Google「Veo 3」はCVのゲームチェンジャーか?ゼロショット推論の実力に迫る
ども!最新のAI技術を触りまくることに命を燃やすテックブロガーのタカマツです。
はじめに
近年、大規模言語モデル(LLM)が「プロンプト(指示文)を与えるだけで」翻訳、要約、コーディングといった多様なタスクをこなすようになり、自然言語処理(NLP)の世界に革命をもたらしました。これまでタスクごとに専用のモデルを開発するのが当たり前だった時代から、一つの巨大な汎用モデルがすべてをこなす時代へと、大きなパラダイムシフトが起きています。
では、画像や動画を扱うコンピュータビジョン(CV)の分野ではどうでしょうか?CVの世界でも、LLMがNLPにもたらしたような変革は起こりうるのでしょうか?
今回ご紹介するのは、そんな問いに力強く「Yes」と答える、Google DeepMindによる論文「Video models are zero-shot learners and reasoners」です。この論文では、最新の動画生成モデル「Veo 3」が、特定のタスクのために訓練されていないにもかかわらず、驚くほど多様な視覚タスクを「ゼロショット(=事前学習なし)」で解決できることを示しています。
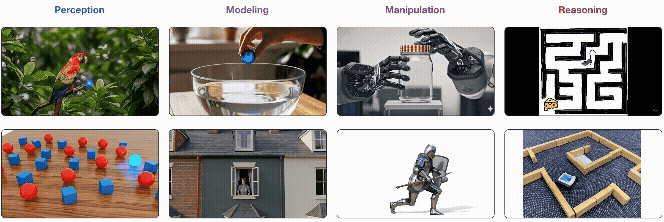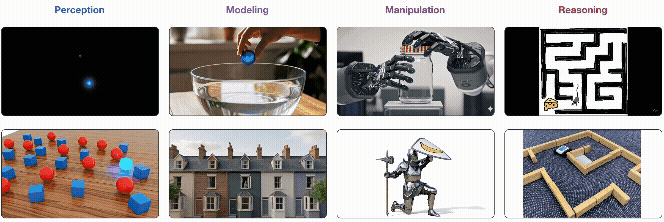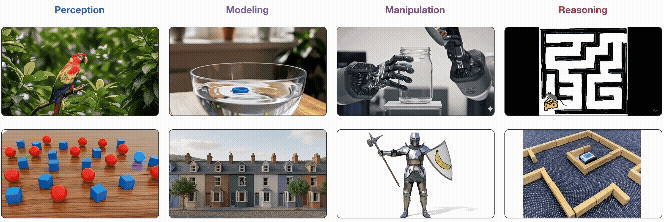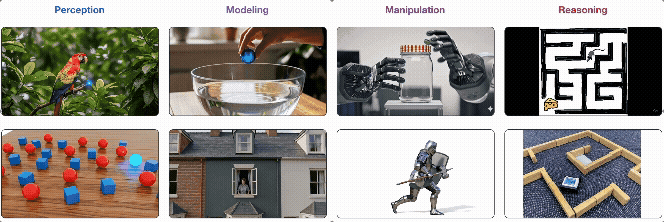
(出典: Wiedemer et al. "Video models are zero-shot learners and reasoners" Fig.1より抜粋)
この記事では、Veo 3が持つ驚異的な能力とは何か、そしてそれがどのようにコンピュータビジョンの未来を変える可能性を秘めているのかを、分かりやすく解説していきます。
論文の概要:Veo 3が示す「視覚的知性」の萌芽
本論文の核心的な主張は、「大規模な動画モデルは、CV分野における汎用的な基盤モデルになる軌道に乗っている」というものです。研究チームは、Veo 3の能力を検証するために、実に18,384本もの動画を生成し、その性能を分析しました。
論文が明らかにした主なポイントは以下の通りです。
- 驚異的なゼロショット能力: Veo 3は、物体セグメンテーション、エッジ検出、画像編集、物理法則の理解、迷路解決など、明示的に訓練されていない60以上の多様なタスクをプロンプトだけで解決できる。
- 4つの階層的な能力: Veo 3の能力は、単純なものから複雑なものへ、①知覚(Perception) → ②モデリング(Modeling) → ③操作(Manipulation) → ④推論(Reasoning) の4つの階層で理解できる。
- "Chain-of-Frames (CoF)"という新概念: LLMが「思考の連鎖(Chain-of-Thought)」で複雑な問題を解くように、動画モデルは**フレームの連鎖(Chain-of-Frames)**によって、時間と空間をまたぐ段階的な視覚的推論を行うことができる。
- 急速な進化: 前モデルのVeo 2からVeo 3への性能が大幅に向上しており、この分野の技術が急速に進歩していることを示している。
Veo 3はどのように世界を理解するのか? 4つの階層的能力
論文では、Veo 3の能力を4つの階層に分けて整理しています。これにより、動画モデルがどのように視覚世界を理解し、操作しているのかが非常に分かりやすくなります。

(出典: Wiedemer et al. "Video models are zero-shot learners and reasoners" Fig.2より抜粋)
1. Perception (知覚)
これは、視覚情報を基礎的なレベルで理解する能力です。人間でいえば「見る」能力に相当します。
Veo 3は、プロンプトを与えるだけで、これまで専用のモデルが必要だった以下のようなタスクを実行できます。
- エッジ検出: 物体の輪郭線を正確に抽出する。
- セグメンテーション: 画像内の個々の物体を領域分けする。
- 超解像: 低画質の画像を鮮明な高画質画像に変換する。
- ノイズ除去: ノイズだらけの画像からクリーンな画像を復元する。
これらのタスクの多くは、Veo 3が明示的に訓練されたものではないにもかかわらず可能であり、モデルが汎用的な視覚表現を内部に獲得していることを示唆しています。
2. Modeling (モデリング)
知覚した情報をもとに、その世界の法則や物体間の関係性を理解する能力です。物理法則や空間関係を「モデル化」する力と言えます。
