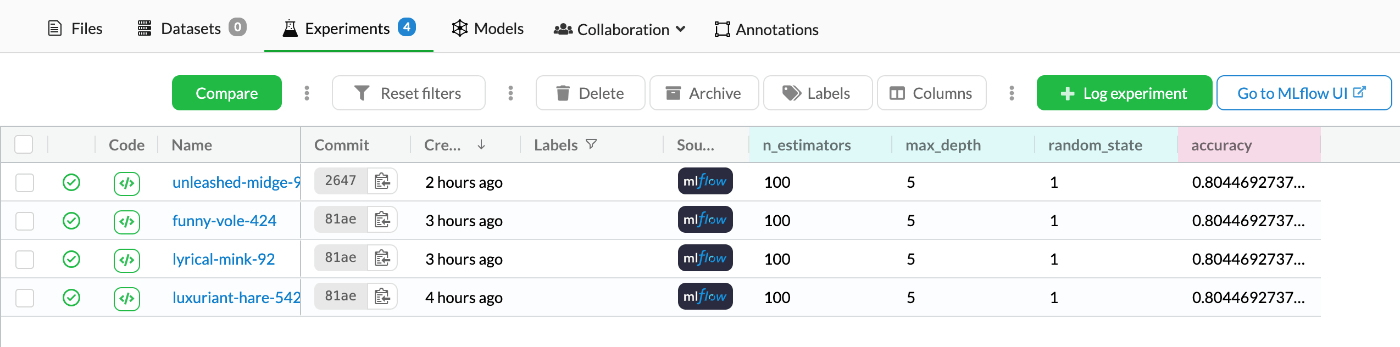
それぞれのNameをクリックすることで詳細を見ることもできる。
次にMLflow UI上から確認する。
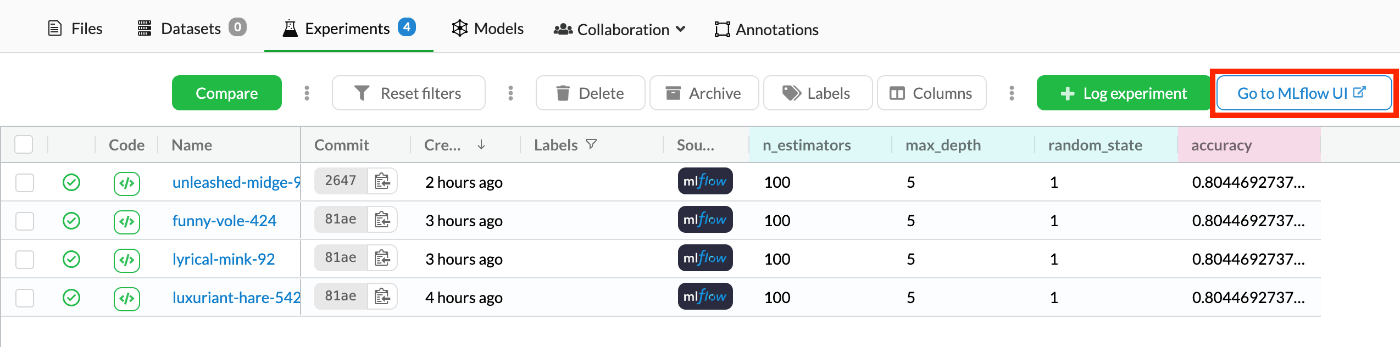
先ほどのDagsHub Experiments画面の右上に[Go to MLflow UI]というボタンがあるのでクリックする。
するとMLflow UIに飛ぶことができる。
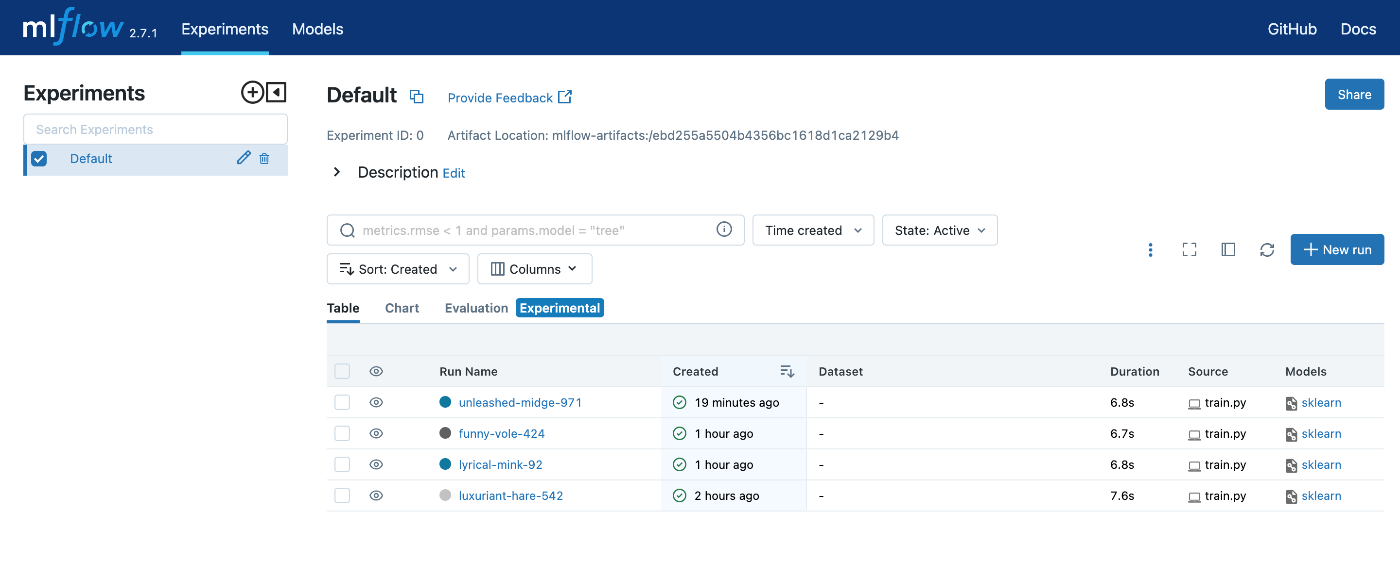
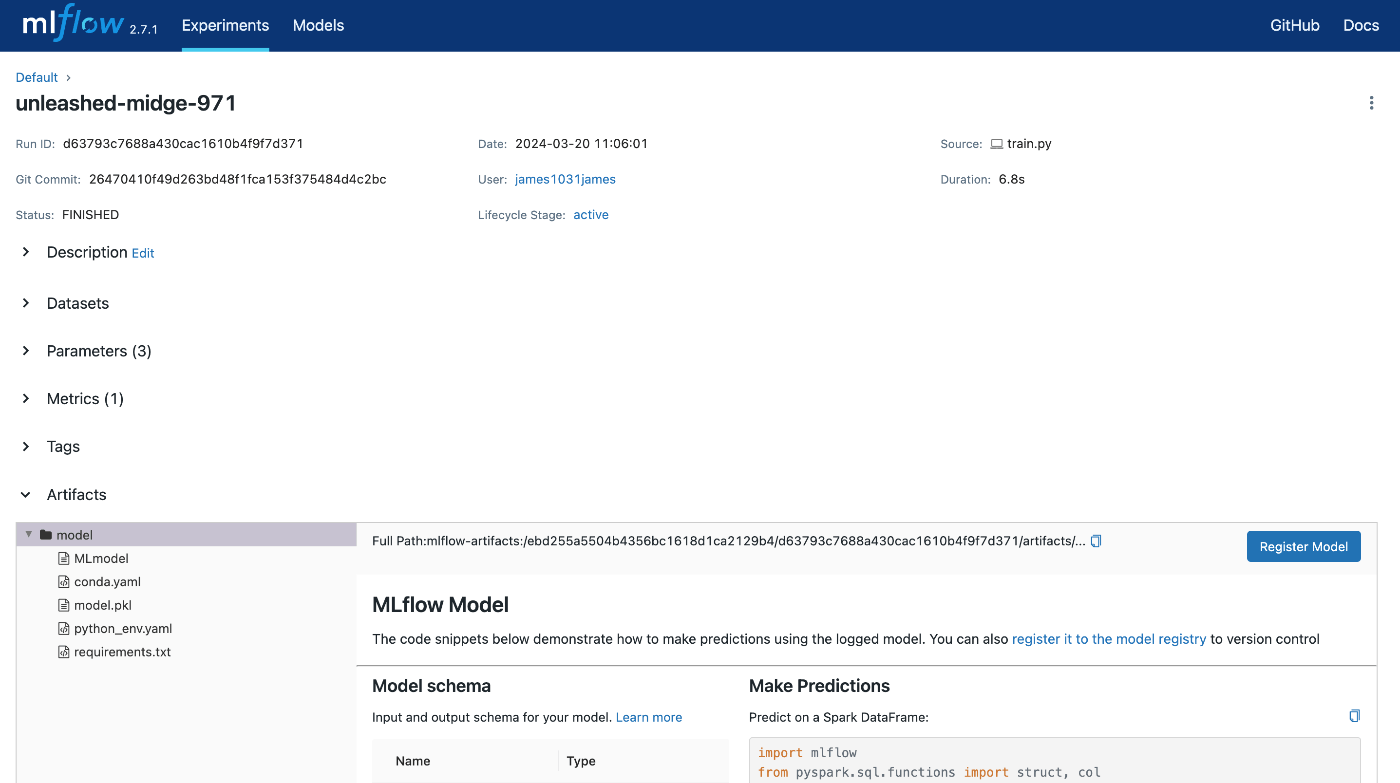
同様にそれぞれのRun Nameをクリックすることで詳細を見ることもできる。
アーティファクトとしてモデルが保存されていることも確認できる。
データ共有にDagsHub Storageを使う
はじめに
DVCは実行後であればデータの共有が可能であるが、Jupyterノートブックなどを使って手元であれこれ分析する際にはDVC実行までも行かないため、データの共有ができない。
そんな時にDagsHubで使えるのがDagsHub Storageである。
AWS S3などのようなオブジェクトストレージとして使うことができ、各リポジトリで10GBまでは使えるようになっている。
ということで、このDagsHub Storageを使うシナリオでパイプラインを組んでみる。
データのアップロード
まずはデータのアップロードをしていく。
色々方法はある。
- CLI
- Python
- ファイルシステムにマウント(Linux限定)
この中で一番簡単なのはCLIのように思うのでアップロードはCLIの方法で進める。
まずはローカル専用のディレクトリを作成して、そこにファイルを格納する。
プロジェクト直下で以下を実行する。
mkdir local
echo "/local/" >> .gitignore
data/rawにファイルがあれば以下を実行してファイルをコピーする。
cp data/raw/train.csv data/raw/test.csv data/raw/gender_submission.csv local
