Open5
【DB設計】SQLアンチパターンについて
ピン留めされたアイテム
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
ピン留めされたアイテム
SQLアンチパターン・チートシート📝
Bill Karwin著「SQL Antipatterns」(O’Reilly)の書籍に基づく、代表的なSQLアンチパターンを整理したチートシートにしました📝
各アンチパターンは大きく「論理データベース設計」「物理データベース設計」「クエリ」「アプリケーション開発」の4カテゴリに分けられています。
表中の「回避策」は一例であり、実装環境や要件に応じて最適化してください。
| アンチパターン名 | カテゴリ | 説明 | 回避策の例 |
|---|---|---|---|
| Jaywalking | 論理DB設計 | 属性を列として横に増やし(EAVパターン)、スキーマを柔軟化しようとしてデータ整合性・検索性を損なう | 正規化されたテーブル設計、EAV回避、必要なら専用のメタデータテーブル・正規的なスキーマ進化ツール利用 |
| Naive Trees | 論理DB設計 | 階層データを単純な親IDカラム(隣接リスト)のみで表現し、ツリー操作が複雑化・非効率に | 組み込みの階層構造対応(RCTE)、Nested SetやClosure Tableなどの適切な階層モデル採用 |
| ID Required | 論理DB設計 | 全てのテーブルに無条件でサロゲートキー(ID)を導入し、自然キー活用の機会を失う | 自然キーや複合キーが意味を持つ場合は積極的に活用し、必要な場面のみサロゲートキー使用 |
| Keyless Entry | 論理DB設計 | 主キーなしテーブルを用いて重複データや更新矛盾を招く | 全てのテーブルに一意に識別できる主キー(自然キーまたはサロゲートキー)を定義 |
| Entity-Attribute-Value (EAV) | 論理DB設計 | 属性名や値を行として格納し、スキーマの柔軟性を狙うが、検索・制約・パフォーマンスの問題を引き起こす | 正規化されたスキーマ、動的スキーマが必要な場合はJSON型・NoSQL利用や柔軟なスキーマ管理手法 |
| Polymorphic Associations | 論理DB設計 | 一つの外部キー列で複数テーブルを参照する(多態的関連付け)構造をとりデータ整合性やクエリが複雑化 | 中間テーブル利用、ビューやアプリケーション側ロジックで明示的に関連先を区別 |
| Metadata Tribbles | 論理DB設計 | メタデータ的情報をテーブル行として無制限に増やし、スキーマ管理が複雑化 | スキーマ進化用ツールの利用、適切な正規化、メタデータは必要最小限で管理 |
| Fear of the Unknown | 物理DB設計 | NULLを避けて特定の「ダミー値」を用いることで、意味不明な値や不整合を生む | NULLを適切に活用、CHECK制約やNOT NULL制約で意味を明確化 |
| Phantom Files | 物理DB設計 | 大容量バイナリやファイルをDB内に格納しパフォーマンス劣化やバックアップ問題を引き起こす | ファイルストレージやオブジェクトストレージとのハイブリッド設計、BLOBは必要最小限に |
| Index Shotgun | 物理DB設計 | 安易に多数のインデックスを作成し、更新コストやストレージ使用量増大を招く | クエリパターンの分析、必要最小限のインデックス設計、定期的なインデックス見直し |
| Ambiguous Groups | クエリ | GROUP BY句で非集約列を正しく扱わず、非決定的な結果を返す | ANSI SQL準拠で全ての非集約列をGROUP BYに明示、または適切な集計ロジック見直し |
| Random Selection | クエリ | ORDER BY RAND()のような非効率なランダム取得でパフォーマンス低下 | 専用のランダムサンプリング手法、乱数列を事前付与、テーブルサンプリング機能活用 |
| Poor Man’s Search Engine | クエリ | LIKE演算子等で全文検索を実装しパフォーマンス問題・機能不足を起こす | 専用の全文検索エンジン(全文索引)、Elasticsearch、DBの全文検索機能(FULLTEXT INDEX)活用 |
| Spaghetti Query | クエリ | 複雑過ぎる長大なSQLで保守性、可読性、性能を悪化 | クエリ分割、ビュー/CTEで論理的分離、適切な正規化やアプリ側ロジック整理 |
| Implicit Columns | クエリ | SELECT * に依存し、スキーマ変更で意図せぬ結果やパフォーマンス劣化を招く | 必要なカラムを明示的に指定、スキーマ変更時の影響範囲管理 |
| SQL Injection (Trojan Horse) | アプリ開発 | ユーザ入力を直接SQL文字列に埋め込み、SQLインジェクションを招く | プレースホルダ、バインド変数、ORMのクエリビルダ、適切なエスケープ処理 |
| Reinventing the Wheel | アプリ開発 | DBの標準機能(トランザクション、整合性制約、集計機能など)を無視し、アプリ側で独自実装 | DBの機能活用、トランザクションや制約を正しく設計、SQL標準関数の活用 |
| Hardwired SQL | アプリ開発 | コード中にSQL文字列をベタ書きし、変更や再利用が困難 | SQLを外部ファイルやビューに分離、パラメトリ化、ORMやビルダーパターン活用 |
| Interchangeable Parts | アプリ開発 | アプリとDBスキーマが過度に結合し、スキーマ変更がアプリ全体に波及 | 抽象化レイヤー、マイグレーションツール、スキーマ変更に強いアプリ設計 |
| RBAR (Row-By-Agonizing-Row) | アプリ開発 | 1行ずつ処理するロジックでパフォーマンスを大幅低下 | セット指向処理、集合関数、JOINやサブクエリを用いた集合演算活用 |
| The Kitchen Sink | アプリ開発 | 複雑なロジックを全てDB側で処理させ、メンテナンス困難に | 適切な役割分担、ストアドプロシージャやファンクションの適量利用、アプリ側ロジックとDBロジックのバランス調整 |
上記は代表的なアンチパターン例であり、書籍にはこれら以外にも類似・関連するアンチパターンや詳細が記されています。
実際のプロジェクトでは、これらの指摘を踏まえて適切なデザイン・実装戦略を検討してください。
SQLアンチパターン(失敗パターン・失敗事例)とは?
