Gemini 1.5 FlashからGrounding for Google Searchを使ってみた
はじめに
こんにちは!逆転オセロニアのYouTubeチャンネル「まこちゃんねる」の中の人です。
本稿ではGoogle Cloud Next '24で発表されたVertex AIの最新機能の1つである、Grounding for Google SearchをGeminiから使ってみたいと思います!
概要
本稿で使っていくソリューションは、大きく分けて以下の2つです。この2つは、Vertex AIと呼ばれるGoogle Cloud上に構築されている機械学習プラットフォームを介して利用することができます(Gemini単体は、Vertex AIとは別に、Google AIというサービスからも、Googleアカウントで利用することもできます)。詳細に関しては後述します。
- Gemini 1.5 Flash
- Grounding for Google Search
Geminiとは?
Googleが開発している生成AIのブランドで、OpenAIのGPTに相当します。マルチモーダルにも対応しており、テキスト以外にも画像や音声や動画を入力することができます。2024年6月30日時点で、以下のバージョンが公開されています(詳細はこちら)。本稿では、最新版かつコスパ重視のGemini 1.5 Flashを利用します。
| モデル名 | 対応している入力 | 対応している出力 | 備考 |
|---|---|---|---|
| Gemini 1.5 Flash | テキスト・画像・動画・音声 | テキスト | 最新版で1.5 Proより高コスパ |
| Gemini 1.5 Pro | テキスト・画像・動画・音声 | テキスト | 最新版で1.5 Flashより高精度 |
| Gemini 1.0 Pro | テキスト | テキスト | テキストのみのタスクに最適 |
| Gemini 1.0 Pro Vision | テキスト・画像・動画・音声 | テキスト | マルチメディア対応版 |
| Gemini 1.0 Ultra | テキスト | テキスト | 複雑なタスクに最適化 |
| Gemini 1.0 Ultra Vision | テキスト・画像・動画・音声 | テキスト | マルチメディア対応版 |
Groundingとは?
