Open5
Databricks 共有クラスターにてエラーとなったメソッド群
Databricks 共有クラスターを利用する場合に次のように利用できないメソッドがあり、その事象を整理する。
py4j.security.Py4JSecurityException: Method public void org.apache.spark.sql.internal.CatalogImpl.setCurrentDatabase(java.lang.String) throws org.apache.spark.sql.AnalysisException is not whitelisted on class class org.apache.spark.sql.internal.CatalogImpl
spark.catalog.setCurrentDatabase
エラー
spark.catalog.setCurrentDatabase('zenn')
py4j.security.Py4JSecurityException: Method public void org.apache.spark.sql.internal.CatalogImpl.setCurrentDatabase(java.lang.String) throws org.apache.spark.sql.AnalysisException is not whitelisted on class class org.apache.spark.sql.internal.CatalogImpl

対応方法
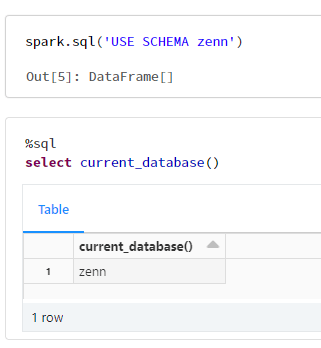
SQL のUSE SCHEMAに変更
spark.sql('USE SCHEMA zenn')
org.apache.spark.sql.types.DataType.fromJson(java.lang.String)
エラー
json_data = df.schema.json()
schema = spark.sparkContext._jvm.org.apache.spark.sql.types.DataType.fromJson(json_data).toDDL()
schema
py4j.security.Py4JSecurityException: Method public static org.apache.spark.sql.types.DataType org.apache.spark.sql.types.DataType.fromJson(java.lang.String) is not whitelisted on class class org.apache.spark.sql.types.DataType

対応方法
schema = ",".join([f'{col_type[0]} {col_type[1]}' for col_type in df.dtypes])
schema

出力結果の比較
DDL を生成するデータフレームを作成
# サンプルデータフレームを作成
from pyspark.sql import Row
from decimal import *
import datetime
sample_Data = [
Row(
string_column='AAA',
byte_column=1,
integer_column=1,
bigint_column=1,
float_column=12.300000190734863,
double_column=12.3,
numeric_column=Decimal('12'),
boolean_column=True,
date_column=datetime.date(2020, 1, 1),
timestamp_column=datetime.datetime(2021, 1, 1, 0, 0),
binary_column=bytearray(b'A'),
struct_column=Row(struct_string_column='AAA', struct_int_column=1),
array_column=['AAA', 'BBB', 'CCC'],
map_column={'AAA': 1},
)
]
schema = '''
--文字型
string_column string,
--整数型
byte_column byte,
integer_column integer,
bigint_column bigint,
--浮動小数点型
float_column float,
double_column double,
numeric_column numeric,
--真偽型
boolean_column boolean,
--日付時刻
date_column date,
timestamp_column timestamp,
--バイナリー型
binary_column binary,
--複合型
struct_column struct<
struct_string_column :string,
struct_int_column :int
>,
array_column array<string>,
map_column map<string, int>
'''
df = spark.createDataFrame(sample_Data, schema)
org.apache.spark.sql.types.DataType.fromJson(java.lang.String)の出力結果
'string_column STRING,byte_column TINYINT,integer_column INT,bigint_column BIGINT,float_column FLOAT,double_column DOUBLE,numeric_column DECIMAL(10,0),boolean_column BOOLEAN,date_column DATE,timestamp_column TIMESTAMP,binary_column BINARY,struct_column STRUCT<struct_string_column: STRING, struct_int_column: INT>,array_column ARRAY<STRING>,map_column MAP<STRING, INT>'

提示した対応方法の出力結果
'string_column string,byte_column tinyint,integer_column int,bigint_column bigint,float_column float,double_column double,numeric_column decimal(10,0),boolean_column boolean,date_column date,timestamp_column timestamp,binary_column binary,struct_column struct<struct_string_column:string,struct_int_column:int>,array_column array<string>,map_column map<string,int>'

spark.catalog.listColumns
エラー
spark.catalog.listColumns("hive_metastore.uc_migration_01.nation_02")
py4j.security.Py4JSecurityException: Method public org.apache.spark.sql.Dataset org.apache.spark.sql.internal.CatalogImpl.listColumns(java.lang.String) throws org.apache.spark.sql.AnalysisException is not whitelisted on class class org.apache.spark.sql.internal.CatalogImpl

対応方法
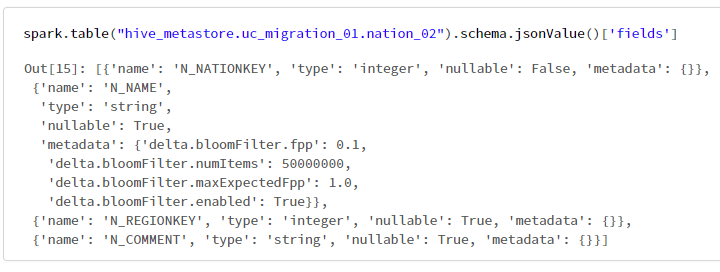
isPartitionとisBucketの値を取得できなことに注意が必要。
spark.table("hive_metastore.uc_migration_01.nation_02").schema.jsonValue()['fields']
spark.catalog.listColumns では次の項目が表示される。

spark._jsparkSession.sessionState().sqlParser().parsePlan()
エラー
query = """
SELECT 1 AS fafdsf fafa
"""
spark._jsparkSession.sessionState().sqlParser().parsePlan(query)
py4j.security.Py4JSecurityException: Method public org.apache.spark.sql.catalyst.parser.ParserInterface org.apache.spark.sql.internal.SessionState.sqlParser() is not whitelisted on class class org.apache.spark.sql.internal.SessionState

対応方法
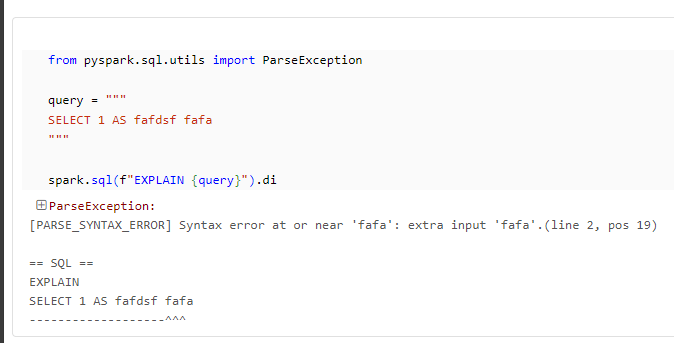
想定通りにParseExceptionが発生
from pyspark.sql.utils import ParseException
query = """
SELECT 1 AS fafdsf fafa
"""
spark.sql(f"EXPLAIN {query}").di