Vertex AI Vector Searchを使って類似画像検索を構築してみた
はじめに
こんにちは!逆転オセロニアのYouTubeチャンネル「まこちゃんねる」の中の人です。
本稿ではVertex AIのサービスの1つである、Vector Searchを使って、類似画像検索の構築からAPIエンドポイントへのデプロイまでを実施していきたいと思います!
Vector Searchとは?
Vector Searchは、テキストや画像データを数値ベクトルとして表現し、その間の類似度を計算することで、関連性の高いデータを検索する手法です。Google Cloudでは、Vertex AIと呼ばれるGoogle Cloud上に構築されている機械学習プラットフォームを介して利用することができます。
本稿で構築する類似画像検索の概要
以前にテンプレートマッチングを利用して類似画像を検索する仕組みを実装したのですが(Qiitaの記事にまとめています)、Vector Searchを利用すると、Google検索と同等のインフラストラクチャを使ってベクトル検索システムを構築できるということで、試してみたくなりました。本稿では、以前にテンプレートマッチングで実装した部分を置き換えるイメージで実装していこうと思います。以下のようなデッキ画像から各駒の図鑑Noを検索することで、図鑑Noに紐づく駒の詳細をデータベースから取得します。
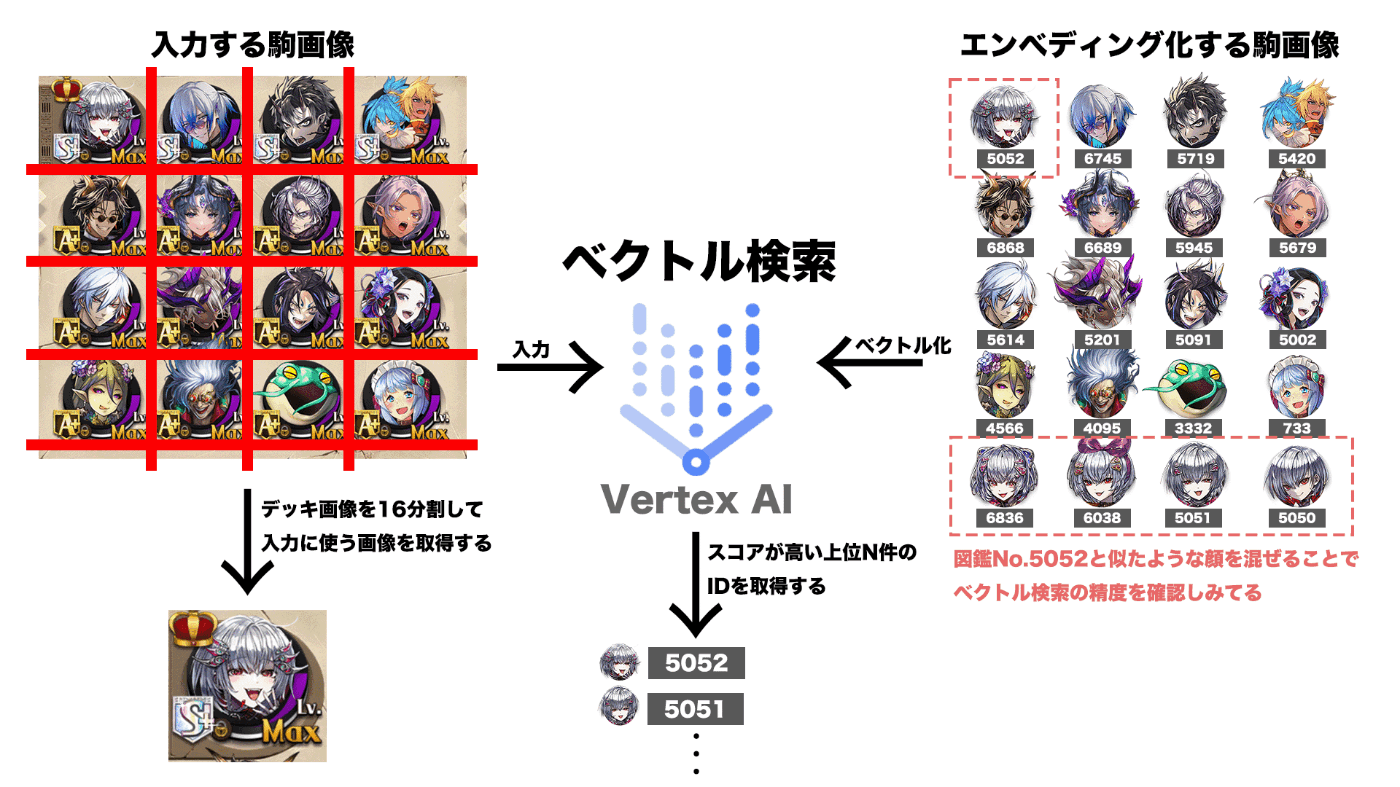
- 駒画像を図鑑Noと一緒に管理してエンべディング化を行う
- エンべディングのインデックスを作成してエンドポイントにデプロイする
- デッキ画像を16分割して、1駒を入力画像とする
- 入力画像をエンドポイントに投げて、類似駒画像の図鑑Noを検索する
環境
以下、筆者の環境です。Google Cloud SDKは公式リファレンスを参考に導入してください。
- Mac OS
- VS Code 1.90.2
- Python 3.9.6
- Google Cloud SDK 479.0.0
Vertex AI SDK for Pythonのインストール
以下のpipコマンドを実行して、SDKをインストールします。
pip install "google-cloud-aiplatform>=1.38"
手順
類似画像検索の実装とテストまでに、大きく分けて以下の手順で行います。
エンべディングの作成
本稿では、Vertex AIの生成AIであるマルチモーダルエンべディングモデルを使用して、画像データのエンべディングを作成していきます。以下、1枚の駒画像をエンべディング化するための全体のコードになります。すべての駒画像に対して同様の処理を行い、エンべディングを作成していきます。各スニペットの解説は後述します。
import vertexai
from vertexai.vision_models import (
Image,
MultiModalEmbeddingModel
)
# Vertex AIクライアントの初期化
vertexai.init(project="project-id", location="us-central1")
# マルチモーダルエンベディングモデルの読み込み
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
# エンベディングを作成する画像の読み込み
image = Image.load_from_file("/path/to/image.png")
# 画像のエンべディングの作成および確認
embeddings = model.get_embeddings(image=image)
