データ修正で気をつけること-失敗を踏まえて




はじめに
エンジニア1年目を振り返った時に、とても印象に残った話が一つあるのでそれについて書きます。
社内業務システムの運用時にデータ修正を行うことがあるのですが、そこで起きた失敗と振り返りの話です。
背景
社内の1000人以上が利用する業務システムの運用の仕事の中に、ヘルプデスク対応というものがあります。
これは、事業部の方からプロダクトについての質問や依頼が開発部に寄せられ、その対応を行なう仕事です。
平均して週に10件ほど依頼が来て、チームメンバーで分担しながら対応していきます。
その中には、画面上から更新できないのでデータを直接修正して欲しいという依頼が来ることがあります。
運用で想定されていない何らかの特殊な操作をした場合、本来の想定と異なるデータが登録されてしまう場合があります。
そうなると、流入実績の計算等が異なるものになってくるので、事業部の方の評価や戦略に関わってくることになります。
そのため、開発部にヘルプデスクとしてデータ修正を依頼する運用フローになっています。
ちなみにデータベースはGoogle CloudのCloud SQLでPostgresを利用しています。
上記述べたようなデータ修正のフローがあり、運用ルールに従って定常タスクとして処理していました。
具体的には以下のようなフローになります。
- ヘルプデスクが来て、データ修正が必要となった場合、対応するJiraチケットを作成する
- 背景等を記入し、Jiraのコメントにクエリを書く
- 他のチームメンバーにダブルチェックを依頼する。
- ダブルチェック体制でクエリを確認してから、レビュワーと一緒に本番環境でクエリを実行する
この際、ダブルチェックの依頼された人がクエリのチェックも兼ねて見ることになります。
また、チームの共通ツールとしてDBeaver上で実行するルールとなっていました。
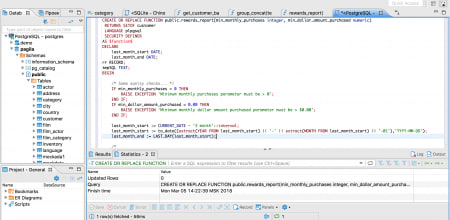
何が起きたか
結論、SQLのUPDATE文のWHERE句をつけ忘れて、あるテーブルの該当カラムの更新を全レコードに対して実行してしまいました。
状況としては、私がダブルチェックのレビュワーで、他のチームメンバー(先輩)のSQL実行を見守るような図式でした。
データの復旧に関しては、Cloud SQLのバックアップと別に存在する履歴テーブルを元にして、どうにか復旧することができました。
不幸中の幸いは、対象テーブルとその更新によって、事業の業務が止まらずに済んだことです。
しかし非常に重大なインシデントになりうるミスであることには変わりありません。
UPDATE文のWHERE句が無いという初歩的なミスをなぜ気付けなかったのか?
振り返りをすると、以下のような要因が挙げられました。
DBeaverのクライアントツール依存
本件のデータ修正は、実はDBeaver以外のクライアントツール、Table Plusを利用していました。
元々、DBeaverの設定では、手動コミットのチェックを外すことがチームルールとなっており、UI上からデフォルトでトランザクションを貼られることになります。
こうして、万一の時のために、意識的にコミットボタンを押さない限りデータ修正が反映されないような仕組みとなっていました。
しかし、実施時のTable PlusにはUI上でのトランザクションが設定されていませんでした。
私はてっきり、トランザクションが貼られているものと思い込んでいて、ヒューマンエラーがあってもROLLBACKできるだろうと気軽に構えていた節がありました。
「そういえばwhere句が無かったですね。rollbackの出番、いや?これもしかしてrollbackできない?あっ」
本来であれば、データ修正のためのSQL文は明示的にBEGIN~COMMITを書くことが必要です。
しかし、クライアントツールのDBeaverのUI設定に慣れていたため、その意識が希薄となっていました。
その他の要因
他にも細かい要因は幾つかあったように思います。
- データ修正自体は1レコード1カラムの更新のみのシンプルなパターンだったので大丈夫だろう、と逆に気楽に構えていた
- 先輩が書いたコードなので大丈夫だろうと、気楽に構えていた
- データ修正の背景理解が難しく、頭の片隅で逡巡していた
- 次の予定(ミーティング)が有ったので、モヤモヤを抱えながらも何かしら仕様があるのだろうと区切りをつけデータ修正を開始した
