クラウドに頼らないMLOps基盤: Argo Workflows+MLflowを使ってKubernetes上にMLOps基盤を構築する




はじめに
クラウドに頼らないMLOps基盤を作ってみたくなり、Kubernetesに入門してみました。
クラウドサービスは便利ですが、コストや制約が気になることもあります。そこで、自宅のサーバーを活用して、Kubernetes上に独自のMLOps環境を構築することにしました。これにより、コストを抑えつつ、柔軟なシステムを実現できるのではないかと期待しています。
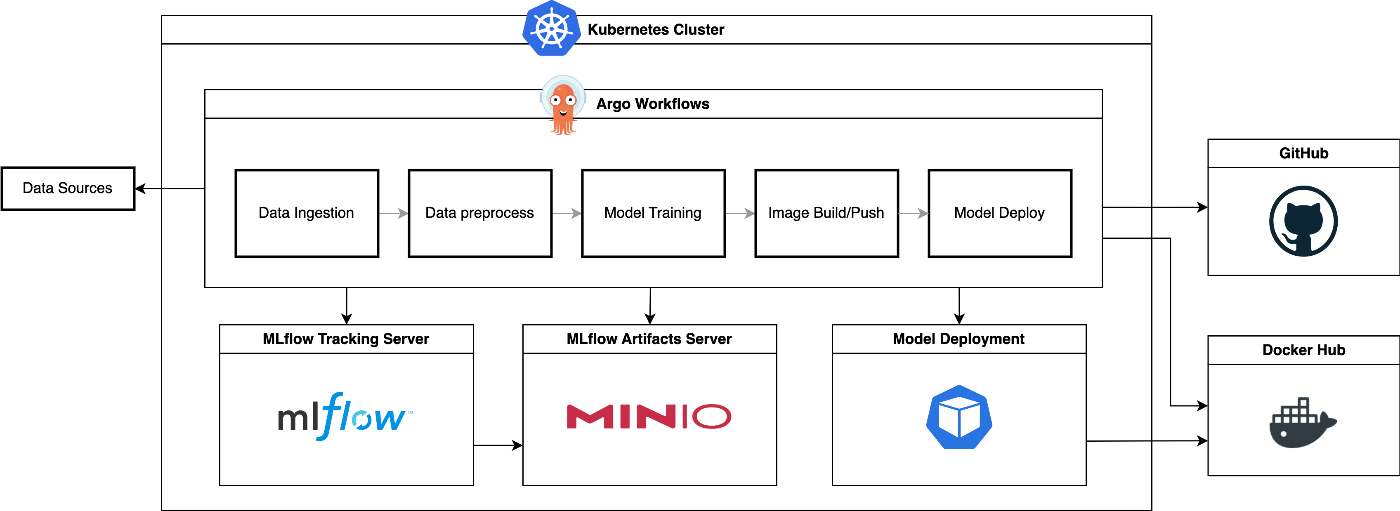
システム構成
様々あるワークフローツールの中で、k8sネイティブかつ軽量なツールということでArgo Workflowsを選定。
実験管理やデータ・モデルのバージョン管理は馴染みのあったMLflowを選定。アーティファクトサーバーにはMinIOを使います。
モデルのサービングはk8sのPodで実行します。
ソースコードの管理には、OSSのGitLabを使っても良かったのですが、その管理まで手をひろげるのは今回の主題から外れるため、GitHubを選定。
同様に、イメージリポジトリにはDocker Hubを選定。
まとめると以下のようなシステム構成図になります。
環境構築
ソースコード等は分割しながら説明していきますので、まとまったものはGitHubリポジトリをご確認ください。
クラスター作成
まずは、Kubernetesクラスターを作成するところから始めます。今回は軽量なクラスター管理ツールであるkind(Kubernetes IN Docker)を使用してクラスターを構築します。kindは、Dockerコンテナ内にKubernetesクラスターを作成するため、手軽に開発やテストを行うには最適です。
kindを使ってk8sクラスターを作成します。以下のコマンドを実行して、クラスターを作成します:
kind create cluster --name mlplatform
クラスターの作成が完了したら、kubectlを使って確認します。
kubectl cluster-info --context kind-mlplatform
Argo Workflowsのインストール
次に、Argo WorkflowsをKubernetesクラスターにインストールします。Argo Workflowsは、Kubernetes上で動作するワークフローツールで、複雑なワークフローの定義と実行が可能です。
- Argo Workflowsのインストール
公式ドキュメントに従って、Argo Workflowsをインストールします
ARGO_WORKFLOWS_VERSION="vX.Y.Z"
kubectl create namespace argo
kubectl apply -n argo -f "https://github.com/argoproj/argo-workflows/releases/download/${ARGO_WORKFLOWS_VERSION}/quick-start-minimal.yaml"
- Argo Workflows UIへのアクセス
Argo WorkflowsのUIにアクセスするためには、ポートフォワーディングを設定します
kubectl -n argo port-forward deployment/argo-server 2746:2746
ブラウザでhttps://localhost:2746にアクセスすると、Argo WorkflowsのUIが表示されます。
MLflowサーバーのインストール
MLflowサーバーの概要
次に、MLflowをKubernetesクラスターにインストールします。MLflowは、機械学習ライフサイクルを管理するためのオープンソースプラットフォームです。
ここで構築するMLflowサーバーは大きく以下3つのコンポーネントに分かれています。
- トラッキングサーバー
- バックエンドサーバー
- アーティファクトサーバー
トラッキングサーバーは、実験のメタデータをロギングするためのエンドポイントとして機能し、ログの結果を閲覧するためのUIでもあります。
バックエンドサーバーは、MLflowがメタデータを保存するためのデータベースのことを指します。今回は、PostgreSQLを使用します。
アーティファクトサーバーは、データや学習済みモデルなどのオブジェクトを保存するためのストレージとして機能します。今回は、MinIOを使用します。
マニフェストの作成
3つのコンポーネントをまとめて作成するマニフェストを作成していきます。
1. Namespaceの作成
MLflowのすべてのリソースを含むNamespaceを作成します。
apiVersion: v1
kind: Namespace
metadata:
name: mlflow
2. SecretsとConfigMapsの設定
Secret
PostgreSQLの認証情報やMinIOのアクセス情報をSecretとして管理します。
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
namespace: mlflow
type: Opaque
stringData:
POSTGRES_DB: mlflow
POSTGRES_USER: mlflow
POSTGRES_PASSWORD: password
---
apiVersion: v1
kind: Secret
metadata:
name: minio-secret
namespace: mlflow
type: Opaque
stringData:
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio123
ConfigMap
MLflowサーバーの設定をConfigMapとして管理します。
apiVersion: v1
kind: ConfigMap
metadata:
name: mlflow-config
namespace: mlflow
data:
BACKEND_STORE_URI: postgresql://mlflow:password@postgres:5432/mlflow
