Pythonを使用したデータサイエンスに入門してみた📝
データサイエンスに入門する(『マナビDXクエス』に参加する )
タイトルのとおり『FrontEndエンジニアが、Pythonを使用したデータサイエンスに入門してみた』ので、その学習記録(Log)をここに、Outputしていきたいと思います。
データサイエンスに入門するために、この『マナビDXクエス』に参加してみます。
スペック
- FrontEndエンジニア3年目
- メインで使用している技術は、JavaScript, TypeScript, React, Next.js, Vue, Nuxt.js, Docker, PHP, Laravelなど。
- Pythonは、ちょっと書ける程度(実務で少しだけ使っていたので、基本文法 & Flaskがわかる程度)
CSVを読み込む際に UnicodeDecodeError: 'utf-8' codec can't decode Errorに遭遇
データ分析のために、CSVを読み込む際に、
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8f in position 0: invalid start byte
エラーに遭遇。
上記エラーは、文字コードが違うというError。
日本語が入っているcsvファイルは、UTF-8では、読めないからShift_JIS に変更しろってことなので、
Pandasでの CSV読み込みに encoding="shift-jis"を設定します。
import pandas as pd
import pprint
# df = pd.read_csv("デモ_商品カテゴリ別集計.csv", encoding="utf-8")
df = pd.read_csv("デモ_商品カテゴリ別集計.csv", encoding="shift-jis")
pprint.pprint(df)
そもそもPandasとは?
Pandas(パンダス)とは、データ解析を容易にする機能を提供するPythonのデータ解析ライブラリです。
Pandasの特徴には、データフレーム(DataFrame)などの独自のデータ構造が提供されており、様々な処理が可能です。
特に、表形式のデータをSQLまたはRのように操作することが可能で、かつ高速で処理出来ます。
Pandasでできること。
- CSVやExcel、RDBなどにデータを入出力できる
- データ前処理(NaN / Not a Number、欠損値)
- データの結合や部分的な取り出しやピボッド(pivot)処理
- データの集約及びグループ演算
- データに対しての統計処理及び回帰処理
Pandasのメリット
- 多種の型のデータを一つのデータフレームで扱えること
- データ加工や解析の関数が多いこと
Pythonで、グループ化したDataの『合計値』『平均値』『最大値』を算出するには?
次のような実装で、グループ化したDataの『合計値』『平均値』『最大値』を算出することができる。
import pandas as pd
import pprint
# 1. 分析対象となる元_Data
data = {
"ColumnA": ["A", "B", "C", "A", "B", "A"],
"ColumnB": [1, 2, 3, 1, 2, 1],
"Value": [10, 20, 15, 25, 30, 35],
}
