Datadog の構成管理に意思決定の手触りを残す
こんにちは。株式会社ヌーラボ で Lead Platform Engineer として働く iwa (@mananyuki) です。最近は育児に奮闘しています。シナぷしゅにハマりました。
さて、ヌーラボでは2025年3月に Datadog を導入しました。導入した当初は Datadog の Web UI で手動設定し、その後 Terraform による Infrastructure as Code (IaC) 化を進めました。私は2025年11月末まで育休を取っており、育休期間に Terraform 化がされたことで、復帰後にキャッチアップすることが大変でした。特になぜその設計にしたのかの記録が散逸しており、さまざまなドキュメントを見にいく必要がありました。自分が下した意思決定ですら、あっさりと記憶から抜け落ちてしまうものですね。
今回は、その課題の解決のために Spec-Driven Development (SDD) を活用しました。題材として Datadog の Data Access Control を用いた Fine-grained RBAC (Role-Based Access Control) の設計という複雑性の高い課題を採用しました。この課題に対して、意思決定の痕跡を残し、レビュー可能・巻き戻し可能にする ことで、手触りを残しながら進める実践例をご紹介します。
Data Access Control が必要となった理由
まずは、私たちがなぜ Data Access Control を導入し、Fine-grained RBAC を設計する必要があったのかについて書きます。
ヌーラボは、以下に挙げるような複数の SaaS プロダクトを運営しています。
そして、各プロダクトの認証基盤となる Nulab Account を提供しています。これらのプロダクトはそれぞれ独立したチームが開発・運営しており、各チームは自分たちのプロダクトに関連するログやトレースを閲覧したいというニーズがあります。
一方で、監査要件やセキュリティポリシーにより、他のプロダクトのテレメトリーデータへのアクセスを制限する必要もあります。例えば、Backlog チームのメンバーは Backlog に関連するログのみを閲覧できるようにし、Cacoo チームのメンバーは Cacoo に関連するログのみを閲覧できるようにしたい、という要件です。
これまでは Datadog の Logs Restriction Queries を用いてログのアクセス制御を行ってきました。しかし、この機能はあくまでログに対してアクセス制限を加えるもので、トレースやメトリクスなどログ以外のテレメトリーデータには適用できません。そんな中、Backlog における RUM 導入の機運の高まりや LLM を用いたエージェント機能の開発に伴い、機密性の高いデータを Datadog に保存するニーズも高まってきました。
今後の Datadog 利用範囲の拡大を見据えた場合、より包括的で細粒度なアクセス制御メカニズムを実現し、ガバナンスを利かせつつスピードを落とさないようにしなければなりません。つまり、Fine-grained RBAC が未整備であることを理由に、新しい機能の利用開始が止まってしまう状況は避けたい と考えました。