ARTIFACT_ROOT: s3://mlflow-artifacts/
MLFLOW_S3_ENDPOINT_URL: http://minio:9000
3. PostgreSQLのデプロイ
Deployment
PostgreSQLデータベースをデプロイします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
namespace: mlflow
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:13
env:
- name: POSTGRES_DB
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_DB
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_USER
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_PASSWORD
ports:
- containerPort: 5432
Service
PostgreSQLデータベースにアクセスするためのサービスを設定します。
apiVersion: v1
kind: Service
metadata:
name: postgres
namespace: mlflow
spec:
ports:
- port: 5432
selector:
app: postgres
4. MinIOのデプロイ
Deployment
MinIOサーバーをデプロイします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: minio
namespace: mlflow
spec:
replicas: 1
selector:
matchLabels:
app: minio
template:
metadata:
labels:
app: minio
spec:
containers:
- name: minio
image: minio/minio
args:
- server
- /data
- --console-address
- :9001
env:
- name: MINIO_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ACCESS_KEY
- name: MINIO_SECRET_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_SECRET_KEY
ports:
- containerPort: 9000
- containerPort: 9001
volumeMounts:
- name: minio-data
mountPath: /data
volumes:
- name: minio-data
emptyDir: {}
Service
MinIOサーバーにアクセスするためのサービスを設定します。
apiVersion: v1
kind: Service
metadata:
name: minio
namespace: mlflow
spec:
ports:
- name: minio
port: 9000
targetPort: 9000
- name: console
port: 9001
targetPort: 9001
selector:
app: minio
Job
MinIOのバケットを作成するためのジョブを設定します。
apiVersion: batch/v1
kind: Job
metadata:
name: create-minio-bucket
namespace: mlflow
spec:
template:
spec:
containers:
- name: mc
image: minio/mc
command: ["sh", "-c", "mc alias set myminio http://minio:9000 $MINIO_ACCESS_KEY $MINIO_SECRET_KEY && mc mb myminio/mlflow-artifacts"]
env:
- name: MINIO_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ACCESS_KEY
- name: MINIO_SECRET_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_SECRET_KEY
restartPolicy: OnFailure
5. MLflowのデプロイ
Deployment
MLflowサーバーをデプロイします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: mlflow
namespace: mlflow
spec:
replicas: 1
selector:
matchLabels:
app: mlflow
template:
metadata:
labels:
app: mlflow
spec:
containers:
- name: mlflow
image: bitnami/mlflow:2.14.2
command: ["mlflow", "server"]
args:
- "--backend-store-uri=$(BACKEND_STORE_URI)"
- "--default-artifact-root=$(ARTIFACT_ROOT)"
- "--host=0.0.0.0"
- "--port=5000"
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ACCESS_KEY
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_SECRET_KEY
envFrom:
- configMapRef:
name: mlflow-config
ports:
- containerPort: 5000
