👋
データ分析基盤における概念モデル(リファレンスアーキテクチャ)




概要
データ分析基盤における概念モデル(リファレンスアーキテクチャ)の詳細を記載します。
下記の観点で、コンポーネントを整理しております。特定のベンダーによらないように汎用的なデータ分析基盤のモデルを目指して検討しました。
- ビックデータの3V(Volume、Variety、Velocity)に対応できる拡張性のあるアーキテクチャとすること
- データ分析レイヤーにて、可視化・統計解析(AI)シミュレーションの3つに分けて、それぞれのツールを選定できるようにすること
- データ仮想化サービス、データレプリケーションサービス、データプリパレーション(データ連携サービス)などのサービスの位置付けの明確化を行うこと
概念モデル
概念モデル図

レイヤー詳細
| 番号 | レイヤー | 説明 |
|---|---|---|
| 1 | ソースレイヤー | データ分析基盤がソースとするデータを保持したシステム、および、データストアを保持した層。 |
| 2 | インタフェースレイヤー | ソースレイヤーとデータ分析基盤の仲介を行い、必要に応じてデータの一時的保存や処理を行う層。 |
| 3 | バッチレイヤー | バッチ処理にてデータ処理を行い、永続的に大量のデータを保持する層。 |
| 4 | スピードレイヤー | リアルタイムデータ処理を行い、短期的に少量データのみを保持する層。 |
| 5 | サービスレイヤー | データ活用を行う上で最適なクエリを発行できるようにデータを保持する層。 |
| 6 | 物理レイヤー (サービスレイヤー) | 物理的にデータを保持することで、最適なクエリを発行できるようにする層。 |
| 7 | 論理レイヤー (サービスレイヤー) | 論理的に構造化したデータモデルを保持することで、想定文脈内での意味を結びつけたクエリを発行できるようにする層。 |
| 8 | データ利活用レイヤー | データ基盤にて管理したデータに対して、データ分析やデータ提供を行う層。 |
| 9 | データ分析レイヤー (データ利活用レイヤー) | ある目的に従い、可視化・統計解析・シミュレーションにより、価値を創造する活動を行うためのシステムを保持した層。 |
| 10 | データ利用レイヤー (データ利活用レイヤー) | データ分析基盤におけるデータを提供する層。 |
| 11 | データカタログ | データモデルとData Integration and Interoperability(データ統合と相互運用性)のメタデータに関する、カタログの作成(定義・抽出・蓄積)、および、カタログの利用(探索・把握・共有・配信)によるデータガバナンス支援システム層。 |
| 12 | オーケストレーション | ETL(データ抽出・変換・取り込み)や他プログラミングの実行などの処理の実施、データフローの開始から終了までの処理フローをパイプラインとして定義のの実施、および、パイプラインをトリガー(スケジュールトリガー、イベントトリガー等)トリガー登録によりプロセスコントロールの実施を行うシステム層。 DMBOKにおける下記コンポーネントを含めることを想定している。 ・データ変換エンジン/ETLツール ・オーケストレーション ・プロセスコントロール |
| 13 | DevOps | 運用チームと開発チーム間のコラボレーションを向上させるために、IT の迅速なサービス提供を可能とするシステム層。 |
コンポーネント詳細
| 番号 | データ基盤におけるレイヤー | コンポーネント名 | 説明 | サービス例 |
|---|---|---|---|---|
| 1 | ソースレイヤー | 業務システム | 業務を実施するために利用するシステム。 | SAP、Dynamics |
| 2 | ソースレイヤー | マスターデータ管理システム(MDM) | マスタデータの値と識別子の制御によるシステム間で一貫した利用を行うための運用を支援するシステム。データ分析基盤においては、管理されたマスターデータと参照データによる適合ディメンションの利用が可能となる。マスターデータと参照データを別のデータストアから連携することもある。 | Informatica MDM |
| 3 | ソースレイヤー | ストレージサービス | データをファイルとして保存できるサービス。 | AWS S3、Azure Storage、BOX、SharePoint Onlineドキュメント |