そこで、私たちは Datadog の比較的新しい機能である Data Access Control を採用することにしました。Data Access Control は、Logs / APM / RUM / LLM Observability などの機能単位で、機能が包含するテレメトリーデータに対して統合的にアクセス制御できる機能です。これにより、各プロダクトチームが自分たちのプロダクトに関連するデータのみを閲覧できるようになります。
Data Access Control では、Restricted Dataset という単位でアクセス制御します。
Restricted Dataset では、テレメトリータイプごとに「どのデータを Dataset に含めるか」を境界[1]として定義し、それにアクセス可能な Role もしくは Team を割り当てます。テレメトリータイプごとに1つのタグもしくは属性しか使えない制約があるため、境界の条件としてどのタグもしくは属性を使うかの設計判断が重要になります。 言い換えると、APM を制御するなら「APM の境界は常にこのタグ・属性で区切る」を最初に決める必要があります。後から別の Restricted Dataset を追加しても、APM の境界で env タグと service タグのように複数のタグ・属性を併用したり、Dataset ごとに境界の条件を変えたりはできません。
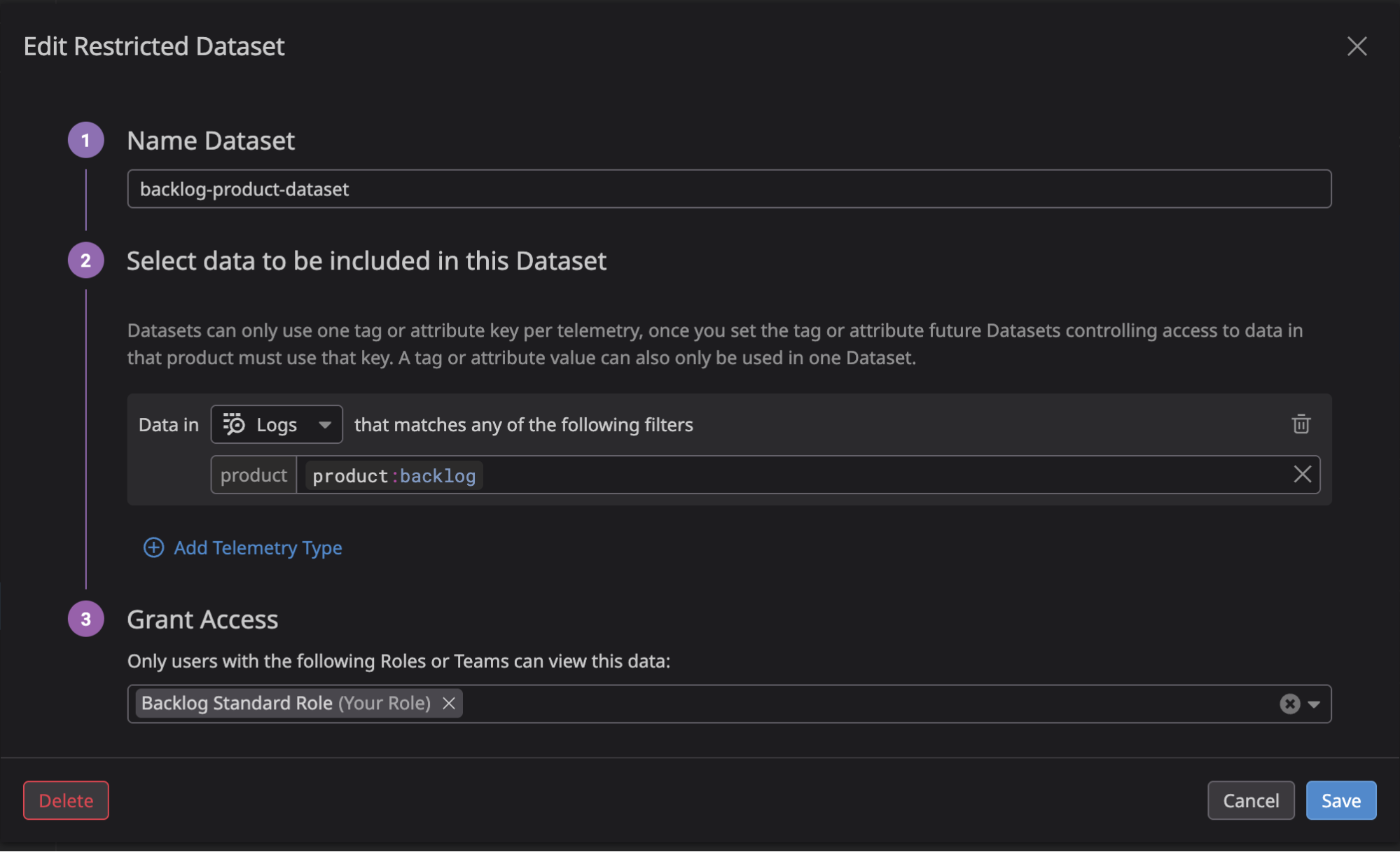
上記はヌーラボで設定している例です。Backlog に関わるテレメトリーデータへアクセス可能な Backlog Standard Role という Custom Role があります。この Role に割り当てる Restricted Dataset では、テレメトリータイプごとに product:backlog というタグを境界の条件として設定します。こうすることで、Backlog Standard Role を持つユーザーは Backlog に関連するログのみを閲覧できるようになります。また、product:backlog というタグを持つログは制限データとして扱われるため、Backlog Standard Role を持たないユーザーはこれらのデータにアクセスできません。
また、Terraform による構成管理も(公式には未アナウンスですが)利用可能です。Datadog Provider v3.72.0 で追加された datadog_dataset リソースを用いてアクセス制御の設定をコード化でき、私たちは実際にこのリソースを用いて Restricted Dataset を定義しました。
ただし、Data Access Control のドキュメントには以下の記述があります。
Terraform support will be announced after Data Access Control is generally available.