# 2. データをDataFrameで、読み込む => データが成形される
df = pd.DataFrame(data)
pprint.pprint(df)
# ColumnA ColumnB Value
# 0 A 1 10
# 1 B 2 20
# 2 C 3 15
# 3 A 1 25
# 4 B 2 30
# 5 A 1 35
# 3. 特定の Columnでグループ化する => ColumnAで、グループ化する
grouped = df.groupby("ColumnA")
# 同じ値で、グループ分けする => 1は3つ, 2は2つ, 3は1つ ある。
# 4. ColumnA の各グループの合計値を計算する
sum_by_group = grouped["Value"].sum()
pprint.pprint(sum_by_group)
# ColumnA
# A 70
# B 50
# C 15
# Name: Value, dtype: int64
# 5. ColumnA の各グループの平均値を計算する
mean_by_group = grouped["Value"].mean()
pprint.pprint(mean_by_group)
# ColumnA
# A 23.333333
# B 25.000000
# C 15.000000
# Name: Value, dtype: float64
# 6. ColumnA の各グループの最大値を計算する
max_by_group = grouped["Value"].max()
pprint.pprint(max_by_group)
# ColumnA
# A 35
# B 30
# C 15
# Name: Value, dtype: int64
matplotlib で、グラフを作成する
matplotlib とは、Python 用のグラフ描画ライブラリです。
まずは、matplotlib を installする。
pip install matplotlib
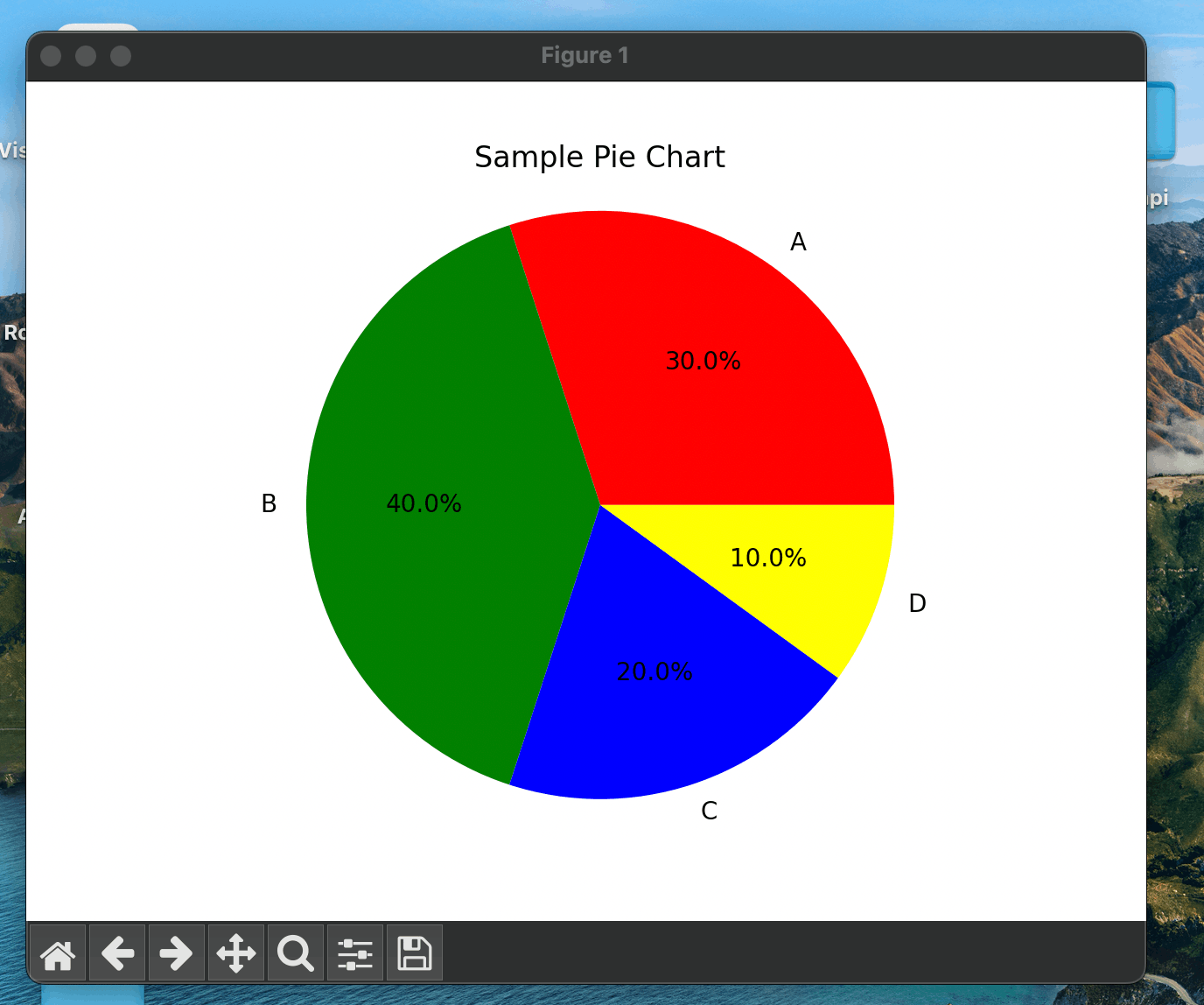
試しに、円グラフを描いてみる。
import matplotlib.pyplot as plt
# 各要素の大きさ
sizes = [30, 40, 20, 10]
# 各要素のラベル
labels = ["A", "B", "C", "D"]
# 各要素の色
colors = ["red", "green", "blue", "yellow"]
# パーセンテージを表示する位置
pctdistance = 0.6
# 円グラフを描画
plt.pie(
sizes,
explode=None,
labels=labels,
colors=colors,
autopct="%1.1f%%",
pctdistance=pctdistance,
)
# アスペクト比を保持して円形に描画
plt.axis("equal")
# グラフのタイトル
plt.title("Sample Pie Chart")
# グラフを表示
plt.show()
実行すると、次のような円グラフが作成できました。
【 参考・引用 】
pandasでxlsxファイル(Excel)を扱うときは、Openpyxlも必要なので注意
pandas で、xlsxファイル(Excel)を読み込もうとしたところ、
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.