Service
MLflowサーバーにアクセスするためのサービスを設定します。
apiVersion: v1
kind: Service
metadata:
name: mlflow
namespace: mlflow
spec:
ports:
- port: 5000
selector:
app: mlflow
全てのマニフェストをまとめたものは以下のGitHubから
MLパイプラインの実装
今回のMLパイプラインでは、
- データ収集
- データの前処理
- モデル学習
- モデル評価
- イメージのビルド/プッシュ
- デプロイ
- 推論テスト
を順に実行します。
これらを実行するワークフローをArgo Workflowsによって定義していきます。
まとまったソースコードは以下のGitHubリポジトリからご確認ください。
データ収集〜イメージのビルド/プッシュ
Pythonスクリプト
1. 初期設定
MLflowのrunを作成するためだけのスクリプトです。
続くタスクで同じrunを使えるようにrun idを出力します。
import mlflow
def main():
with mlflow.start_run() as run:
run_id = run.info.run_id
print(run_id)
if __name__ == "__main__":
main()
2. データ収集
データ収集を行います。
今回はスタンフォード大学の講義で用いられているタイタニックのデータセットを使います。
pd.read_csv()でURLを指定して読み込み、アーティファクトとして保存します。
import pandas as pd
import mlflow
def main():
with mlflow.start_run() as run:
run_id = run.info.run_id
print(run_id)
# データのダウンロード
url = "https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv"
data = pd.read_csv(url)
# 前処理したデータを保存
data.to_csv("data.csv", index=False)
mlflow.log_artifact("data.csv", "raw")
mlflow.set_tag(key='ingest', value="done")
if __name__ == "__main__":
main()
3. データの前処理
データの前処理を行います。
収集したデータをアーティファクトサーバーから読み込み、前処理をした後、教師用特徴量データ/教師用ラベルデータ/テスト用特徴量データ/テスト用ラベルデータに分割します。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
import mlflow
import mlflow.sklearn
def main():
with mlflow.start_run() as run:
run_id = run.info.run_id
# データのダウンロード
mlflow.artifacts.download_artifacts(artifact_uri=f"runs:/{run_id}/raw", dst_path="./artifacts")
data = pd.read_csv("artifacts/raw/data.csv")
# 特徴量とラベルに分割
X = data.drop("Survived", axis=1)
y = data["Survived"]
# 前処理の定義
numeric_features = ["Age", "Fare", "Siblings/Spouses Aboard", "Parents/Children Aboard"]
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_features = ["Pclass", "Sex"]
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
]
)
X_preprocessed = preprocessor.fit_transform(X)
X_columns = preprocessor.get_feature_names_out()
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X_preprocessed, y, test_size=0.2, random_state=42)
# 前処理したデータを保存
pd.DataFrame(X_train, columns=X_columns).to_csv("X_train.csv", index=False)
pd.DataFrame(X_test, columns=X_columns).to_csv("X_test.csv", index=False)
pd.DataFrame(y_train).to_csv("y_train.csv", index=False)
pd.DataFrame(y_test).to_csv("y_test.csv", index=False)
mlflow.log_artifact("X_train.csv", "preprocess")
mlflow.log_artifact("X_test.csv", "preprocess")
mlflow.log_artifact("y_train.csv", "preprocess")
mlflow.log_artifact("y_test.csv", "preprocess")
mlflow.set_tag(key='preprocess', value="done")
if __name__ == "__main__":
main()
4. モデル学習
モデルの学習を行います。
前処理したデータをアーティファクトサーバーから読み込み、グリッドサーチ+ランダムフォレストで学習します。
学習したモデルはアーティファクトとして保存します。
import os