Geminiのような大規模言語モデル(Large Language Models、LLM)は、事実とは異なるもっともらしい嘘の情報を生成してしまうことがあります(ハルシネーション)。この問題に対処する手法の1つに、回答を直接生成させるのではなく、質問内容に基づいて外部の情報源を参照して生成することで、信頼性のある回答を得ることができます。外部データを参照して回答結果を生成する仕組みは、RAG(Retrieval Augmented Generation)とも呼ばれ、こちらもGroundingの手法の1つです。具体的なユースケースとしては、社内の情報源からナレッジベースを作成し、LLMの参照先とすることで、社内の人間しか知りえない情報をLLMに追加学習させることなく検索できる仕組みを構築することが可能です。本稿では、情報源としてGoogle検索を扱う内容になります。
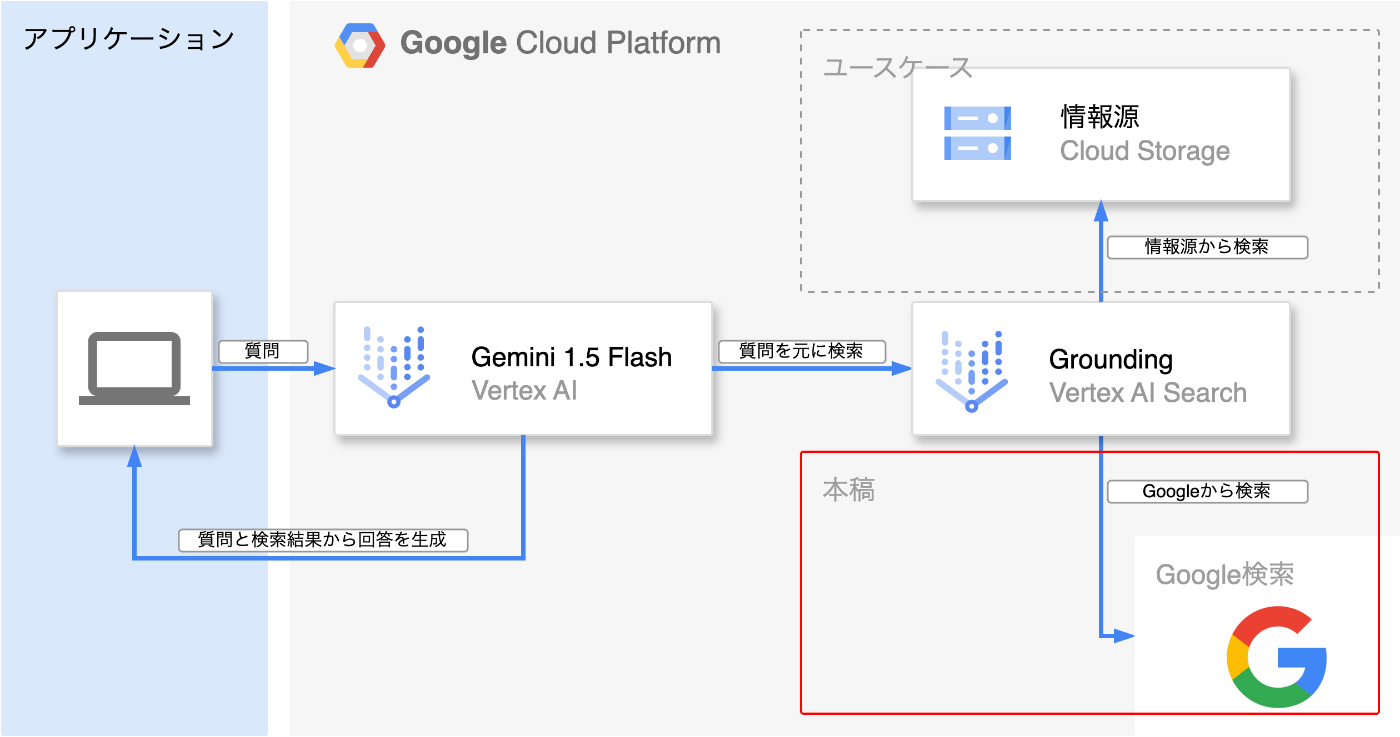
使ってみる
今回は、以下の2つの方法から使ってみたいと思います。尚、既にGoogleアカウントおよびGoogle Cloudプロジェクトが準備されている前提とします。また、本稿ではGoogle Cloudコンソール画面の言語設定が英語の状態で解説します。
- Google Cloudのコンソール画面から利用する方法
- Vertex AI SDK for Pythonから利用する方法
Google Cloudのコンソール画面から利用する方法
プログラムを書かずに、ブラウザ上から利用することができます。Google Cloudコンソールの検索窓で、[Vertex AI]と入力して検索し、Vertex AIの画面を開きます。左にある[TOOLS]サイドバーから[Language]を選択し、[TEXT PROMPT]を押下してプロンプト画面を開きます。

Grounding for Google Searchを有効化する
プロンプト画面の右にあるサイドバーから[Model]は[gemini-1.5-flash-001]を選択し、[Advanced]を開き、[Enable Grounding]のトグルスイッチをオンにして、[CUSTOMIZE]ボタンを押下してGroundingの設定画面を開きます。
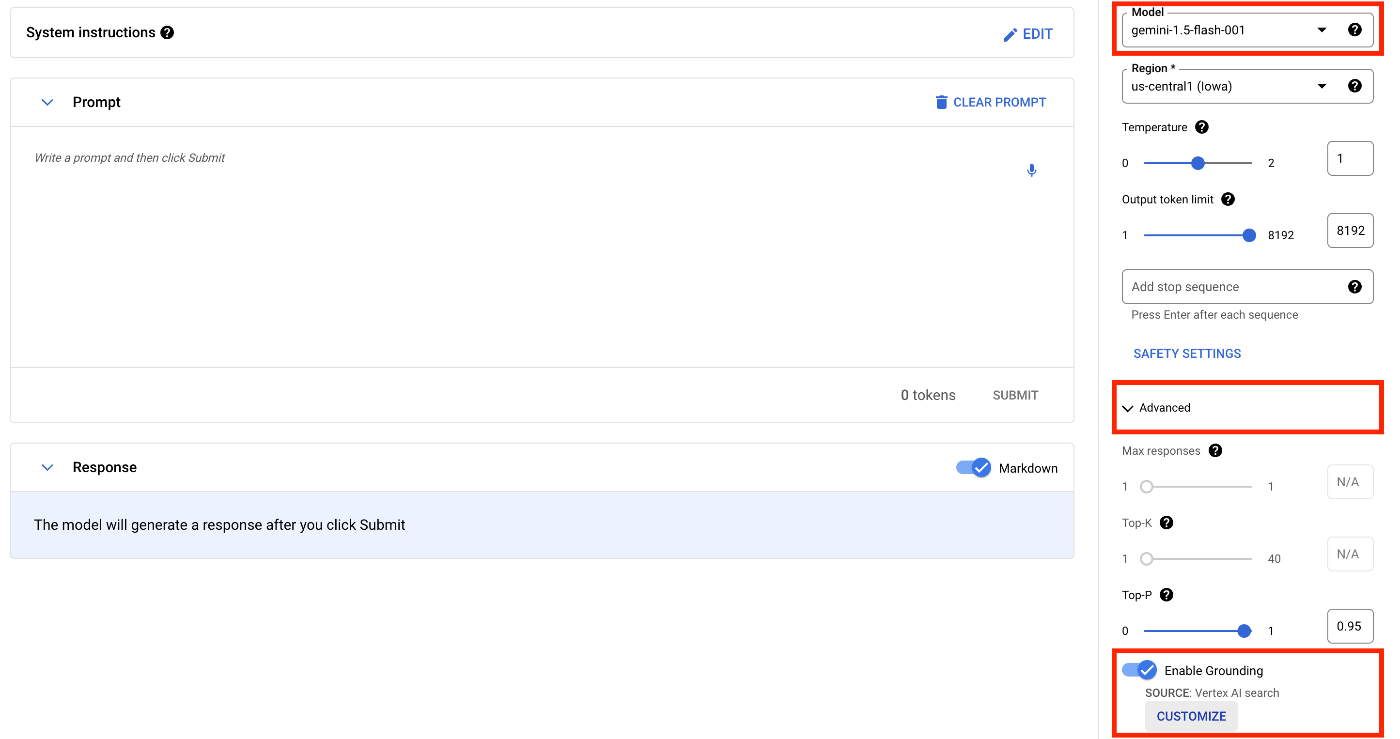
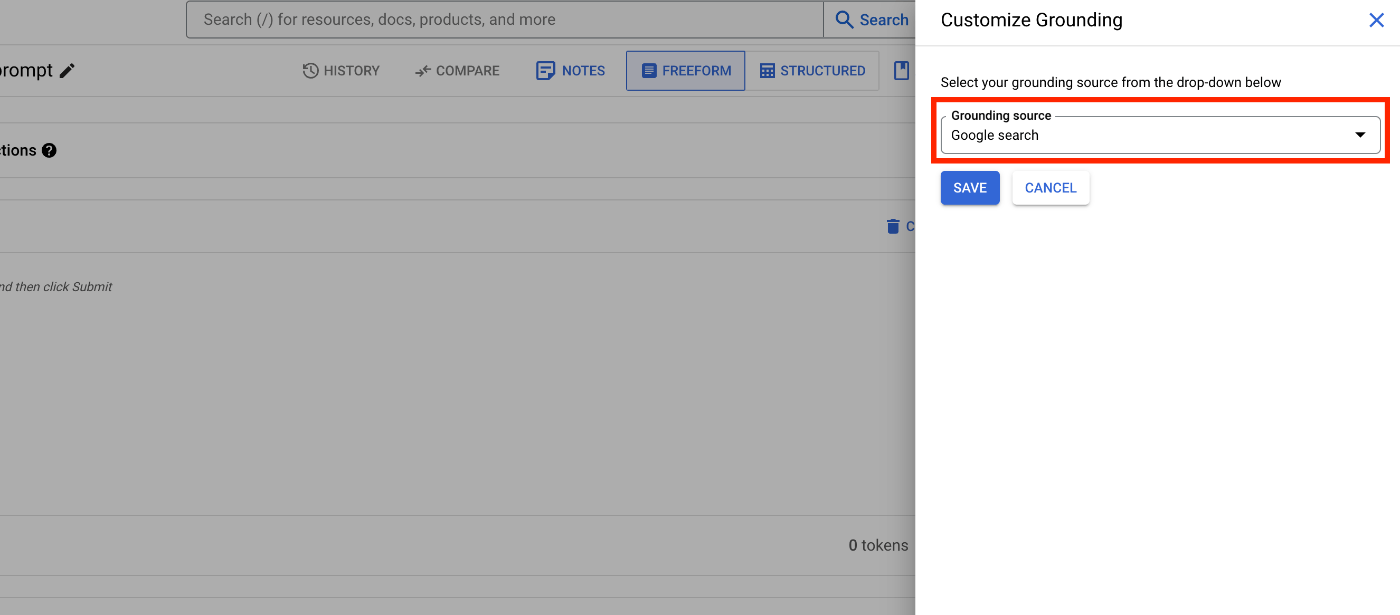