上記の Errorに遭遇しました。
調べたところ、pandasでxlsxファイル(Excel)を扱うときは、openpyxlという Moduleが必要なので、別途 installします。
pip install openpyxl
【 参考・引用 】
Pandasで、作成した Dataフレームを使用して、matplotlibで円グラフを描く方法は?
import pandas as pd
import matplotlib.pyplot as plt
import pprint
# 1. Pandasで、DataFlameを作成する
df = pd.read_excel("デモ_円グラフの描画用ファイル.xlsx", sheet_name="商品カテゴリ別売上割合")
# 〜 ここに、「前処理(必要に応じて)」や「円グラフの描画」を行うソースコードを記述する 〜
pprint.pprint(df)
# 商品カテゴリ 売上割合
# 0 スナック類 50
# 1 チョコレート類 20
# 2 グミ・ガム類 20
# 3 その他 10
# 2. DataFlameから、円グラフを作成したい 売上割合_Column のDataを抽出する。
values = df["売上割合"]
# 円グラフを描画・作成する
plt.pie(values, labels=df["商品カテゴリ"], autopct="%1.1f%%")
# アスペクト比を保持して円形に描画
plt.axis("equal")
# グラフのタイトル
plt.title("お菓子のカテゴリ別の「売上割合」")
# グラフを表示する
plt.show()
Pandasのチートシート
初心者には、Pandasでできる Dataの操作が多すぎて戸惑うので、チートシートをまとめました。
条件による行の選択と並び替え
# 条件による行の選択
df[df['column_name'] == 'value'] # 特定の値をもつ行
df[(df['column_1'] > 10) & (df['column_2'] == 'value')] # 複数の条件を満たす行
# データの並び替え
df.sort_values(by='column_name', ascending=False) # 列の値で昇順または降順にソート
Pandasで、DataFlameの行数を countする方法は?
Pandasを使用してDataFrameの行数を数える方法には、次の 3つの方法があります。
これらの方法はすべてDataFrameの行数を得ることができますが、それぞれ特有の特徴があります。
なので、目的に応じてこれらの方法を使い分けるのがベストです。
-
len(df)を使用する方法-
len(df)はDataFrameのインデックス行の長さを返します。 - この方法は非常にシンプルで効率的ですが、行数だけが必要な場合に使用します。
-
行数 = len(df)
-
df.shape[0]を使用する方法-
df.shape[0]はDataFrameの形状属性を使って行数を得ます。 - shape属性は行数と列数をタプルで返します。
-
行数 = df.shape[0]
-
df.count()を使用する方法-
df.count()は各列ごとに非欠損値(NA値ではない値)の数を返します。 - DataFrame内の各列の非欠損値の数を取得したい場合に使用します。
-
行数 = df.count()
Test
import pandas as pd
import pprint
data = {
"Name": ["John", "Alice", "Bob"],
"Age": [30, 25, 28],
"City": ["New York", "Los Angeles", "Chicago"],
}
df = pd.DataFrame(data)
pprint.pprint(df)
print("-------------------------------------------------------")
row_len = len(df)
pprint.pprint(row_len)
print("-------------------------------------------------------")
実行結果
Name Age City
0 John 30 New York
1 Alice 25 Los Angeles
2 Bob 28 Chicago
-------------------------------------------------------
3
-------------------------------------------------------
Pandasで、特定の Column の Data が、空欄(欠損値)であるかどうかを判定する方法は?
import pandas as pd
# DataFrameを読み込む(例)
df = pd.read_csv('data/src/sample_pandas_normal_nan.csv')
# 特定のColumnの欠損値を判定
is_missing = df['column_name'].isnull()
# 欠損値の箇所を表示
print(is_missing)
Pandasを使用して特定のColumnのDataが空欄(欠損値)でないDataだけの DataFlameを取得する方法は?
-
特定のColumnのDataが空欄(欠損値)でないDataだけのDataFrameを取得する方法は、dropna()メソッドを使用することで実現できます。
-
dropna()メソッドは欠損値が含まれる行を削除することができますが、subset引数を使用して特定のColumnだけを対象にすることで、欠損値が含まれない行だけを取得できます。
import pandas as pd
# DataFrameを読み込む(例)
df = pd.read_csv('data/src/sample_pandas_normal_nan.csv')
# 特定のColumnのDataが空欄(欠損値)でないDataだけのDataFrameを取得
column_name = 'target_column'
df_not_null = df.dropna(subset=[column_name])
# 結果を表示
print(df_not_null)
Pandasで、同じ行(重複行)を削除する方法は?