新たに必要なライブラリをインストールしておく。
pip install dagshub
DagsHubにCLIからログインする。
dagshub login
ファイルをアップロードする。
dagshub upload --bucket <username>/<repo_name> <local_file_path> <repo_path>
例)
dagshub upload --bucket marcy/my-first-repo local/train.csv data/raw/train.csv
dagshub upload --bucket marcy/my-first-repo local/test.csv data/raw/test.csv
dagshub upload --bucket marcy/my-first-repo local/gender_submission.csv data/raw/gender_submission.csv
気をつけるべきところは--bucketオプションをつけるというところ。
これをつけないとgit管理のディレクトリ上にアップロードしてしまう。
データのダウンロード
データのダウンロードはDVCパイプライン中にて実行していく。
ということで新たにデータロード用のスクリプトを作成する。
import os
import click
from dotenv import load_dotenv
from dagshub import get_repo_bucket_client
load_dotenv()
DAGSHUB_USERNAME = os.environ.get("DAGSHUB_USERNAME")
DAGSHUB_REPO_NAME = os.environ.get("DAGSHUB_REPO_NAME")
s3 = get_repo_bucket_client(f"{DAGSHUB_USERNAME}/{DAGSHUB_REPO_NAME}")
@click.command()
@click.argument('input_path')
@click.argument('output_path')
def data_load(input_path, output_path):
