マナリンクCTOの名人です。
今回は、SentryとLoggingの工夫により、「開発チームとエラー監視の心理的距離を近くする」ことをテーマに記事を書きます。
背景
エラー監視、嫌ですよね。
手塩にかけて育てたソースコードが本番環境でエラーを吐いている様子は、誰が見ても気持ちいいものではありません。
そんなエラー監視から目を逸らさず、普段の開発から意識して関わっていくことが、サービスの安定した運用や障害対応のスピードに繋がります。
弊社では昨年1年ほどかけて、コツコツとSentryとの関わり方や、日頃どんな基準でどんな形式でどこにLoggingするか、およびSentryとLoggingの連携について模索してきました。
専用の運用監視チームや担当エンジニアを持たない弊社においては、過度に頑張りすぎず、過度に最新のトレンドに追従せず、それでいて日頃の開発で意識しやすいラインに落とし込むことが必要でした。
本記事では、あくまで開発チームとエラー監視の距離を近くするテーマを軸に、SentryやLoggingの工夫を解説していきます。
目次
- 弊社で実践しているSentryとLoggingの運用例
- 具体的な実装・インフラの設定(AWS、Next.js、Laravel、React Native)
- 現在の運用に至るまでに検討したことや背景
- 実際運用してみての課題
- 補足
弊社で実践しているSentryとLoggingの運用例
まずは、できるだけ詳細な技術やソースコードを書かずに、実運用の概要を示します。
後続のセクションで具体的な実装や設定の例を示すので、興味があるセクションを見つけていただければと思います。
バックエンドでは標準出力を介してエラーをSentryに流す
エラーをSentryに渡したいときに、一般的な方法はSentry.captureException(error)やSentry.captureMessage(string)だと思います。
ですが、ソースコードから直接Sentryを呼び出すことには以下のデメリットもあります。
- エラー情報がSentryだけに閉じてしまい、Sentry以外で活用することの難易度が上がる
- Sentry側のSDKに仕様変更があるなど使い方が変わったとき、影響範囲が多岐に渡る
そこで、マナリンクでは標準出力にエラーを流すと、Sentryにも保存される方針を採用しています。
内部ロジックとしては、LOGレベルがERRORである標準ログをSentryにもSeverity=ERRORとして流すし、WARNINGレベルだとSentryにもSeverity=WARNINGとして流しており、それ以下のレベルだとそもそもSentryに流さない、といった塩梅です。
これにより、開発者が開発時に意図することはエラーを漏らさず・わかりやすくログに残そうということだけです。結果としてエラーがSentryに集約され、適切にレポーティングされます。
// バックエンド(PHP)のサンプルコードです
if ($isInquiryDuplicate) {
// 内製したカスタムLoggerです※実装は後述
// LOGレベルをERRORとして記録する関数です
Logger::reportError('レアケースなエラーなので、ユーザーにフィードバック済みだけど念の為流します|重複したお問合せはできません', [
'userId' => $authUserId,
'inquiryId' => $inquiryId,
]);
throw new MyValidationException(
上記のように開発時にはログを残すだけで、結果としてSentryにも流れる仕組みです。具体的な設定方法は後続のセクションで示します。
「システムエラー」以外の「ドメインエラー」も残すことで、開発の不安を解消
前節に示したコードでは、Exceptionをthrowしてユーザー(フロントエンド)にエラーが起きたことをフィードバックしつつ、エラーログも合わせて記録しています。
このように、マナリンクではいわゆるシステムエラー(500を返すようなエラー。たとえばNULL Pointer Exceptionなど)のみならず、ドメインエラー(400系を返すようなエラー)でも、場合によってはエラーログとして残す運用方針を採っています。