重複した行を削除するにはdrop_duplicates()メソッドを使用します。
# 重複した行を削除します
df_no_duplicates = df.drop_duplicates()
print(df_no_duplicates)
-
このコードでは、
drop_duplicates()メソッドを使用してDataFrame (df) 内の重複した行を削除し、重複がない新しいDataFrame であるdf_no_duplicatesを作成しています。 -
drop_duplicates()メソッドはデフォルトではすべての列を比較して重複を削除しますが、特定の列だけを考慮したい場合はsubset引数を使用して指定することもできます。
# 'name'列を基準に重複を判定し、最初に出現した行を残す
df_no_duplicates = df.drop_duplicates(subset='name', keep='first')
print(df_no_duplicates)
Pandasで、同じ行(重複行)を抽出する方法は?
-
重複した行を抽出する方法は、
duplicated()メソッドを使用します。 -
これにより、DataFrameやSeries内で重複している行を検出できます。
import pandas as pd
# 例としてDataFrameを作成します
data = {
'name': ['Alice', 'Bob', 'Charlie', 'Dave', 'Ellen', 'Frank', 'Dave'],
'age': [24, 42, 18, 68, 24, 30, 68],
'state': ['NY', 'CA', 'CA', 'TX', 'CA', 'NY', 'TX'],
'point': [64, 92, 70, 70, 88, 57, 70]
}
df = pd.DataFrame(data)
# 重複した行を抽出します
duplicates = df.duplicated()
print(duplicates)
上記の例では、duplicated()メソッドを使用してDataFrame (df) 内の重複した行を検出しています。
結果は、各行が重複しているかどうかを示すブール値のSeriesとして表示されます。
Pandasで行と列を転置する方法は?
- T属性を使う方法
- PandasのDataFrameオブジェクトには、T属性を使うことで転置されたDataFrameを取得することができます。
- この方法では、元のDataFrameは変更されず、転置された新しいDataFrameが返されます。
import pandas as pd
# サンプルのDataFrameを作成
df = pd.DataFrame({'X': [0, 1, 2], 'Y': [3, 4, 5]}, index=['A', 'B', 'C'])
print("元のDataFrame:")
print(df)
# DataFrameを転置する
transposed_df = df.T
print("転置されたDataFrame:")
print(transposed_df)
- transpose()メソッドを使う方法
- transpose()メソッドを使用する方法もあり、T属性と同様に、元のDataFrameは変更されず、転置された新しいDataFrameが返されます。
import pandas as pd
# サンプルのDataFrameを作成
df = pd.DataFrame({'X': [0, 1, 2], 'Y': [3, 4, 5]}, index=['A', 'B', 'C'])
print("元のDataFrame:")
print(df)
# DataFrameを転置する
transposed_df = df.transpose()
print("転置されたDataFrame:")
print(transposed_df)
Pandasで、2つの表を縦方向に連結する方法は?
- Pandasを使用して2つの表を縦方向に連結する方法は、pd.concat()関数を使用します。
- pd.concat()関数は、指定した複数のデータフレームを縦方向に連結することができます。
- 引数axisに0を指定することで、縦方向に連結します。
- pd.concat([df1, df2], axis=0)という形でpd.concat()関数を使い、2つのデータフレームを縦方向に連結します。
import pandas as pd
df1 = pd.DataFrame({'name': ['A', 'B', 'C', 'D', 'E'],
'class': ['df01', 'df01', 'df01', 'df01', 'df01'],
'math': [60, 70, 80, 90, 100]})
df2 = pd.DataFrame({'name': ['A', 'B', 'C', 'D'],
'class': ['df02', 'df02', 'df02', 'df02'],
'english': [100, 90, 80, 70]})
# データフレームを縦方向に連結します
result_df = pd.concat([df1, df2], axis=0)
Pandasで、2つの表を内部結合するには?
- Pandasで、表「 新規顧客.csv 」と表「 顧客別売上集計.csv 」を、列「 顧客ID 」をキーとして内部結合する場合は次のとおり。
import pandas as pd
# 表「新規顧客.csv」と「顧客別売上集計.csv」をPandasのDataFrameとして読み込む
df1 = pd.read_csv('新規顧客.csv')
df2 = pd.read_csv('顧客別売上集計.csv')
# 列「顧客ID」をキーとして内部結合を実行
merged_df = pd.merge(df1, df2, on='顧客ID', how='inner')
# 結合された結果を別のCSVファイルに書き込む場合
merged_df.to_csv('結合結果.csv', index=False) # index=Falseを指定すると、インデックス列は書き込まれない
# 結合された結果のDataFrameを表示する場合
print(merged_df)
Python の Pandasで、特定の値で、順位付けをする方法は?