print(f"Image Embedding: {embeddings.image_embedding}")
Vertex AIクライアントの初期化
まずはじめに、Vertex AIクライアントの初期化を行います。Vertex AIのマルチモーダルエンべディングモデルを利用するproject引数(プロジェクトID)やlocation引数(マルチモーダルエンべディングモデルがホストされているロケーション)を指定して初期化します。
vertexai.init(project="project-id", location="us-central1")
マルチモーダルエンベディングモデルの読み込み
MultiModalEmbeddingModelクラスのfrom_pretrained関数のmodel_name引数にモデル名multimodalembeddingを指定することで、マルチモーダルエンべディングのモデルを利用することができます。
model = MultiModalEmbeddingModel.from_pretrained(model_name="multimodalembedding")
エンベディングを作成する画像の読み込み
エンべディングを作成する画像のパスを指定して画像を読み込みます。本稿では駒画像がエンべディング対象であり、駒画像の名前を図鑑No.pngとして扱います。例えば以下のように読み込み、show関数を利用することで画像を表示できます。
image = Image.load_from_file("/path/to/5052.png")
image.show()
画像のエンべディングの作成および確認
エンべディングモデルのget_embeddings関数のimage引数に読み込んだ画像を指定することで、エンべディングを作成します。最後にエンべディングを確認すると、数値配列として表現され、ベクトル化されていることが分かると思います。
embeddings = model.get_embeddings(image=image)
print(f"Image Embedding: {embeddings.image_embedding}")

エンべディングの保存
次に作成したエンべディングのインデックスを作成するために、ファイルに出力してCloud Storageに保存する必要があります。ファイル形式はcsv、avro、json形式に対応していますが、本稿では以下のようなjson形式として保存します。公式ドキュメントも参考にしてください。
{"id": "1", "embedding": [-0.0304771625,-0.00153010117,...,-0.0110342083]}
{"id": "2", "embedding": [0.0327105522,7.96596e-05,...,-0.0328009538]}
JSONを作成するサンプルコードは以下になります。本稿では駒画像の図鑑Noをidをとして保存します。
import json
# エンべディングをIDと一緒にまとめたデータを作成する
data = {
"id": "5052",
"embedding": embeddings.image_embedding
}
# JSON文字列に変換する
json_string = json.dumps(data)
# JSON文字列をファイルに書き込む
with open('image_embeddings.json', 'w') as file:
file.write(json_string)
作成したjsonファイルをCloud Storageの任意のバケットにアップロードします。
gcloud storage cp /path/to/image_embeddings.json gs://bucket_name