これは開発時の不安を解消することが主な目的です。
新しい機能をリリースするとき、機能が意図しない挙動をすることがないか不安になりますよね。
たとえば前節のコードは「フロントエンドで重複したお問合せができないように制約をかけているので、この分岐を通ることは理論上ありえないが、仮に発生するとデータベースへの永続時にシステムエラーとなるため、事前に分岐を実装した」といったコード例ですが、
逆に言えばフロントエンドでの制御が不足していたり、意図しない認可漏れがあったり、誤ったお問合せIDが指定可能になっているバグが想定されます。
もちろんこのような想定はするとキリがありません。一方で、技術的に不安が残る機能や、事業にとってミッションクリティカルな機能の初回リリース時にこのような分岐を通ると、より大きなバグの初期症状である可能性も否定できません。要するに、可能性×悪影響の大きさをリスクと捉えたときに、そのリスクが普段より大きいケースが存在するということです。
そこで、マナリンクではそういった想定外の分岐かつ重要なインシデントに繋がりかねない場合は、遠慮なくERRORレベルのログとして記録してよい、ということにしています。実際、「クレジットカード支払いに3Dセキュアを導入」や「ユーザー退会時のデータ削除ロジックを変更」といった、ミッションクリティカルであったり影響範囲が不確実に広いことが予期される領域の改修時にこのようなログを仕込むことで、リリース後Sentryを経由してエラーが開発チームにレポートされ、初期対応を速く始められたり、ビジネスチームに事前に共有するといった対応ができています。
「ドメインエラー」を残した一例
それでは具体的に、ドメインエラーをSentryを通してレポートした事例をStep by Stepで示します。
先日私はクレジットカード決済に3Dセキュア認証を追加しました。既存の技術選定の都合上、カード決済代行会社のマニュアル通りの実装では完遂できず、いくつか自前で実装する箇所があり、事前に綿密にテストしても実際にユーザーランドでどのようなクレジットカード決済エラーが起きるのか、一抹の不安がある状態でした。
バックエンドで3Dセキュアの完了処理を行う際、もちろん決済代行会社のAPIをコールするため失敗するケースも想定するわけですが、ここが失敗するケースがどの程度あるのか(カード起因・システム起因両方)読みきれないことから、以下のようにERRORレベルのログを残す判断をしました。
Logger::reportError('3Dセキュア認証に失敗しました(※システム側の問題である可能性は低いが、万が一の捕捉を早めるために流している): '.$e->getMessage());
throw new DomainException(
status: 400,
code: FAILED_3D_SECURE_FINISH,
);
リリース後、特定の条件でユーザーが決済に失敗すると、以下のようにSentryに記録されました。

また、Sentryで設定したAlert条件(後述)を満たすため、社内のSlackにもエラーが通知されました。

御存知の通り、クレジットカード決済を導入すると、カード決済の失敗自体は日常茶飯事で起きます。そして大半のケースは決済失敗はユーザーのカードそのものや入力が原因です。しかし、万が一システム側の実装に問題があると大問題という性質があります。そこで、このように決済失敗時にエラーをレポートする運用方針を採用し、結果として、以下のようにいち早く社内Slackにて告知することができました(結果は杞憂でした)。

このように、技術観点で一抹の不安が残るリリースにおいては重要な分岐などに一定レベル以上のログを残しSentryに集約およびAlertを担ってもらうことで、素早く問題の候補をキャッチアップし、先手を打つことができます。
ログレベルの判断
本記事ではERRORレベルのログを流す例を示しましたが、SentryにはWarningレベルのエラーも記録することが可能です。そこでマナリンクでは、LOGレベルがWARNINGでも、SentryにSeverity=WARNINGで記録することにしています。
一方で、SlackへのAlertを行うのはERRORのみです。この運用により、発生後速やかにキャッチアップしなければ致命的というわけではないが、知りたいときにその挙動が起きているかすぐに知ることができるべきものをWARNINGレベルのログとして収集しています。
