🖐️
MediaPipeの検出結果をもとに、P5で描画する。
この記事ではGoogle MediaPipeを用いて手を検出し、その結果をもとにP5で描画を行う方法を紹介します。
P5による描画をカスタマイズしてコンテンツに活用できると思います。
デモ
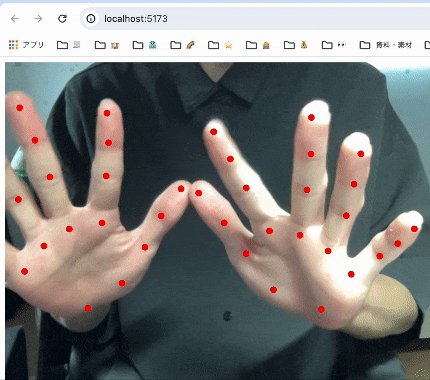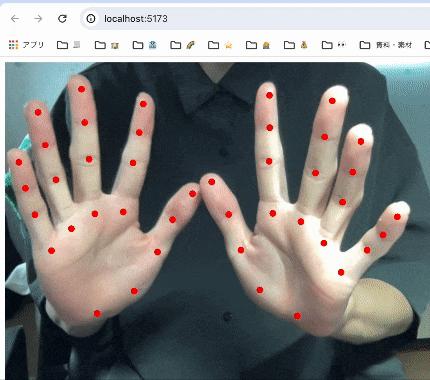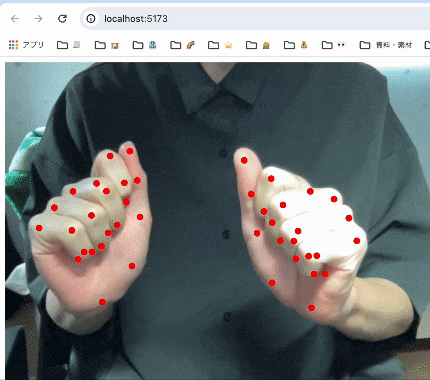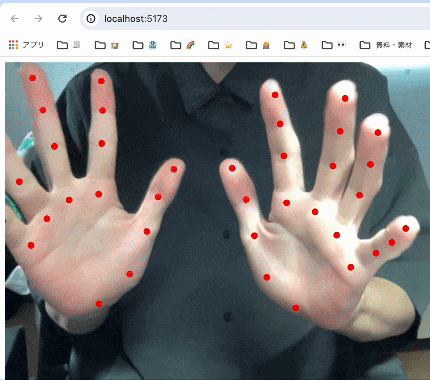
実装
🌾捕捉事項
過去の記事ではMediaPipe Handsが用いられており、npmパッケージも@mediapipe/handsなどを使い実装されているものが多かったです。
2024.05現在MediaPipeのうち視覚情報を扱うものがMediaPipe Vision tasksとしてまとめ提供されているようなのでこの記事では後者で実装を行なっています。
環境構築
学習済みのモデルをダウンロード
MediaPipeを使うために学習済みのモデルをダウンロードしてプロジェクトに配置します。
下のリンクからhand_landmarker.taskを入手し、プロジェクトのルートディレクトリに置いてください。
Viteプロジェクトの作成
npm create vite@latest
npm i @mediapipe/tasks-vision
npm i p5 @types/p5
手(HandLandmark)を検出し、P5で描画する。
main.ts
import { FilesetResolver, HandLandmarker } from "@mediapipe/tasks-vision";
import p5 from "p5";
//オプションからHandLandmarkerを作成
const createHandLandmarker = async () => {
const vision = await FilesetResolver.forVisionTasks(
"../node_modules/@mediapipe/tasks-vision/wasm"
);
const handLandmarker = await HandLandmarker.createFromOptions(vision, {
baseOptions: {
//ダウンロードした学習済みのモデルファイル
modelAssetPath: "../hand_landmarker.task",
//CPUだと若干重くなりました。
// delegate: "CPU",
delegate: "GPU",
},
runningMode: "VIDEO",
numHands: 2,
});
return handLandmarker;
};
export const sketch = (p: p5) => {
let handLandmarker: HandLandmarker;
let lastVideoTime = -1;
let capture: p5.Element;
let video: HTMLVideoElement;
const setup = async () => {
//handLandmarkの検出で利用
handLandmarker = await createHandLandmarker();
//キャンバスを生成し#App直下に配置
const canvas = p.createCanvas(640, 480);
const app = document.querySelector<HTMLDivElement>("#app")!;
canvas.parent(app);
//キャプチャ設定
capture = p.createCapture("video");