エンベディングのインデックス作成
次に作成した駒画像のエンべディングのインデックスを作成していきます。インデックスの種類は2種類あり、定期的にまとめて更新するバッチインデックスと、すぐにインデックスを更新するストリーミングインデックスがあります。本稿では、バッチインデックスを扱います。公式ドキュメントも参考にしてください。以下、全体のコードになります。aiplatformをvertexaiと同様に初期化し、create_tree_ah_indexの引数でインデックスに関するオプションを指定します。
from google.cloud import aiplatform
# AI Platformクライアントの初期化
aiplatform.init(project="project-id", location="us-east1")
# インデックスの作成
index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
# インデックスの表示名
display_name="Image Embeddings Index",
# インデックスの説明
description="Image Embeddings Index",
# 作成したjsonファイルが格納されているバケットパス
contents_delta_uri="gs://bucket_name",
# 各エンべディングの次元数で、画像の場合はデフォルトで1408
dimensions=1408,
# シャーディングサイズの指定(サンプル数が少ないのでSMALLを指定)
shard_size="SHARD_SIZE_SMALL",
# 正確な並べ替えが実行される前に近似探索によってデフォルトで探索される近傍数
approximate_neighbors_count=150,
# インデックスの種類
index_update_method="batch_update",
# データポイントとクエリベクトルの距離計算のアルゴリズム(コサイン類似度等も指定可能)
distance_measure_type="DOT_PRODUCT_DISTANCE"
)
print(index.name)
Creating MatchingEngineIndex
Create MatchingEngineIndex backing LRO: projects/.../locations/us-east1/indexes/.../operations/...
MatchingEngineIndex created. Resource name: projects/.../locations/us-east1/indexes/...
To use this MatchingEngineIndex in another session:
index = aiplatform.MatchingEngineIndex('projects/.../locations/us-east1/indexes/...')
12345678900000000000
インデックスのデプロイ
次に作成したインデックスをデプロイしてAPIとして利用できるようにします。本稿ではマシンタイプをe2-standard-2(shard_sizeがSMALLでないとエラーが出てしまったので注意)、最小最大レプリカ数を1に設定することで、ランニングコストを最小に抑えています。料金に関しては公式ドキュメントを確認してください。以下、全体のコードになります。実行するとデプロイ完了までに30分ほどかかるので気長に待ちましょう。