[Grounding source]は[Google search]を選択し、[SAVE]ボタンを押下して設定を保存します。これだけで、Google検索のGroundingを有効化することができます。
コンソール画面からGemini 1.5 Flashを実行
Groundingが有効化されているか確認するために、一旦[Enable Grounding]のトグルスイッチをオフにした状態で回答を生成してみます。事前に知識として持っていないであろう、逆転オセロニアのプロデューサーは誰かを質問してみます。
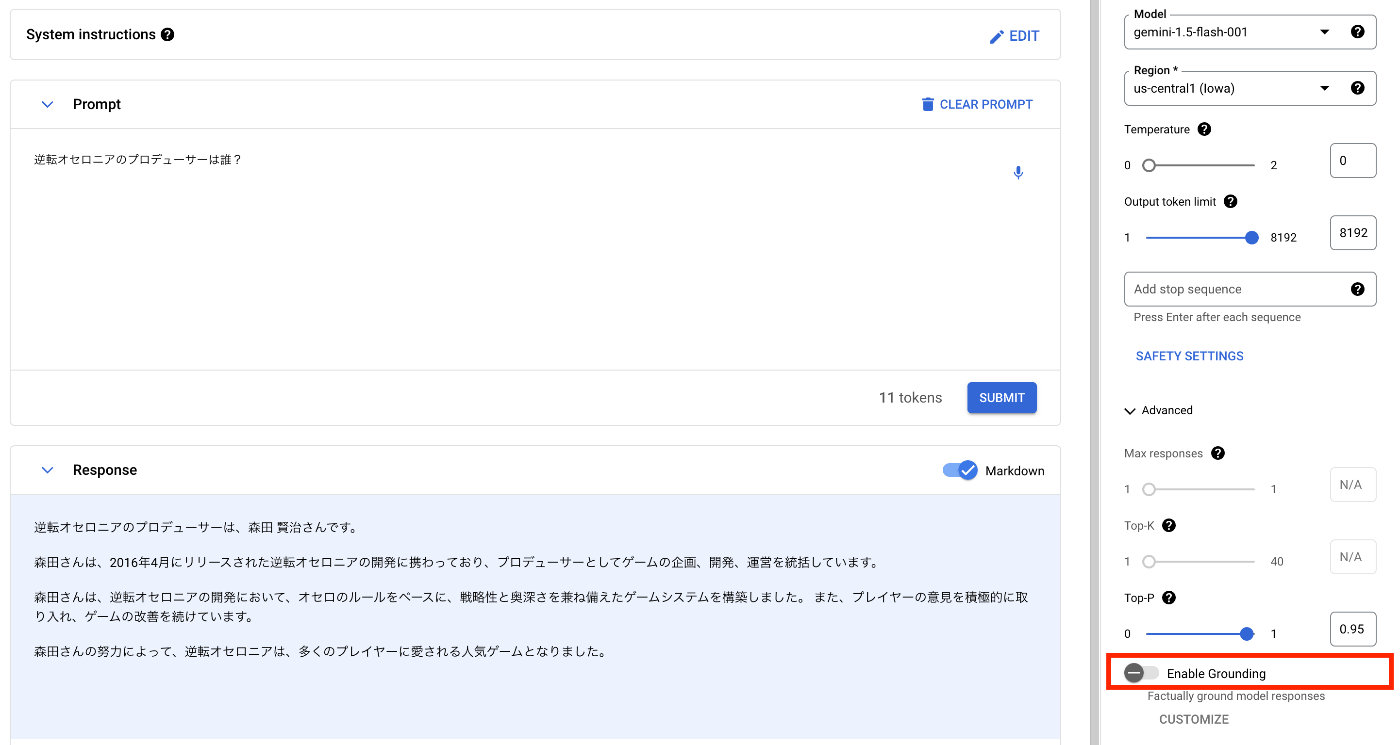
プロデューサーは森田賢治さんであるという答えが返ってきましたが、これは誤りです。逆転オセロニアのプロデューサーは、Wikipediaにも記載のある通り、「けいじぇい」こと「香城卓」さんです。では次に、[Enable Grounding]のトグルスイッチをオンにした状態で回答を生成してみます。
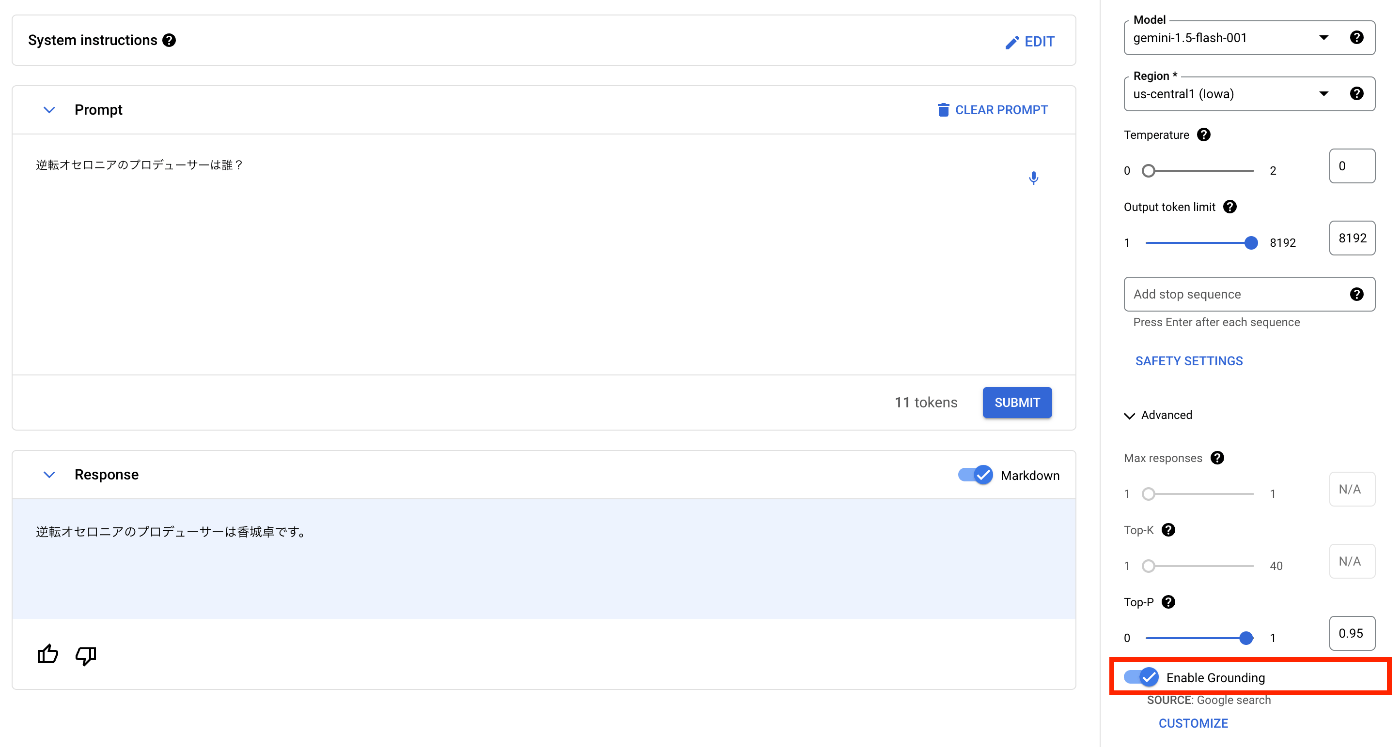
プロデューサーは香城卓さんであるという正しい答えが返ってきました。このように、Google検索で調べた時と同等の精度でGeminiに回答させることが可能になります。生成AIは特に固有名詞や日付に関する質問にはハルシネーションを起こしやすいため、こうしたGroundingを活用していくことで、より精度の高いシステムを構築することが可能です。
Vertex AI SDK for Pythonから利用する方法
次に、Pythonからも利用してみたいと思います。Geminiを活用したシステムを構築する場合は、Vertex AIのSDKが用意されているので、こちらを利用します。
環境
以下、筆者の環境です。Google Cloud SDKは公式リファレンスを参考に導入してください。
- Mac OS
- VS Code 1.90.2
- Python 3.9.6
- Google Cloud SDK 479.0.0
Vertex AI SDK for Pythonのインストール
以下のpipコマンドを実行して、SDKをインストールします。
pip install "google-cloud-aiplatform>=1.38"
PythonからGemini 1.5 Flashを実行
以下、全体のコードになります。実行すると、コンソール画面から実行した回答結果と同様に、「逆転オセロニアのプロデューサーは香城卓です。」という結果が出力されます。各スニペットの解説は後述します。