- SQLアンチパターンは、データベース設計やSQLの記述において避けるべき一般的な間違いや誤った実践を指します。
- これには、非効率的なクエリ、データ整合性の問題、スケーラビリティの問題など、様々な問題が含まれます。
- 例えば、NULLを適切に扱わない、適切なデータ型を使用しない、過度に複雑なクエリを書くなどが挙げられます。
- これらのアンチパターンを避けることで、より効率的で、メンテナンスしやすく、信頼性の高いデータベースシステムを設計することが可能になります 。
アンチパターンとは?
- アンチパターンとは、ソフトウェア開発におけるよくある失敗パターンを整理し、それを回避する方法をまとめたものです。
- SQLはデータベースと違い、厳密性よりもパフォーマンスやバグに関する問題点が浮上しやすいことが特徴です。
SQLアンチパターンの種類
SQLアンチパターンには、次のようなものがあります。
- 主キーの規約を確立することを目的として、UNIQUE制約を貼ったサロゲートキーではなく複合キーを用いれば重複を回避できるケース
- ポリモーフィック関連
- テーブルスキャンと呼ばれる手法
- 複数のテーブルと関連をもたせるために、親テーブルの名前を格納するカラムを作成する
参考・引用
SQLアンチパターンのEAV(Entity-Attribute-Value)について
EAV(Entity-Attribute-Value)とは?
- EAV(Entity-Attribute-Value)は、属性と値の対応関係を表すテーブルです。
- EAVは、属性が動的かつ多様であるようなデータを効果的に保存する方法として使用されます。
- 特に、属性の数や種類が固定されていない場合に有用です。
- ただし、EAVモデルはいくつかのメリットとデメリットを持っているため、適切な使用場面を選択する必要があります。
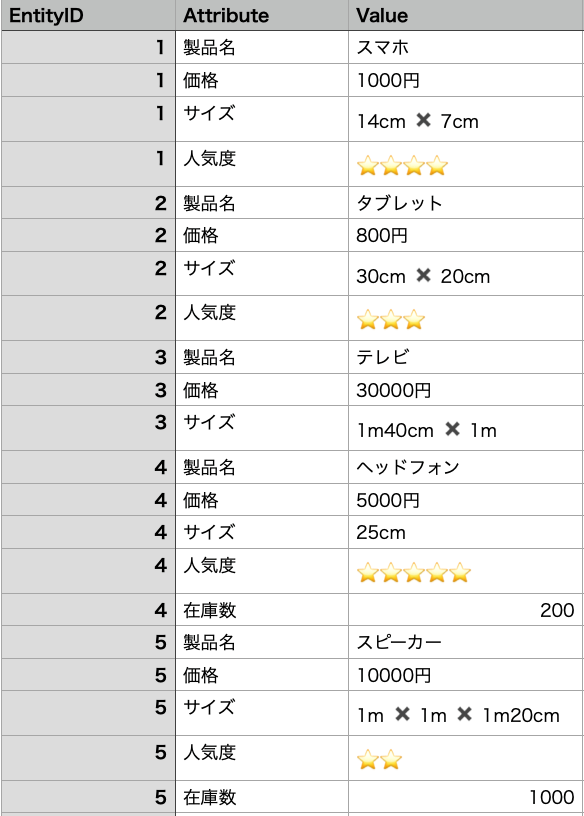
- EAV では、エンティティ(データベース内で区別される対象やオブジェクト)、属性(エンティティに関連する特性や情報の名前)、値(エンティティの属性に対応する実際のデータ)の3つの要素を持つテーブルを使用してデータを保存します。
- ここでは、 製品名、価格、サイズ、在庫数、人気度の5つの属性を持つデータをいくつか示しています。各エンティティ(EntityID)に対して、それぞれの属性(Attribute)と値(Value)が関連付けられています。
- このように、データベース内でのエンティティと属性の数が多様であり、柔軟性が求められる場合に EAV は有用です。
参考・引用
【DB設計】柔軟なデータに対するテーブル設計とEAVについて