Open4
【AI/LLM】次世代AI評価の最前線:HLE(HUMANITY’S LAST EXAM)で見るLLMの現状と課題について📝
次世代AI評価の最前線:HLEで見るLLMの現状と課題📝
HLEの構成
ベンチマークは、公開されている2,500問の設問で構成されています。
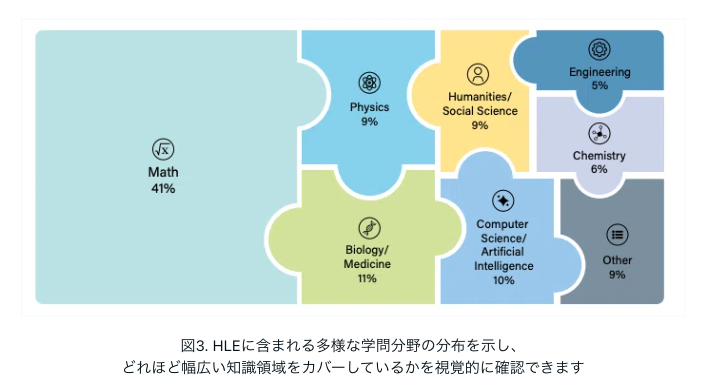
論文では、設問を以下の大まかな科目に分類しています。数学(41%)、物理学(9%)、生物学/医学(11%)、人文科学/社会科学(9%)、コンピュータサイエンス/人工知能(10%)、工学(4%)、化学(7%)、その他(9%)。
設問の約14%は、テキストと画像の両方を理解する能力、すなわちマルチモダリティを必要とします。
設問の24%は多肢選択式、残りは短答式の完全一致設問です。
ベンチマークの過剰適合をテストするための非公開設問も用意されています。
HLE 評価Script📝
HLE DataSet📝
推論の深さと知識の広さ📝
Humanity's Last Exam (Text Only) LeaderBoard📝
HLE Datasets📝
HLEスコアが高いLLMモデル:Grok4について分析する📝
STEM分野のデータセットについて📝