import vertexai
from vertexai.generative_models import GenerativeModel, FinishReason, Tool
import vertexai.preview.generative_models as generative_models
# Vertex AIクライアントの初期化
vertexai.init(project="project-id", location="us-central1")
# Grounding for Google Searchの設定
tools = [
Tool.from_google_search_retrieval(
google_search_retrieval=generative_models.grounding.GoogleSearchRetrieval(disable_attribution=False)
),
]
# モデル情報の初期化
model = GenerativeModel(
"gemini-1.5-flash-001",
tools=tools,
)
# 生成AIのパラメータ設定
generation_config = {
"max_output_tokens": 8192,
"temperature": 1,
"top_p": 0.95,
}
# 安全性属性の設定
safety_settings = {
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
}
# Gemini APIの実行
response = model.generate_content(
["""逆転オセロニアのプロデューサーは誰?"""],
generation_config=generation_config,
safety_settings=safety_settings,
stream=False,
)
# 回答結果の確認
print(response.text)
Vertex AIクライアントの初期化
まずはじめに、Vertex AIクライアントの初期化を行います。Gemini APIを利用するproject引数(プロジェクトID)やlocation引数(Geminiがホストされているロケーション)を指定して初期化します。デフォルトでは、gcloud initした時のクレデンシャル情報を参照するようになっているので、独自のサービスアカウントのクレデンシャルを利用したい場合は、credentials引数にサービスアカウントのJSONキーパスを指定することもできます。