| 4 | ソースレイヤー | メッセージング | メッセージを一方向または双方向で送受信するサービス。利用される通信プロトコルには、HTTP、MQTT、AMQPがある。 | Fluentd |
| 5 | ソースレイヤー | データ仮想化サービス | データストアやサービスに対して、データの抽出、変換、統合を仮想的に実行するサービス。 | denodo |
| 6 | インタフェースレイヤー | ストレージ | データストアやサービスからのデータの配置、および、コネクター経由で取得したデータの配置を実施するためのデータストア。 | HDFS、Amazon S3、Azure Storage |
| 7 | インタフェースレイヤー | コネクター | データストアやサービスから、データの抽出・ロードを実施する機能。 | ODBC、REST API |
| 8 | インタフェースレイヤー | オペレーショナルデータストア (ODS) | ソースから抽出したデータに対して、クレンジング・統合・標準形式への変換により品質を保証したデータを、短期間(30日から60日)を保持させる、運用データの統合データストア。 データレイクに連携前に、本コンポーネントにより、データ品質を確認することにより、データスワンプ(沼)化をさけることが可能となる。 インターフェースレイヤーにて、インターフェース側のシステム担当者の仲介を果たすこともある。 | RDB(MySQL、SQL Server、PostgreSQL) |
| 9 | インタフェースレイヤー | データレプリケーションサービス | あるプライマリーデータストアにおけるデータを1つ以上のセカンダリデータストアへ、定期的にデータを同期するサービス。 | CData Sync、Qlik Replicate |
| 10 | インタフェースレイヤー | リアルタイムインジェスト | メッセジングのエンドポイントとなり、メッセジングとストリーム処理サービスとのデータの仲介を行い、データを一時的に保持するサービス。 | Amazon Kinesis、Azure IoT Hub、Apatch Kafka |
| 11 | バッチレイヤー | データレイク | 様々な構造であるデータ、大量のデータ、多頻度で発生するデータを保存できるサービス。Sparkなどのデータ統合サービスやETLツールを含める場合もある。管理がされていないデータや一貫性がないデータを含む場合には、データスワンプと呼ばれることがある。 | HDFS、Amazon S3、Azure Storage |
| 12 | バッチレイヤー | データ統合サービス | 様々な構造のデータを抽出し、そのデータを変換・標準化の処理を行い、マージを含むロード処理を行うサービス。 | Hadoop、Spark、Databricks、Google Big Query |
| 13 | スピードレイヤー | ストリーム処理サービス | リアルタイムインジェストから連続したデータを取得し、処理を行ったうえでデータの提供を低遅延で行うサービス。 | Amazon Kinesis、Azure Stream Analytics |
| 14 | サービスレイヤー (物理レイヤー) | データウェアハウス(DWH)【分析データストア(コールドパス)】 | バッチレイヤーにて統合されたデータをデータ活用を行うために提供することに最適化したデータストア。 今までは一元的に統合された意思決定支援データベースとして扱われてたが、データレイクの概念の普及によりデータ提供機能が主たる目的となってきた。 | Amazon Redshift 、Azure Synapase Analytics |
| 15 | サービスレイヤー (物理レイヤー) | 分析データストア(ホットパス) | ストリーム処理サービスのターゲットとなり、リアルタイムまたは低レイテンシのデータ処理を取り込み、データ活用レイヤーにデータを提供するデータストア。 | Amazon DyanamoDB、Azure CosmosDB |
| 16 | サービスレイヤー (論理レイヤー) | セマンティックデータモデル | 利用者がデータ構造を意識せずにデータ要素の意味の推論を行いながらデータ活用を実施可能となるように、基となるデータモデルをベースとして想定文脈内での意味を結びつけたデータモデルを保持したデータストア。 基となるデータモデリング手法としてはディメンションナルモデリングが多く、スキーマの項目をビジネス用語へ変換やテーブル間のリレーションシップ・メジャー(集計値)の定義を事前に実施しておき、ユーザーはGUIで必要なデータを抽出させることが多い。 | Azure Analytsis Servcies、SAP BW、Tableau Hyper、Power BI dataset |