- Pandasの
rank()メソッドを使用することで、データフレーム内の特定の列の値に基づいて順位付けを行うことができます。
import pandas as pd
# データフレームの作成
data = {'Auction_ID': [123, 123, 123, 123, 124, 124, 124, 125],
'Bid_Price': [9, 7, 6, 2, 3, 2, 1, 1]}
df = pd.DataFrame(data)
# 'Auction_ID'でグループ化し、'Bid_Price'の値で降順に順位付け
df['Auction_Rank'] = df.groupby('Auction_ID')['Bid_Price'].rank(ascending=False)
print(df)
出力結果は次のようになります。
Auction_ID Bid_Price Auction_Rank
0 123 9 1
1 123 7 2
2 123 6 3
3 123 2 4
4 124 3 1
5 124 2 2
6 124 1 3
7 125 1 1
このように、「Auction_Rank」列に、各オークションIDの入札価格に基づいた順位が割り当てられています。
- 順位付けの方法には、methodパラメータを使用して、同じ値のグループに対してどのような順位を付けるかを指定できます。
- デフォルトではmethod='average'となっており、同じ値のグループに対しては平均の順位が割り当てられます。
- 他の方法として、'min'(最小の順位)、'max'(最大の順位)、'first'(出現順)、'dense'(連続した順位)などがあります。
- また、NaNの値に対しても順位付けを行う場合は、na_optionパラメータを使用します。
- デフォルトではna_option='keep'となっており、NaNの値はそのまま順位に含まれます。
- 'top'を指定するとNaNの値を最低の順位として割り当て、'bottom'を指定すると最高の順位として割り当てることができます。
Pandasで、Column を追加する方法は?
-
assign()を使用してColumnを追加する方法
df = pd.DataFrame({'team': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'],
'points': [5, 17, 7, 19, 12, 13, 9, 24],
'assists': [4, 7, 7, 6, 8, 7, 10, 11]})
print(df)
# 新しいColumnであるrow_numberを追加して、各行の行番号を表示する
df = df.assign(row_number=range(len(df)))
print(df)
出力結果は次のようになります。
team points assists row_number
0 A 5 4 0
1 B 17 7 1
2 C 7 7 2
3 D 19 6 3
4 E 12 8 4
5 F 13 7 5
6 G 9 10 6
7 H 24 11 7
- reset_index()を使用してColumnを追加する方法
- reset_index()メソッドを使用して、DataFrameに新しいColumnを追加し、各行の行番号を表示することもできます。
df = pd.DataFrame({'team': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'],
'points': [5, 17, 7, 19, 12, 13, 9, 24],
'assists': [4, 7, 7, 6, 8, 7, 10, 11]})
df['row_number'] = df.reset_index().index
print(df)
これにより、同じ結果が得られます。
team points assists row_number
0 A 5 4 0
1 B 17 7 1
2 C 7 7 2
3 D 19 6 3
4 E 12 8 4
5 F 13 7 5
6 G 9 10 6
7 H 24 11 7
どちらの方法も、DataFrameに新しいColumnを追加して行番号を表示するための簡単な方法です。
さらなる方法として、assign()やreset_index()以外にも、[]オペレーターやinsert()メソッドを使用してColumnを追加する方法もあります。
- []オペレーターを使用してColumnを追加する方法
- DataFrameに新しいColumnを追加するために[]オペレーターを使用することもできます。
df = pd.DataFrame({'team': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'],
'points': [5, 17, 7, 19, 12, 13, 9, 24],
'assists': [4, 7, 7, 6, 8, 7, 10, 11]})
df['new_column'] = ['value1', 'value2', 'value3', 'value4', 'value5', 'value6', 'value7', 'value8']
print(df)
これにより、DataFrameにnew_columnという新しいColumnが追加されます。
team points assists new_column
0 A 5 4 value1
1 B 17 7 value2
2 C 7 7 value3
3 D 19 6 value4
4 E 12 8 value5
5 F 13 7 value6
6 G 9 10 value7
7 H 24 11 value8
このように、新しいColumnが追加され、指定した値が各行に割り当てられています。
- insert()メソッドを使用してColumnを追加する方法
- insert()メソッドを使用して、DataFrameの指定した位置に新しいColumnを挿入することができます。
df = pd.DataFrame({'team': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'],
'points': [5, 17, 7, 19, 12, 13, 9, 24],
'assists': [4, 7, 7, 6, 8, 7, 10, 11]})
df.insert(1, 'new_column', ['value1', 'value2', 'value3', 'value4', 'value5', 'value6', 'value7', 'value8'])
print(df)
これにより、DataFrameの指定した位置にnew_columnという新しいColumnが挿入されます
team new_column points assists
0 A value1 5 4
1 B value2 17 7
2 C value3 7 7
3 D value4 19 6
4 E value5 12 8
5 F value6 13 7
6 G value7 9 10
7 H value8 24 11
このように、新しいColumnが指定した位置に追加されます。
Pandasで、行 (Row) を追加する方法は?