# Vertex AIクライアントの初期化
vertexai.init(project="project-id", location="us-central1")
Grounding for Google Searchの設定
ここでは、Groundingの設定を行います。Google Searchを利用する場合は、以下のように書けば指定できているようです。ちなみに、Vertex AIのプロンプト画面右上の[GET CODE]から、プロンプト画面で設定している内容で、Pythonから実行できるコードを生成してくれる機能があります。ここでは、Grounding for Google Searchを設定した上で、[GET CODE]から生成したPythonコードを参考にしています。
# Grounding for Google Searchの設定
tools = [
Tool.from_google_search_retrieval(
google_search_retrieval=generative_models.grounding.GoogleSearchRetrieval(disable_attribution=False)
),
]
モデル情報の初期化
ここでは、利用するモデルバージョン(gemini-1.5-flash-001)やGrounding情報を設定して、GenerativeModelクラスを生成します。システムプロンプトもここで設定することができて、その場合はsystem_instruction引数を指定します。詳細な引数項目に関しては公式リファレンスを参考にしてください。
# モデル情報の初期化
model = GenerativeModel(
"gemini-1.5-flash-001",
tools=tools,
)
生成AIのパラメータ設定
ここでは、最大出力トークン数や温度等のパラメータを設定します。詳細な引数項目に関しては公式リファレンスを参考にしてください。
# 生成AIのパラメータ設定
generation_config = {
"max_output_tokens": 8192,
"temperature": 1,
"top_p": 0.95,
}