| 17 | サービスレイヤー (論理レイヤー) | データ仮想化ソリューション | データストアやサービスに対して、データの抽出、変換、統合を仮想的に実行するサービス。 | denodo |
| 18 | データ利活用レイヤー (データ分析レイヤー) | 可視化システム(Business Interigence(BI)ツール) | データに基づき、集計や可視化によるデータの比較により洞察を主たる目的としたシステム。 | Tableau、Power BI、 |
| 20 | データ利活用レイヤー (データ分析レイヤー) | 解析システム | データに基づき、事象を数学的に定式化(モデル化)することを主たる目的としたシステム。 | SAS、Datarobot、Amazon SageMake、Azure Machine Learning |
| 22 | データ利活用レイヤー (データ分析レイヤー) | シミュレーションシステム | データに基づき、作成済みのモデルに制約条件を設定したうえで、期待値の算出、組み合わせの最適化、または、想定事象の現出の実施を主たる目的としたシステム。 | Anaplan、Python |
| 21 | データ利活用レイヤー (データ利用レイヤー) | データ連携サービス | バッチレイヤー、スピードレイヤー、サービスレイヤーにて保持しているデータに対して、データの抽出・変換・出力や多様な接続方法(REST API、MQTT等)によりデータを提供するサービスがある。 | Amazon Athena、Azure Synapse Analytics SQLオンデマンド 、Apache Presto |
| 22 | データ利活用レイヤー (データ利用レイヤー) | クエリエンジン | バッチレイヤー、スピードレイヤー、サービスレイヤーにて保持しているデータに対して、データへの接続環境を提供するサービス。 | |
| 23 | データカタログ | データカタログ | データモデルとData Integration and Interoperability(データ統合と相互運用性)のメタデータに関する、カタログの作成(定義・抽出・蓄積)、および、カタログの利用(探索・把握・共有・配信)によるデータガバナンス支援システム群。 | Informatica Data Catalog、Glue Catalog |
| 24 | オーケストレーション | オーケストレーション | ETL(データ抽出・変換・取り込み)や他プログラミングの実行などの処理の実施、データフローの開始から終了までの処理フローをパイプラインとして定義のの実施、および、パイプラインをトリガー(スケジュールトリガー、イベントトリガー等)トリガー登録によりプロセスコントロールの実施を行うシステム群。 DMBOKにおける下記コンポーネントを含めることを想定している。 ・データ変換エンジン/ETLツール ・オーケストレーション ・プロセスコントロール | JP1、Amazon Glue、Azure Data Factory |
| 25 | DevOps | DevOps | 運用チームと開発チーム間のコラボレーションを向上させるために、IT の迅速なサービス提供を可能とするシステム群。 | Github、Azure DevOps |
関連知識
ラムダアーキテクチャ
ラムダアーキテクチャについては、下記のマイクロソフト様の資料が詳しいです。本記事ではラムダアーキテクチャの概念のみを利用しており、ラムダアーキテクチャ思想に準拠しているわけではないです。

引用元:ビッグ データ アーキテクチャ
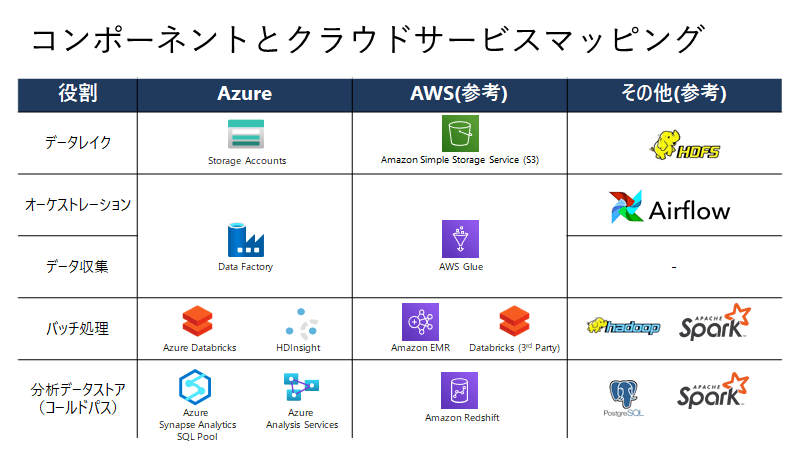
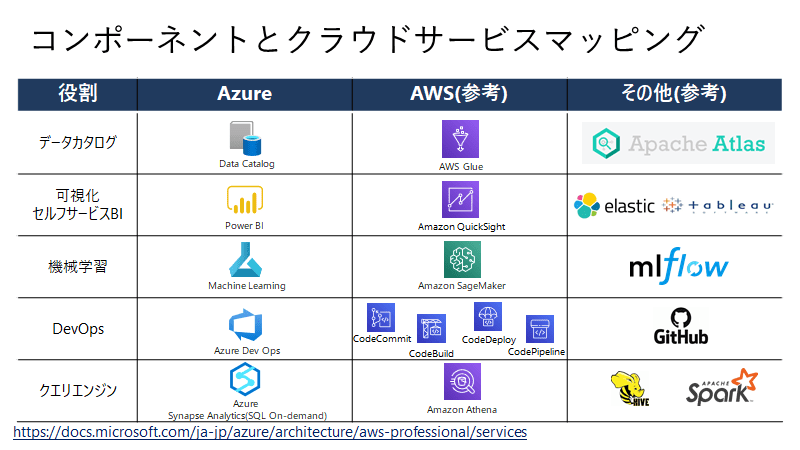
利用を検討すべきサービスについて
利用すべきサービスとしては、下記のものがあります。バッチ処理や分析データストア(コールドパス)に、Snowflakeを検討してもよいかもしれません。

Discussion
こちら、バッチレイヤーとスピードレイヤーの説明って逆ですか?
コメントありがとうございます。
反対ですね。
修正します。
修正しました。
ありがとうございました。
別途ご質問等ございましたら、ご気軽にどうぞ。
ありがとうございます!
とても参考にさせていただいております。
一通りお勉強させていただきつつ、個別にご相談させていただくかもしれません!