- Pandasの.append()メソッドを使用する方法
- .append()メソッドは、Pandasのconcat()関数の補助的なメソッドです。
- 単一の行を追加する方法として最も簡単な方法です。
import pandas as pd
# サンプルのPandas DataFrameを作成
df = pd.DataFrame.from_dict({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [31, 30, 40, 33],
'Location': ['Toronto', 'London', 'Kingston', 'Hamilton']
})
# 新しい行を辞書形式で作成
new_row = {'Name': 'John', 'Age': 25, 'Location': 'New York'}
# .append()メソッドを使用して新しい行を追加
df = df.append(new_row, ignore_index=True)
print(df)
- pd.Seriesオブジェクトを使用する方法
- 新しい行をpd.Seriesオブジェクトとして作成し、DataFrame.append()関数を使用してPandas DataFrameに追加する方法です。
import pandas as pd
# サンプルのPandas DataFrameを作成
df = pd.DataFrame({'RegNo': [111, 112, 113, 114, 115],
'Name': ['Gautam', 'Tanya', 'Rashmi', 'Kirti', 'Ravi'],
'CGPA': [8.85, 9.03, 7.85, 8.85, 9.45],
'Dept': ['ECE', 'ICE', 'IT', 'CSE', 'CHE'],
'City': ['Jalandhar', 'Ranchi', 'Patna', 'Patiala', 'Rajgir']})
# 新しい行をpd.Seriesオブジェクトとして作成
new_row = pd.Series([116, 'Sanjay', 8.15, 'ECE', 'Biharsharif'], index=df.columns)
# DataFrame.append()関数を使用して新しい行を追加
df = df.append(new_row, ignore_index=True)
print(df)
- pd.concat()を使用して複数の行を一度に追加する方法
- 複数の新しい行を別のPandas DataFrameとして作成し、pd.concat()関数を使用して元のPandas DataFrameに追加する方法です。
import pandas as pd
# サンプルのPandas DataFrameを作成
df1 = pd.DataFrame({'Name': ['Martha', 'Tim', 'Rob', 'Georgia'],
'Maths': [87, 91, 97, 95],
'Science': [83, 99, 84, 76]})
# 新しい行を別のPandas DataFrameとして作成
df2 = pd.DataFrame({'Name': ['Amy', 'Maddy'],
'Maths': [89, 90],
'Science': [93, 81]})
# pd.concat()関数を使用して複数の新しい行を追加
df3 = pd.concat([df1, df2], ignore_index=True)
print(df3)
社員別売上実績のランク(順位づけ)をして、Sortする
file_path = "社員別売上実績集計.csv"
df = pd.read_csv(file_path, encoding="shift-jis")
# Rankingを求める
df["順位"] = df["成約数"].rank(ascending=False, method="min")
# データの並び替え
sort_df = df.sort_values(by="成約数", ascending=False) # 列の値で昇順または降順にソート
# DataFrameを表示
pprint.pprint(sort_df)
実行結果は次のとおり。
成約数で、Lankがわかりやすくなっています。
営業社員ID 受注金額合計 成約数 商談数 順位
84 833 571500000 72 163 1.0
79 764 478000000 57 136 2.0
71 723 437500000 53 147 3.0
54 594 427000000 52 166 4.0
5 73 418500000 51 123 5.0
.. ... ... ... ... ...
28 353 20500000 3 109 92.0
51 577 18000000 3 78 92.0
25 321 18000000 2 115 95.0
2 41 20500000 2 124 95.0
63 645 14500000 2 98 95.0
[97 rows x 5 columns]