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
import mlflow
import mlflow.sklearn
from mlflow.models.signature import infer_signature
def main():
with mlflow.start_run() as run:
# データの読み込み
run_id = run.info.run_id
mlflow.artifacts.download_artifacts(artifact_uri=f"runs:/{run_id}/preprocess", dst_path="./artifacts")
X_train = pd.read_csv("artifacts/preprocess/X_train.csv")
y_train = pd.read_csv("artifacts/preprocess/y_train.csv")
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# モデルの学習
model = RandomForestClassifier(n_estimators=100, random_state=42)
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train.values.ravel())
best_model = grid_search.best_estimator_
# モデルの保存
model_signature = infer_signature(X_train, y_train)
mlflow.sklearn.log_model(
best_model,
"model",
registered_model_name=" GridSearch/RandomForestClassifier",
signature=model_signature
)
mlflow.set_tag(key='train', value="done")
if __name__ == "__main__":
main()
5. モデル評価
モデルの評価を行います。
学習したモデルとテスト用データをアーティファクトサーバーから読み込み、評価した後、評価結果をトラッキングサーバーに記録します。
import pandas as pd
from sklearn.metrics import accuracy_score, classification_report, precision_score, recall_score, f1_score, confusion_matrix
import mlflow
import mlflow.sklearn
def main():
with mlflow.start_run() as run:
# データの読み込み
run_id = run.info.run_id
mlflow.artifacts.download_artifacts(artifact_uri=f"runs:/{run_id}/preprocess", dst_path="./artifacts")
X_test = pd.read_csv("artifacts/preprocess/X_test.csv")
y_test = pd.read_csv("artifacts/preprocess/y_test.csv")
# モデルの読み込み
model = mlflow.sklearn.load_model(f"runs:/{run_id}/model")
# モデルの評価
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
precision = precision_score(y_test, predictions, average='weighted')
recall = recall_score(y_test, predictions, average='weighted')
f1 = f1_score(y_test, predictions, average='weighted')
report = classification_report(y_test, predictions)
conf_matrix = confusion_matrix(y_test, predictions)
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")
print(f"Classification Report:\n{report}")
print(f"Confusion Matrix:\n{conf_matrix}")
# メトリクスのログ
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("precision", precision)
mlflow.log_metric("recall", recall)
mlflow.log_metric("f1_score", f1)
mlflow.log_text(report, "classification_report.txt")
mlflow.log_text(str(conf_matrix), "confusion_matrix.txt")
mlflow.set_tag(key='evaluate', value="done")
if __name__ == "__main__":
main()
6. イメージのビルド/プッシュ
モデルを含むDockerイメージをビルドし、Docker Hubにプッシュします。
ビルドにはmlflow.models.build_docker()という関数を使います。
アーティファクトとして保存したモデルを指定するだけでビルドすることが可能です。
ビルド後、DockerHubにログインし、プッシュします。
import os
import mlflow
import docker
DOCKER_USERNAME = os.getenv("DOCKER_USERNAME")