capture.size(640, 480);
video = capture.elt;
capture.hide();
};
const draw = () => {
//必要なデータが揃っていない場合はdrawを見送り
if (!handLandmarker || !video.srcObject) return;
if (!video.videoWidth || !video.videoWidth) return;
if (video.currentTime === lastVideoTime) return;
//前回のキャンバスの反転をリセット
p.pop();
p.push();
//キャンバスを反転
p.translate(p.width, 0);
p.scale(-1, 1);
p.displayWidth = p.width;
p.displayHeight = (p.width * capture.height) / capture.width;
p.image(capture, 0, 0, p.displayWidth, p.displayHeight);
//ここでhandLandmarkの検出を行う
//result.handLandmarksは手ごとのhandLandmarkの配列
const results = handLandmarker.detectForVideo(video, video.currentTime);
lastVideoTime = video.currentTime;
if (results.landmarks.length <= 0) return;
for (const landmarks of results.landmarks) {
for (let i = 0; i < landmarks.length; i++) {
//全てのhandLandmarkを円で描画
p.fill(255, 0, 0);
p.noStroke();
p.ellipse(
landmarks[i].x * p.displayWidth,
landmarks[i].y * p.displayHeight,
10,
10
);
}
}
};
p.setup = setup;
p.draw = draw;
};
new p5(sketch);
index.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>MediaPipe HandDetection with P5</title>
</head>
<body>
<div id="app"></div>
<script type="module" src="/src/main.ts"></script>
</body>
</html>
実行方法
npm run dev
解説
HandLandmarkの検出
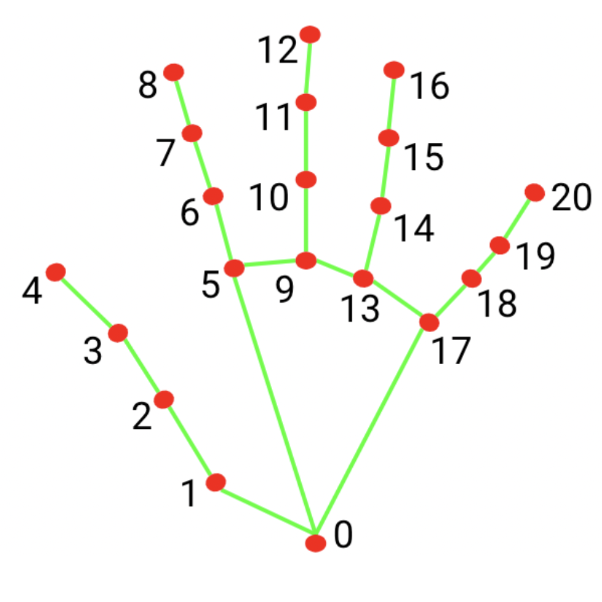
result.handLandmarksは検出された手の数と同じ大きさの配列になっています。
HandLandmarkは下の画像のように取得され、1つ目の手の親指の先端のx位置を取得したければ
result.handLandmarks[0][4].xで取得できます。
const result = handLandmarker.detectForVideo(video, video.currentTime);
//1つ目の手の親指のx位置を取得
const thumbTipX = result[0][4].x
MediaPipeについて
MediaPipeでは画像・音声・テキストに対して様々な分類、検出が行えます。
また、LLMをデバイス上で実行でき、文章の認識や生成も行えます。
WebAssemblyを用いることで、デバイス側で高速に処理を行えるようにしているみたいです。
Discussion