🍣
クラウド型DWHにおけるデータストア(データベース)の拡張方法に関する整理
概要
下記のサービスにて、データストア(データベース)の拡張方法を整理します。
- Azure SQL Database for PostgreSQL
- Databricks
- Snowflake
- Azure Synapse Analytics SQL Pool
- Amazon Redshift
- BigQuery
背景としては、Snowflakeは拡張性にすぐれているのですが、他サービスと比較したときにどのような相違点があるのかを説明するために実施しました。他クラウド型DWHと比較すると「3. クラスターのスケールアウト」と「4. コンピューティングリソースのマルチ化」観点で異なります。Databricksのように「4. コンピューティングリソースのマルチ化」が可能となることから、データレイクとしての利用が可能となります。即答性が高いことからも、バッチレイヤーとサービスレイヤーの共存させるようなレイクハウスとしての利用が可能となります。
各サービスにおけるデータストアの拡張方法の比較
| サービス | テクノロジー | 1. スケールアップ | 2. ノードのスケールアウト | 3. クラスターのスケールアウト | 4. コンピューティングリソースのマルチ化 |
|---|---|---|---|---|---|
| Azure SQL Database for PostgreSQL | 対称型マルチプロセッシング (SMP) | 〇 | △ <Br>読み取りのみ | - | - |
| Databricks | 超並列処理 (MPP) | 〇 | 〇 | × | 〇 |
| Snowflake | 超並列処理 (MPP) | × | 〇 | 〇 | 〇 |
| Azure Synapse Analytics SQL Pool | 超並列処理 (MPP) | × | 〇 | × | × |
| Amazon Redshift | 超並列処理 (MPP) | × | 〇 | △ <Br>読み取りのみ | △ <Br>読み取りのみ |
| BigQuery | 超並列処理 (MPP) | × | 〇 <Br>定額料金のみ | × | × |
前提知識
2つのコンピューティング処理テクノロジー~SMPとMPP~
| テクノロジー | 説明 | サービス例 |
|---|---|---|
| 対称型マルチプロセッシング (SMP) | CPU、メモリ、ストレージなどのリソースを共有したシステム。 | RDB |
| 超並列処理 (MPP) | CPU、メモリ、ストレージなどのリソースを保持させたノードを、ネットワークリンクにより処理を行うシステム。 | Hadoop、Spark、Presto |
データストアの拡張方法
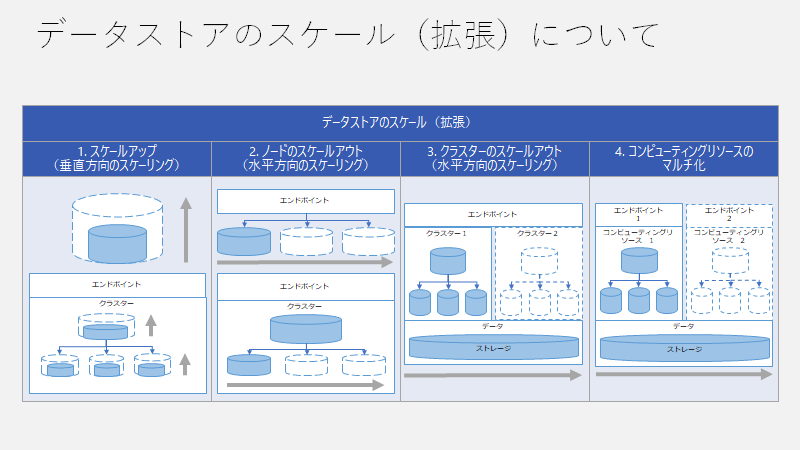
| 番号 | 拡張方法 | 説明 | メリット |
|---|---|---|---|
| 1 | スケールアップ (垂直方向のスケーリング) | CPU、メモリなどのリソースの容量を増減する方法。 |
SMP・MPPにおいて 処理可能なデータ量を増やすことができる。 |
| 2 | ノードのスケールアウト (水平方向のスケーリング) | 同一のエンドポイントを利用可能な状態で、CPU、メモリなどのリソースを保持したノードの数を増減する方法。 |
SMPにおいては 同時実行性(同時接続数)を高めることができる MPPにおいて 処理可能なデータ量を増やすことができる。 |
| 3 | クラスターのスケールアウト (水平方向のスケーリング) | 同一のエンドポイントを利用可能な状態で、クラスターの数を増減する方法。 |
MPPにおいて 同時実行性(同時接続数)を高めることができる。 |
| 4 | コンピューティングリソースのマルチ化 | 同一のストレージに接続可能な状態で、クラスターの数を増減する方法。 |
MPPにおいて コンピューティングリソース間の依存関係が低いため、データの書き込みやデータの読み込みなどの複数のワークロードを同時に実行可能となる。 |
更新履歴
- Amazon Redshiftにて、「4. コンピューティングリソースのマルチ化」の読み取りのみが可能へ
2020年10月15日に、クロスデータベースクエリという機能が発表されたため、Amazon Redshiftにて、「4. コンピューティングリソースのマルチ化」の読み取りのみが可能となりました。
Discussion