- 直感物理: 物体の硬さ(剛体/軟体)、浮力、空気抵抗といった物理的な性質を理解し、それに基づいたシミュレーションを生成する。
- 物体関係の理解: 複数の物体があるシーンで、「おもちゃだけをバックパックに入れる」といった抽象的な指示を理解し、実行できる。
- 世界の状態記憶: カメラが一度ズームインして、再びズームアウトした際に、元の世界の配置を記憶している。
3. Manipulation (操作)
知覚し、モデル化した世界を、意図に沿って能動的に変化させる能力です。これは、想像力や創造性にも繋がります。
- 画像編集: 背景の削除、画像のカラー化、スタイル変換などをゼロショットで行う。
- 3D世界の理解: 1枚の画像から新しい視点の画像を生成したり、キャラクターのポーズを変更したりできる。
- 複雑なインタラクションのシミュレーション: ロボットアームが器用に瓶のフタを開ける、といった複雑な操作をシミュレートする。
4. Reasoning (推論)
これまでの3つの能力を統合し、複数のステップを要する複雑な視覚的問題を解決する能力です。これが、本研究のタイトルにもある「reasoner (推論者)」たる所以です。
- 迷路解決: スタートからゴールまでの正しい経路をたどる動画を生成する。
- パズル解決: 簡単な数独や、ルールに基づいたパズルを解く。
- ツールの使用: 水槽の中にあるクルミを、直接手を使わずに道具(網)を使って取り出す様子を生成する。
特に、迷路解決のようにステップバイステップでの思考が求められるタスクを動画(=フレームの連鎖)として生成できる能力は、Chain-of-Frames (CoF) と名付けられ、LLMにおける思考の連鎖(CoT)に匹敵する、動画モデルの新たな可能性を示しています。
Veo 3の実力は? 実験結果
論文では、これらの能力を定性的・定量的に評価しています。
定性評価では、冒頭の図にもあるように、62もの多様なタスクにおける成功率を評価しました。タスクによっては100%に近い成功率を示すものもあり、その汎用性の高さが伺えます。
定量評価では、特に7つのタスク(エッジ検出、セグメンテーション、迷路解決など)に絞って、前モデルのVeo 2や他のモデルと比較しています。

(出典: Wiedemer et al. "Video models are zero-shot learners and reasoners" Fig.7より抜粋)
上のグラフは、様々なサイズの迷路解決タスクにおける成功率を示したものです。Veo 3 (紫色の線) は、前モデルの Veo 2 (青色の線) に比べて、圧倒的な性能向上を達成していることが一目瞭然です。これは、動画モデルの能力がわずか半年ほどの期間で飛躍的に進化したことを意味します。
もちろん、多くのタスクにおいて、その分野の最先端(SOTA)である特化型モデルの性能にはまだ及びません。しかし、これはLLMの初期段階でも見られた現象です。汎用モデルでありながら、ゼロショットでこれだけの性能を発揮することは驚異的と言えるでしょう。
まとめ:コンピュータビジョンの「GPT-3モーメント」は近いか?
今回の論文は、コンピュータビジョン分野が、NLPが数年前に経験したような大きな変革の入り口に立っていることを強く示唆しています。
- パラダイムシフトの兆候: Veo 3が示した驚異的なゼロショット汎化能力は、タスクごとに専用モデルを開発する時代から、単一の巨大な動画基盤モデルがあらゆる視覚タスクを担う未来を予感させます。
- 性能向上の速度: Veo 2からVeo 3への短期間での飛躍的な性能向上は、今後のさらなる進化に大きな期待を抱かせます。
- Chain-of-Framesの可能性: 動画を生成するプロセスそのものが「推論」になるというCoFの考え方は、より高度な視覚的AIエージェントの実現に向けた重要な一歩となるかもしれません。
論文も認めているように、Veo 3はまだ「Jack of many trades, master of few (多芸は無芸)」の状態かもしれません。しかし、LLMの歴史が示すように、汎用モデルの性能と効率は急速に向上していきます。
動画生成のコストなど、まだ乗り越えるべき課題はありますが、コンピュータビジョンにおける「GPT-3モーメント」は、私たちが思うよりずっと近くまで来ているのかもしれません。
それではまた、次の記事で! 🚀
参考文献
- Wiedemer, T., Li, Y., Vicol, P., Gu, S. S., Matarese, N., Swersky, K., ... & Geirhos, R. (2025). Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328.
- Project page: https://video-zero-shot.github.io/
Discussion