具体的なWARNINGの例として、「古いバージョンのネイティブアプリで利用されている可能性があるが、綿密な調査をするのも面倒だ。とりあえず該当コードにWARNINGを入れておいて、1週間後にSentryで見てみよう」というラフな利用実績調査に用いることがあります。
こういう運用方針はチーム人数が大きいと意見がぶつかりあうかもしれませんが、弊社は小規模組織でアジリティをあくまで重視しているので、このような意思決定をしています。
ログ実装の削除
ERRORレベルで仕込んだログがリリース後数回発火したが、結果として問題は何も起きていなかったこともしばしばあります。そのときは当該ログを追って削除したり、LevelをWARNINGやINFOまで下げる対応を行います。
文化形成
これらの運用方針を採択し継続するには、ある意味でSentryやLoggingを原理主義的に捉えず、あくまで「想定外のシステムの挙動を蓄積、分析、検知、対応できることをゴール」としてアジリティを高めたまま運用する思想をチームで共通認識にすることが大事です。
また、発覚しないエラーより発覚するエラーのほうが100倍マシだし、読み解けないエラーより読み解きやすいエラーログのほうが1000倍マシ、といった価値観の共有も必要と思いますし、エンジニア以外の職種の方々に対しても、エンジニアは完璧な意思決定を常にできるわけではないが、本番環境で問題が起きたら速やかにキャッチアップできるよう最善を尽くしている、というスタンスを取っていることが何かと心理的安全性にも繋がるのかなと考えています。
Sentryを結局どういうツールとして捉えているか?
現状、マナリンクではSentryを以下のようなことができるツールとして捉えています。
- エラーを構造化して、検索可能にする
- Alertルールをカスタマイズして、Slack等に通知する条件を運用に応じて決めることができる
- SDKを使うことで、エラーに付随すべき基本的な情報(User IDなど)をある程度自動収集できる
- エラー発生直前に起きたことを辿れる(Breadcrumbs機能)ことで原因解決に貢献する
Sentryは人気で歴史の長いサービスなので、巷にベストプラクティスも多々ありますが、あくまでSentryができることを能力ベースで捉えることで、自社の状況に応じて、Sentryだけに頼らない柔軟な監視体制を構築できると考えています。
具体的な実装・インフラの設定(AWS、Next.js、Laravel、React Native)
本章では具体的な実装やインフラの設定に触れていきます。
前提条件
マナリンクはユーザー数が爆発的に多いわけではない
技術選定における前提として、マナリンクはtoCサービスにもかかわらず、顧客単価が高く1ユーザーあたりの価値提供が大きいという特徴があります(大学生の家庭教師は採用せず、プロの家庭教師のみを採用している)。
したがって、エラーログに対しては、どのUser IDがどの文脈で起こしたのかが非常に問題解決において重要です。ユーザー規模が大きく個別のユーザーのエラーに関心を持っていてはキリがない事業では、前提が異なるでしょう。
日々流れるERRORレベルのログがそもそも多くない
また、マナリンクはまだリリース後5年弱しか経っていないため、日々流れるエラーログの数も多くありません。Sentry上で適切にフィルタリングすれば(sentry configでignoreするエラーを指定できます)、SlackにAlertされるエラーは日に数件程度に抑えられています。
この前提があるからこそ、新規リリースなどにおいてエラーログをあえて増やしてみようという意思決定がしやすいです。また、前章に書いたとおり、そもそも標準出力には必ずログが残っているが、一部をSentryに流しているアーキテクチャなので、すべてをSentryに拾わせなくていいのも功を奏しています。
実装内容
Sentry for Laravel
Laravelでは公式のSentry SDKを利用しています。
ポイントとしては以下ページに書かれているLog Channelの設定を行うことです。