安全性フィルタの設定
ここでは、安全性フィルタを設定します。以下の4つの項目に対して、5段階の閾値を設定することで、回答結果のフィルタリングを行うことができます。詳細は公式リファレンスを参照してください。
- ヘイトスピーチ(HARM_CATEGORY_HATE_SPEECH)
- 危険なコンテンツ(HARM_CATEGORY_DANGEROUS_CONTENT)
- 性的に露骨な表現(HARM_CATEGORY_SEXUALLY_EXPLICIT)
- 嫌がらせ(HARM_CATEGORY_HARASSMENT)
# 安全性属性の設定
safety_settings = {
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
}
Gemini APIの実行
ここでは、generate_content関数を実行して回答結果を取得します。引数には入力内容、生成AIのパラメータ設定(generation_config)、安全性フィルタの設定(safety_settings)、ストリーミングフラグ(stream)を設定して実行します。今回の入力は単一のテキストだけですが、マルチモーダルの場合は、同時に画像や動画をリストに含めることができます。
# Gemini APIの実行
response = model.generate_content(
["""逆転オセロニアのプロデューサーは誰?"""],
generation_config=generation_config,
safety_settings=safety_settings,
stream=False,
)
回答結果の確認
最後に、回答結果を確認します。responseオブジェクトのtextから回答結果のテキストを取得できます。
# 回答結果の確認
print(response.text)
逆転オセロニアのプロデューサーは香城卓です。
まとめ
本投稿では、コンソール画面とPythonの両方から、GeminiをベースにGrounding for Google Searchを利用する方法を紹介しました。基本的にはフラグを有効化するだけで、Google検索レベルでのRAGが実装できることに感動しました!ユースケースとしては、社内の独自資料をパブリックにすることなく、LLMベースで検索できる仕組みの方が需要があるかなと思うので、そちらもいずれ紹介していきたいと思います!
Discussion