s3.download_file(
Bucket=DAGSHUB_REPO_NAME,
Key=input_path,
Filename=output_path,
)
if __name__ == "__main__":
data_load()
環境変数を追加する。
DAGSHUB_USERNAME=marcy
DAGSHUB_REPO_NAME=my-first-repo
dvc.yamlも更新する。
stages:
data_load:
foreach:
- train
- test
- gender_submission
do:
cmd: python code/data_load.py data/raw/${item}.csv data/raw/${item}.csv
deps:
- code/data_load.py
outs:
- data/raw/${item}.csv
実行前にdata/raw/配下のファイルは消しておく。
その後、DVC実行
dvc repro
結果の確認
DVC実行に成功して、gitとdvcをプッシュしたら結果を確認する。
DagsHubにアクセスしてリネージュを確認すると以下のようになっている。
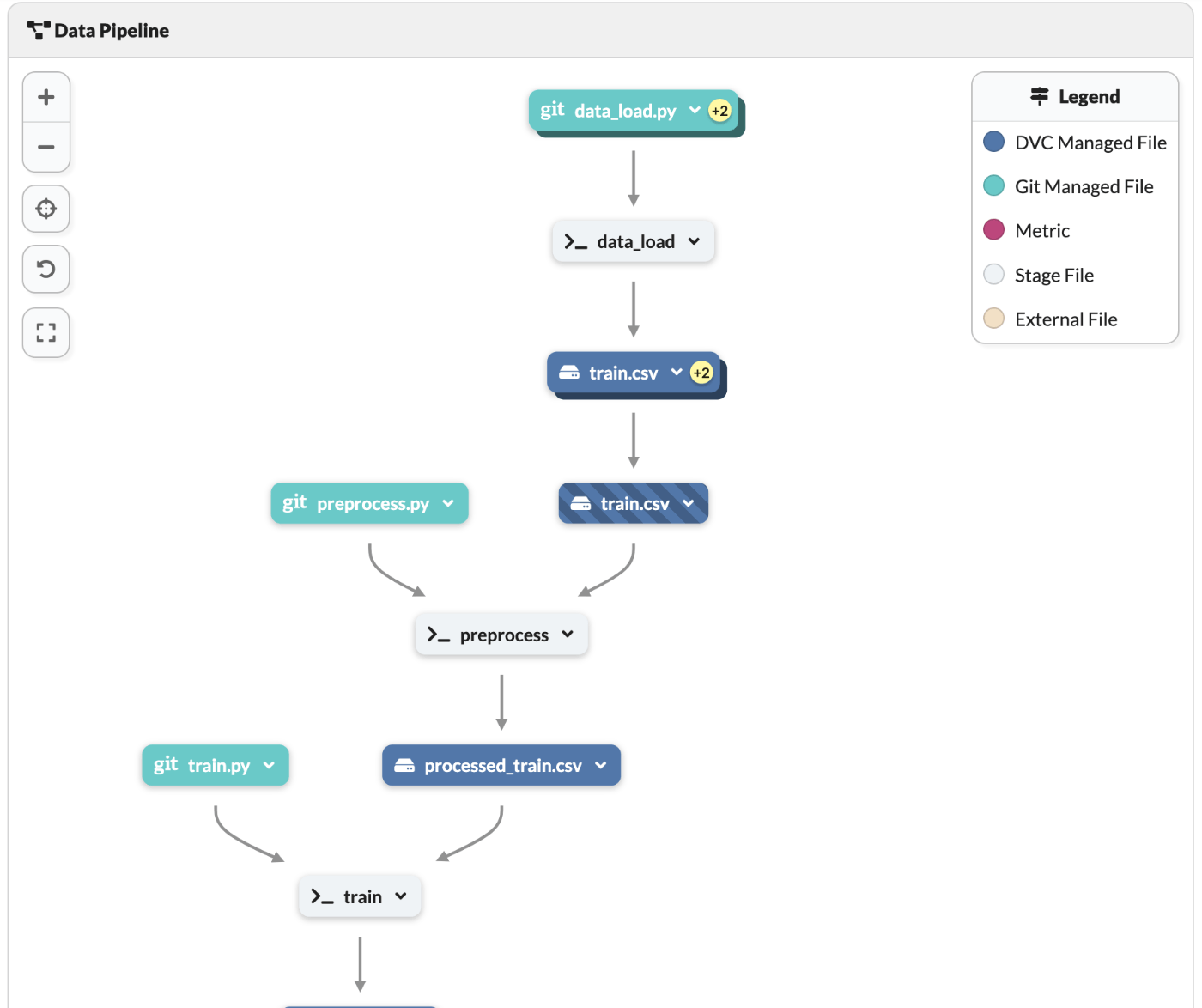
dvc addからではなく、data_loadによってデータが読み込まれていることが分かる。
また、foreachによって3回繰り返されていることが分かる。
考察
今回data_loadのステップをパイプラインに組み込み、DagsHub Storageからデータを読み込んだ。
dvc addによる方法と比較して、一つ欠点があるように思ったので検証しつつ考察する。
結論
-
dvc addにより追跡対象としたファイルは、もし更新があったらキャッシュのデータを使わずに、更新されたファイルを読み込む。 -
DagsHub Storage上のファイルが更新されても、データの読み込みスクリプトに変更がない場合、data_loadステージがスキップされる(キャッシュの使用を回避するためには、
dvc reproコマンドに--forceオプションを指定する)。