DOCKER_PASSWORD = os.getenv("DOCKER_PASSWORD")
def main():
with mlflow.start_run() as run:
# モデルを含むDockerイメージのビルド
run_id = run.info.run_id
image_name = f"{DOCKER_USERNAME}/mlflow-model"
tag_name = f"{run_id:.5}"
image_tag = f"{image_name}:{tag_name}"
mlflow.models.build_docker(f"runs:/{run_id}/model", name=image_tag)
mlflow.set_tag(key='build_image', value="done")
client = docker.from_env()
image = client.images.get(image_tag)
image.tag(image_tag, tag="latest")
# ビルドしたイメージのプッシュ
client.login(username=DOCKER_USERNAME, password=DOCKER_PASSWORD)
client.images.push(image_name)
mlflow.set_tag(key='push_image', value="done")
mlflow.set_tag(key='image_name', value=image_tag)
print(image_tag)
if __name__ == "__main__":
main()
ワークフロー定義
MLproject
各スクリプトの実行はMLflow Projectsという機能を用いて定義します。
MLflow Projectsは、機械学習プロジェクトの実行環境と実行方法を簡潔に定義するための仕組みです。
私がMLflow Projectsを気に入っている点の一つは、Gitのリモートリポジトリを指定して実行できることです。この方法で実行すると、トラッキングサーバーに記録されるメタデータにリポジトリとバージョンが含まれるため、ソースコードのバージョン管理が容易になります。
以下がMLflow Projectsを実行するために必要なMLprojectファイルです。
name: mlflow-argo
conda_env: argo-workflows/conda_env.yaml
entry_points:
initialize:
command: "python mlflow-project/initialize.py"
ingest:
command: "python mlflow-project/ingest.py"
preprocess:
command: "python mlflow-project/preprocess.py"
train:
command: "python mlflow-project/train.py"
evaluate:
command: "python mlflow-project/evaluate.py"
build-image:
command: "python mlflow-project/build-image.py"
ワークフロー
大まかに、タスクとテンプレートの二つに分けてワークフローファイルを記述していきます。
タスク
タスクの定義では他タスクとの依存関係やテンプレート、パラメータを記述していきます。
今回はタスクを順番に実行していくので、そのように依存関係を定義しています。
また、データ収集タスク以降はMLprojectに必要なentrypointとrun_idのパラメータを定義しています。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: mlflow-preprocess-to-push-
spec:
entrypoint: main
volumes:
- name: docker-graph-storage
emptyDir: {}
templates:
- name: main
dag:
tasks:
- name: initialize
template: mlflow-initialize
- name: ingest
template: mlflow
arguments:
parameters:
- name: entry_point
value: ingest
- name: run_id
value: "{{tasks.initialize.outputs.result}}"
dependencies: [initialize]
- name: preprocess
template: mlflow
arguments:
parameters:
- name: entry_point
value: preprocess
- name: run_id
value: "{{tasks.initialize.outputs.result}}"
dependencies: [ingest]
- name: train
template: mlflow
arguments:
parameters:
- name: entry_point
value: train
- name: run_id
value: "{{tasks.initialize.outputs.result}}"
dependencies: [preprocess]
- name: evaluate
template: mlflow
arguments:
parameters:
- name: entry_point
value: evaluate
- name: run_id
value: "{{tasks.initialize.outputs.result}}"
dependencies: [train]
- name: build-image
template: mlflow-build
arguments:
parameters:
- name: entry_point
value: build-image
- name: run_id