Ref: https://docs.datadoghq.com/account_management/rbac/data_access/
ここでは、Terraform のサポートは正式にアナウンスされたわけではないと記述されており、正しく動作しない可能性があります。なお、私たちは LLM Observability の Restricted Dataset を作成する際に、うっかり境界として @env:prod と指定したところ、Web UI から変更できない Restricted Dataset を作成してしまいました。一度削除してから再作成することで事なきを得ました…。
Fine-grained RBAC 設計の課題
そもそも RBAC の設計は複雑な意思決定を伴う難易度の高いタスクです。
単に「誰が何を使えるか」を決めるだけではありません。どの機能へのアクセスを許可するかという機能レベルの制御、どの範囲のデータを閲覧可能にするかというデータレベルの制御、そして定義したロールをどのようにユーザーに割り当てて異動や退職時にどうメンテナンスするかという承認フローや運用設計まで、多岐にわたる考慮が必要です。これらが相互に絡み合うため、整合性の取れた設計を維持するのは難しいです。
Datadog のようなオブザーバビリティツールの導入時は、
- サービスをまたいだ統一的なタグ付け要件の設計
- 既存のオブザーバビリティツールからの移行計画
といった、優先度が高く意思決定を伴うタスクが多く発生します。これに加えて RBAC を設計する場合、意思決定の難易度はさらに上がります。その場合は意思決定の記録まで手が回らず、属人的な知識に依存し、引き継ぎや変更が困難になります。
実際にヌーラボでは私ともう1名でリードしながら Datadog の導入を進めました。しかし、統一的なタグ付け要件のドキュメントといった SWE / SRE が Datadog を導入するにあたって必須であるドキュメントは整備できても、RBAC の設計ドキュメントまでは充分に手が回らない状況でした。
さらに Data Access Control を用いた Fine-grained RBAC の設計にはいくつかの課題があります。
前述したように、Data Access Control ではテレメトリータイプごとに1つのタグもしくは属性しか使えない制約があります。そして、既存のタグ付け戦略や Role 設計との整合性も考慮しなければなりません。また、これまではログのみを対象としていたアクセス制御が、様々な機能・テレメトリーデータに拡大されることで、設計の複雑性が増します。各テレメトリータイプごとに異なる要件や制約を考慮しながら、統一的なアクセス制御ポリシーを設計することが求められます。
意思決定を生きたドキュメントとして残さないと、後からなぜその設計にしたのか分からなくなったり、現在の設計と乖離していて参考にならなかったりすることで、変更や拡張が困難になります。例えば、「なぜ APM データは制限しないことにしたのか」「なぜ product タグを境界に選んだのか」といった判断理由が、口頭やチャットで決まり後から追えなくなることがあります。これは、設計を変更したい人、監査対応する人、あるいは私のように育休から復帰してキャッチアップする人にとって大きな障壁となります。
これらの制約や複雑性を踏まえた上で、なぜその設計にしたのかを明確にし、レビュー可能・巻き戻し可能にするための方法論が求められました。
Spec-Driven Development による解決策
そこで、私たちは Spec-Driven Development (SDD) を活用しました。
SDD は、意思決定の記録を Spec(仕様)という形でドキュメントとして残し、コードと同じくレビュー可能・履歴追跡可能にする開発手法です。今回は Kiro という AWS が開発する Agentic IDE を用いて SDD を実践しました。Kiro では、Requirements(要件: 何を実現したいのか)、Design(設計: なぜその設計にしたのか)、Tasks(タスク: 何をどの順でやるか)という3つのフェーズに分けて意思決定を記録します。これにより、設計の背景や理由が明確になり、後から参照しやすくなります。
私たちは、Datadog の構成を管理するリポジトリにて、Pull Request ベースで Spec をレビューし、チームで明確に Spec の合意を行なってから実装に進むプロセスを採用しました。これにより、Spec と Terraform コードを同じリポジトリで管理できるため、意思決定と実装が一元化され、整合性が保たれます。また、Git で履歴管理されるため、過去の設計判断を参照したり、設計に問題があった場合に巻き戻すことも容易です。これは、生きたドキュメントとして Spec を残し、意思決定の手触りを保ちながら Datadog の構成管理を進めるための効果的な方法となりました。
Datadog MCP サーバーの活用
今回の SDD の実践にあたり、Datadog が提供する リモート MCP サーバー を活用しました。Datadog MCP サーバーは、AI エージェントが Datadog のドキュメント・API・データにアクセスできる仕組みを提供します。現時点ではパブリックプレビュー版として提供されており、プレビューリクエスト が承認される必要があります。
利用可能なツールは以下の通りであり、今回は特に search_datadog_docs ツールを活用しました。
-
search_datadog_logs: アプリケーションおよびインフラストラクチャのログを検索 -