前提
DVCではパイプラインの各ステージにおいて必要となる要素を、dvc.yamlのdepsにて定義している。
そして、depsにおいて定義した要素に更新があるか確認し、更新があればそのステージを実行、更新がなければそのステージを実行せずキャッシュを使用する。
検証
二つのデータ読み込みの方法を、それぞれブランチを分けて検証した。
dvc addによる方法
data/raw/train.csvの最終行と同じものをその下の行に追加してファイルを更新した。
890,1,1,"Behr, Mr. Karl Howell",male,26,0,0,111369,30,C148,C
891,0,3,"Dooley, Mr. Patrick",male,32,0,0,370376,7.75,,Q
891,0,3,"Dooley, Mr. Patrick",male,32,0,0,370376,7.75,,Q
その後パイプラインを実行した。
dvc repro
無事スキップされず実行された
$ dvc repro
Verifying data sources in stage: 'data/raw/train.csv.dvc'
Running stage 'preprocess':
> python code/preprocess.py data/raw/train.csv data/processed/processed_train.csv
Updating lock file 'dvc.lock'
Running stage 'train':
> python code/train.py data/processed/processed_train.csv model/model.pkl
Updating lock file 'dvc.lock'
DagsHub Storageから読み込む方法
local/train.csvのファイルを前項と同様に更新し、ストレージにアップロードした。
dagshub upload --bucket marcy/my-first-repo local/train.csv data/raw/train.csv
その後パイプラインを実行した。
dvc repro