こちらの設定を終わらせると、標準出力へのログがSentryにも流れるようになりますし、最低レベルも指定できます。弊社ではWarningを最低レベルにしています。
'sentry' => [
'driver' => 'sentry',
'level' => env('SENTRY_LOG_LEVEL', 'warning'),
'bubble' => true,
],
また、後述する内製LoggerによるログをすべてBreadcrumbsに記録するように、以下のオプションをTrueにしています。
'breadcrumbs' => [
// Capture Laravel logs in breadcrumbs
'logs' => true,
要するに、Warning以上のログならSentryに記録するし、そうでなくてもBreadcrumbsに記録されるから、該当ログ以降にエラーが起きた場合もそのIssueの詳細ページから直前のログを確認できるということです。
Logging.php
ここまでの説明で度々出てきましたが、Laravelでは内製のLoggerを開発・運用しています。
といっても大した実装ではなく、以下のようにLaravel側のログ関数の薄いWrapperです。
public static function logStepOfProcess(string $processName, string $message, array $context = []): void
{
self::logWithTrace('debug', '['.$processName.'] '.$message, $context + [
'log_type' => 'logStepOfProcess',
]);
}
private static function logWithTrace(string $level, string $message, array $context = []): void
{
$trace = self::getTrimmedTrace(debug_backtrace(DEBUG_BACKTRACE_IGNORE_ARGS));
Log::log($level, $message, $context + ['user_id' => Auth::user()?->id, 'trace' => $trace]);
}
このようなWrapperは半年ほど前に追加した比較的新しいモジュールです。
というのも、Sentryをログ経由で利用できるようにして以来、チームメンバーが積極的にログを残してくれるようになったのはいいものの、人によってフォーマットなどに差があり、可読性が落ちてしまったことから、目的別に所定のログ形式で流すように統一する目的で実装しました。
上記の例のlogStepOfProcess 関数は、処理がある程度複雑なUseCaseなどで、ところどころに仕込むことで、エラー時などにどこまで処理が正常に進んだかを把握しやすくします。
もちろん明確にエラーが起きたらSentryで検索できますし、そうでなくてもCloudWatchにログが流れているので、Logs Insightsからログ検索ができます(当然ながらログはJSON形式で統一しており、統一されたクエリでログを検索することができます)。
エラーを伴うような明確な障害はSentryで対応し、わかりにくい障害やバグの場合はCloudWatch Logs Insightsから検索可能という二枚看板です。あくまでログを窓口にすることで、開発チームがSentryを使うハードルを下げることに成功しています。
Next.js / React Nativeについて
ここまでほとんどバックエンドについて解説してきました。フロントエンドでのSentry活用についてもいくつかTipsがありますが、開発チームとの心理的距離という本題から反れるので割愛します。
現在の運用に至るまでに検討したこと
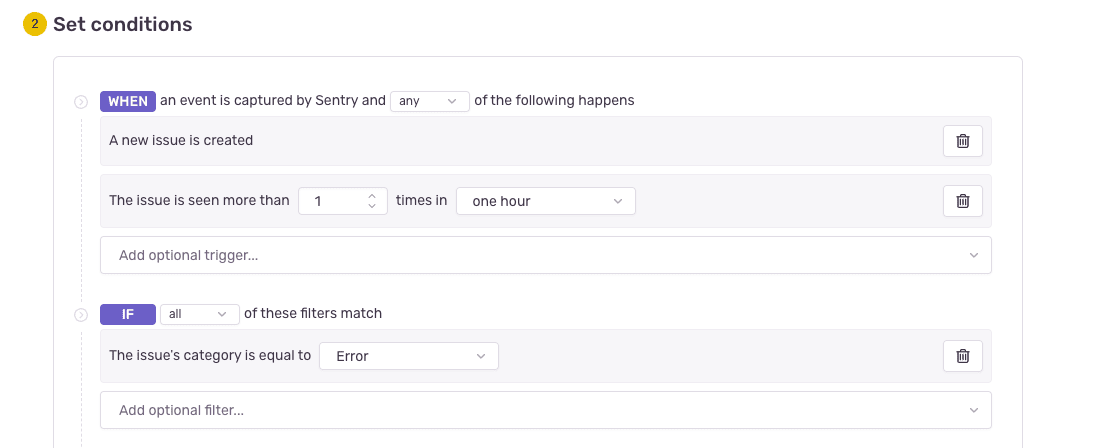
AWS Lambdaでログ検知してSlack通知→障害時に数が多くなりすぎたため、SentryのAlertを採用