get_datadog_metric: 時系列メトリクスをクエリ -
search_datadog_spans: APM トレースおよびスパンを検索 -
get_datadog_trace: トレース ID から完全なトレース詳細を取得 -
search_datadog_rum_events: RUM イベントを検索 -
search_datadog_incidents: インシデントを検索・一覧表示 -
get_datadog_incident: インシデントの詳細情報を取得 -
search_datadog_monitors: アラートモニターを検索 -
search_datadog_services: APM サービスを一覧表示 -
search_datadog_dashboards: ダッシュボードを検索 -
search_datadog_docs: Datadog ドキュメントを検索
MCP サーバーには、AI エージェントの起動時にツールが読み込まれるため、コンテキストウインドウを圧迫しがちという課題があり、ツールにより様々な解決策が模索されている現状です。今回 SDD の実現のために利用した Kiro には、Kiro Powers という解決策が実装されており、MCP サーバーのツールが必要になったタイミングで動的に読み込むことで、コンテキストウインドウの無用な圧迫を防げます。また、Power に含まれる MCP サーバーにまつわる知識を用いて MCP サーバーをより効果的に活用できるという特徴もあります[2]。
Datadog は Kiro Powers のローンチパートナーであるため、Datadog Observability Power がすでに提供されています。今回はこの Power に加えて Deploy infrastructure with Terraform Power を用いて、Spec 作成中に Datadog や Terraform の Datadog Provider のドキュメントを参照しながら設計を進めました。例えば、以下のような点で活用しました。
- Datadog MCP サーバーが提供する
search_datadog_docsツールで、Data Access Control のドキュメントに書かれている制約やベストプラクティスを調査して、Design ドキュメントを改善する - テレメトリーデータで利用されているタグの分析を LLM で行う
このおかげで、現在の Datadog の利用状況に応じた最適な設計判断を行うことができました。
今回、育休明けに短期間で Data Access Control の導入を進めましたが、私の育休中に進んだ Datadog の活用や Terraform 化の状況を、Power を通じて短時間でキャッチアップできた点は大きなメリットでした。また、Data Access Control の機能自体が新しいため、充分にキャッチアップできていないにも関わらず、LLM と対話しながら学習することですぐ設計に活かせた点も助かりました。
Data Access Control の設計実践例
ここからは、実際に私たちが Datadog の Data Access Control を用いた Fine-grained RBAC の設計を SDD でどのように進めたのか、その実践例をご紹介します。
基本的に Kiro が強く支援してくれるため、Kiro と対話しながら Spec を作成し、レビューを経て Terraform で実装するという流れで進めました。
今回の設計では、小さく始めて大きく育てることを意識し、意図的にスコープを絞って進めました。
- 対象テレメトリー: Logs のみ(プロダクト間通信を追えるようにするため、APM は除外)
- 境界の条件に使うタグ:
productタグ(product:apps,product:backlog,product:cacoo) - 許可する主体: 既存の Custom Role(Backlog Standard Role, Cacoo Standard Role, Apps Standard Role)
- 追加: LLM Observability の
env:prod制御(LLM Observability にアクセス可能な LLM Observability Write Role のみ)
前提として、Unified Service Tagging をベースとしたタグ付け要件が導入済みであり、Entra ID グループとの SAML Group Mappings で Role が自動割り当てされています。また、既存の Logs Restriction Queries からの移行という位置づけです。
要件(Requirements): 何を実現したいのか
Requirements フェーズでは、ユーザーストーリーと受け入れ条件を定義します。
これは Kiro に要求を伝えて何度か対話をすることで、要件として固まったユーザーストーリーを網羅的に記述できます。
私たちは以下のようなユーザーストーリーをひとつの要件として設定しました。
As a security administrator, I want to define fine-grained access policies using Data Access Control, so that I can control access to sensitive logs data based on Unified Service Tagging while preserving APM visibility for service-to-service communication.