value: "{{tasks.initialize.outputs.result}}"
dependencies: [evaluate]
テンプレート
テンプレート定義では、起動するコンテナのイメージやコンテナ内で実行するコマンドなどを記述していきます。
オプションとして、ハードウェアリソースの制約やサイドカーという機能についても設定することができます。
今回はほとんどのタスクでmlflowというテンプレートを使います。
このテンプレートではconda runにより仮想環境を指定しながらコマンドを実行します。実行するコマンドはmlflow runで、これはMLflow Projectsを実行するためのコマンドです。
他にも、コンテナ内で設定しておく必要のある環境変数等を定義しています。
ビルドタスクでは他のタスクとは異なるイメージを用いるため、テンプレートも別のものに分けています。
使うイメージは事前にビルドしておいたカスタムイメージとなっており、DockerとMinicondaが使えるようになっています。実行するコマンドはほとんど同じなのですが、Dockerを有効化するための処理を最初に実行しています。
- name: mlflow-initialize
container:
image: marcy326/mlflow-conda:py3.11
imagePullPolicy: Always
command: [
"conda", "run", "--no-capture-output", "-n", "mlflow-env",
"mlflow", "run", "https://github.com/marcy326/mlflow-argo.git"
]
args: [
"--entry-point", "initialize",
"--env-manager", "local"
]
env:
- name: MLFLOW_TRACKING_URI
value: "http://mlflow.mlflow:5000"
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ACCESS_KEY
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_SECRET_KEY
- name: MLFLOW_S3_ENDPOINT_URL
value: "http://minio.mlflow.svc.cluster.local:9000"
resources:
requests:
memory: "64Mi"
cpu: "250m"
- name: mlflow
inputs:
parameters:
- name: entry_point
- name: run_id
container:
image: marcy326/mlflow-conda:py3.11
imagePullPolicy: Always
command: [
"conda", "run", "--no-capture-output", "-n", "mlflow-env",
"mlflow", "run", "https://github.com/marcy326/mlflow-argo.git"
]
args: [
"--entry-point", "{{inputs.parameters.entry_point}}",
"--env-manager", "local",
"--run-id", "{{inputs.parameters.run_id}}"
]
env:
- name: MLFLOW_TRACKING_URI
value: "http://mlflow.mlflow:5000"
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ACCESS_KEY
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_SECRET_KEY
- name: MLFLOW_S3_ENDPOINT_URL
value: "http://minio.mlflow.svc.cluster.local:9000"
resources:
requests:
memory: "64Mi"
cpu: "250m"
- name: mlflow-build
inputs:
parameters:
- name: entry_point
- name: run_id
container:
image: marcy326/mlflow-conda:docker
imagePullPolicy: Always
command:
- /bin/sh
- -c
args:
- >
docker-entrypoint.sh &&
conda run --no-capture-output -n mlflow-env
mlflow run https://github.com/marcy326/mlflow-argo.git
--entry-point {{inputs.parameters.entry_point}}
--run-id {{inputs.parameters.run_id}}
--env-manager local
env:
- name: MLFLOW_TRACKING_URI
value: "http://mlflow.mlflow:5000"
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ACCESS_KEY
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_SECRET_KEY
- name: MLFLOW_S3_ENDPOINT_URL
value: "http://minio.mlflow.svc.cluster.local:9000"
- name: DOCKER_USERNAME
valueFrom:
secretKeyRef:
name: docker-secret
key: username
- name: DOCKER_PASSWORD
valueFrom:
secretKeyRef:
name: docker-secret
key: password
- name: DOCKER_HOST
value: "tcp://localhost:2375"
volumeMounts:
- name: docker-graph-storage
mountPath: /var/lib/docker
sidecars:
- name: dind
image: docker:20.10.7-dind
securityContext:
privileged: true
env:
- name: DOCKER_TLS_CERTDIR
value: ""
volumeMounts:
- name: docker-graph-storage
mountPath: /var/lib/docker
デプロイ〜推論テスト
Pythonスクリプト
1. デプロイ
デプロイだけはPythonではなく、タスク内のコマンドとしてkubectlを用いて実行します。
run_id={{inputs.parameters.run_id}}
image_name=marcy326/mlflow-model:${run_id:0:5}
echo $image_name
kubectl set image deployment/mlflow-model-deployment mlflow-model-container=$image_name -n mlmodel
kubectl scale deployment mlflow-model-deployment --replicas=1 -n mlmodel
kubectl rollout restart deployment/mlflow-model-deployment -n mlmodel
kubectl describe deployment mlflow-model-deployment -n mlmodel
2. 推論テスト
テスト用データを読み込み、デプロイしたサーバーに対してリクエストを送信します。
レスポンスとして返ってきた推論結果と評価用データを用いてaccuracyを算出します。
import requests
import json
import click
import mlflow
import pandas as pd
from sklearn.metrics import accuracy_score
@click.command()
@click.option('--url', required=True, help='The inference endpoint URL.')
def main(url):
with mlflow.start_run() as run:
run_id = run.info.run_id
mlflow.artifacts.download_artifacts(artifact_uri=f"runs:/{run_id}/preprocess", dst_path="./artifacts")
X_test = pd.read_csv("artifacts/preprocess/X_test.csv")
y_test = pd.read_csv("artifacts/preprocess/y_test.csv")
instances = X_test.to_dict(orient='records')
data = {"instances": instances}
# 推論リクエストを送信
response = requests.post(url, json=data)
response_data = response.json()
predictions = response_data.get('predictions', [])
truth = y_test["Survived"].to_list()
accuracy = accuracy_score(truth, predictions)
# レスポンスを表示
print(f"predictions: {predictions}")
print(f"truth: {truth}")
print(f"accuracy: {accuracy}")
if __name__ == "__main__":
main()
ワークフロー定義
タスク
前半と同様にタスク部分を記述します。
- name: deploy
template: mlflow-deploy
arguments:
parameters:
- name: run_id
value: "{{tasks.initialize.outputs.result}}"
dependencies: [build-image]
- name: test-inference
template: mlflow-inference
arguments:
parameters:
- name: run_id
value: "{{tasks.initialize.outputs.result}}"
- name: inference_url
value: "http://mlflow-model-service.mlmodel.svc.cluster.local:8080/invocations"
dependencies: [deploy]
テンプレート
デプロイタスクで用いるテンプレートではkubectlコマンドを使いたいため、そのセットアップが済んでいるイメージを利用します。
- name: mlflow-deploy
serviceAccountName: argo-deploy-sa
inputs:
parameters:
- name: run_id
container:
image: bitnami/kubectl:latest
command:
- bin/bash
- -c
args:
- |
run_id={{inputs.parameters.run_id}}
image_name=marcy326/mlflow-model:${run_id:0:5}
echo $image_name
kubectl set image deployment/mlflow-model-deployment mlflow-model-container=$image_name -n mlmodel