今となってはあまりに原始的ですが、創業当初はエラーログはAWS Lambdaで検知して直接Slack通知していました。しかし障害発生時に大量のSlack通知が流れてしまいました。Sentryを介することで、(ある程度)同じ内容のエラーログは連続して流れないし、一方で一定時間以上間が空いても続いていればまた流れる設定が可能です。

OpenTelemetry→将来的なスケールを考慮するとアリだが、現実的にはLogging Wrapperを構成することで落ち着いた
OpenTelemetryのエコシステムに参入することも検討しました。SentryもどうやらOtelに対応しつつあるようで、本記事で書いてあるように、一次情報をAWS CloudWatchに置くことでポータビリティを保つ方針はOtelに則ることでもっと精度高く達成可能です。
一方で、PHPでの計装を調査したり、Otel形式のログを閲覧するための専用クライアントを調べていく中で、そこまでやらなくても弊社の規模や事業特性であればCloudWatch Logs Insightsで検索するノウハウさえ揃えれば問題ないとの認識に至りました。
この辺については、弊社がまだエンジニア5人のチームであることや、バグ発生が事業運営に及ぼす影響度や、バグの原因を細部に至るまで追求する必要性の高さなどを検討のうえ判断しています。
また、将来的にOtelに採用したい場合は、自前Loggerを経由する運用を守っておくことで、そのLoggerをOtel計装にすればプロダクトコードへの影響範囲は小さくできるのかな、と楽観的に考えています。
実際運用してみての課題
エラーログを流すことが目的になってしまう
前節までで、標準出力へのログをSentryのError Reportに繋げることで、エンジニアが容易に開発上のリスクや懸念を表現できるようになった話をしました。
その副作用として、エラーレポートは確かにSentryに流れているものの、そのログを見ても具体的に何をしたらいいかわからず、結果として無意味なエラーレポートになったり、本来の目的である問題解決に時間がかかることがありました。
たとえば以下のようにエラーレポートの内容を詳細にして、数ヶ月後の開発メンバーが見ても、やることがある程度明確になっていることが望ましいです。
《当初の目的》
サービスに初めてStripeを導入するため、安定性に不安が残る。場合によってはリトライ実装も検討しつつ1stリリースではStatus Codeを400とし、ユーザーに再入力をお願いする仕様とした。念の為にAPIコール失敗時は原因をエラーレポートに残しておこう。
《Before》
「Error: Operationがタイムアウトしました」
→Sentryの詳細画面を開いてStack Trace等を読みようやく意味がわかる。リスクの大きさがわからない。などの問題がある
《After》
「◯◯の支払いを行うStripeのAPI呼び出しがタイムアウトしました。ユーザー画面で再度支払いが要求されているはずですが、多発する場合は障害発生やタイムアウト設定を再確認し、適宜Bizへの共有や実装修正をお願いします。」
また、JSON形式のログとしてモジュール名を含めておくことで、あとでCloudWatch等から統計的に検索可能
まとめ
本記事で解説したような体制を組むことで、開発時に感じた不安を、解消せずに気合でリリース!といった力ずくの解決策に頼らず、エラーログを流す形で向き合えるようになりました。
今となっては日々ソースレビューなどにおいて、「ここの分岐に辿り着くということはInvalidなデータがあるということだから、ERRORログを流して監視しよう」だったり「古いバージョンのアプリのユーザーがここを経由するとエラーにして良いとビジネスサイドと握ったけど、ユーザーさん視点ではクレームになるかもしれないから前後の処理をログに残そう」といった柔軟な意思決定ができ、未来予知をできる範囲で実施したうえでリリースができています。
今後もいろいろな手段を使って、本番運用を考慮した実装ができるように工夫していきたいです。

オンライン家庭教師マナリンクを運営するNoSchool社のテックブログです。 manalink.jp/ 実際に検証・開発した内容をベースに、ただのマニュアルや告知に留まらない具体的な知見を公開します! カジュアル面談はこちら! forms.gle/fGAk3vDqKv4Dg2MN7
Discussion