データの更新が確認されず、data_loadステージがスキップされた。
$ dvc repro
Stage 'data_load@train' didn't change, skipping
Stage 'data_load@test' didn't change, skipping
Stage 'data_load@gender_submission' didn't change, skipping
Stage 'preprocess' didn't change, skipping
Stage 'train' didn't change, skipping
Data and pipelines are up to date.
原因・解決方法
前提で述べたように、depsにおいて定義した要素に更新があるか確認している。
DagsHub Storageから読み込む方法では、depsにファイルを指定せず、データ読み込みのスクリプトのみ指定している。
このため、DagsHub Storage上のファイルが更新されても、スクリプト自体に変更がない限り、スキップされる。
解決方法としては、-f --forceオプションを使用すると、スクリプトの変更の有無に関係なく、常に全ステージが再実行される。
データの削除
Dagshub Storageに間違ってデータをアップロードしてしまったとき、どのように削除するかを調べたが、結構時間がかかってしまったので、手順を残しておく。
結論
下記をPythonスクリプトかJupyterで実行する。
from dagshub import get_repo_bucket_client
s3 = get_repo_bucket_client("<username>/<repo_name>")
s3.delete_object(
Bucket=<repo_name>,
Key=<repo_path>,
)
方法
PythonでDagsHub APIのget_repo_bucket_clientを使用すると、DagsHub Storageをboto3のs3クライアントと同様に操作することができる。
そのため、「boto3 s3 delete object」等で検索することにより、方法を特定できた。