kubectl scale deployment mlflow-model-deployment --replicas=1 -n mlmodel
kubectl rollout restart deployment/mlflow-model-deployment -n mlmodel
kubectl describe deployment mlflow-model-deployment -n mlmodel
- name: mlflow-inference
inputs:
parameters:
- name: run_id
- name: inference_url
script:
image: marcy326/mlflow-conda:py3.11
imagePullPolicy: Always
command: [
"conda", "run", "--no-capture-output", "-n", "mlflow-env",
"mlflow", "run", "https://github.com/marcy326/mlflow-argo.git"
]
args: [
"--entry-point", "test-inference",
"--env-manager", "local",
"--run-id", "{{inputs.parameters.run_id}}",
"-P", "url={{inputs.parameters.inference_url}}"
]
env:
- name: MLFLOW_TRACKING_URI
value: "http://mlflow.mlflow:5000"
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ACCESS_KEY
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_SECRET_KEY
- name: MLFLOW_S3_ENDPOINT_URL
value: "http://minio.mlflow.svc.cluster.local:9000"
resources:
requests:
memory: "64Mi"
cpu: "250m"
ワークフローの実行と結果の確認
ワークフローの実行方法
それでは、定義したワークフローを実行してみましょう。Argo WorkflowsのCLIを使用して、以下のコマンドでワークフローを開始できます。
argo submit -n argo argo-workflows/workflow.yaml
環境構築では、argoNamespaceにSecrets等を作成していたので、ワークフローでも同様のNamespaceを使っていきます。
実行結果の確認
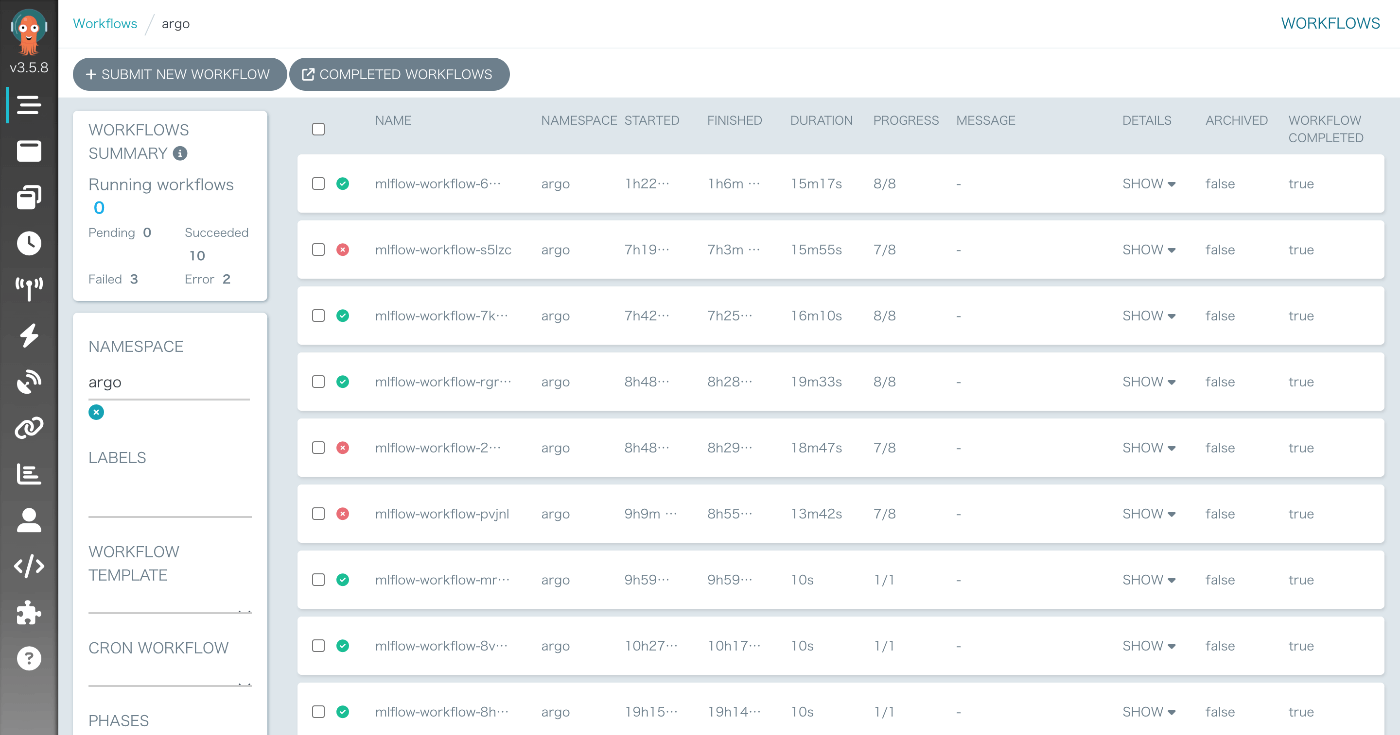
Argo Workflows
Argo WorkflowsのUIを開くと以下の画像のようにワークフローが実行されていることが確認できます。
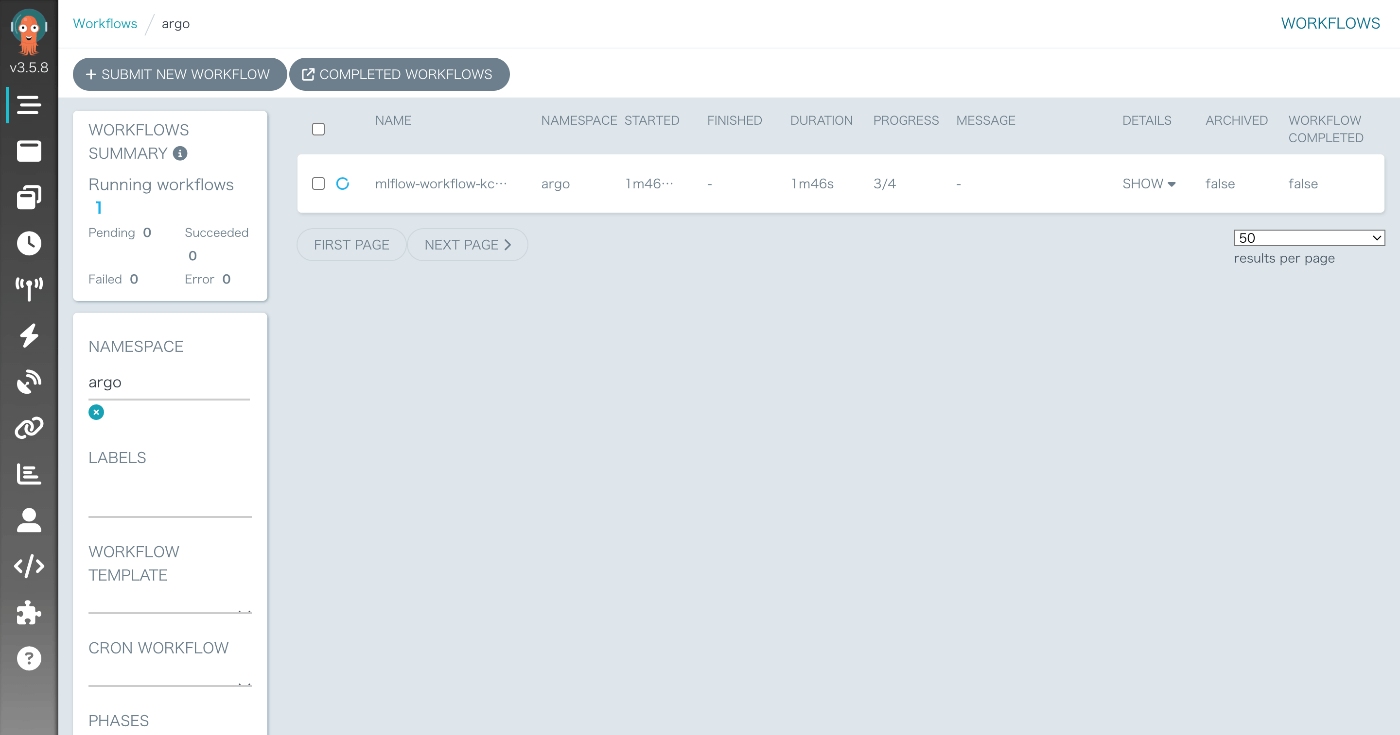
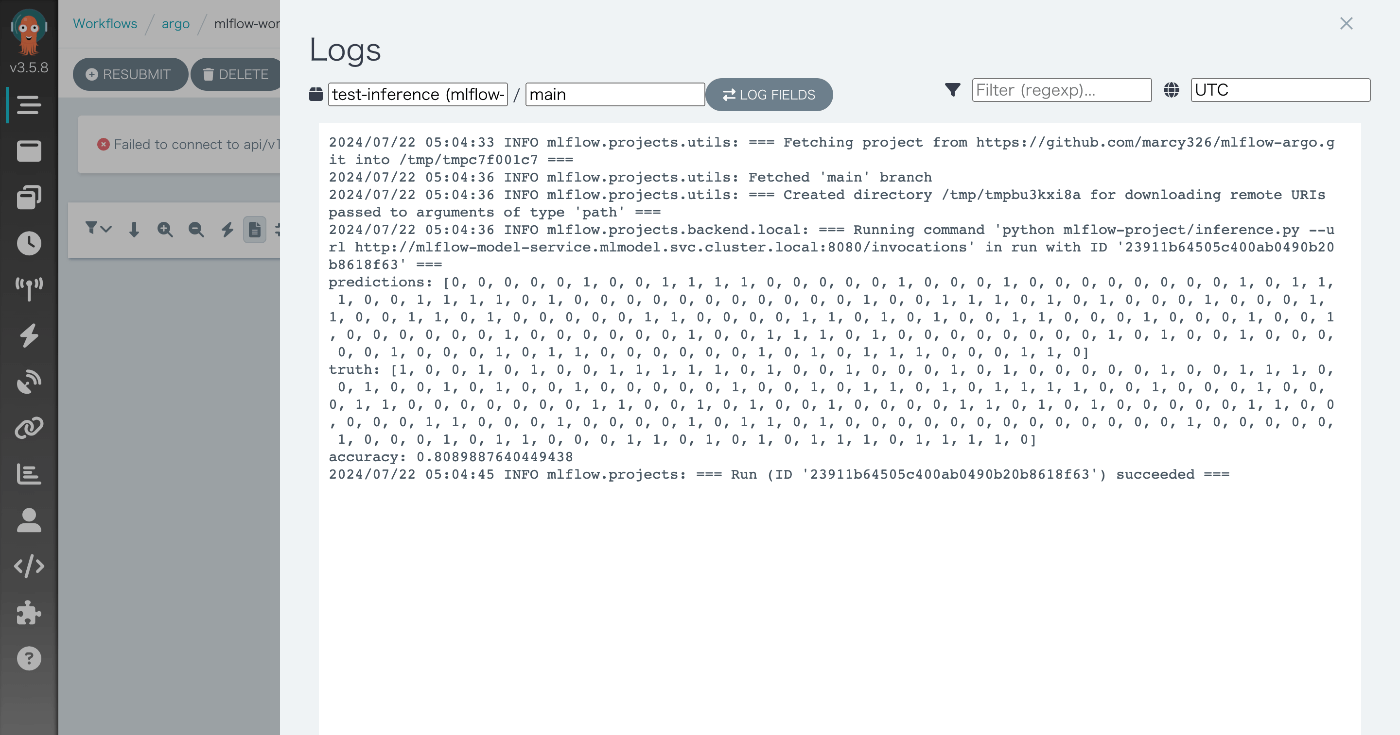
このワークフローをクリックすることでタスクの進行状況や各タスクのログを確認することができます。
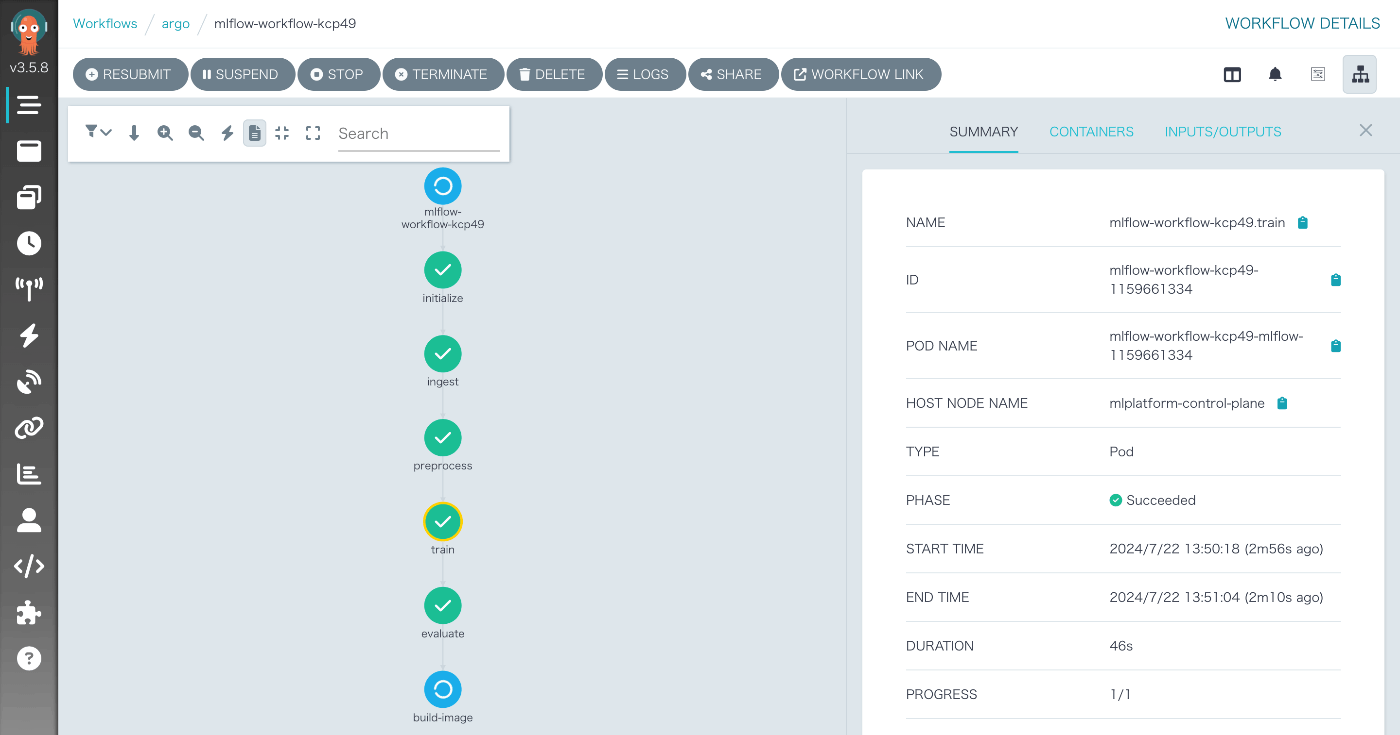
推論テストタスクのログを確認すると、デプロイしたサーバーから推論結果を取得できていることが分かります。
MLflow
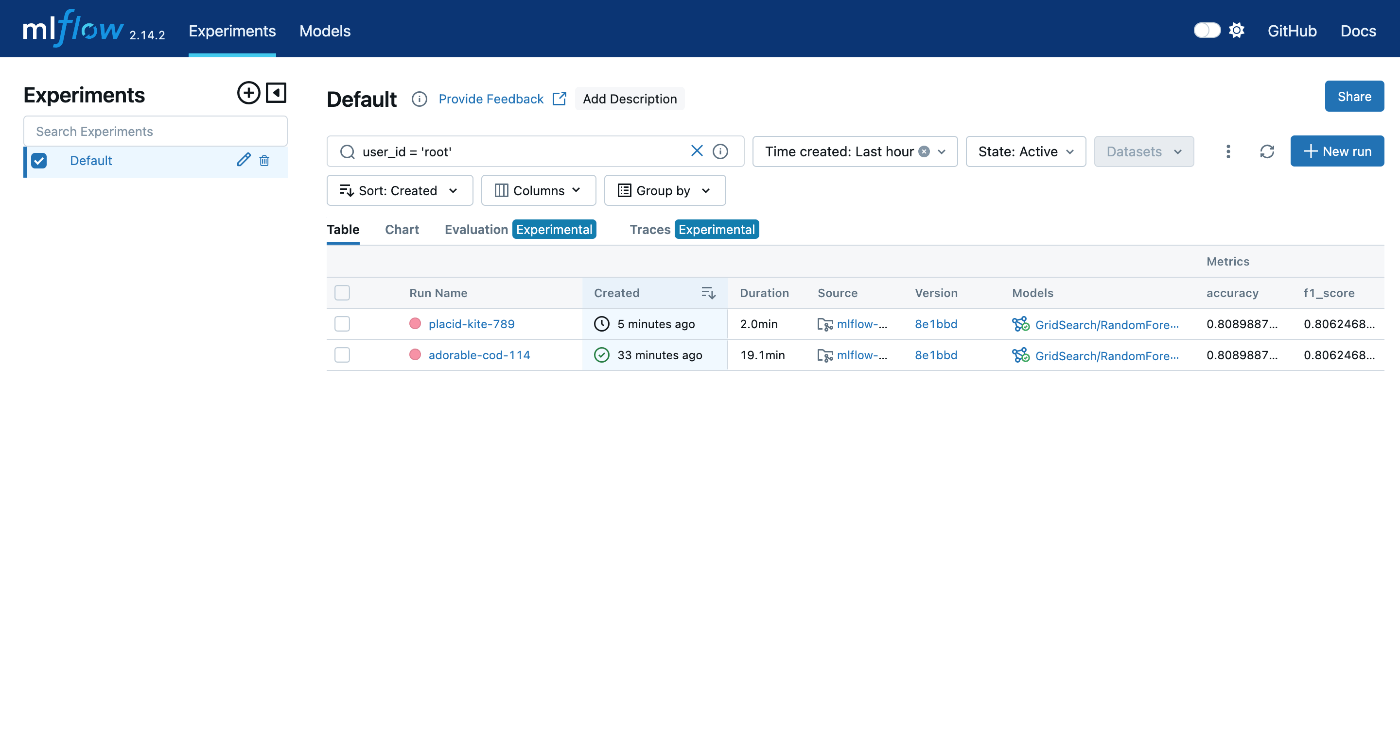
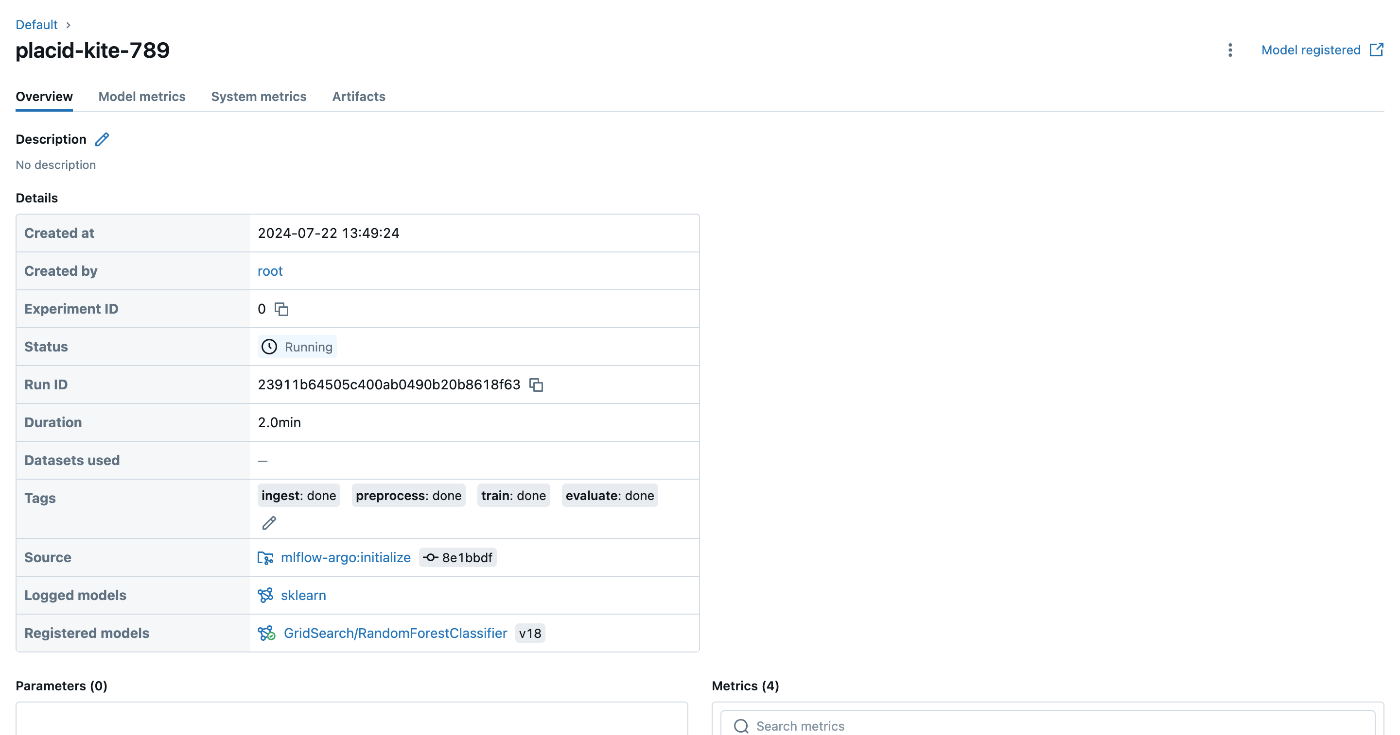
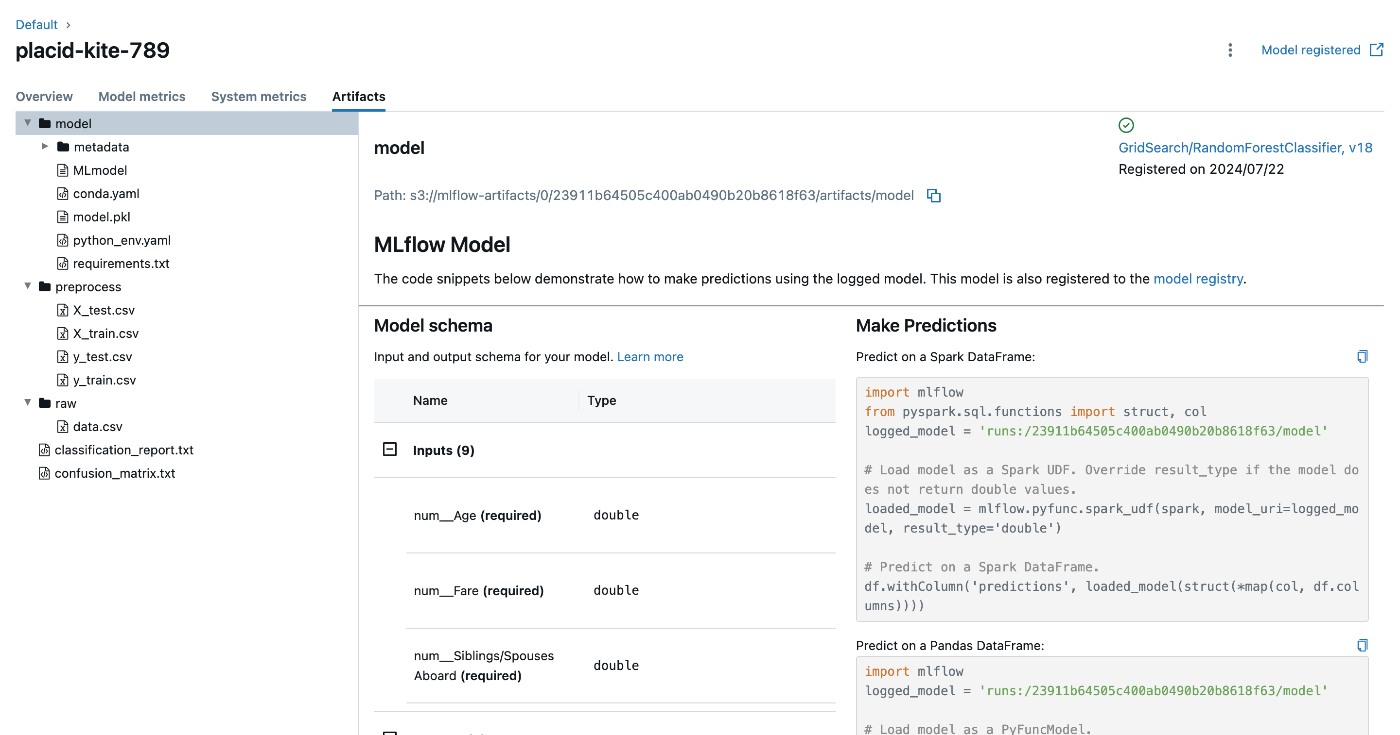
MLflowのUIを開くと以下の画像のようにロギングされていることが確認できます。
おわりに
まとめ
これで、Argo Workflowsを使用してMLflowによる機械学習ワークフローの実行、モデルのデプロイ、および推論テストまでの一連の流れを確認しました。今回の構成では、以下が重要なポイントとなりました。
-
Argo Workflowsの活用:
ワークフローをDAG形式で定義し、各ステップを独立したタスクとして実行。これにより、複雑なMLパイプラインを管理および自動化。 -
MLflow Projectsの使用:
各ステップ(前処理、トレーニング、評価、イメージのビルド)をMLflow Projectsとして定義し、再現可能な実行環境を提供。 -
モデルのデプロイと推論テスト:
ビルドされたDockerイメージを使用して、Kubernetes上にモデルをデプロイ。デプロイされたモデルに対して推論リクエストを送り、結果を評価。
これらの手法を活用することで、機械学習プロジェクトのワークフローを効率的に管理し、デプロイから推論までのプロセスを自動化することができます。また、MLflowのトラッキング機能を利用することで、実験の結果やモデルのバージョン管理も容易になります。
今後の課題
-
並列処理・分散学習:
Argo Workflowsは並列タスクと分散学習をサポートしています。今後、HorovodやRayなどと組み合わせ、大規模データセットの効率的なトレーニングを目指します。 -
モニタリング・視覚化:
ワークフローの進捗とリソース使用状況をリアルタイムで監視するため、Argo Workflowsのダッシュボード、Prometheus、Grafanaを活用します。これにより、パフォーマンスの最適化と迅速な障害対応が可能です。 -
CI/CD:
Argo WorkflowsをJenkinsやGitHub Actionsと連携させ、コードの変更を検知すると自動的にワークフローをトリガーします。これにより、テストやデプロイが自動化され、モデルのバージョン管理とリリース管理が強化されます。
以上、クラウドに頼らないMLOps基盤でした。
今後の課題に手をつけるか分かりませんが、進捗があれば続きます。
Discussion