このユーザーストーリーに対する受け入れ条件は、Kiro が標準として採用する EARS (Easy Approach to Requirements Syntax) 形式で記述します。EARS 形式は、「WHEN … THE system SHALL …」のように条件と動作を明確に記述するフォーマットで、曖昧さを排除できます。以下はその抜粋です。
- WHEN creating access policies, THE Data Access Control SHALL support granular permissions for logs data only, excluding APM data to preserve service-to-service communication visibility
- WHEN defining resource scope, THE Data Access Control SHALL filter logs data using Unified Service Tagging conventions, prioritizing product tags for operational simplicity
- WHEN configuring user permissions, THE Data Access Control SHALL support role-based assignment through SAML group mapping
- WHEN policies are applied, THE Data Access Control SHALL enforce restrictions immediately across all Datadog interfaces
- WHEN LLM Observability data is accessed, THE Data Access Control SHALL restrict access to production environment data only (env:prod) for the LLM Observability Write Role
これらの受け入れ条件により、「APM データは制限しない」「product タグを境界に使う」「SAML 連携で Role を割り当てる」といった設計判断の根拠が明確になりました。
設計(Design): なぜその設計にしたのか
続く Design フェーズでは、Requirements を満たすためのアーキテクチャと意思決定を記録します。SDD の核心はここにあり、なぜその設計にしたのかを明確に残すことで、後から参照・変更しやすくなります。今回は Design ドキュメントに加えて、Datadog MCP サーバーおよび Terraform MCP サーバーを活用して、最新のドキュメントや利用状況を調査した内容を Research ドキュメントとして残しました。これにより、設計判断の背景にある情報源が明確になり、設計の妥当性を検証しやすくなります。
私たちの設計では、以下の3つの主要な意思決定を行いました。このフェーズでも Kiro と対話しながら設計の意思決定を進めました。
アクセス権は Team ではなく既存の Custom Role に与える
Datadog の Data Access Control では、Restricted Dataset に対して Role または Team を割り当てます。ここで私たちは既存の Custom Role のみに絞ることを選択しました。理由は、Entra ID グループでの承認フローが充分に機能しており、SAML Group Mappings で既に適切に Role が管理されているためです。この Role 管理に加えて Team を別途管理すると二重管理になり、運用の複雑性を生むためです。
境界の条件は service ではなく product を使う
Unified Service Tagging では service, env, version の3つのタグを使います。私たちはこの3つのタグを拡張して product タグもすべてのサービスに付与しています。この product タグを境界の条件に選択しました。理由は、service タグは1,000以上あり運用が複雑になる一方、product タグは3つ(apps, backlog, cacoo)で管理しやすいためです。また、Datadog MCP サーバーの search_datadog_docs ツールで Data Access Control の境界におけるタグ・属性の制約を確認し、シンプルな条件が必須と判断しました。
APM データは制限しない
Logs は product タグで分離しますが、APM データは制限しません。理由は、プロダクト間通信の可視性を維持し、障害調査時に全体像を把握できるようにするためです。また、今回は Data Access Control の導入初期であり、Logs のみを対象とすることで段階的に導入を進める意図もあります。
タスク(Tasks): 実装を小さな単位に分解
Tasks フェーズでは、Design を実現するための具体的な実装タスクを定義します。ここでは Kiro が充分にレビューされた Requirements および Design から分解されたタスクを記述してくれます。私たちは以下の4つのフェーズに分けて実装を進めました。
Phase 1: Infrastructure Setup and Role Discovery
- Task 1.1:
rbac.tfファイルを作成 - Task 1.2: 既存の Custom Role を
datasource で参照 - Task 1.3: 現行の Logs Restriction Queries 設定を棚卸し・文書化
Phase 2: Dataset Implementation
- Task 2.1: Apps Product Dataset 作成(当初:
@product:apps→ 最終:product:apps, Logs のみ) - Task 2.2: Backlog Product Dataset 作成(当初:
@product:backlog→ 最終:product:backlog, Logs のみ) - Task 2.3: Cacoo Product Dataset 作成(当初:
@product:cacoo→ 最終:product:cacoo, Logs のみ) - Task 2.4: LLM Observability Dataset 作成(当初:
@env:prod→ 最終:env:prod, LLM Observability のみ)
Phase 3: Integration and Validation
- Task 3.1:
terraform validateおよびterraform planの実行
Phase 4: Configuration Corrections
- Task 4.1: アクセス権のフォーマット修正
- 誤って
<role-id>のみ記述していたが、Team か Role の判定のためのプレフィックスが必要だったので、role:<role-id>形式へ
- 誤って
- Task 4.2: 各 Dataset の境界修正
- 誤記(当初):
@product:backlog,@env:prod - 修正後(最終):
product:backlog,env:prod - 背景: Terraform の Datadog Provider のドキュメント例の記法を誤解し、
@を付けてしまった - 方針: Web UI との整合とわかりやすさのため
product:.../env:...に寄せた
- 誤記(当初):
実装中にアクセス権のフォーマットや境界に関する問題が発覚し、Phase 4 を追加しました。このように Tasks ドキュメントは実装の進捗とともに更新され、問題の発見と解決の履歴も残ります。
実装(Implementation): Terraform で実装
最後に、Design と Tasks に基づいて Terraform で実装します。以下は、Backlog Product Dataset および LLM Observability Dataset の最終的な実装例です。
# 既存の Custom Role を data source で参照
data "datadog_role" "backlog_standard" {
filter = "Backlog Standard Role"
}
data "datadog_role" "llm_observability_write" {
filter = "LLM Observability Write Role"
}
# Backlog Product Dataset の作成
resource "datadog_dataset" "backlog_dataset" {
name = "backlog-product-dataset"
principals = ["role:${data.datadog_role.backlog_standard.id}"]
product_filters {
product = "logs"
filters = ["product:backlog"]
}
}
# LLM Observability Dataset の作成
resource "datadog_dataset" "llm_observability_prod_dataset" {
name = "llm-observability-prod-dataset"
principals = ["role:${data.datadog_role.llm_observability_write.id}"]
product_filters {
product = "ml_obs"
filters = ["env:prod"]
}
}
このコードには、Design で決めた意思決定が反映されています。
-
data "datadog_role": 既存 Role を参照し、新規作成しない -
principals: Role を指定し、Team は使わない -
product_filters.product:logsのみを指定し、APM は除外 /ml_obs(LLM Observability) を指定 -
product_filters.filters: 境界としてproduct:backlog/env:prodを指定
この Terraform コードは HCP Terraform で管理しており、PR でレビューした後に自動デプロイされます。terraform plan の差分をレビューすることで、意図した通りの設定が反映されているかを確認できます。最終的には、Datadog の Web UI で設定内容を確認し、期待通りに動作していることを検証しました。
まとめ
今回は、Datadog の Data Access Control を用いた Fine-grained RBAC の設計において、Spec-Driven Development (SDD) を活用して意思決定の手触りを残しながら進めた実践例をご紹介しました。合わせて Datadog MCP サーバーを活用することで、最新のドキュメントや利用状況を参照しながら設計を進めることができました。これにより、複雑な設計判断を明確に記録し、レビュー可能・巻き戻し可能にできました。
SDD を活用することで、Datadog の構成管理における意思決定の透明性と追跡可能性が向上し、将来的な変更や拡張が容易になると確信しています。「意思決定は点ではなく線である」 という点を意識すると、SDD がなぜこれほど世間に注目されているか納得します。今後もこのアプローチを他の構成管理タスクにも展開し、チーム全体での知識共有と継続的な改善を図っていきたいと考えています。
皆さんの Datadog 導入や構成管理においても、SDD を活用して意思決定の手触りを残すことをぜひ検討してみてください!
Discussion