振り返りを通して変わったこと
本件のインシデントを開発チーム全体で振り返り、運用ルールが刷新されました。
個人の意識で気をつけましょうではヒューマンエラーの防止にはならないので仕組みで解決することを目指します。
刷新された点は以下になります。
データ修正手順書のテンプレートを作る
今までは、担当者が背景やクエリをJiraのコメントに自由に書いていくスタイルでした。
そうすると、クエリの書き方なども人それぞれで異なってくるので、ミスに気づかない要因となります。
手順書を作成することで、クエリのフォーマットも統一できるのでルールを強制できます。例えば、トランザクションもBEGINを含めることが明文化されます。
また、フォーマットに沿うことで内容も伝えやすくなるのでレビュワーの負担も小さくすることができます。
以下のような手順書となりました。
# 概要
* Jiraチケット: (チケットのURL)
* クエリ作成者、実行者: (名前)
* レビュー、ダブルチェック担当者: (名前)
* 背景: (データ修正が必要となった経緯と理由)
* 対象テーブル: (対象のテーブルと修正件数)
# レビュー観点
* [ ] バックアップと確認用のselect文があること
* [ ] UPDATE/DELETE文にはWHERE句があり、一つのレコードに特定できること
* [ ] updated_atの更新が含まれること
# 手順
1. DBに接続する
psql ...
2. トランザクションを貼る
database_name=> BEGIN;
3. バックアップ用のSQL実行
database_name=> SELECT ...
4. データ修正のSQL実行
database_name=> UPDATE ...
5. 想定通りにデータが修正されたか確認する
database_name=> SELECT ...
6. 想定通りであればCOMMIT
database_name=> COMMIT;
7. 実行履歴のログを貼る
...
psqlコマンドで実行する
GUIのクライアントツールを使わずにpsqlコマンドでデータ修正を実行するようになりました。
GUIツールでデータ修正を実行すると以下のようなデメリットが挙げられました。
- UIに依存するので、バージョンアップのたびに手順書を更新する必要がある
- UI上で間違った操作をするリスクがある
- トランザクションを貼る意識が希薄になる
- 記録が残しづらい
- 今までは実行履歴をツールのスクショで貼っていた
また、psqlコマンドを利用することで以下のメリットがあります
- レビューが通った手順書のコマンドをコピペして実行するだけなので、作業が明確になる
- コマンドラインの実行履歴を残せるので、誰が見ても操作が明確に分かる
- テキストベースで記録が残るので、後から検索もしやすくなる
このようなメリットが享受できるため、今後データ修正はGUIツールではなくpsqlコマンドで実行することになりました。
GUIツールは、あくまでRead ReplicaのDB専用にデータ閲覧のためだけに使うというルールとなりました。
改めて、データ修正の運用フローは以下のようになりました。
- ヘルプデスクが来て、データ修正が必要となった場合、対応するJiraチケットを作成する
- データ修正手順書のテンプレートに沿って、背景やクエリを埋めていく
- 年次が高い他のチームメンバーにクエリレビューを依頼する
- クエリレビューが通ったら、ダブルチェック体制でレビュワーと一緒に、手順書に沿って本番環境でクエリを実行する
まとめ
UPDATE文にWHERE句を書かずに実行してしまったインシデントと、その振り返りについて書きました。
SQLのUPDATEとDELETEは、事故の元になるので慎重に考える必要があるんだなということを痛感しました。
蛇足ですが、MySQLでは言語レベルでWHERE句の無いUPDATE文やDELETE文を弾くオプションをつけることができるようです。
MySQL
振り返りにあたっては、新しい運用フローを制定する過程で、経験豊富な先輩方のアドバイスや議論が多くありました。
運用フロー刷新以降は、データ修正にまつわるミスやインシデントは一度も起きていません。
色々な議論の積み重ねでルールが定まっていくことを実感する機会となりました。
Discussion