# インデックスエンドポイントの作成
image_embeddings_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
# エンドポイントの表示名
display_name="Image Embeddings Index",
# エンドポイントの公開フラグ
public_endpoint_enabled=True
)
# インデックスエンドポイントのデプロイ
image_embeddings_index_endpoint.deploy_index(
# 作成したインデックス
index=index,
# エンドポイントを識別するための、ユーザー指定のエンドポイントID
deployed_index_id="image_embeddings_index_endpoint",
# マシンタイプの指定
machine_type="e2-standard-2",
# マシンレプリカの最大数の指定
max_replica_count=1,
# マシンレプリカの最小数の指定
min_replica_count=1
)
デプロイが完了してAPIが利用できるようになると、コンソール上からも確認することができます。

ベクトル検索のテスト
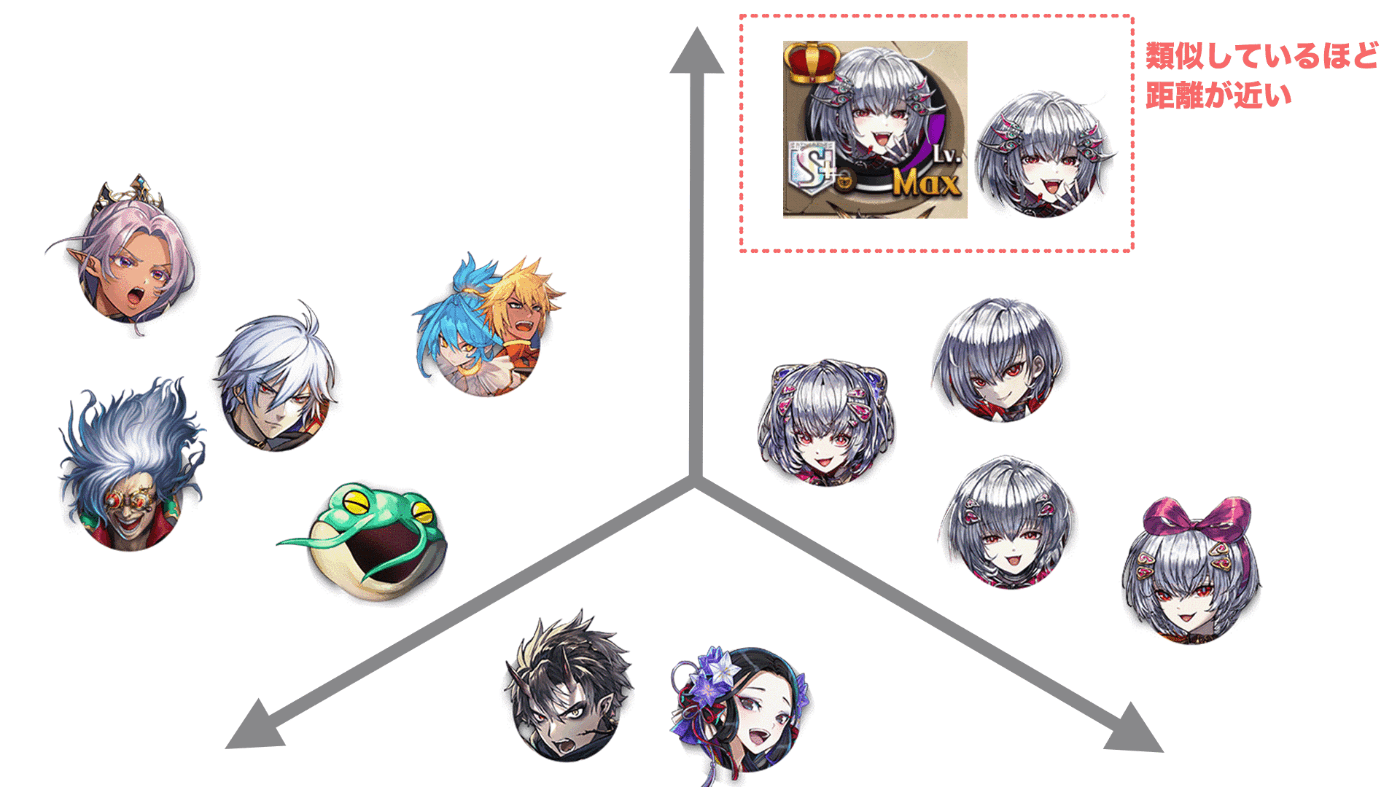
最後にデプロイされたインデックスエンドポイントをテストしてみます。入力画像は、デッキ画像から図鑑No.5052のメルヴェユールという駒画像部分のみをクロップした画像を扱ってみます。事前に似ている画像(同駒の別絵)をエンべディングとして含めているので、ここを見分けて検索してくれるかで精度をみたいと思います。
以下、全体のコードになります。
from vertexai.vision_models import Image
# 入力画像のエンべディングを作成する
query_image = Image.load_from_file("./images/_5052.png")
print("入力画像")
query_image.show()
query_embedding = model.get_embeddings(image=query_image)
# 類似度が高い上位3件を取得する
response = image_embeddings_index_endpoint.find_neighbors(
deployed_index_id="image_embeddings_index_endpoint",
queries=[query_embedding.image_embedding],
num_neighbors=3
)
print("検索された画像")
print(response[0][0])
print(response[0][1])
print(response[0][2])

上位3件のIDとその距離(大きい方が類似性がある)が返ってきているのが確認できます。これだけだと何の画像が検索されたのか分からないので、IDから対象の画像を、スコアが高い順に左から描画してみます。

検索されて欲しかった画像が一番類似度が高いという結果になりました!また、他の2つも似ている画像が検索されていることが分かると思います。
まとめ
本稿では、Vertex AIのVector Searchを使ってサクッと画像に対するベクトル検索を構築する方法を紹介しました。今回は画像から画像を検索するケースのみしか扱っていませんが、テキストと画像を組み合わせたようなマルチモーダルエンべディングにも対応しているので、いずれ紹介していきたいと思います!また、将来的にはデッキ画像を16分割するところも、生成AIへのテキスト指示でうまく作れそうな気がしているので模索していきたいです。
Discussion